
Grok Image to Video, powered by der proprietären xAI Aurora Engine, ist der wettbewerbsfähigste KI-Videogenerator, der 2026 veröffentlicht wurde. Grok Imagine Video 1.5 erreichte den 1. Platz auf der Image-to-Video Arena-Bestenliste mit einem Sprung von +52 Elo-Punkten gegenüber dem Vorgänger und übertraf damit Seedance 2.0 von ByteDance, HappyHorse 1.0 und Google Veo.

Die obigen Daten stammen von Arena.ai
Drei Vorteile heben es sofort von der Konkurrenz ab:
- Geschwindigkeit: Die Generierung ist in 5 bis 30 Sekunden abgeschlossen – schneller als die meisten Modelle mit vergleichbarer Qualität.
- Native Audiosynchronisation: Audio wird im selben Durchgang generiert, was den Aufwand für die Postproduktion komplett eliminiert.
- Motivtreue: Das Quellbild verankert den ersten Frame und sichert so Identität und Komposition über den gesamten Clip hinweg.
Dieses Modell nutzt die Aurora Engine, die Text, Bilder, Videos und Audio nahtlos kombiniert. Angetrieben durch die fortschrittlichen grok xai video analysis capabilities 2026, versteht das System räumliche und zeitliche Logik tiefgreifend. Wenn Sie lernen, die richtigen Prompts zu schreiben, können Sie aus generischen Clips Videos in Kinoqualität erstellen. Falls Sie sich fragen, wie man mit grok xai effizient Videos generiert, führt Sie dieser Leitfaden durch die exakten Produktionsschritte.
So nutzen Sie Grok Image to Video: Der vollständige Workflow und die Generierungsmodi
Der Produktionszyklus ist einfach, sobald man die Struktur verstanden hat. Hier ist der komplette Schritt-für-Schritt-Workflow von der Bildeingabe bis zur finalen Auslieferung.
Schritt 1: Ihr Quellbild vorbereiten
Ihr Quellbild-Input ist die wichtigste Variable in der gesamten Pipeline. Grok fixiert es als unveränderlichen ersten Frame; daher wirken sich die hier getroffenen Kompositionsentscheidungen auf den gesamten Clip aus.
Checkliste für die Bildvorbereitung:
- Verwenden Sie unterstützte Formate: JPG, JPEG, PNG und WEBP
- Wählen Sie Ihr gewünschtes Seitenverhältnis vor dem Hochladen (16:9, 9:16, 1:1 usw.)
- Stellen Sie sicher, dass das Motiv klar definiert ist und saubere Kanten hat
- Vermeiden Sie starke Kompressionsartefakte, da diese die Bewegungskohärenz beeinträchtigen
Schritt 2: Generierungsmodus wählen
Wenn Sie Grok über die X-App oder das Web-Interface genutzt haben, sind Sie wahrscheinlich mit den Schaltflächen für den Kreativmodus vertraut. Da xAI jedoch Grok 1.5 auf High-Fidelity-Produktion ausrichtet, haben sich diese Modi weiterentwickelt:
- Normal Mode (Der aktuelle Standard): Am besten geeignet für professionelle Inhalte, Markenvideos und Produktdemos. Er liefert ausgewogene, vorhersagbare und bürotaugliche, cineastische Bewegungen. [Aktueller Status] Dies ist nun der Standardmodus auf allen Plattformen und das Kernverhalten der Engine.
- Fun Mode (Legacy / Veraltet): Ursprünglich für Social-Media-Memes und dynamisches Storytelling konzipiert, wobei Energie, Verspieltheit und übertriebene Physik Vorrang vor Realismus hatten. [Aktueller Status]Hinweis für Creator: xAI hat diesen Schalter in den neuesten UI-Updates entfernt oder versteckt, um die zeitliche Stabilität zu priorisieren. Um Ergebnisse wie im „Fun Mode“ zu erzielen, müssen Sie nun explizit actionreiche, chaotische Beschreibungen in Ihren Text-Prompt einfügen.
- Custom Mode (Fokus auf Entwickler-API): Am besten für granulare kreative Kontrolle, ermöglicht fortgeschrittenes Multi-Image-Mapping und Overrides für Kameratrajektorien.
🧑💻 Hinweis zur Entwicklerintegration: Wenn Sie mit der offiziellen xAI Developer API (x.ai/api/imagine) arbeiten, werden Sie in der Backend-Dokumentation keinen Parameter wie mode="fun" oder mode="normal" finden. Die API überspringt diese vereinfachten Front-End-Schalter vollständig und gibt Ihnen direkten Zugriff auf das Modell. Sie erzielen "Normal"- oder "Fun"-Stile nativ durch die Anpassung von Parametern wie Prompt-Formulierungen, Seed-Werten und Frame-Dimensionen.
Schritt 3: Auflösung einstellen und Entwurf erstellen
Erstellen Sie immer Prototypen in der 480p-Entwurfsauflösung, bevor Sie ein 720p-Rendering in Auftrag geben. Die Bewegungslogik, das Timing und das Prompt-Verhalten sind in beiden Pipelines identisch. Ein 0,50 USD Entwurf validiert also Ihre kreative Richtung, bevor Sie 0,70 USD für das finale Ergebnis ausgeben.
Schritt 4: Via API einreichen und Ergebnisse abrufen
Die API-basierte Generierung verwendet ein asynchrones Polling-Modell. Sie senden den Auftrag ein, erhalten eine Task-ID und fragen den Endpunkt in Intervallen ab, bis der Status als abgeschlossen zurückgegeben wird. Dies verhindert Timeout-Fehler bei längeren Generierungen und ermöglicht die parallele Batch-Verarbeitung mehrerer Anfragen.
Tipp für die Enterprise-Infrastruktur: Für Produktions-Pipelines mit hohem Durchsatz erfordert die Skalierung von Roh-API-Anfragen eine robuste Cloud-Ebene. Viele Tech-Teams betreiben diese rechenintensiven Workflows auf Atlas Cloud, um erstklassige GPU-Leistung und schnelles Edge-Caching zu nutzen. Dies hält alles in Bewegung und verhindert schmerzhafte Verzögerungen, wenn alle gleichzeitig auf die Server zugreifen._
Schritt 5: Abrufen und Bereitstellen
Sobald die Statusleiste abgeschlossen ist, erhalten Sie Ihre finale H.264 MP4-Datei. Sie ist sofort bereit für YouTube, TikTok oder Instagram, ohne dass Sie etwas konvertieren müssen.
Pro-Tipp: Die Generierungsgeschwindigkeit von 5 bis 30 Sekunden macht schnelle Iterationen möglich. Testen Sie drei bis fünf Prompt-Variationen in 480p, wählen Sie das Ergebnis mit der besten Bewegung aus und rendern Sie dann nur diese Version in 720p für die endgültige Auslieferung.
Fortgeschrittene Multi-Image-Reference-to-Video-Pipelines
Die Generierung aus einem einzelnen Bild deckt die meisten Anwendungsfälle ab. Doch wenn ein Projekt präzise kompositorische Kontrolle über Charakter, Umgebung und Requisiten gleichzeitig erfordert, ist die Reference-to-Video-Modellarchitektur der Bereich, in dem sich Grok von der Konkurrenz abhebt.
Funktionsweise des Multi-Image-Inputs
Anstatt auf einen Quell-Frame beschränkt zu sein, akzeptiert Grok zwischen 1 und 8 verschiedene Referenzbilder pro Anfrage. Sie können jedes Bild als Standard-Weblink oder als Base64-Datenstring übergeben. Dies bietet sowohl Programmierern als auch No-Code-Buildern einfache Möglichkeiten zum Hochladen von Dateien.
Das System betrachtet jedes Bild einzeln und mischt dann deren visuelle Stile, um einen flüssigen Videoclip zu erstellen. Stellen Sie es sich so vor, als würden Sie eine Szene aus Einzelteilen zusammensetzen, anstatt das Ganze zu animieren.
Aufschlüsselung der praktischen Referenzzuweisung:
| Referenz-Slot | Was übergeben? | Engine extrahiert |
| @image1 | Charakterporträt oder Gesicht | Identitätssicherung, Gesichtsgeometrie |
| @image2 | Standort oder Umgebungsaufnahme | Hintergrundtiefe, Lichtkontext |
| @image3 | Requisite oder Objektnahaufnahme | Objekttextur, Skalierung, Platzierung |
| @image4 bis @image8 | Zweitcharaktere oder Stil-Anker | Charakterkonsistenz in der Szene |
Sequenzielles Prompt-Tagging zur Identitätssicherung
Das Tagging-System ist die kritische operative Ebene. Referenzieren Sie innerhalb Ihres Text-Prompts jedes Bild explizit mit sequenziellen Tags:
„@image1 geht durch @image2 und trägt dabei @image3, während @image4 aus dem Hintergrund zuschaut.“
Diese Syntax teilt der Aurora Engine genau mit, welchem visuellen Element jedes Prompt-Segment zugeordnet ist. Ohne Tagging mittelt das Modell die visuellen Merkmale über alle Inputs hinweg, was die Identitätssicherung verwässert und zu vermischten, zweideutigen Ergebnissen führt.
Regeln für zuverlässiges Tagging:
- Taggten Sie immer in der Reihenfolge, in der die Bilder im API-Payload übermittelt werden.
- Halten Sie Charakterreferenzen auf ein einzelnes, sauberes Porträt pro Slot isoliert.
- Vermeiden Sie überlappende visuelle Merkmale über die Slots hinweg (z. B. verwirren zwei Bilder mit ähnlichem Hintergrund die Tiefenzuweisung).
- Verwenden Sie dasselbe Tag konsistent, wenn ein Charakter in mehreren Aktionen innerhalb des Prompts erscheint.
Wann die Multi-Image-Pipeline zu nutzen ist
Multi-Image-Input ist nicht immer das richtige Werkzeug. Reservieren Sie es für Produktionen, die wirklich eine kompositorische Kontrolle über verschiedene Quellen erfordern, wie etwa Marken-Charakterserien, cineastische Kurzfilme oder Product-Placement-Videos, bei denen Umgebung, Talente und Requisiten von verschiedenen Drehtagen stammen. Für einfachere Animationen ist ein einzelnes, gut komponiertes Quellbild immer schneller und günstiger in der Iteration.
Kreative Prompting-Frameworks für Grok Image to Video
Das Beherrschen der Frage, wie man mit grok xai Videos generiert, hat weniger mit dem Beschreiben dessen zu tun, was Sie sehen, als vielmehr damit, die Veränderungen zu steuern. Da die Aurora Engine Text autoregressiv verarbeitet, bedeutet dies, dass sie Ihren Prompt von links nach rechts sequenziell liest. Ereignisse, die zuerst geschrieben werden, werden zuerst im Clip ausgeführt. Details, die am Ende vergraben sind, werden möglicherweise nie gerendert.
Die Blueprint-Formel
Jeder effektive Prompt folgt dieser sequenziellen Prompt-Struktur:
[Bewegungskern des Subjekts] + [Kameratrajektorie/Linsenaktion] + [Lichtwechsel/Atmosphärischer Übergang]
Beispiel:
„Mann hebt seine Kaffeetasse langsam, Dolly-Zoom-Effekt schiebt sich auf sein Gesicht zu, Morgenlicht intensiviert sich zu warmem Gold, während Dampf aufsteigt.“
Die goldenen Regeln des Grok-Promptings
Direkte Bewegung, keine Beschreibung
Das Modell weiß bereits, was auf Ihrem Quellbild zu sehen ist. Bewegungsbeschreibungen sind Ihre einzige Aufgabe. Sagen Sie Grok, was sich bewegt, wie es sich bewegt und in welche Richtung. Das Beschreiben statischer Elemente verschwendet Token-Budget für die falsche Instruktionsebene.
Widersprechen Sie niemals dem Quellbild
Ihr Input-Bild ist Gesetz. Wenn Ihr Subjekt eine sitzende Frau ist, wird der Prompt „rennt durch einen Wald“ zu einem inkohärenten Ergebnis führen. Stimmen Sie jede Aktion direkt auf die bestehende Körperhaltung und Umgebung ab.
Überspringen Sie negative Prompts
Das Video-Modell von Grok ignoriert negative Prompt-Strings weitgehend. Verwenden Sie stattdessen explizite positive Verhaltensanweisungen.
Führen Sie mit der Kameraabsicht
Kamera-Tracking-Shots und Bewegungsanweisungen, die früh im String platziert werden, geben der Engine Zeit, die cineastische Rahmung zu etablieren, bevor die Bewegung ihren Höhepunkt erreicht.
| Prompt-Element | Beispiel-Syntax |
| Subjektbewegung | „dreht langsam den Kopf nach links“ |
| Kamera-Tracking-Shots | „Arc-Shot um das Subjekt herum“ |
| Dolly-Zoom-Effekt | „Dolly-Push auf die Augen zu“ |
| Atmosphärischer Wechsel | „Nebel zieht auf, Licht wird blau“ |
Kreative Prompting-Formeln, die um diese Struktur herum aufgebaut sind, übertreffen konsequent längere, deskriptive Prompts, die die Bewegungsabsicht im Text vergraben.
Anwendungsfälle aus der Praxis: Von E-Commerce bis Pre-Visualization
Grok Image to Video 1.5 ist kein reines Spielzeug. Besonders in drei Branchen eliminiert es unter Nutzung der grok xai video analysis capabilities 2026 Produktionsschritte, die zuvor ganze Teams, spezielle Software oder tagelange Rendering-Zeit erforderten.
Branchen-Anwendungsmatrix
| Branche | Input | Output | Hauptvorteil |
| E-Commerce | Produktfotografie | Dynamisches Werbevideo mit Voiceover | Kein Studio-Shooting erforderlich |
| Unterhaltung | 2D-Konzeptkunst | 24fps Pre-Viz-Reel mit SFX | Validiert Vision vor dem schweren Rendering |
| Social Media | Einzelnes Markenbild | Fünf plattformfertige Hook-Variationen | Schnellere Iteration als bei jedem Konkurrenten |
E-Commerce Produktpräsentationen
E-Commerce Produktpräsentationen sind die unmittelbarste kommerzielle Anwendung. Ein einzelnes Studiofoto eines Produkts wird zu einem hochwertigen, rotierenden Lifestyle-Clip mit nativer Audiosynthese, die im selben Durchgang automatisierte Voiceovers generiert. Marken eliminieren Reshoots komplett und konvertieren bestehende Bildbibliotheken in kommerzielle Marketing-Assets, die bereit für bezahlte Platzierungen auf Meta, TikTok und Google sind.
Fallstudie: 9:16 High-Velocity Footwear Commercial
📸 Input-Payload-Konfigurationen:
- @image1 (Produktanker): Ein kontrastreiches statisches Foto eines neon-grünen Tech-Sneakers mit einer transparenten Air-Cushion-Gel-Mittelsohle und starrem Branding.
- @image2 (Umgebungsanker): Ein dunkler, stimmungsvoller Raum mit schwebenden kristallinen Fragmenten und einem reflektierenden Liquid-Metal-Boden.
Pre-Visualization Konzeptkunst
Film- und Spielestudios nutzen Grok für Pre-Visualization Konzeptkunst-Pipelines. Rohe Charakter-Skizzen oder Umgebungsillustrationen werden zu flüssigen 24fps-Proof-of-Concept-Reels mit synchronisierten Soundeffekten animiert. Regisseure kommunizieren Bewegungsabsichten an ihre Teams, bevor Budgets für schwere CGI-Rendering-Pipelines bereitgestellt werden, was den Review-Zyklus der Vorproduktion erheblich verkürzt.
Mit der xAI Aurora Engine können Pre-Viz-Supervisoren cineastische Lichtstresstests und Kamera-Tracking-Benchmarks in einem einzigen, asynchronen API-Durchgang ausführen.
Fallstudie: Multi-Asset-Lichtwechsel in der Umgebung
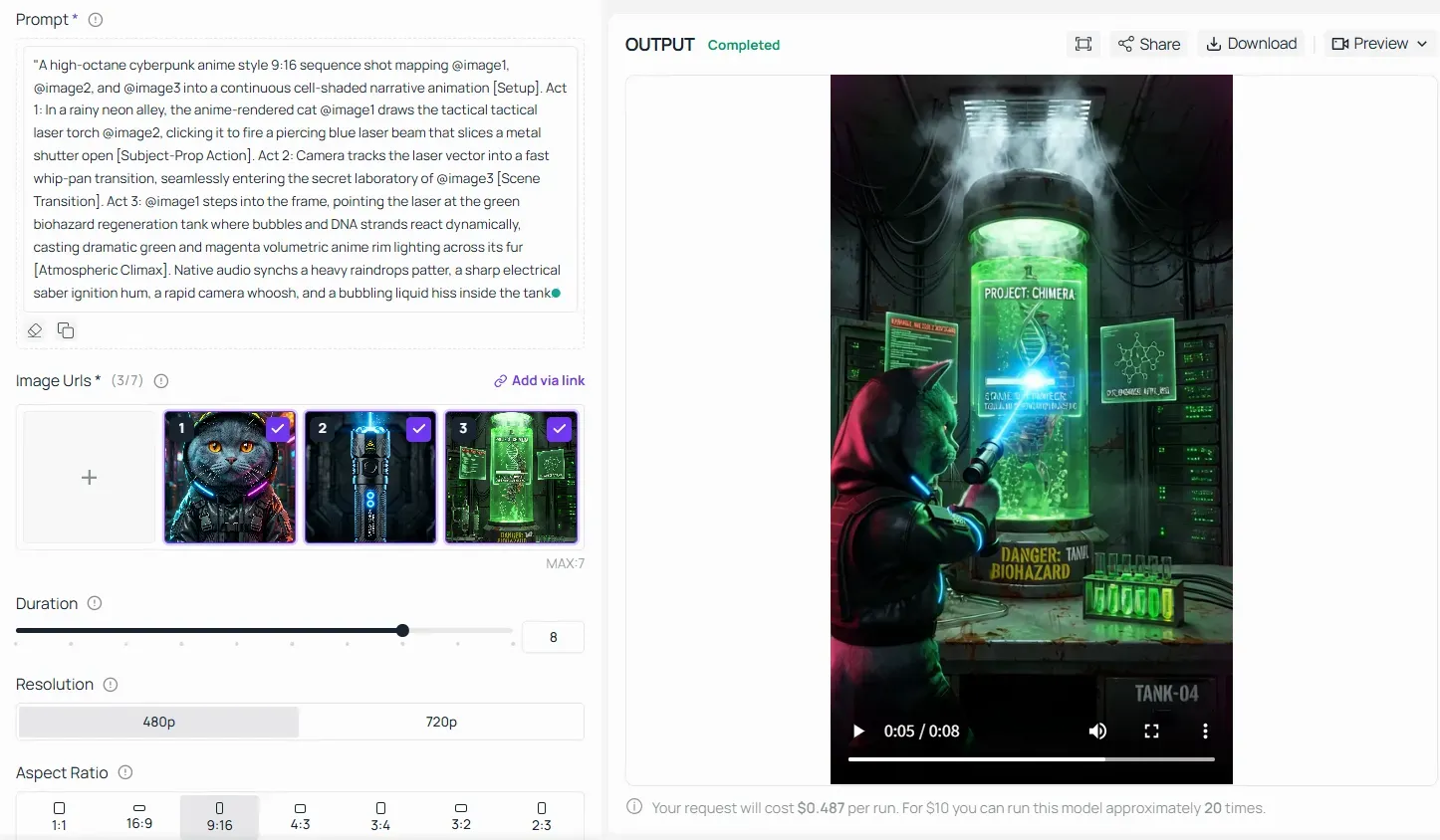
Um zu verstehen, wie Grok 1.5 plötzliche, kontrastreiche atmosphärische Änderungen bewältigt, ohne die Motivtreue zu verlieren, analysieren Sie diese cineastische Action-Pre-Viz-Sequenz:
📸 Input-Payload-Konfigurationen:
- @image1 (Charakter-Asset): Eine hochdetaillierte konzeptionelle Zeichnung einer weiblichen kybernetischen Soldatin mit violetten Haaren und einem leuchtenden roten optischen Implantat.
- @image2 (Umgebungs-Asset): Eine nasse, detaillierte Sci-Fi-Gasse voller hyperdichter Neon-Schilder, überlappender Stromkabel und regnerischer Pfützen.
- @image3 (Requisiten-Asset): Ein futuristisches elektromagnetisches Sturmgewehr mit blauen elektrischen Entladungsleitungen.
Social Media Content Creation
Social Media Content Creation in großem Maßstab ist der Bereich, in dem die Generierungsgeschwindigkeit den klarsten ROI liefert. Schnelle Editier-Setups ermöglichen es, fünf verschiedene Video-Hooks für TikTok, Reels oder Shorts in der Zeit zu testen, die andere Tools benötigen, um nur ein Video zu erstellen. Die vertikalen 9:16-Dateien sind sofort perfekt dimensioniert, sodass Sie sie direkt posten können, ohne etwas zuschneiden zu müssen.
Fallstudie: 9:16 Chronologischer Lifestyle-Vlog
Die ultimative Hürde für generative KI in der sequenziellen Videoproduktion ist die langfristige kausale Konsistenz. Standard-Engines haben normalerweise Probleme, wenn ein Subjekt eine mehrstufige körperliche Aufgabe ausführt, z. B. Schürze anziehen → Lebensmittel waschen → unter einem Messer schneiden → Pfannenrühren. Normalerweise verzerren sich Charaktere über die Aufnahmen hinweg, oder die Physik der Hand-zu-Objekt-Interaktion bricht zusammen.
Analysieren Sie, wie der Custom Mode von Grok 1.5 eine hyperkomplexe, 4-stufige chronologische Pipeline in einem einzigen Ausführungsdurchgang verarbeitet:
📸 Input-Payload-Konfigurationen:
- @image1 (Charakter-Asset): Ein kontrastreiches Porträt einer rundgesichtigen Britisch Kurzhaar-Katze mit leuchtend orangen Augen und dichtem blaugrauen Fell.
- @image2 (Küchen-Asset): Eine gemütliche, sonnendurchflutete Cottage-Core-Küche mit hellen Holz-Arbeitsplatten, weißen Fliesen, Messingarmaturen und einem Miniatur-Gasherd.
Fehlerbehebung bei Grok Image to Video und häufige Fehler
Die meisten Fehler bei der Grok Imagine Video-Generierung lassen sich auf drei Grundursachen zurückführen: ein schlechtes Input-Bild, ein schlecht strukturierter Prompt oder ein Engpass in der Infrastruktur. So diagnostizieren und beheben Sie jeden Fehler schnell.
Kurze Diagnosereferenz
| Symptom | Grundursache | Lösung |
| Charakter verformt oder löst sich auf | Prompt widerspricht Quellbild | Richten Sie alle Aktionen an der bestehenden Körperhaltung aus |
| Subjekt verliert Gesichtsdetails | Unscharfer oder kontrastarmer Input | Verwenden Sie nur hochwertige Input-Frames |
| Bewegung wird mitten im Clip ignoriert | Prompt zu lang, Aktionen am Ende abgeschnitten | Platzieren Sie kritische Bewegungsanweisungen am Anfang |
| Generierung blockiert oder Warteschlange | Kapazitätsgrenze im geteilten Portal | Wechseln Sie zur serverlosen Entwickler-API |
Fehlerbehebung bei Identitätsauflösung
Der am häufigsten gemeldete Fehler ist die Auflösung des Charakters mitten im Clip. Die Lösung für die Identitätsauflösung ist einfach: Prüfen Sie zuerst Ihr Quellbild. Die Aurora Engine verlässt sich auf knackige Pixeldaten im ersten Frame, um ihr Token-Tracking zu initialisieren. Unscharfe Fotos, ungleichmäßige Beleuchtung oder starke JPEG-Kompression mindern diesen Anker. Überprüfen Sie neben der Bildqualität, dass Ihr Prompt keine Subjekte, Umgebungen oder Aktionen einführt, die dem Quellbild widersprechen. Widersprüche lassen die Generierungskohärenz sofort zusammenbrechen.
Einschränkungen der Warteschlange
Einschränkungen der Warteschlange treten am häufigsten in geteilten öffentlichen Portalen zu Spitzenzeiten auf. Das Verschieben Ihres Workflows auf eine serverlose Entwickler-API-Plattform eliminiert dies vollständig.
Indem Sie Ihre Generierungs-Pipelines über KI-Infrastruktur auf Enterprise-Niveau wie Atlas Cloud betreiben, können Sie Anfragen über dedizierte Hochleistungs-GPU-Instanzen leiten. Diese Architektur eliminiert geteilte Warteschlangenverzögerungen, beseitigt Hardware-Engpässe und stellt durch einen „Privacy by Design“-Ansatz die Datensicherheit für sensible kommerzielle Video-Assets auf Unternehmensebene sicher.
Token-Rendering-Beschränkungen
Token-Rendering-Beschränkungen sind eine direkte Konsequenz der autoregressiven Architektur. Die Engine verarbeitet Ihren Prompt sequenziell und stoppt, wenn der Clip endet, nicht, wenn Ihr Text endet. Jede Bewegungsanweisung, die in einem langen Prompt vergraben ist, läuft Gefahr, nie ausgeführt zu werden. Halten Sie Prompts prägnant und platzieren Sie jede kritische Aktion in der ersten Hälfte Ihres Strings.
Fazit: ROI steigern mit Grok Image to Video
Grok 1.5 Image to Video hat sich von einer Social-Media-Spielerei zu einem Produktionstool auf Enterprise-Niveau gewandelt. Durch die Beherrschung von sequenziellem Tagging und das Verständnis der autoregressiven Natur der Aurora Engine können Creator und Entwickler Engpässe in der Postproduktion komplett umgehen.






