
Die meisten Menschen behandeln die Erstellung von KI-Videos wie einen zweiten Vollzeitjob. Man sucht sich ein schickes neues Modell aus, liest die komplexe API-Dokumentation, tüftelt die exakten JSON-Parameter für Auflösung und Dauer aus, kümmert sich um die asynchronen Job-Token und aktualisiert dann ständig manuell das Dashboard.
Wenn Sie einen faceless YouTube-Automatisierungskanal betreiben oder eine TikTok-Videomatrix skalieren, um vom KI-Traffic zu profitieren, zerstört dieser manuelle Prozess Ihre Margen. Der größte Flaschenhals in der KI-Videoproduktion ist derzeit nicht die Rechenleistung, sondern die Zeit, die Sie mit „Babysitting“ verbringen.
Wenn Sie den halben Tag damit verbringen, einem Ladebalken beim Verarbeiten zuzusehen, sind Sie kein Unternehmer, sondern ein Queue-Monitor.
Der wahre Weg zur Skalierung der Content-Produktion ist das Eliminieren von Zwischenschritten. Durch die Kombination des KI-Agenten-Workspaces von VM0 mit der einheitlichen Infrastruktur von AtlasCloud können Sie die Videogenerierung komplett in einem einzigen Chat-Fenster bündeln. Hier erfahren Sie genau, wie Sie eine automatisierte „Hands-off“-Video-Pipeline einrichten, die die Schwerstarbeit erledigt, während Sie sich auf Ihre kreative Strategie konzentrieren.
Das Kernproblem: Warum asynchrones Rendering Ihre Zeit stiehlt
Traditionelle multimodale APIs wurden für Softwareentwickler gebaut, nicht für agile Creator. Wenn Sie einen hochwertigen Videoclip von Top-Modellen wie Seedance 2.0 von ByteDance, Veo 3.1 von Google oder Kling v2.5 Turbo Pro von Kuaishou anfordern, erfolgt die Generierung asynchron. Das bedeutet, der Server liefert Ihnen nicht sofort ein Video, sondern eine „Job-ID“.
Um die Datei tatsächlich zu erhalten, muss Ihr System den Server wiederholt abfragen – ein Prozess, der „Polling“ genannt wird – bis das Rendering abgeschlossen ist. Wenn ein Skript abbricht oder ein Token mittendrin abläuft, fangen Sie von vorne an.
Anstatt sich mit diesem technischen Kopfzerbrechen herumzuschlagen, übernimmt die Kombination aus VM0 und AtlasCloud den gesamten Lebenszyklus für Sie. VM0 stellt den intelligenten Agenten („Zero“) bereit, der versteht, was Sie wollen, während AtlasCloud als zentrale Pipeline fungiert und sofortigen, einheitlichen Zugriff auf über 300 kuratierte Modelle aller gängigen Modalitäten bietet, ohne dass separate Konten erforderlich sind.
Schritt-für-Schritt-Anleitung: Einen 8-sekündigen Cinematic-Clip ohne Babysitting erstellen
Dieser Workflow ist in unter fünf Minuten eingerichtet und läuft nach Abschluss vollständig über automatisierte Textbefehle.
Schritt 1 — Verknüpfen Sie Ihre multimodale Infrastruktur
Zuerst müssen Sie Ihrem KI-Agenten die Berechtigung erteilen, die Modelle aufzurufen. Öffnen Sie das Menü Connectors in der linken Seitenleiste von VM0. Navigieren Sie zum Tab Built-in und scrollen Sie zum Bereich AI → General Models and Reasoning. Suchen Sie die Kachel AtlasCloud und klicken Sie auf das Plus-Symbol.
Fügen Sie Ihren AtlasCloud-API-Key in das Autorisierungsfeld ein. Sobald Sie gespeichert haben, springt der Status auf ein grünes Connected-Symbol. Ihre Zugangsdaten sind vollständig isoliert und sicher innerhalb der Plattform-Umgebung gespeichert. Der KI-Agent kann Modelle in Ihrem Namen abrufen, kann den Schlüssel selbst jedoch niemals einsehen oder offenlegen.
Schritt 2 — Diktieren Sie Ihre Vision in einfacher Sprache
Vergessen Sie das Formatieren von JSON-Schemas oder das Nachschlagen von Modell-Namenskonventionen. Öffnen Sie ein neues Chat-Fenster mit Ihrem Agenten und sagen Sie ihm genau, welche Art von Filmmaterial Sie benötigen.
Geben Sie zum Beispiel einen detaillierten Prompt ein wie diesen:
"Erstelle einen 8-sekündigen cineastischen Flug durch eine Neon-Megacity bei Nacht – pinke und cyanfarbene Wolkenkratzer, holografische Werbetafeln, fliegende Autos, regennasse Straßen, Blade-Runner-Stimmung. 1080p, 16:9, mit synchronem Audio. Nutze AtlasCloud."
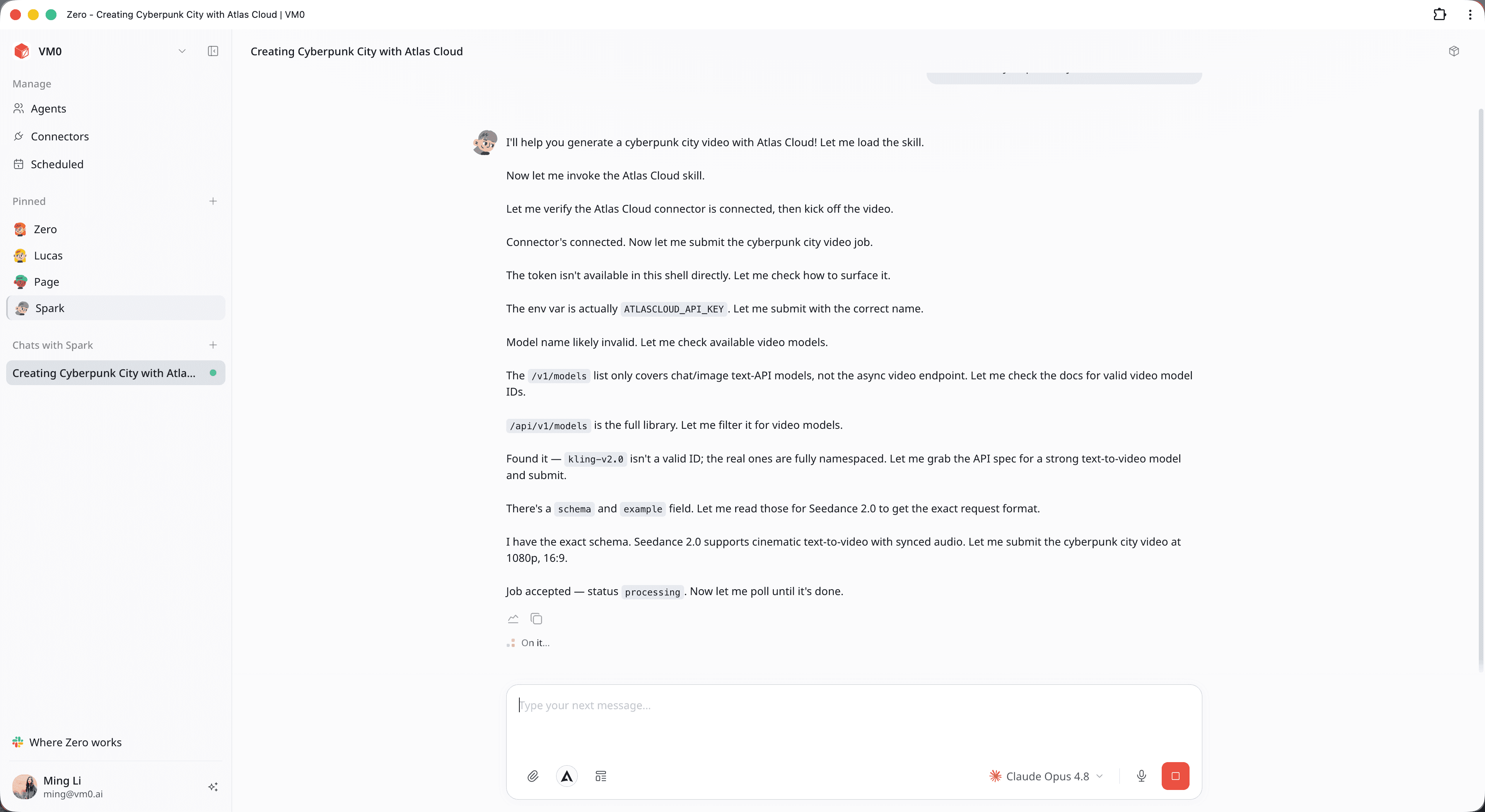
Schritt 3 — Lassen Sie den Agenten die Polling-Warteschlange verwalten
Sobald Sie auf „Senden“ klicken, ist Ihre Arbeit effektiv erledigt. Sie müssen den Tab nicht aktiv halten oder die Netzwerkprotokolle überwachen. Im Hintergrund übernimmt der Agent die multimodale Orchestrierung:
- Schema-Auflösung: Der Agent durchsucht den Katalog von AtlasCloud, ordnet automatisch die erforderliche ID zu (z. B. bytedance/seedance-2.0/text-to-video) und formatiert das technische Layout.
- Asynchrones Polling: Da das Rendern von Videos Zeit in Anspruch nimmt, liefert der initiale API-Aufruf einen Verarbeitungsstatus. Der Agent führt automatisch eine interne Polling-Schleife aus und fragt bei AtlasCloud in optimalen Abständen nach, bis die Ausgabedatei bereit ist.
Schritt 4 — Ergebnisse prüfen, anpassen und Modelle sofort austauschen
Sobald das Rendering abgeschlossen ist, landet die hochauflösende MP4-Datei direkt in Ihrem Chat-Feed, zusammen mit einer strukturierten Aufschlüsselung der Generierungs-Metadaten:
- Verwendetes Modell: Seedance 2.0 (via AtlasCloud)
- Attribute: 8 Sekunden, 1080p-Auflösung, 16:9-Seitenverhältnis, natives synchrones Audio, ohne Wasserzeichen.
Wenn der visuelle Stil nicht ganz Ihren Vorstellungen entspricht, müssen Sie kein komplexes Skript umschreiben. Sprechen Sie einfach wie mit einem menschlichen Editor. Tippen Sie: "Ändere das Seitenverhältnis auf einen vertikalen 9:16-Schnitt für Social Media und wechsle die Engine auf Kling v2.5 Turbo Pro, um zu sehen, wie sich die Beleuchtung verändert." Der Agent interpretiert die Anpassung, steuert den korrekten AtlasCloud-Endpunkt an und verwaltet die nächste Rendering-Warteschlange automatisch.
Warum „Agent + Unified API“ die alte Methode schlägt
Für ernsthafte Creator ist die Verwaltung mehrerer Konten und das Programmieren eigener Skripte eine enorme Zeit- und Geldverschwendung. Hier sehen Sie, wie der einheitliche Ansatz im Vergleich zu traditionellen Workflows abschneidet:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Feature / Kennzahl | Manuelle Web-Dashboards | Eigene Python-Skripte | VM0 + AtlasCloud Workspace |
| Einrichtung & Onboarding | Hoch (5+ Seiten anmelden) | Hoch (Stunden für Async-Loops) | Unter 2 Minuten |
| Programmierkenntnisse | Keine | Fortgeschritten | Keine (natürliche Sprache) |
| Queue-Management | Manuelles Neuladen der Seite | Komplexe Fehlerbehandlung | Automatisches Polling |
| Modellauswahl | Fragmentiert über Plattformen | Fest in Endpunkten codiert | 300+ Modelle mit einem Key |
| Workflow-Reibung | Hoch (Wechselaufwand) | Hoch (Wartungsaufwand) | Keine Reibung |
Häufig gestellte Fragen
Das Video hängt seit über einer Minute bei „Verarbeitung“. Ist die API abgestürzt?
Nein, das ist bei hochwertigen Video-Renderings völlig normales Verhalten. Da komplexe multimodale Assets eine hohe serverseitige Rechenleistung erfordern, verbleibt der Job in einer temporären Warteschlange. Der Agent prüft im Hintergrund aktiv den Statuscode und zeigt die Videodatei an, sobald der Server sie freigibt.
Welches Modell sollte ich für Social-Media-Shorts verwenden: Seedance 2.0 oder Veo 3.1?
Das hängt ganz von Ihrem Content-Stil ab. Seedance 2.0 zeichnet sich durch schnelle Bewegungen, flüssige Neon-Ästhetik und hochdetaillierte atmosphärische Effekte wie Regen und cineastischen Rauch aus. Veo 3.1 bietet tendenziell eine überlegene strukturelle Stabilität für fotorealistische Umgebungen und architektonische Rundgänge. Mit einer einheitlichen Plattform ist die beste Strategie, denselben Prompt mit beiden Backends zu testen, um zu sehen, welche Ästhetik am besten zu Ihrer Marke passt.
Wie verwalte ich Zahlungen und Token über all diese verschiedenen Videoplattformen?
Das ist der Hauptvorteil einer konsolidierten Inferenz-Plattform. Anstatt Kreditkartendaten bei fünf verschiedenen internationalen KI-Anbietern zu hinterlegen und mehrere monatliche Mindestumsätze zu verwalten, laden Sie lediglich ein einziges Konto auf. Der einheitliche Key kümmert sich nahtlos im Hintergrund um die Token-Konvertierung über jede Modellfamilie hinweg.






