
Bei der Entwicklung von KI-Anwendungen oder dem Prototyping von Agenten-Workflows müssen wir häufig mit mehreren Large Language Models experimentieren, um die optimale Lösung zu finden. Da jedoch verschiedene Anbieter unterschiedliche API-Strukturen und Protokolle verwenden, erfordert der Wechsel zwischen ihnen in der Regel mühsames Refactoring des Codes und ständige Updates der Backend-Logik.
AIClient2API löst genau dieses Problem. Es fungiert als intelligente Proxy-Schicht, die Client-Anfragen von Plattformen wie Gemini CLI, Antigravity, Codex, Grok und Kiro simuliert und diese in eine einzige, standardisierte, OpenAI-kompatible API-Schnittstelle kapselt. Neben der Protokoll-Vereinheitlichung bietet es ein Web-UI-Dashboard zur Überwachung des Live-Status jedes Knotens.
Hauptfunktionen
- Kostenloser Modellwechsel: Schreiben Sie Ihren Integrationscode einmal im Standard-OpenAI-SDK-Format und wechseln Sie die Backend-Anbieter dynamisch, ohne Ihre Geschäftslogik ändern zu müssen.
- Visuelle Verwaltungskonsole: Enthält ein Web-UI-Dashboard für Echtzeit-Konfigurationsmanagement, Gesundheitsüberwachung, API-Tests über ein integriertes Playground-Tool sowie eine Prüfung von Anfrage-Logs.
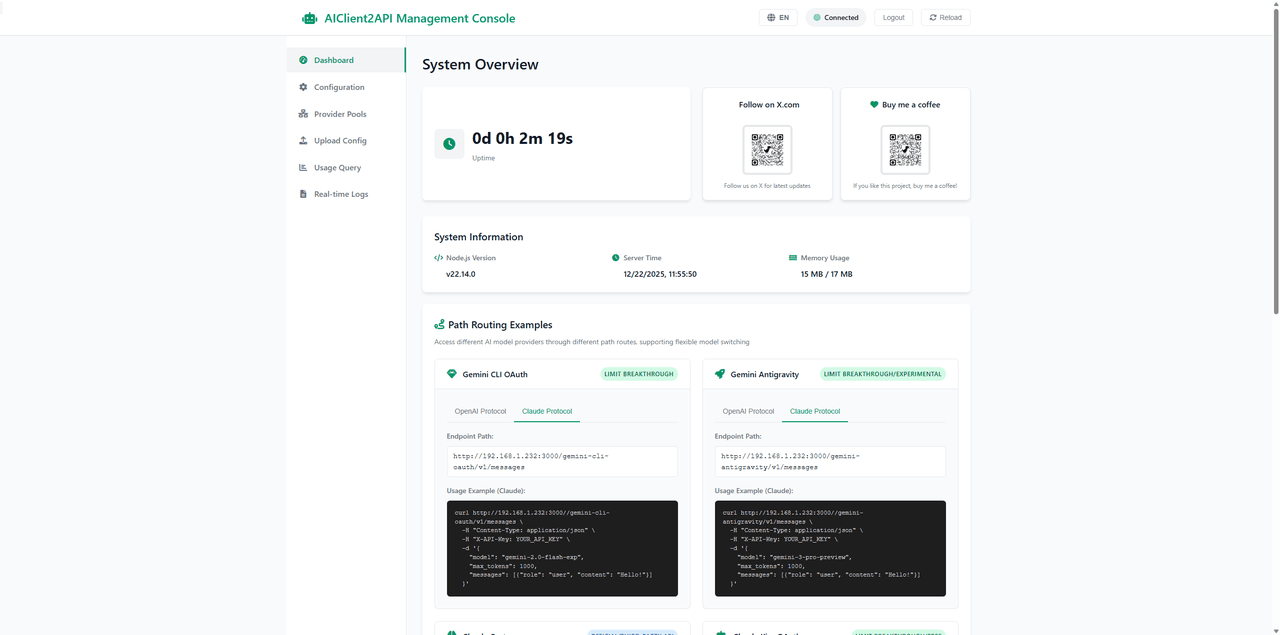
Technische Architektur & Implementierung
Das Projekt basiert auf einer AI-First-Modulararchitektur, die auf Node.js aufbaut, um die Protokollübersetzung zu handhaben und eine hohe Verfügbarkeit zu gewährleisten:
plaintext1[ Your Application (Cherry-Studio / Cline / Custom Code) ] 2 │ (Standard OpenAI / Claude Request) 3 ▼ 4 ┌─────────────────────────────┐ 5 │ AIClient2API Gateway │ 6 └──────────────┬──────────────┘ 7 │ 8 ┌─────────────┴─────────────┐ 9 ▼ ▼ 10 ┌──────────────┐ ┌──────────────┐ 11 │ Adapters │ │ Provider Pool│ 12 └───────┬──────┘ └───────┬──────┘ 13 │ │ (Health Check / Cooldown) 14 ▼ ▼ 15 ┌──────────────┐ ┌──────────────┐ 16 │ TLS Sidecar │ │ Failover & │ 17 │ (Go uTLS) │ │ Fallback │ 18 └───────┬──────┘ └───────┬──────┘ 19 │ │ 20 └─────────────┬─────────────┘ 21 ▼ 22 [ Backends: Gemini, Grok, Kiro...]
1. Strategie- und Adapter-Muster
Wenn eine Anfrage das Gateway erreicht, identifiziert das System den Ziel-Modellanbieter und leitet sie über einen spezifischen Service-Adapter weiter. Der Adapter übersetzt Standard-OpenAI- oder Claude-Payloads in die exakte Struktur, die vom Upstream-Client benötigt wird (z. B. Geminis interne CLI-Struktur oder Groks Endpunkte), und verarbeitet dabei nahtlos sowohl Standard- als auch Streaming-Antworten (text/event-stream).
2. Intelligente Provider-Pools & Fallback-Ketten
Um Zuverlässigkeit auf Produktionsebene zu gewährleisten, verwaltet der Proxy einen Pool von Konten und Endpunkten:
- Automatisierte Gesundheitsprüfungen & Cooldown: Das System führt regelmäßige Heartbeats durch. Wenn ein Knoten ausfällt oder ein 429-Limit (Too Many Requests) erreicht, wird er automatisch in eine temporäre Cooldown-Warteschlange verschoben und umgangen.
- Typübergreifender Fallback: Wenn das Kontingent eines kompletten Anbietertyps erschöpft ist, kann das Gateway Anfragen entlang einer vorkonfigurierten Fallback-Kette leiten (z. B. Fallback von gemini-cli-oauth auf gemini-antigravity), sofern die Protokolle übereinstimmen.
3. TLS-Fingerprint-Mimikry (TLS Sidecar)
Bestimmte Upstream-Dienste erzwingen strenge Netzwerkprüfungen und blockieren Anfragen, die nicht mit Browser-TLS-Fingerprints übereinstimmen. Um dies zu lösen, integriert das Projekt einen TLS Sidecar-Proxy, der in Go (unter Verwendung von uTLS) geschrieben wurde. Er emuliert Standard-Chrome-TLS-Handshakes und wickelt automatisch HTTP/2-Aushandlungen ab, um 403 Forbidden-Fehler zu vermeiden.
Ökosystem-Integration: Native AtlasCloud-Unterstützung
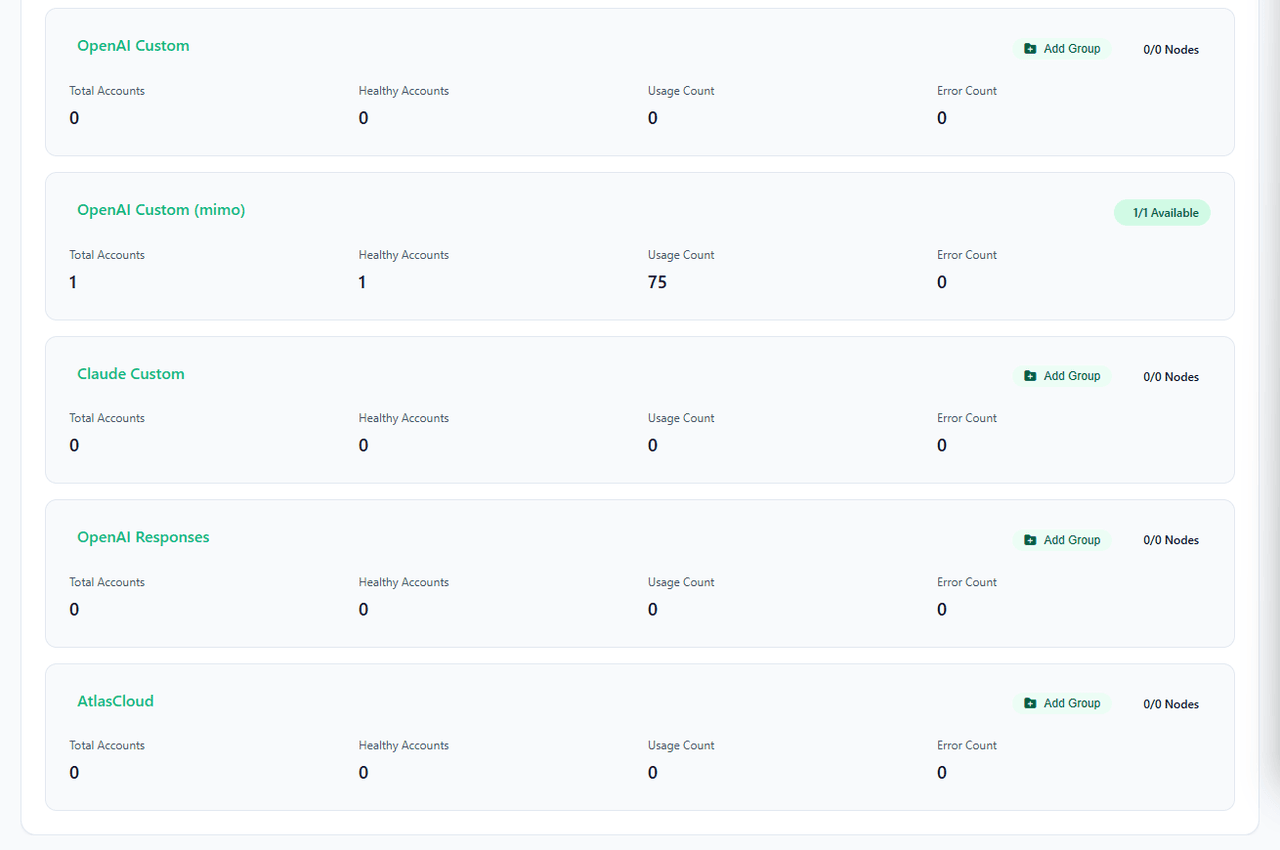
In aktuellen Updates hat AIClient2API eine native Anbieterunterstützung für AtlasCloud eingeführt, eine All-in-One Plattform für multimodale KI-Inferenz.
AtlasCloud bündelt hochgradig kosteneffiziente Modelle wie Qwen 3.6, DeepSeek v4 pro, Kimi k2.6 und GLM 5.1 unter einem einzigen Endpunkt. Die Integration von AtlasCloud in Ihren AIClient2API-Pool bietet spezifische Vorteile:
- Nahtloser Wechsel & Stabiler Durchsatz: Sie können ohne Reibungsverluste zwischen den Reasoning-Fähigkeiten von DeepSeek, der Sprachverarbeitung von Qwen und multimodaler Generierung wechseln. Die zugrunde liegende Unternehmensinfrastruktur garantiert stabile Gleichzeitigkeitsraten.
- Direkt einsetzbare Vorlagen: Das Repository enthält Konfigurationsvorgaben in der provider_pools.json.example sowie dedizierte Router-Pfade, mit denen Sie sofort loslegen können.
Dieses Setup ist äußerst vorteilhaft für Entwickler, die an der kostengünstigen Coding Plan Promotion von AtlasCloud teilnehmen, um den Infrastrukturaufwand zu minimieren.
Erste Schritte
- Bereitstellung via Docker:
- Bash
plaintext1docker run -d -p 3000:3000 -p 8085-8086:8085-8086 -p 1455:1455 -p 19876-19880:19876-19880 --restart=always -v "your_path/configs:/app/configs" --name aiclient2api justlikemaki/aiclient-2-api
- Konfiguration via Web-UI: Besuchen Sie http://localhost:3000 (Standardpasswort: admin123), um Ihre Anmeldedaten hinzuzufügen und Ihre Anbieter visuell zu verwalten.
- Traffic weiterleiten: Richten Sie Ihren bevorzugten KI-Desktop-Client oder Ihr Backend-SDK auf Ihre lokale Gateway-Instanz aus.
Für vollständige Implementierungsdetails, Dokumentationen und erweiterte Konfigurationsoptionen besuchen Sie das GitHub-Repository.






