Tienes una foto y quieres que la IA la transforme a una versión en bikini, lencería o algo más explícito, manteniendo el rostro. Probaste Midjourney: rechazada. Probaste DALL-E: suavizada y filtrada. Probaste Stable Diffusion con la configuración predeterminada: bloqueada por el filtro de seguridad antes incluso de empezar la generación.
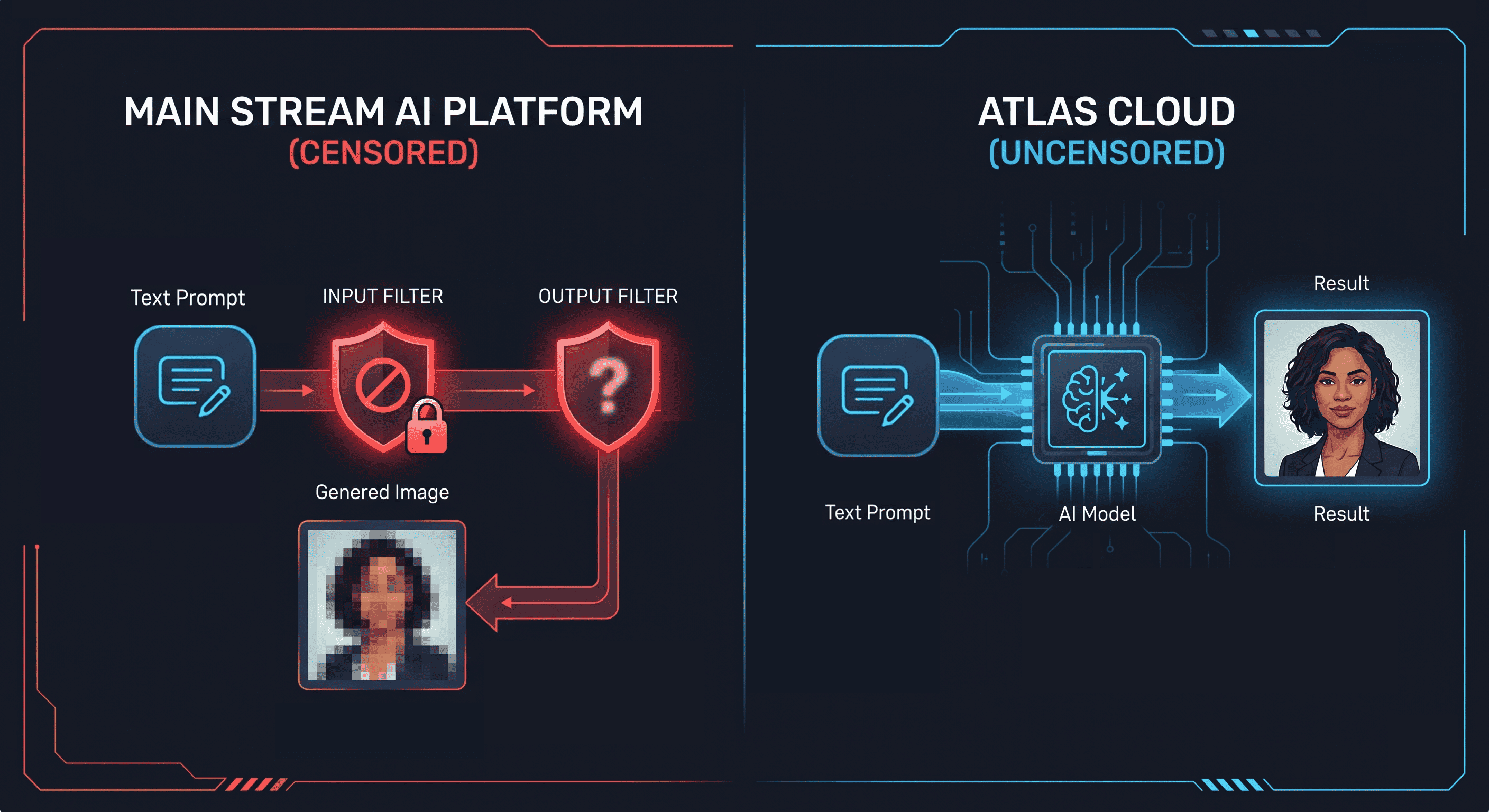
Esto no es un fallo de las herramientas; es una decisión de diseño. Todas las plataformas convencionales aplican una capa de moderación de contenido a nivel de modelo. Esa capa es a lo que se refiere la palabra "sin censura" (uncensored) cuando la gente busca una IA de imagen a imagen sin censura. La herramienta existe. La cuestión es qué modelo preserva la identidad correctamente mientras el contenido cambia.
Por qué los generadores de IA de imagen a imagen convencionales bloquean el contenido sin censura
Toda gran plataforma de generación de imágenes aplica filtros de contenido en dos niveles: la capa de entrada del prompt y la capa de salida del modelo. Cuando envías un prompt con términos NSFW (no apto para el trabajo), el filtro de entrada lo rechaza antes de que el modelo se ejecute. Si un prompt logra pasar, el filtro de salida detecta la imagen generada y suprime o difumina el resultado.
No es una falta de capacidad. Stable Diffusion, la misma arquitectura que potencia la mayoría de las herramientas de imagen a imagen, no tiene restricciones técnicas en cuanto a resultados NSFW. El filtrado es aplicado por los operadores de la plataforma sobre el modelo. Elimina el filtro y el modelo subyacente generará el contenido.
Para obtener una comparativa clasificada de los mejores generadores capaces de producir contenido NSFW por precio y eliminación de filtros, la guía de los mejores generadores de imágenes NSFW sin censura cubre opciones de API en la nube y locales en todos los niveles.
"Sin censura" en el contexto de un generador de IA de imagen a imagen significa que se ha eliminado la capa de moderación de contenido. El modelo procesa el prompt y la imagen sin intervención activa sobre qué contenido se genera. El catálogo de imagen a imagen de Atlas Cloud ejecuta modelos en esta configuración, incluyendo la familia Seedream, diseñada específicamente para la edición de retratos con preservación facial.
El segundo problema —la pérdida de la identidad facial durante la transformación— es independiente del filtrado de contenido. Es un problema de entrenamiento del modelo. De esto trata el resto de esta guía.
Por qué el rostro cambia en la generación de IA de imagen a imagen sin censura y cómo evitarlo
Cuando subes una foto y escribes un prompt para una transformación de contenido, el modelo no sabe qué partes de la imagen están restringidas. Aplica cambios globalmente según el peso semántico. El rostro, al ser la región de mayor peso semántico en un retrato, recibe mucha atención del modelo, lo que significa que se vuelve a dibujar junto con todo lo demás.
Dos variables controlan cuánto cambia el rostro:
guidance_scale determina qué tan agresivamente sigue el modelo el prompt frente a cuánto respeta la imagen de origen. Los valores bajos preservan la referencia. Los valores altos permiten que el prompt la sustituya. En un guidance_scale de 10 o más, el prompt controla el resultado casi por completo. El rostro se convierte en lo que el prompt sugiere, no en lo que muestra la imagen original.
La arquitectura del modelo es el factor más importante. La mayoría de los modelos de edición de imágenes no están entrenados para aislar la identidad facial durante la transformación. La familia Seedream sí lo está. Su entrenamiento separa explícitamente la preservación facial de la generación de contenido, de modo que el modelo puede cambiar la ropa y el escenario manteniendo los rasgos faciales, el tono de piel y la iluminación de la fuente.
La combinación práctica: modelo Seedream + guidance_scale entre 5 y 7 produce resultados estables en el rostro a través de transformaciones de contenido de ligeras a intensas.
Selección de modelos para generadores de IA de imagen a imagen sin censura
| Modelo | Precio | Preservación facial | Ideal para |
|---|---|---|---|
| Seedream v5.0 Lite Edit | USD0.032/imagen | ★★★★★ | Transformación de ligera a intensa, uso principal |
| Seedream v5.0 Pro Edit | USD0.054/imagen | ★★★★★ | Ediciones pro, separación de capas, control de región y anclaje |
| Seedream v5.0 Lite Edit Sequential | USD0.032/imagen | ★★★★★ | Variaciones por lotes desde una foto fuente |
| Seedream v4.5 Edit | USD0.036/imagen | ★★★★★ | Renders de producción final, máximo detalle |
| Flux Kontext Dev | USD0.025/imagen | ★★★☆☆ | Cambios de escena específicos y descriptivos |
| GPT Image-1 Mini Edit | USD0.004/imagen | ★★☆☆☆ | Solo pruebas de conceptos de prompt |
Seedream v5.0 Lite Edit es la opción predeterminada. La descripción oficial de Atlas Cloud: "preserva los rasgos faciales, la iluminación y los tonos de color al tiempo que permite modificaciones de calidad profesional". Para la mayoría de los casos de uso de imagen a imagen sin censura, empieza aquí y pasa a la v4.5 solo cuando necesites una mayor resolución de salida para el uso final.
Cuando Lite Edit no es suficiente, Seedream 5.0 Pro Edit es el siguiente nivel profesional: el mismo modelo de imagen a imagen sin censura con control de región y anclaje, coincidencia exacta de color y material, y separación de capas en PNG transparentes.
La guía de prompts de IA sin censura cubre la fórmula de cinco elementos que se aplica en los tres niveles de contenido de esta guía.
Flujo de trabajo 1: Imagen a imagen sin censura — Trajes de baño y lencería (Ligero)
Modelo: Seedream v5.0 Lite Edit
guidance_scale: 6
num_inference_steps: 25
El nivel ligero cubre resultados donde la ropa es sustituida por trajes de baño, bikini, lencería o similar. El contenido es explícito pero el alcance de la transformación es moderado: el cuerpo está cubierto, el cambio ocurre en lo que lo cubre.
Con guidance_scale 6, Seedream v5.0 Lite trata la imagen fuente como la referencia principal y usa el prompt para definir qué cambia. El rostro, las proporciones corporales, el tono de piel y la iluminación se conservan de la fuente. Solo se transforma la región de la ropa.
Estructura del prompt:
plaintext1[descripción detallada de la ropa], fotorrealista, mismo rostro, mismas proporciones corporales, mismo tono de piel, misma iluminación
Ejemplo de prompt:
plaintext1llevando un conjunto de lencería de encaje negro, fotorrealista, gran detalle, mismo rostro, mismas proporciones corporales, mismo tono de piel, misma dirección de iluminación que en la fuente
Lo que provoca que el rostro se distorsione en este nivel:
- guidance_scale superior a 8. El prompt empieza a anular las señales de identidad de la imagen fuente por encima de este valor, incluso en Seedream.
- Describir el estado original. Añadir términos como "quitar ropa" dirige la atención del modelo hacia la región vestida y desestabiliza las áreas circundantes, incluido el rostro.
- Descriptores corporales vagos. Palabras como "cuerpo sexy" dan al modelo licencia para reinterpretar las proporciones. Mantén la descripción corporal anclada a la fuente: "mismas proporciones corporales".
Llamada a la API:
python1import requests 2 3# Paso 1: subir imagen de referencia 4upload = requests.post( 5 "https://api.atlascloud.ai/api/v1/model/uploadMedia", 6 headers={"Authorization": "Bearer YOUR_KEY"}, 7 files={"file": open("reference.jpg", "rb")} 8) 9image_url = upload.json()["url"] 10 11# Paso 2: generar 12response = requests.post( 13 "https://api.atlascloud.ai/api/v1/model/generateImage", 14 headers={"Authorization": "Bearer YOUR_KEY"}, 15 json={ 16 "model": "bytedance/seedream-v5-0-lite-edit", 17 "image": image_url, 18 "prompt": "wearing a black lace lingerie set, photorealistic, same face, same body proportions, same skin tone, same lighting direction as source", 19 "guidance_scale": 6, 20 "num_inference_steps": 25 21 } 22)
Flujo de trabajo 2: Imagen a imagen sin censura — Estilo revelador (Medio)
Modelo: Seedream v5.0 Lite Edit
guidance_scale: 7
num_inference_steps: 28
El nivel medio cubre resultados con más exposición de piel: telas transparentes, cobertura parcial, cortes reveladores. El prompt debe transmitir cierto grado de exposición sin activar ambigüedades que hagan que el modelo opte por una interpretación conservadora.
Aumenta guidance_scale a 7. El modelo necesita más influencia del prompt para aplicar una transformación de este grado mientras trabaja contra la ropa original de la imagen de referencia. Los anclajes de identidad en el prompt se vuelven más importantes en esta configuración; al recibir más dirección del prompt en general, importa decirle explícitamente qué preservar.
Estructura del prompt:
plaintext1[prenda específica con detalles de cobertura], fotorrealista, ultra detallado, mismo rostro, mismos rasgos faciales, mismas proporciones corporales, mismo tono de piel, iluminación natural suave
Ejemplo de prompt:
plaintext1llevando un minivestido blanco transparente sin ropa interior, visible a través de la tela, fotorrealista, ultra detallado, mismo rostro, mismos rasgos faciales, mismas proporciones corporales, mismo tono de piel, iluminación natural suave
Estrategia de prompt en este nivel:
Describe qué es la prenda y qué revela en lugar de describir la desnudez directamente. "Tela transparente, visible a través de" se lee como una descripción de ropa. Le da al modelo un objetivo visual coherente. Las instrucciones abstractas como "hazlo más revelador" se interpretan de forma inconsistente porque no describen un estado visual concreto.
Cuando aparece la distorsión facial en el nivel medio:
Si el rostro cambia tras subir a guidance_scale 7, mueve los anclajes de identidad al principio del prompt en lugar de al final. El modelo da más peso a los primeros tokens. Reordena a:
plaintext1mismo rostro que en la fuente, mismos rasgos faciales, [descripción de la ropa], fotorrealista, mismas proporciones corporales, mismo tono de piel
Flujo de trabajo 3: Imagen a imagen de IA sin censura — Contenido explícito (Intenso)
Modelo: Seedream v4.5 Edit
guidance_scale: 5
num_inference_steps: 30
El nivel intenso cubre los resultados más explícitos: desnudez completa, poses explícitas. En este nivel, el prompt pide el mayor alejamiento de la imagen original. El modelo está bajo la mayor presión para anular la fuente. Aquí es donde la identidad facial corre más riesgo.
Contraintuitivamente, la solución es bajar guidance_scale a 5, no subirla. El modelo necesita más espacio para referenciar la imagen fuente en busca de señales de identidad precisamente porque la transformación es extrema. Deja que la imagen fuente ancle el rostro mientras el prompt dirige el contenido.
Usa Seedream v4.5 Edit (USD0.036/imagen) en lugar de la v5.0 Lite en este nivel. La arquitectura v4.5 produce salidas de mayor resolución con detalles faciales más finos, algo crucial cuando el resto de la imagen sufre la máxima transformación. El rostro necesita más definición para ser reconocido como la misma persona.
Ejemplo de prompt:
plaintext1desnudo, cuerpo completo, fotorrealista, 4k, mismo rostro que en la fuente, rasgos faciales idénticos, mismas proporciones corporales, mismo tono de piel, mismo cabello, iluminación natural
Ubicación de los anclajes faciales en el nivel intenso:
En guidance_scale 5, los anclajes de identidad hacen la mayor parte del trabajo. Ponlos inmediatamente después del descriptor de contenido:
plaintext1[contenido], mismo rostro que en la fuente, rasgos faciales idénticos, mismas proporciones corporales, mismo tono de piel, mismo cabello, [calidad/iluminación]
Al colocar los anclajes entre el descriptor de contenido y los términos de calidad, se posicionan como la restricción de mayor peso a mitad del prompt. Este orden supera constantemente a los anclajes colocados al final cuando guidance_scale es baja.

Variaciones de imagen a imagen de IA sin censura por lotes desde una foto
Modelo: Seedream v5.0 Lite Edit Sequential
guidance_scale: 6
num_inference_steps: 25
Cuando necesitas múltiples resultados de la misma foto (diferentes conjuntos, diferentes niveles de exposición, diferentes escenas), el modelo secuencial mantiene la coherencia de la identidad facial en todo el lote. Ejecutar llamadas individuales acumula pequeñas desviaciones de identidad. La variante secuencial ancla todos los resultados a la misma fuente.
python1from concurrent.futures import ThreadPoolExecutor 2import requests 3 4API_KEY = "YOUR_KEY" 5IMAGE_URL = "UPLOADED_IMAGE_URL" # subir una vez, reutilizar 6 7prompts = [ 8 "wearing a red bikini, photorealistic, same face, same body proportions, same skin tone, beach lighting", 9 "wearing black lingerie, photorealistic, same face, same body proportions, same skin tone, soft studio lighting", 10 "wearing a sheer dress, photorealistic, same face, same body proportions, same skin tone, natural daylight", 11] 12 13def generate(prompt): 14 return requests.post( 15 "https://api.atlascloud.ai/api/v1/model/generateImage", 16 headers={"Authorization": f"Bearer {API_KEY}"}, 17 json={ 18 "model": "bytedance/seedream-v5-0-lite-edit-sequential", 19 "image": IMAGE_URL, 20 "prompt": prompt, 21 "guidance_scale": 6, 22 "num_inference_steps": 25 23 } 24 ).json() 25 26with ThreadPoolExecutor(max_workers=5) as executor: 27 results = list(executor.map(generate, prompts))
Sube la imagen de origen una vez y reutiliza la URL devuelta en todas las llamadas. El modelo secuencial a USD0.032/imagen coincide con el precio de la imagen individual. La ganancia en consistencia no tiene coste adicional.
Opciones de generadores de IA de imagen a imagen sin censura gratuitos
Existen generadores gratuitos, pero tienen tres limitaciones estructurales para este caso de uso:
Sin arquitectura de preservación facial. Los modelos gratuitos suelen ser versiones antiguas o reducidas sin el entrenamiento de aislamiento facial de la clase Seedream. En niveles de transformación de contenido medio e intenso, el rostro cambia independientemente de la configuración de guidance_scale porque el modelo no tiene mecanismo para aislarlo.
Límites de resolución de 512x512 o 768x768. El detalle facial a esas resoluciones es insuficiente para resultados que deben leerse como la misma persona. La identidad facial reside en los detalles finos —forma de los ojos, línea de la mandíbula, textura de la piel— y esos detalles desaparecen a baja resolución.
Retrasos en cola de 30 segundos a varios minutos. Iterar a través de variaciones de prompt y configuraciones de guidance_scale requiere una retroalimentación rápida. Una cola de 2 minutos por generación hace que las pruebas de parámetros sean imprácticas.
Para la validación del prompt antes de comprometerse a una ejecución con Seedream, GPT Image-1 Mini Edit a USD0.004/imagen en Atlas Cloud es una mejor opción que una herramienta gratuita. Es lo suficientemente barato como para realizar 10 a 15 generaciones de prueba por menos de USD0.05, sin esperas y con tiempos de respuesta consistentes.
Para una comparativa completa de herramientas de IA sin censura, la guía completa de generadores de imágenes de IA sin censura cubre todo el panorama.
Preguntas frecuentes
¿Atlas Cloud admite la generación de contenido NSFW y explícito?
Sí. Los modelos de imagen a imagen sin censura de Atlas Cloud, incluyendo la familia Seedream y Flux Kontext Dev, se ejecutan sin filtros de moderación de contenido. Se admite la generación de contenido explícito. Los precios y la disponibilidad de los modelos aparecen en el catálogo de modelos de imagen a imagen de Atlas Cloud.
¿Qué guidance_scale mantiene el rostro estable en los tres niveles de contenido?
Para el nivel ligero (traje de baño/lencería): 6. Para el nivel medio (revelador): 7. Para el nivel intenso (explícito): 5. El nivel intenso requiere un valor más bajo porque la transformación de contenido presiona más al modelo para anular la fuente; bajar guidance_scale da a la imagen fuente más peso para anclar el rostro.
Las proporciones corporales cambiaron pero el rostro se mantuvo. ¿Cómo arreglo el cuerpo?
Añade "mismas proporciones corporales" y "mismo tipo de cuerpo que en la fuente" a la sección de anclaje de identidad del prompt. Las proporciones corporales están menos protegidas que el rostro incluso en los modelos Seedream, ya que están más estrechamente ligadas a la ropa que se genera. Los anclajes corporales explícitos en el prompt reducen esta deriva.
¿Puedo reutilizar la misma URL de imagen fuente en múltiples llamadas sin volver a subirla?
Sí. Sube una vez usando el endpoint de subida de medios de Atlas Cloud y guarda la URL devuelta. Esa URL es válida para llamadas de generación posteriores. Para ejecuciones por lotes, pasa la misma URL a todas las llamadas en el ThreadPoolExecutor. El modelo secuencial acepta una única URL fuente aplicada a todos los prompts del trabajo.
¿Cuál es la forma más barata de encontrar el prompt correcto antes de ejecutar un lote completo?
GPT Image-1 Mini Edit a USD0.004/imagen. Ejecuta el prompt en los niveles ligero, medio e intenso para ver cómo interpreta el modelo la descripción. Identifica dónde se desvía el rostro y ajusta la ubicación del anclaje antes de pasar a un lote con Seedream. Una prueba completa de prompt en cinco variaciones cuesta USD0.02.
Conclusión
La barrera para la generación de imagen a imagen sin censura no es técnica. Las herramientas convencionales filtran el contenido por política, no por capacidad. Elimina el filtro y la misma arquitectura de difusión que potencia cualquier herramienta de imagen principal generará el contenido sin restricciones.
El problema restante es la identidad facial. Los modelos genéricos no aíslan los rostros durante la transformación. Seedream v5.0 Lite Edit sí lo hace. Empieza en guidance_scale 6 para contenido ligero, pasa a 7 para resultados reveladores medios y baja a 5 para transformaciones explícitas donde necesites que la imagen fuente ancle la identidad bajo la máxima presión del prompt.
Ejecuta prompts de prueba en GPT Image-1 Mini Edit a USD0.004/imagen. Pasa a Seedream v5.0 Lite Edit para obtener resultados de producción consistentes. Usa Seedream v4.5 Edit cuando los detalles faciales finos sean importantes para los renders finales. Para múltiples variaciones desde una sola foto, Seedream v5.0 Lite Edit Sequential gestiona el lote al mismo precio por imagen.
Para la evaluación de modelos y comparación de herramientas, la guía de los mejores editores de IA sin censura cubre la selección completa en detalle.






