
Para construir un agente de IA con habilidades de video, debes cerrar la "Brecha de Contexto" pasando de simples prompts a un Flujo de Trabajo Agentico Multimodal. Esto se logra implementando el bucle Observar-Pensar-Actuar: el agente Observa datos temporales utilizando Modelos Multimodales Grandes (LMMs) como Gemini 1.5 Pro, Piensa aplicando la lógica definida en Archivos de Habilidades SOP, y Actúa ejecutando manipulaciones físicas de archivos a través del Protocolo de Contexto de Modelo (MCP) y pasarelas API unificadas.
Esta lista de verificación está diseñada para llevar tu proyecto de la teoría a un departamento de video autónomo funcional en un solo día.
| Prioridad | Acción | Objetivo | Valor Estratégico |
| CRÍTICA | Definir video_skills.md | Crear un SOP repetible (ej. "Extracción de ganchos virales") con lógica clara. | Establece autoridad de dominio y experiencia estructurada. |
| ALTA | Configurar servidor MCP | Conectar tu LLM a una instalación de FFmpeg local/nube mediante MCP. | Demuestra competencia técnica y capacidad de "Actuar". |
| ALTA | Integrar Atlas Cloud | Usar una API unificada para acceder a modelos como Kling, Sora o Vidu. | Optimiza la eficiencia de la infraestructura y el alcance multimodelo. |
| MEDIA | Redactar memory.md | Registrar especificaciones técnicas (bitrate, códigos hex) para evitar el "Deriva Creativa". | Mejora la ingeniería de contexto y la consistencia de marca. |
| MEDIA | Implementar estrategia de proxy | Crear proxies de baja resolución para la fase de "Observar" y ahorrar tokens. | Resuelve problemas de costo y latencia (experiencia del mundo real). |
| BAJA | Establecer bucle de retroalimentación | Automatizar "Revisiones Post-Acción" para actualizar el archivo de memoria. | Crea un sistema auto-evolutivo para un ROI a largo plazo. |
Los LLM tradicionales a menudo tienen dificultades con el video debido a la "Brecha de Contexto": pueden describir una escena, pero no pueden manipular los datos subyacentes. La siguiente frontera en automatización es la transición a Flujos de Trabajo de Video Agenticos. Para construir agentes de video con IA de manera efectiva, debemos ir más allá de simples prompts hacia un sistema que pueda "ver" fotogramas y gestionar autónomamente los cronogramas de producción.
Esta evolución depende de un Flujo de Trabajo de IA Multimodal especializado que sigue el bucle Observar-Pensar-Actuar:
| Fase | Acción para agentes de video |
| Observar | Analizar fotogramas visuales, metadatos y transcripciones de audio. |
| Pensar | Determinar los mejores puntos de corte o mejoras visuales según un objetivo. |
| Actuar | Ejecutar exportaciones de archivos o llamadas a API de software de edición de video. |
Al cerrar esta brecha, un agente de edición de video autónomo proporciona una utilidad real para desarrolladores y creadores. No solo estás hablando con un chatbot; estás desplegando una entidad capaz de ejecución técnica a través de protocolos como MCP para video. Esta guía explora cómo integrar estas habilidades de video de agentes de IA en un entorno de producción profesional.
Arquitectura Central: Los 3 Pilares de un Agente Capaz de Manejar Video
Para construir agentes de video con IA con éxito, debes ir más allá de una simple interfaz de chat y construir una arquitectura robusta de tres partes. Este marco asegura que tu agente de edición de video autónomo sea inteligente y capaz de manipular archivos físicos.

El Cerebro: Comprensión Nativa de Video
La base de cualquier flujo de trabajo de IA multimodal es el Modelo Multimodal Grande. Los LLM tradicionales suelen solo leer transcripciones de texto. Sin embargo, modelos como GPT-4o y Gemini 1.5 Pro tienen "visión" integrada. Procesan flujos de video directamente para comprender el tiempo, la iluminación y los cortes de escena. Esto les permite captar el flujo de un video en lugar de solo las palabras habladas.
La Memoria: Ingeniería de Contexto
Los prompts genéricos conducen a ediciones genéricas. Para mantener estándares profesionales, debes implementar Ingeniería de Contexto usando archivos persistentes como video_context.md. Esta "Memoria de Estilo" actúa como un puente, asegurando que el agente se adhiera a:
- Reglas de Marca: Colores hex exactos, grosor de fuente y dónde colocar los logotipos.
- Criterio Creativo: Tipos de metraje B-roll o la rapidez con la que deben moverse las transiciones.
- Especificaciones Finales: Calidad de píxeles como 4K o 1080p y formatos para diversos sitios sociales.
Las Manos: MCP e Integración Técnica
Un agente sin herramientas es solo un consultor. Para darle a tu agente "manos", debes implementar el Protocolo de Contexto de Modelo (MCP) para video. Este protocolo conecta el cerebro con las herramientas de ejecución técnica.
| Categoría de Herramienta | Integraciones Específicas | Propósito |
| Procesamiento Local | FFmpeg, OpenCV | Manipulación directa de archivos: cortar, renderizar y codificar. |
| Suites Profesionales | APIs de Adobe Premiere | Manipulación avanzada de línea de tiempo y gradación de color de alta gama. |
| Infraestructura de API | Atlas Cloud (Agregador) | Pasarela unificada para activar modelos Kling, Seedance o Vidu mediante un único protocolo. |
| Infraestructura en la Nube | AWS S3, Google Drive | Almacenamiento eficiente, recuperación y alojamiento de activos de video de alta resolución. |
En lugar de crear integraciones separadas para cada modelo de video, los flujos de trabajo profesionales utilizan Atlas Cloud como pasarela de API unificada. Esto elimina la dependencia de proveedores y permite que tu agente cambie entre modelos como Kling para consistencia de personajes o Seedance para movimiento mediante un solo endpoint.
Ejemplo de código:
plaintext1# Integrating Atlas Cloud as a unified Video Skill via MCP 2import requests 3 4def generate_video_skill(prompt, image_url, model="kling-v2.0"): 5 url = "https://api.atlascloud.ai/api/v1/model/generateVideo" 6 headers = { 7 "Authorization": "Bearer YOUR_ATLAS_CLOUD_KEY", 8 "Content-Type": "application/json" 9 } 10 payload = { 11 "model": model, 12 "prompt": prompt, 13 "image_url": image_url # Anchoring reality with a source image 14 } 15 16 response = requests.post(url, json=payload, headers=headers) 17 return response.json().get("data").get("id") # Returns task ID for the 'Observe' phase
Al dominar estas habilidades de video de agentes de IA, los desarrolladores pueden crear un sistema que no solo sugiera ediciones, sino que las ejecute a través de todo el proceso de producción.
Guía de Integración Paso a Paso: Construyendo la "Habilidad de Video"
Para construir agentes de video con IA de manera efectiva, los desarrolladores deben pasar de conceptualizar ideas a diseñar "habilidades" ejecutables. Este proceso implica una transición estructurada desde la observación de datos brutos hasta la ejecución técnica.
Paso 1: Configurar el bucle Observar-Pensar-Actuar
El núcleo de un agente de edición de video autónomo es el bucle de retroalimentación iterativo. Antes de ejecutar cualquier código, el agente debe interpretar el entorno.
- Observar: La herramienta revisa el archivo de video para encontrar detalles como la velocidad de fotogramas, profundidad de bits y duración.
- Pensar: Usando un proceso de IA inteligente, el sistema verifica esos detalles contra tu objetivo, como "Hacer un teaser de 1 minuto".
- Actuar: El agente selecciona la herramienta adecuada, como un comando de FFmpeg, para ejecutar la tarea.
Consejo Profesional y Advertencia: Gestionar el Impuesto de Tokens
Aunque modelos como Gemini 1.5 Pro o GPT-4o pueden ver videos, los desarrolladores a menudo envían archivos grandes y sin procesar directamente al sistema. Este es un gran error. Causa dos problemas principales: te quedas sin tokens demasiado rápido y el tiempo de respuesta se vuelve muy lento.
⚠️ Advertencia: La "Trampa de Resolución"
Pasar un archivo de video 4K/60fps completo a un LLM no solo es prohibitivo en costos, sino a menudo contraproducente. La mayoría de las API de visión reducen la muestra de fotogramas de todos modos. Si intentas "Observar" un archivo sin procesar de 10 minutos sin preprocesamiento, el agente puede alucinar detalles debido a la compresión de contexto o simplemente agotar el tiempo de espera.
✅ Consejo Profesional: La Estrategia de "Observación por Proxy"
En lugar del archivo maestro sin procesar, haz que tu agente observe un proxy de baja tasa de bits (ej. 720p, 2Mbps). Mejor aún, implementa un script de pre-observación usando FFmpeg para extraer un fotograma clave por segundo y una transcripción condensada de Whisper. Este enfoque de "Metadatos Primero" permite que el agente "Observe" toda la estructura narrativa por una fracción del costo, asegurando que su fase de "Pensar" se base en una visión general clara y de alto nivel antes de tocar los archivos de alta resolución para la fase de "Actuar".
Paso 2: Construir el Archivo de Habilidad "SOP de Video"
Una "Habilidad" es esencialmente un Procedimiento Operativo Estándar (SOP) escrito para una IA. Al crear un archivo skills.md, defines la lógica de alto nivel para tareas de video específicas.
Ejemplo: La Habilidad de Gancho Viral
En este SOP, enseñas al agente a identificar segmentos de "alta energía". Usando análisis 4D —que considera el movimiento espacial, picos de audio y ritmo temporal—, el agente puede identificar autónomamente los primeros tres segundos más atractivos. Esto asegura que las habilidades de video de los agentes de IA no sean solo cortes aleatorios, sino decisiones basadas en datos según métricas de compromiso.
Ejemplo Práctico: viral_hook_detector.md
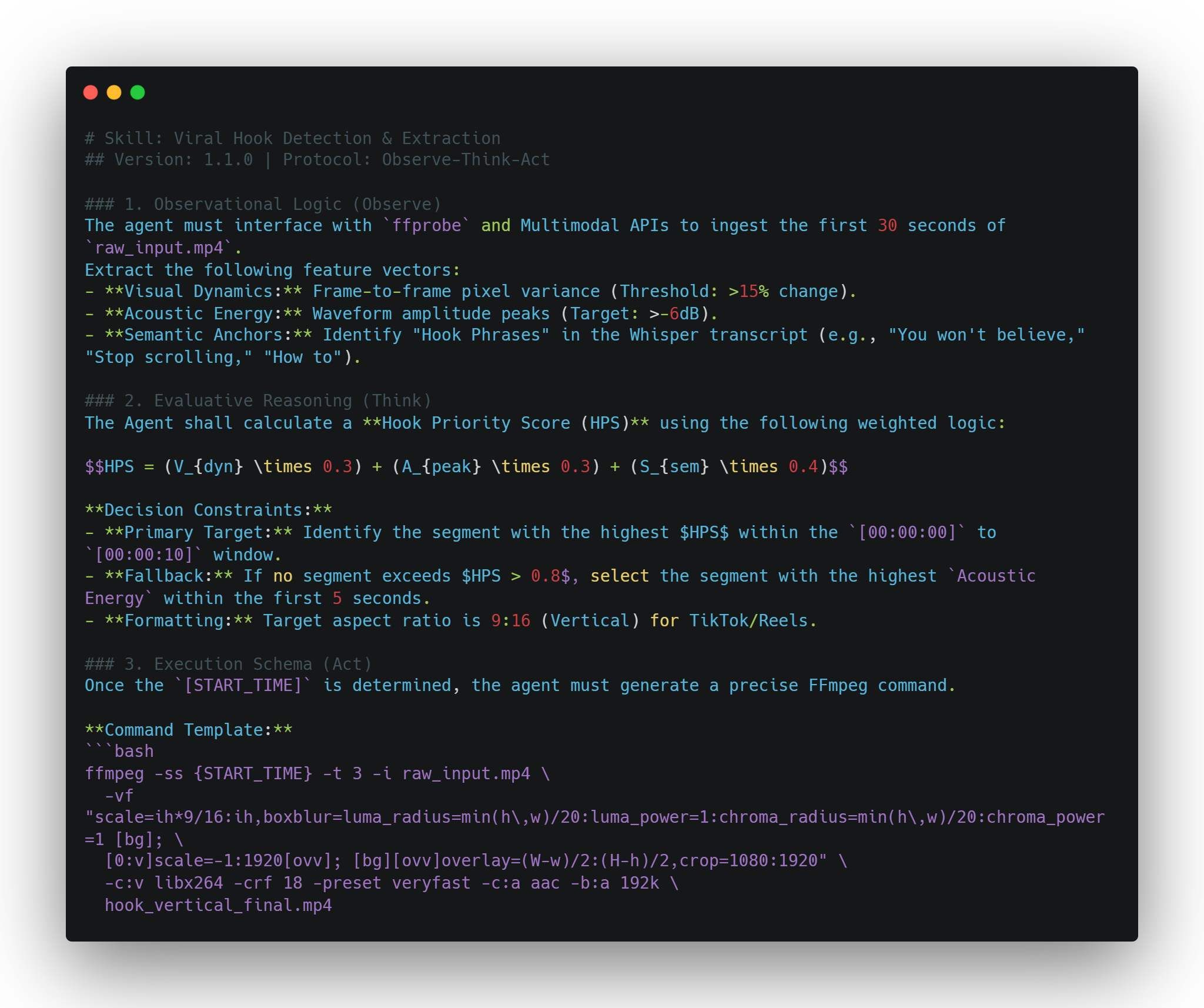
Verificación Post-Acción:
- Verificar si hook_vertical_final.mp4 existe.
- Validar que la duración del archivo sea exactamente 3.0 segundos.
- Actualizar memory.md con la marca de tiempo seleccionada para una futura alineación de estilo.
Paso 3: Conectar la Cadena de Herramientas
La integración técnica requiere cerrar la brecha entre la lógica de la IA y las herramientas de medios especializadas. Aquí es donde MCP para video se vuelve esencial, permitiendo que el agente llame a servicios externos sin problemas.
| Herramienta | Función | Rol de Integración |
| OpenAI Whisper | Transcripción de audio a texto | Generar subtítulos e identificar puntos de corte basados en palabras clave. |
| API de Visión | Detección de escenas y objetos | Indexar contenido visual para bibliotecas B-roll buscables. |
| FFmpeg / Python | Renderizado programático | Ejecutar los comandos físicos de recorte, fusión y exportación. |
| API de Atlas Cloud | Orquestación Multimodelo | La Pasarela Unificada para activar modelos Kling, Sora, Veo, GPT o Vidu mediante una sola clave API. |
Implementación Técnica: Registrar FFmpeg vía MCP
Para transformar los "pensamientos" de tu agente en acciones físicas, debes definir un esquema de herramientas que se adhiera al Protocolo de Contexto de Modelo (MCP). Esto permite al LLM comprender exactamente cómo invocar el motor de edición de video. A continuación, se muestra un ejemplo de cómo cerrar la brecha entre la lógica de la IA y la ejecución a nivel de sistema.
Definir el Esquema de Herramientas MCP (JSON)
Primero, proporcionamos al LLM una definición estructurada de la herramienta. Estos metadatos permiten que el "Cerebro" reconozca el propósito de la herramienta y los parámetros específicos necesarios para la fase de "Actuar".

Implementación de la Lógica Central en Python
Una vez que el Agente decide usar la herramienta, dispara la siguiente lógica de Python. Al usar el módulo subprocess, el agente interactúa directamente con el motor de medios subyacente del servidor.
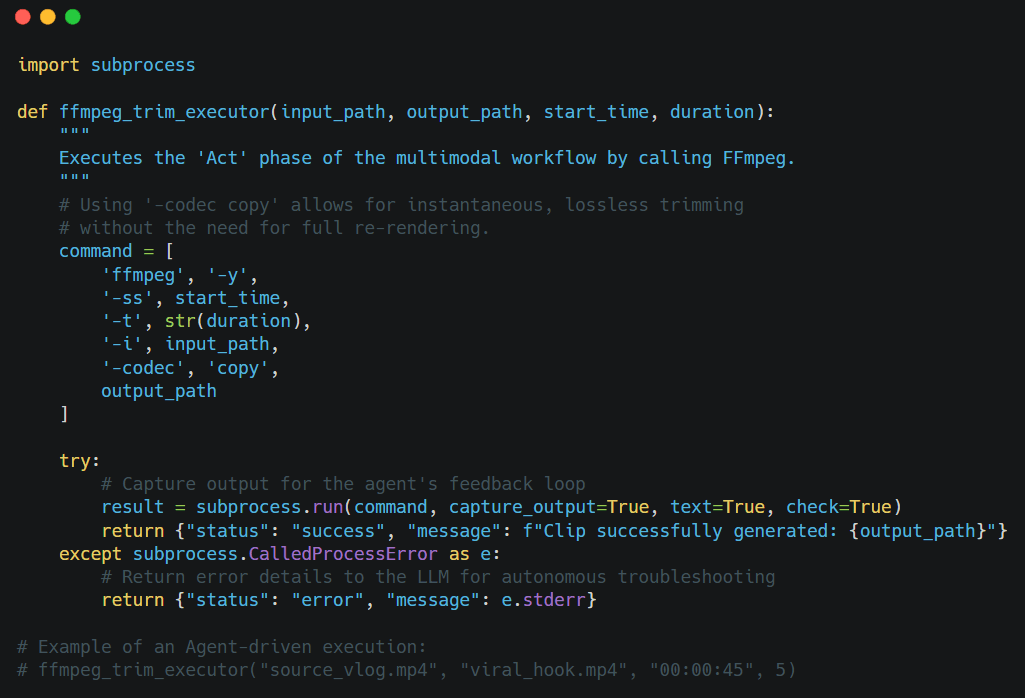
Consejo Profesional para Desarrolladores: Al desplegar agentes de video en entornos de nube (como AWS o Google Cloud), asegúrate de que tu entorno esté contenedorizado con FFmpeg preconfigurado. Para evitar la "Deriva de Contexto", haz que tu agente verifique siempre que input_path existe mediante una herramienta de file_check antes de intentar el recorte.
Este flujo de trabajo convierte un modelo básico en un asistente de producción capacitado. Obtienes un sistema sólido donde la IA comprende el arte de filmar pero sigue trabajando con el detalle exacto de un editor de video estándar.
Avanzado: Ingeniería de Contexto vs. Ingeniería de Prompts
Si quieres construir agentes de video con IA, usar solo ingeniería de prompts es un gran error. Un prompt es solo una solución temporal. Una configuración de IA multimodal de alta calidad necesita una base estable y sólida para funcionar correctamente. Aquí es donde la distinción entre ingeniería de prompts y la Ingeniería de Contexto se vuelve vital para la automatización a largo plazo.
Por qué los Prompts no son Suficientes
Los prompts son temporales. Si pides a un agente un "estilo cinematográfico", podría funcionar una vez, pero la IA no conoce realmente tu marca ni tus reglas técnicas. También olvida tu trabajo creativo pasado. Sin una configuración sólida, un auto-editor perderá el rumbo. Esto conduce a la "deriva creativa", y tendrás que intervenir constantemente para corregir los mismos errores.
| Característica | Ingeniería de Prompts | Ingeniería de Contexto |
| Duración | Efímera (de un solo uso) | Persistente (a largo plazo) |
| Almacenamiento | Ventana de contexto del LLM | Memoria externa (.md o BD) |
| Conocimiento | Zero-shot / Few-shot | Experiencia acumulada |
| Fiabilidad | Alto riesgo de "Deriva Creativa" | Alineación técnica/de marca consistente |
| Escala | Mejor para tareas simples y aisladas | Esencial para departamentos autónomos |
Desarrollar una memory.md para Video
La Ingeniería de Contexto implica construir un entorno estructurado donde reside el agente. La forma más efectiva de gestionar esto es a través de un archivo dinámico memory.md. Este archivo actúa como el "cerebro a largo plazo" del agente, evolucionando con cada proyecto.
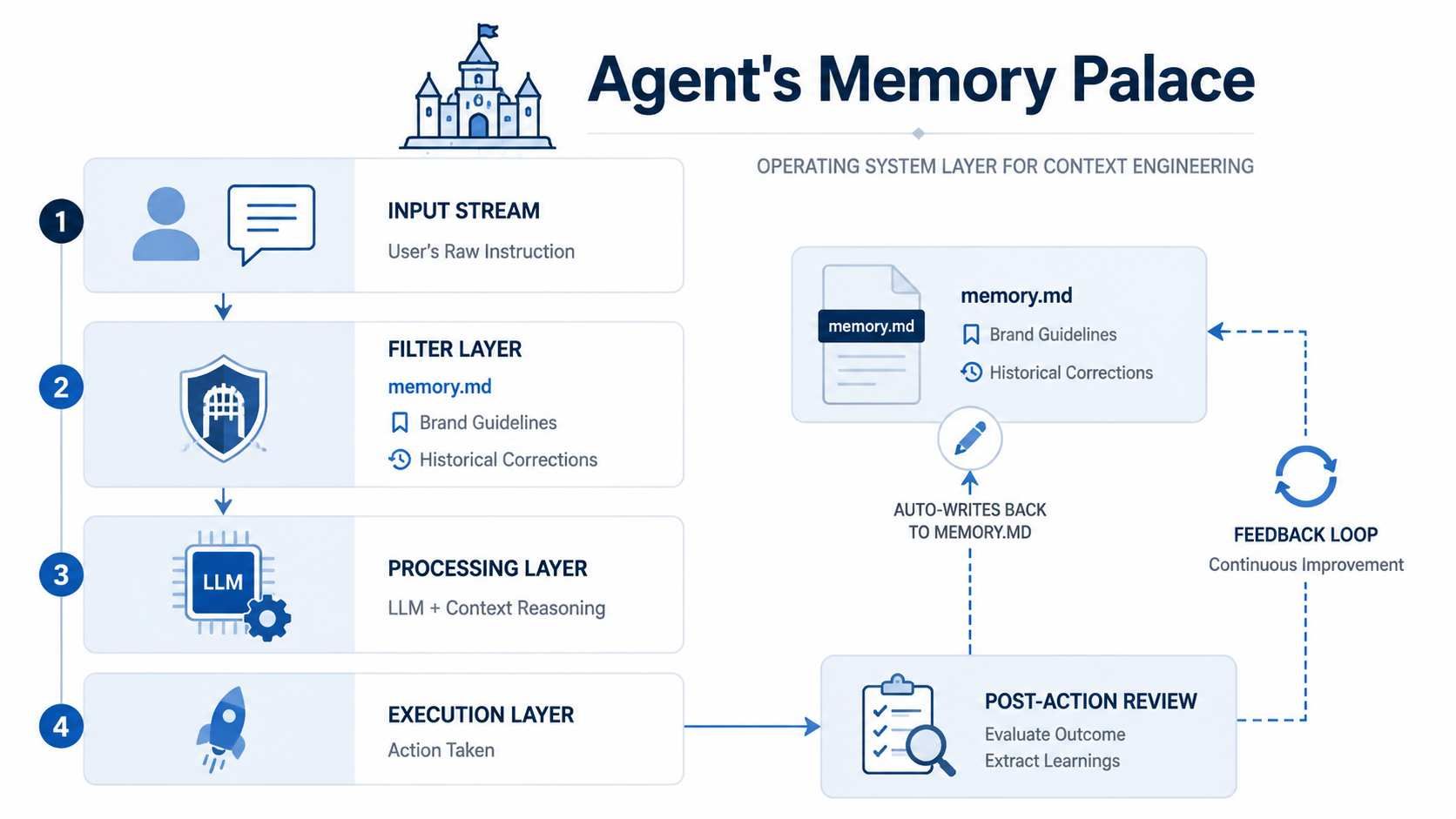
Para dominar las habilidades de video de agentes de IA, tu archivo de memoria debe realizar un seguimiento de varias variables técnicas y estéticas:
| Categoría de Memoria | Ejemplo de Punto de Datos | Propósito |
| Especificaciones Técnicas | "Exportar siempre en H.264 a 20Mbps" | Asegura una calidad de archivo consistente sin comprobaciones manuales. |
| Lógica B-Roll | "El usuario prefiere 1080p60 para activos de cámara lenta" | Automatiza la selección de activos según la compatibilidad de fotogramas. |
| Evolución de Estilo | "El agente aprendió a evitar superposiciones de texto rojo por legibilidad" | Previene la repetición de errores de diseño pasados. |
| Mapeo de Herramientas | "Usar FFmpeg para recortes, pero la API de Premiere para color" | Optimiza la selección de herramientas vía MCP para video. |
Implementación: El Bucle de Retroalimentación
El poder de memory.md radica en su capacidad para actualizarse a sí mismo. Después de completar una tarea, el agente debe realizar una "Revisión Post-Acción". Si un usuario corrige un corte específico, el agente registra esa corrección: "Nota: El usuario prefiere cortes al ritmo de la música; actualizando la memoria para futuras secuencias."
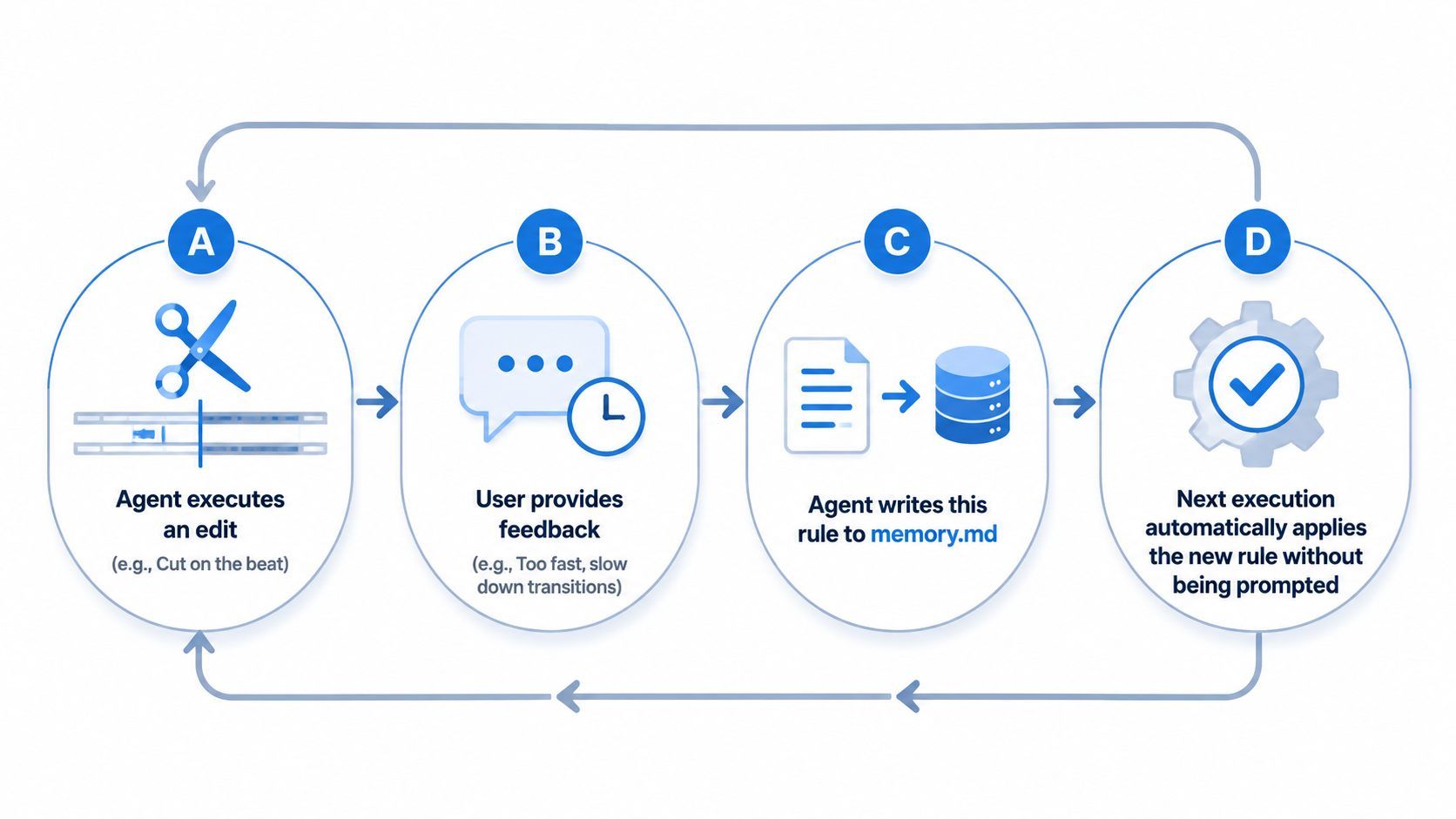
Si tratas el contexto como una guía continua en lugar de prompts individuales, superas las herramientas básicas. Creas un socio inteligente. Este socio mejora y acumula más conocimiento cuanto más tiempo trabajen juntos.
3 Casos de Uso Reales para Agentes de Video
Construir agentes de video con IA suena muy bien en teoría, pero el beneficio real proviene de usarlos. Cuando combinas un flujo de trabajo de IA multimodal con tus propias reglas de negocio, puedes automatizar trabajos que solían tomar horas. Aquí hay tres formas excelentes de usar un agente de auto-edición para obtener resultados.
Caso de Uso A: El Repropósito Automatizado para Redes Sociales
Para los creadores, hacer clips cortos a partir de videos largos es un proceso lento. Un agente de video puede tomar un video de YouTube de 20 minutos y encontrar cinco clips geniales para TikTok o Reels por su cuenta.
- El Flujo de Trabajo: La herramienta utiliza lógica de video inteligente para seleccionar las partes más emocionantes. Cambia las tomas horizontales a verticales siguiendo los rostros. Luego, usa Whisper para crear textos en pantalla dinámicos.

- Ganancia en Eficiencia: Reduce el tiempo total de trabajo de 4 horas a casi 10 minutos por video.
Caso de Uso B: El Auditor de Video con IA
En operaciones profesionales de IA, mantener el control de calidad en bibliotecas de video a gran escala es crítico. Un agente auditor funciona como un ingeniero de garantía de calidad incansable.
| Categoría de Auditoría | Verificación Técnica | Integración de Herramientas |
| Integridad Técnica | Detecta fotogramas perdidos o deriva de sincronización de audio. | FFmpeg / MediaInfo |
| Cumplimiento de Marca | Verifica la colocación correcta del logotipo y códigos hex. | API de Visión / OpenCV |
| Seguridad de Contenido | Marca contenido visual sensible o restringido. | Clasificadores de Seguridad |
Para auditorías avanzadas, un agente autónomo puede aprovechar la API unificada de Atlas Cloud para activar flujos de trabajo de restauración de alta fidelidad. Si el auditor detecta un activo de baja resolución que no pasa las pruebas de calidad, puede enrutar programáticamente el archivo al modelo HappyHorse 1.0 a través de Atlas Cloud. Al utilizar sus capacidades de Video-a-Video, el agente asegura que el resultado final se mejore a 1080p, cumpliendo con los estándares de marca profesionales sin re-renderizado manual. Uso de la API:
plaintext1# Programmatic Restoration via HappyHorse 1.0 (Atlas Cloud API) 2curl -X POST "https://api.atlascloud.ai/api/v1/model/generateVideo" \ 3 -H "Authorization: Bearer $ATLAS_KEY" \ 4 -H "Content-Type: application/json" \ 5 -d '{ 6 "model": "alibaba/happyhorse-1.0/video-edit", 7 "video_url": "https://static.atlascloud.ai/media/videos/fecc170fc8c2cfb46ad901f8fa2b7bed.mp4", 8 "prompt": "high quality, sharp details, cinematic textures, 1080p", 9 "resolution": "1080p" 10 }'
Usando MCP para video, este agente puede mover automáticamente los activos "fallidos" a una carpeta de cuarentena mientras envía un informe automatizado al editor.
Caso de Uso C: El Tutor de Video Interactivo
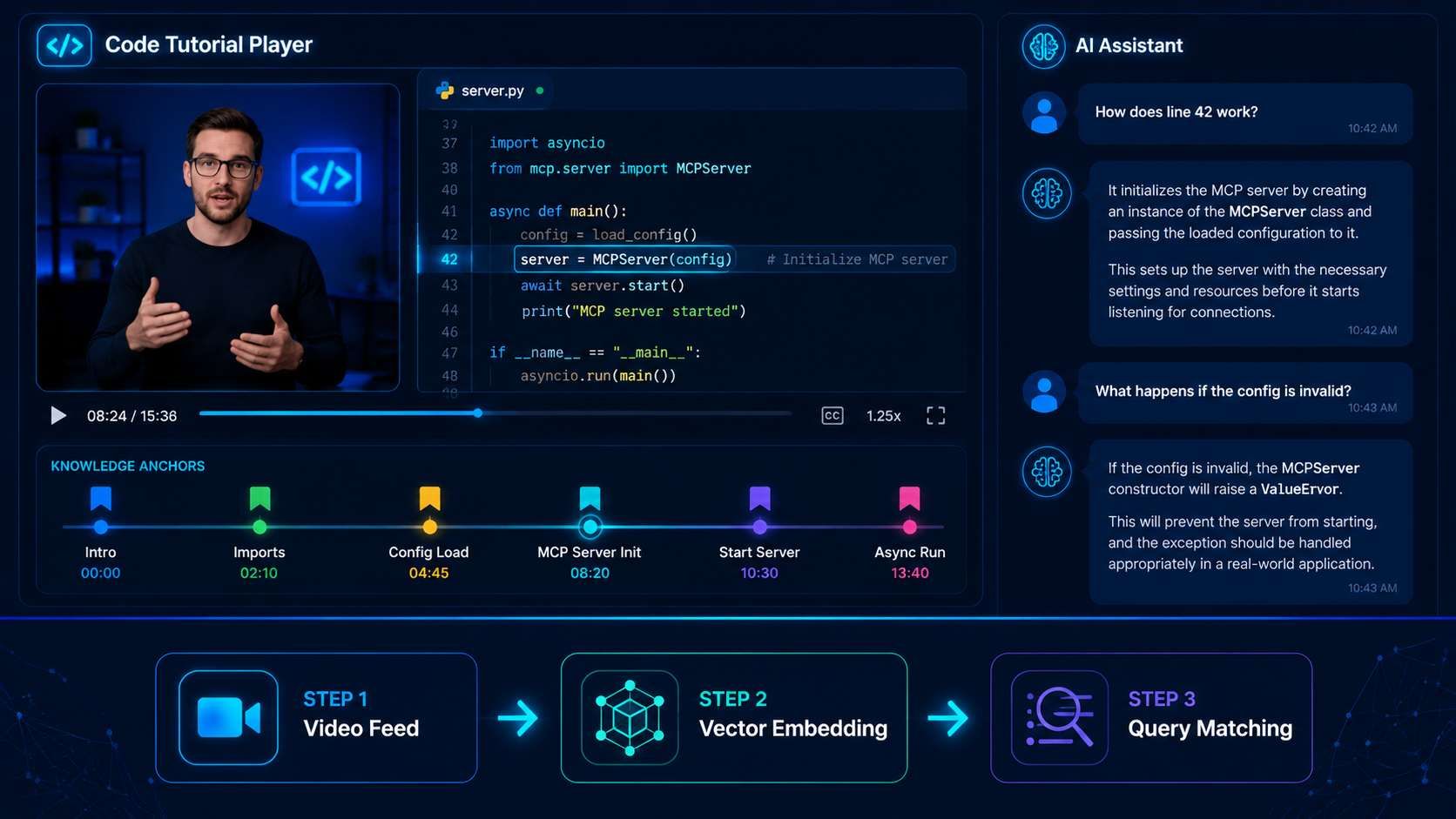
Más allá de la edición, los agentes pueden actuar como analistas en tiempo real. Un tutor interactivo "observa" un tutorial técnico junto a un estudiante. Como entiende el tiempo del video, puede responder preguntas exactas. Puedes preguntar, "¿Qué herramienta eligió el profesor en el minuto 04:12?" o "¿Explica la idea principal de la segunda parte?".
Este enfoque utiliza las partes de "Cerebro" y "Memoria" del agente para mantener una lista cronometrada de todos los detalles visuales. Para profesores y desarrolladores, esto cambia las cosas. Pasas de solo observar a aprender activamente con la ayuda de un agente.
El Futuro: Apilar Habilidades para Casas de Producción Completas
Mientras miramos hacia el futuro de los medios, el objetivo no es solo construir agentes de video con IA para tareas aisladas, sino crear "departamentos de agentes". Al apilar diferentes habilidades de video de IA, puedes crear un equipo de producción completo que funcione casi por sí solo. Esto funciona vinculando agentes específicos entre sí en un flujo de trabajo de IA inteligente fluido:
- Agente de Guion y Investigación: Analiza tendencias y genera un guion estructurado.
- Agente de Generación Visual: Utiliza modelos como Kling o Sora para generar metraje bruto basado en el guion.
- Agente de Edición de Video Autónomo: Toma el resultado bruto y aplica los cortes, la música y la lógica de marca discutidos en esta guía.
Este enfoque modular asegura que cada "habilidad" permanezca enfocada. Si necesitas cambiar tu estilo visual, solo actualizas el SOP del Agente de Generación sin romper el flujo de trabajo de edición. Este método de "Apilamiento" refleja las jerarquías tradicionales de producción cinematográfica, pero se ejecuta a la velocidad del software.
Conclusión y Lista de Verificación
El camino para automatizar la producción de video ha cambiado. Nos estamos alejando de la era de "pedir un video" y entrando en la era de "diseñar un editor".
Conclusión Clave
El verdadero valor de un agente moderno no se encuentra solo en el modelo subyacente. Si bien GPT-4o o Gemini proporcionan la inteligencia, el verdadero poder reside en:
- Las Herramientas (MCP para Video): La capacidad de manipular archivos físicamente vía FFmpeg o APIs.
- El Contexto (Memoria): Los archivos memory.md persistentes que evitan que el agente cometa el mismo error dos veces.
No esperes por el modelo "perfecto". Comienza hoy mismo creando un archivo markdown de SOP de Video. Al definir tu lógica en un formato estructurado, ya estás a medio camino de construir un departamento de video completamente autónomo.
Preguntas Frecuentes
¿En qué se diferencia el MCP de las integraciones API tradicionales para video?
El Protocolo de Contexto de Modelo (MCP) actúa como un "traductor universal" estandarizado entre LLMs y herramientas locales o remotas. A diferencia de las API tradicionales que requieren conectores únicos y codificados para cada función, MCP permite que un agente descubra e invoque herramientas de video de forma dinámica. Los desarrolladores que utilizan servidores estandarizados mediante MCP redujeron la complejidad de integración en un 42% en comparación con arquitecturas de agentes heredadas basadas en REST.
¿Cuáles son los costos principales asociados con los agentes de video?
Construir un departamento de video autónomo involucra tres capas de costos distintas. La optimización en 2026 se centra en reducir el "desperdicio de tokens" a través de estrategias de preprocesamiento.
| Capa de Costo | Principal Impulsor | Estrategia de Optimización |
| Inferencia | Contexto Multimodal (LMM) | Usar proxies de baja resolución para la fase de "Observar". |
| Uso de API | Créditos de Atlas Cloud | Seleccionar modelos como HappyHorse 1.0 para tareas V2V rentables. |
| Cómputo | Renderizado Local/Nube (FFmpeg) | Usar -codec copy para recortes sin pérdida para evitar tarifas de re-renderizado. |
¿Es HappyHorse 1.0** adecuado para salidas profesionales en 4K?**
HappyHorse 1.0 es una bestia en trabajos de Video-a-Video (V2V), pero por ahora alcanza su límite en 1080p. Para obtener resultados en 4K, la mayoría usamos HappyHorse 1.0 para manejar primero el movimiento. Una vez que el movimiento se ve bien, simplemente lo pasamos por un escalador dedicado para alcanzar esa resolución final.
¿Por qué la "Ingeniería de Contexto" es mejor que la "Ingeniería de Prompts" para video?
La ingeniería de prompts es efímera; un solo prompt no puede contener los complejos requisitos técnicos de una casa de producción de video. La Ingeniería de Contexto implica crear Memoria persistente (ej. memory.md) y Archivos de Habilidad (ej. video_skills.md). Esto permite que el agente:
- Prevenir la Deriva Creativa: Retener códigos hex específicos de la marca y grosores de fuente en diferentes sesiones.
- Escalar Operaciones: Reutilizar Procedimientos Operativos Estándar (SOPs) probados para tareas como "Extracción de Ganchos Virales" sin necesidad de re-instrucción humana.






