El verdadero cuello de botella en el video con IA no es que el resultado parezca incorrecto. Es que se siente lento.
1. Por qué 15 segundos de acción con IA siempre decepcionan
Cualquiera que haya pasado tiempo de verdad con Seedance 2.0 se ha topado con el mismo límite: cuando pides un clip de 15 segundos, el modelo te entrega tres o cuatro tomas, y eso es todo.
Le das una escena de pelea. Lo que recibes es: "el luchador entra → levanta el arma → se congela". Inicio, acción, final. Aparecen los créditos.
Pero así no es como se lee realmente una pelea en pantalla. Antes de que el golpe impacte, el hombro gira. Tras esquivar, el contraataque ya se está preparando. Una persecución en plano general corta a un primer plano extremo, y este corta a una cámara lenta de impacto. La tensión proviene de la densidad de cortes, no de hacer que una sola toma sea más bonita.
Y el modelo no te dará dieciséis tomas por sí solo, sin importar cómo redactes el prompt.
Ese es el problema. Así es como lo resolvimos.
2. Tres cambios que transformaron el flujo de trabajo
Tras ejecutar la demo completa de acción con un solo personaje de principio a fin, concluimos que tres aspectos son los que importan:
① La tensión de la acción proviene de la densidad de cortes, no de la calidad de una sola toma. Deja de intentar que una toma sea perfecta. Divide los 15 segundos en un storyboard de 16 celdas primero y luego entrégaselo al modelo de video.
② La verdadera fuerza de GPT Image 2 es la comprensión del guion y la disposición de las tomas, no la consistencia del estilo. Inicialmente queríamos que GPT Image 2 mantuviera un solo estilo en toda la cadena. Tras las pruebas, aceptamos que la referencia a video tiende naturalmente hacia el estilo CG; no hay forma limpia de forzarlo. Pero lo que GPT Image 2 sí puede hacer (leer un guion, planificar las tomas y diseñar un storyboard de 16 celdas) es algo que ningún otro modelo de nuestro grupo hace tan bien.
③ Todo el pipeline funciona con una sola clave de API de AtlasCloud. GPT Image 2, Nano Banana 2 y Seedance 2.0 residen en el mismo grupo de modelos en AtlasCloud. Una clave. Un endpoint. Una factura. Una cuota. Sin la complejidad de trabajar con múltiples proveedores.
3. La prueba de estrés con un solo personaje
Para poner a prueba realmente a GPT Image 2, elegimos el personaje más difícil que se nos ocurrió.
Conoce a Ranx: una operadora táctica cibernética. Moños dobles color oro arena. Y cuatro piezas de equipo completamente asimétricas:
- Un calcetín negro hasta el muslo solo en la pierna derecha
- Una funda rígida roja solo en el muslo derecho
- Ribetes cian solo en la rodilla derecha
- Una bobina negra gruesa que recorre desde la parte trasera derecha de su cinturón hasta su pantorrilla izquierda
La única imagen de referencia que entregamos al modelo fue una toma de tres cuartos de espalda. El modelo tuvo que derivar el frente, los costados, las expresiones y los detalles del arma, sin reflejar (hacer mirror) ni una sola de esas cuatro asimetrías.
Resultado: una generación. Seis vistas de giro, cuatro estudios de cabeza, cuatro expresiones, panel de armas, manos, pies... todo en una página. Las cuatro asimetrías bloqueadas. Cero errores de reflejo.


El entorno lo tratamos como una referencia de diseño terminada (callejón cyberpunk húmedo, estética tipo Stray):

4. El A/B que demuestra el método
Este es el experimento sobre el que descansa todo el flujo de trabajo. Mismo guion. Misma hoja de personaje. Misma referencia de escena. La única variable es la existencia de un storyboard.
Control: solo prompt en prosa, sin storyboard
Entradas para la referencia a video de Seedance 2.0:
- 1× hoja de personaje
- 1× referencia de escena
- Un detallado prompt en prosa de 15 segundos que describe cuatro cortes duros
El metraje es legible y el oficio es correcto. Pero el clip completo se reproduce en aproximadamente tres tiempos lentos: entrar al callejón, levantar el arma, congelarse. Se lee como una demo de personaje, no como una pelea.
Prueba: con un storyboard de 16 celdas
Le pedimos a GPT Image 2 que dividiera el mismo guion en un storyboard de 4×4 = 16 celdas, con cada celda etiquetada para:
- Número de toma (① ② ③ … ⑯)
- Tamaño de toma (WIDE / MS / CU / ECU)
- Flecha de movimiento de cámara (→ ↘ ↙ ↑ ↓ ↗)
- Nota de ritmo ("static rise" / "hard cut" / "impact" / "kill shot" / "outro")
- Una breve nota de dirección en chino escrito a mano (una elección puramente de densidad; el chino permite meter más intención de dirección en una celda pequeña de storyboard; tanto GPT Image 2 como Seedance 2.0 leen ambos idiomas igual de bien)
Luego, un prompt de una sola línea en la referencia a video de Seedance 2.0:
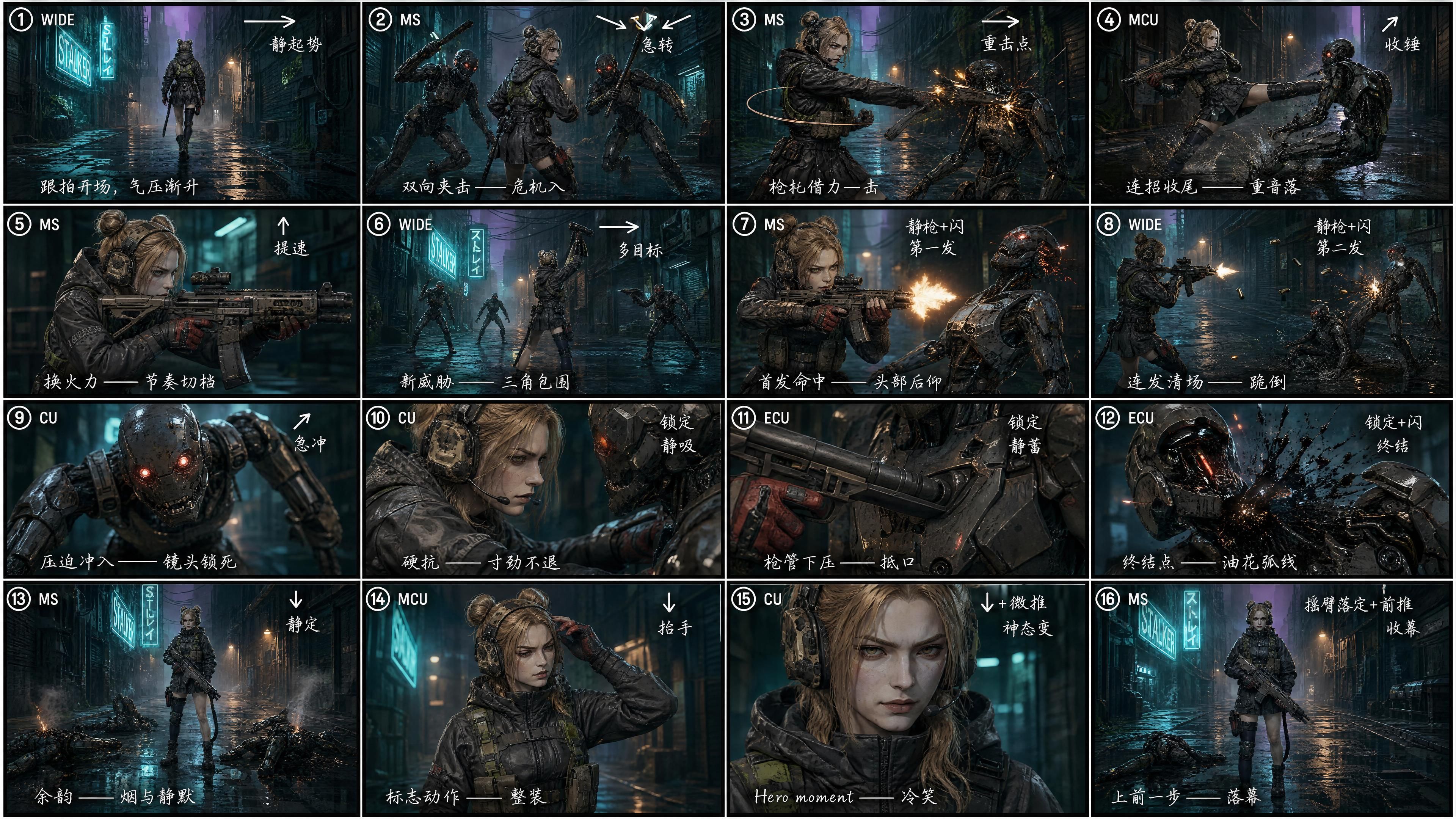
"Genera un video que siga estrictamente la imagen de referencia 3 como storyboard. Fuerte sensación cinematográfica y lenguaje de tomas, dinámica exagerada, acción con impacto contundente."
La diferencia es visible sin necesidad de medirla. La densidad de cortes aumenta aproximadamente 4 veces. Persecución en plano general, montaje al hombro en plano medio, primer plano extremo en la boca del arma y un final en pose de héroe: quince segundos totalmente aprovechados. Mismo guion, distinto ritmo. La primera versión parece una demo. La segunda se lee como un tráiler.
Esa es la tesis completa de este flujo de trabajo: GPT Image 2 no es para fijar el estilo. Es para fragmentar un guion en una secuencia de tomas densa.
5. Escalando: un duelo entre dos luchadores
Una vez que la versión de un solo personaje quedó limpia, escalamos a un duelo. La parte más difícil de una pelea de dos personas es bloquear cuatro cosas a la vez: Personaje A, Personaje B, el entorno y el ritmo de la acción.
En lugar de generar cuatro imágenes separadas e intentar encadenarlas, le pedimos a GPT Image 2 que manejara los cuatro en una sola imagen:
- Personaje A (A-27): una versión ajustada de Ranx: operadora táctica con coleta color oro arena y abrigo de combate corto.
- Personaje B: un diseño de mercenario masculino original: abrigo largo rojo y negro, cabello recogido, espada ancha en la cadera.
- El entorno: una fortaleza industrial en ruinas llamada Ash City: luz ámbar de atardecer, resplandor de horno a lo lejos, humo por todas partes.
- Diez tiempos de acción dibujados a mano: sonda → carga → bloqueo → evasión → gancho → contraataque → inmovilización → rodillazo → cierre → caída.

Importante señalar: solo el Personaje A usó una imagen de referencia (Ranx de antes). El Personaje B, todo el entorno y los diez tiempos de acción fueron diseñados por GPT Image 2. Nosotros describimos la vibra; el modelo hizo el resto.
Estilo, ambas identidades, el entorno y diez tiempos: todo bloqueado en una sola generación. Nada se desvía entre imágenes. El vestuario de nadie cambia a mitad de camino.
Luego, directo a la referencia a video de Seedance 2.0:
Un enfrentamiento en la azotea anclado por dos insignias de facción en el suelo de la plataforma, un agarre en la sección media y un lanzamiento final: quince segundos de coreografía de dos personas en una sola pasada.
6. Por qué este pipeline funciona con una sola clave de API
La cadena (personaje → escena → storyboard → video) antes significaba hacer malabares con claves de API, SDK, documentación, facturación y límites de tasa entre múltiples proveedores. Ya conoces el proceso.
En AtlasCloud, todo eso se encuentra detrás de un solo endpoint:
| Paso | Modelo | Plataforma |
|---|---|---|
| Hoja de personaje | GPT Image 2 | AtlasCloud |
| Concepto de escena | Nano Banana 2 | AtlasCloud |
| Storyboard | GPT Image 2 | AtlasCloud |
| Video | Seedance 2.0 | AtlasCloud |
Una clave. Un endpoint. Una cuota. Una factura. La integración y la carga operativa se reducen casi a cero.
7. La conclusión: deja de pelear por un estilo uniforme entre modelos y empieza a aprovechar la fortaleza de cada uno
Dedicamos un esfuerzo real a intentar fijar un solo estilo en cada paso de la cadena. En el modo de referencia a video, esa batalla es imposible de ganar; cuanto más lo intentas forzar, peor es el resultado.
Una vez que dejamos ir ese objetivo, el flujo de trabajo se abrió. Deja que cada modelo haga aquello en lo que realmente es bueno.
- GPT Image 2: fragmentar el guion, disponer las tomas.
- Seedance 2.0: desplegar el tiempo, renderizar la acción.
- AtlasCloud: una clave, una cadena.
Si estás creando cortos de acción, escenas de pelea o coreografías de duelo con IA, este es el flujo de trabajo que recomendamos.
Pruébalo tú mismo
Ambos modelos viven en el mismo grupo de modelos de AtlasCloud; una clave de API ejecuta toda la cadena:
- Seedance 2.0 (referencia a video) → atlascloud.ai/collections/seedance2
- GPT Image 2 (hoja de personaje + storyboard) → atlascloud.ai/collections/gpt-image-2
- Nano Banana 2 (concepto de escena) → atlascloud.ai/collections/nanobanana-2
El paso a paso completo y cada prompt utilizado en este artículo están publicados junto con el tutorial en video en YouTube.
Ve a crear algo.






