Lancement en avant-première de DeepSeek-V4 : 1M de tokens de contexte, améliorations pour les agents et poids en open source
Aujourd'hui (24 avril), DeepSeek lance officiellement et rend open source la version préliminaire de DeepSeek-V4, sa toute nouvelle série de modèles.
DeepSeek-V4 prend en charge jusqu'à un million de tokens de contexte et atteint des performances de premier plan parmi les modèles nationaux et open source en matière de capacités agentiques, de connaissances générales et de raisonnement. La série se décline en deux tailles :
- DeepSeek-V4-Pro — le modèle phare, est un modèle MoE (Mixture of Experts) massif avec 1,6 billion de paramètres au total, mais seulement 49B activés par passe directe (forward pass) — c'est la clé de son efficacité.
- DeepSeek-V4-Flash — l'option plus rapide et plus économique. Il suit la même conception MoE à une échelle beaucoup plus réduite (284B au total / 13B actifs), permettant une inférence plus rapide et moins coûteuse.
- Les deux modèles partagent la même fenêtre de contexte de 1M de tokens et sont entièrement open source avec accès API.
| Modèle | Paramètres | Activation | Données de pré-entraînement | Longueur du contexte | Open Source | Service API | Mode d'accès Web/App |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 33T | 1M | ✓ | ✓ | Expert Mode |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✓ | ✓ | Fast Mode |
À partir d'aujourd'hui, vous pouvez discuter avec DeepSeek-V4 sur chat.deepseek.com ou via l'application officielle. L'API est également en ligne — définissez simplement model_name sur deepseek-v4-pro ou deepseek-v4-flash pour commencer.
Nous avions rapporté les spéculations et analyses avant la sortie (voir notre guide des attentes pour DeepSeek V4 et notre analyse technique approfondie), nous disposons maintenant de détails officiels confirmés provenant directement de la source. Ce qui suit couvre exactement ce qui a été déployé, les nouveautés et ce que cela signifie si vous développez avec ou évaluez des modèles d'IA aujourd'hui.
DeepSeek-V4-Pro : Rivaliser avec les meilleurs modèles propriétaires
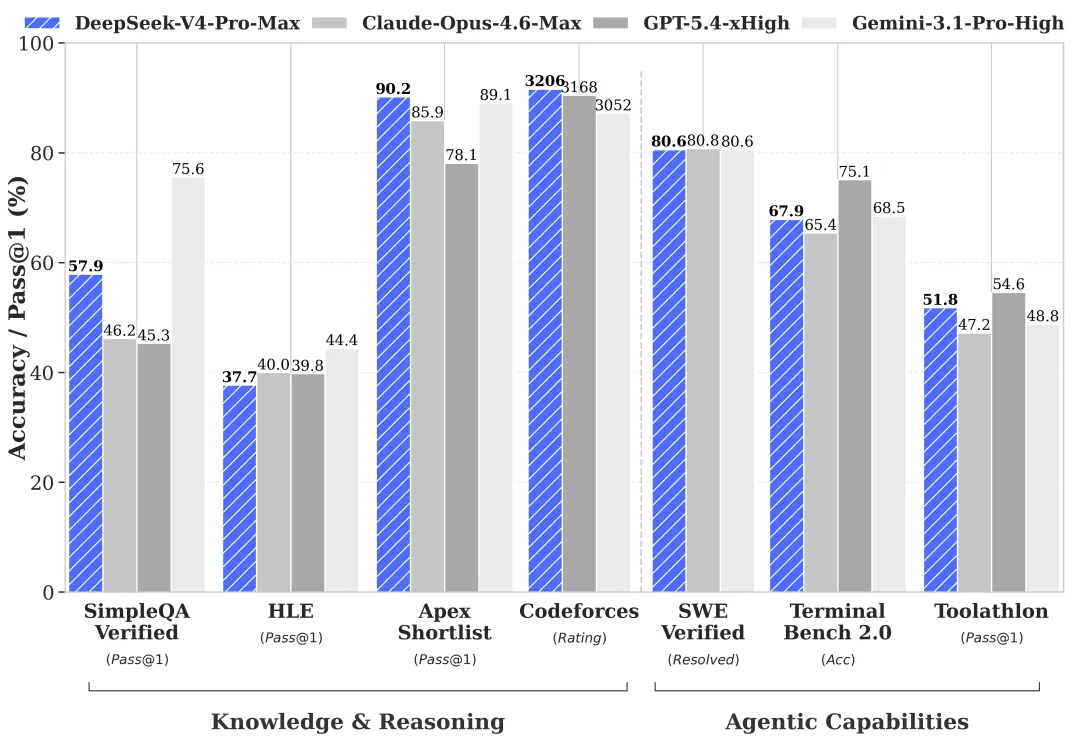
Capacités agentiques considérablement améliorées. Par rapport à son prédécesseur, DeepSeek-V4-Pro affiche une amélioration spectaculaire dans les tâches agentiques. Dans les benchmarks de codage agentique, V4-Pro est désormais en tête parmi tous les modèles open source. DeepSeek a également déployé V4-Pro en interne en tant qu'agent de codage de choix de l'entreprise — les retours des employés indiquent que l'expérience surpasse Claude Sonnet 4.5, avec une qualité de sortie approchant Claude Opus 4.6 en mode sans réflexion, bien qu'il soit encore derrière le mode réflexion d'Opus 4.6.
Richesse des connaissances générales. DeepSeek-V4-Pro surpasse de manière significative les autres modèles open source sur les benchmarks de connaissances générales, ne tombant que légèrement en dessous du meilleur modèle propriétaire, Gemini Pro 3.1.
Raisonnement de classe mondiale. Dans les évaluations en mathématiques, STEM et programmation compétitive, DeepSeek-V4-Pro surpasse tous les modèles open source précédemment évalués et égale les performances des principaux modèles propriétaires mondiaux.
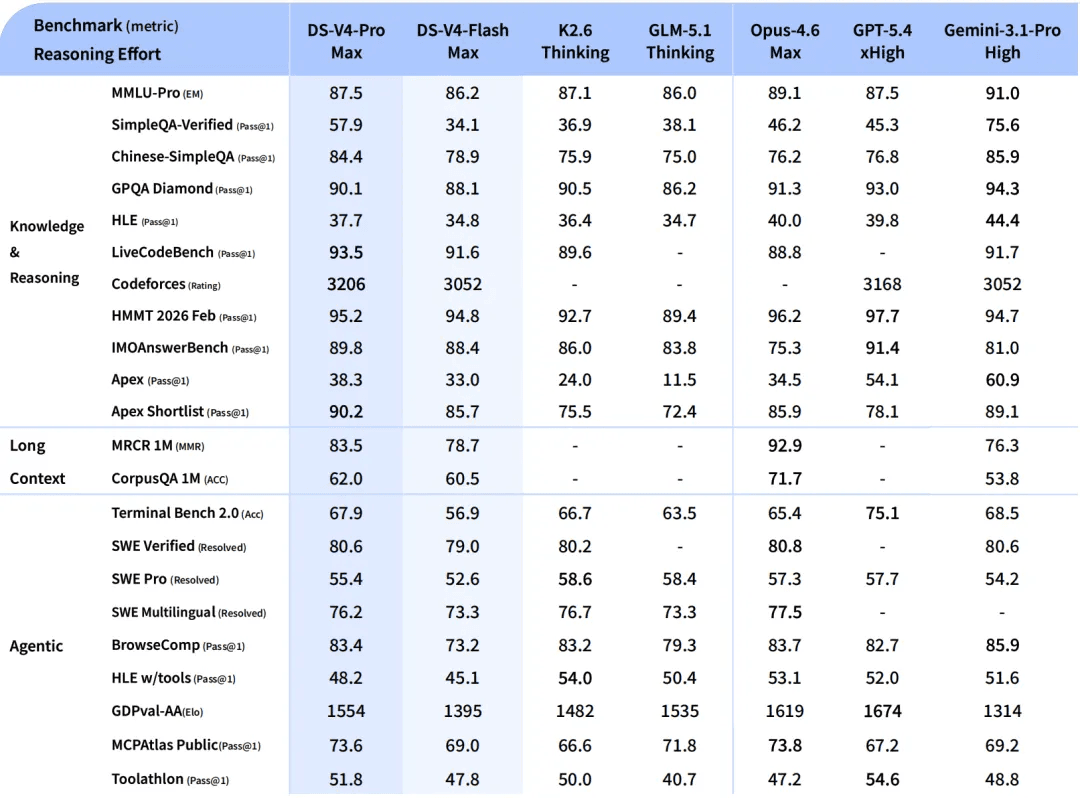
DeepSeek-V4-Flash : Le choix rapide et abordable
Comparé au V4-Pro, DeepSeek-V4-Flash est légèrement en retrait sur les connaissances générales, mais offre des performances de raisonnement comparables. Grâce à son nombre de paramètres plus faible et à ses coûts d'activation réduits, V4-Flash offre des temps de réponse plus rapides et une tarification API plus économique.
Sur les benchmarks d'agents, V4-Flash égale V4-Pro sur les tâches plus simples, bien qu'un écart subsiste sur les plus complexes.
Innovation architecturale et efficacité extrême du contexte
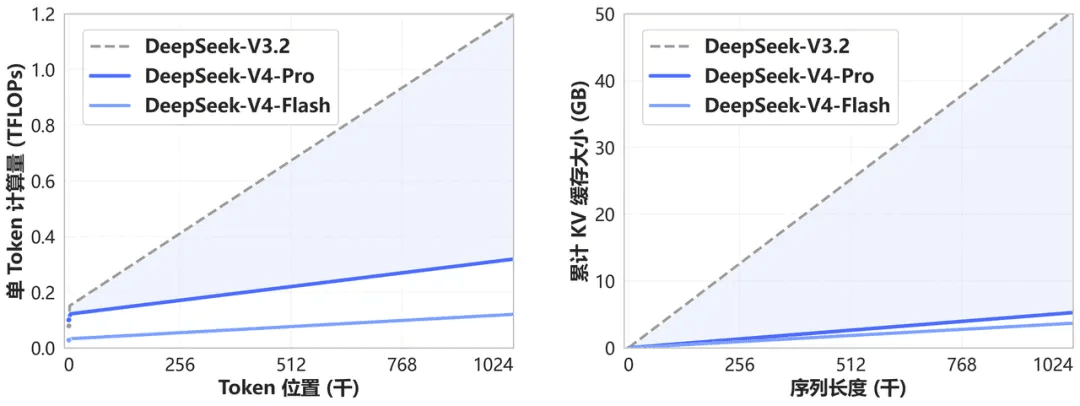
DeepSeek-V4 introduit un mécanisme d'attention novateur qui effectue une compression le long de la dimension des tokens. Associé au DSA (DeepSeek Sparse Attention), cette conception permet d'atteindre des performances long-contexte de premier plan tout en réduisant considérablement les besoins en calcul et en mémoire par rapport aux approches conventionnelles.
À l'avenir, le contexte de 1M (un million) de tokens sera la norme pour tous les services officiels de DeepSeek.
Optimisation spécialisée pour les cas d'usage agentiques
DeepSeek-V4 a été ajusté et optimisé pour des produits d'agents populaires, notamment Claude Code, OpenClaw, OpenCode et CodeBuddy. Des améliorations de performance ont été observées dans la génération de code, la création de documents et d'autres tâches pilotées par des agents.
Ce type d'ajustement spécifique au framework compte plus en pratique qu'il n'y paraît. Un modèle qui fonctionne bien isolément mais qui se comporte de manière incohérente au sein d'une boucle d'agent structurée est difficile à déployer de manière fiable. La décision de traiter les principaux frameworks d'agents comme des cibles d'optimisation de premier ordre reflète l'évolution de l'utilisation de l'IA en production.
Accès API à DeepSeek-V4
V4-Pro et V4-Flash sont désormais disponibles via l'API DeepSeek, avec un support pour les interfaces OpenAI ChatCompletions et Anthropic, ce qui signifie que les intégrations existantes peuvent être redirigées vers les modèles V4 avec un minimum de changements de code. La base_url reste inchangée ; mettez simplement à jour le paramètre model vers deepseek-v4-pro ou deepseek-v4-flash.
Les deux modèles prennent en charge une longueur de contexte maximale de 1M de tokens et offrent des modes sans réflexion et avec réflexion. En mode réflexion, un paramètre reasoning_effort peut être réglé sur high ou max. Pour les flux de travail agentiques complexes, le mode réflexion avec une intensité maximale est recommandé. Documentation pour l'accès API : https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
⚠️ Avis de dépréciation : Les noms de modèles hérités deepseek-chat et deepseek-reasoner seront retirés dans trois mois (24 juillet 2026). Pendant la période de transition, ils correspondent respectivement aux modes sans réflexion et avec réflexion de deepseek-v4-flash. Si vous utilisez l'un ou l'autre de ces noms en production, planifiez votre migration dès maintenant.
Poids Open Source et déploiement local
- Poids du modèle :Hugging Face | ModelScope
- Rapport technique :DeepSeek-V4 PDF
Pour les équipes envisageant un déploiement local ou sur site, il convient de noter que les modèles à cette échelle de paramètres, en particulier V4-Pro avec 1,6T de paramètres au total, imposent des exigences matérielles substantielles. La disponibilité en open source est un avantage significatif pour les cas de conformité et de personnalisation en entreprise, mais la plupart des équipes trouveront que l'accès par API cloud est le point de départ le plus pratique.
Ce que signifie réellement ce lancement de DeepSeek-V4
Trois points ressortent de ce lancement.
Premièrement, l'engagement sur un contexte de 1M est plus significatif qu'il n'y paraît. DeepSeek ne propose pas cela comme une offre premium — c'est le socle pour tous les services officiels. C'est un signal sur la direction que prend la frontière de l'open source, et cela exerce une pression silencieuse sur tous les autres fournisseurs pour qu'ils emboîtent le pas.
Deuxièmement, le travail d'optimisation axé sur les agents — spécifiquement l'adaptation de V4 pour Claude Code, OpenCode et d'autres — reflète une maturité dans la façon dont DeepSeek envisage le déploiement. Les performances sur benchmark sont la base ; ce qui compte pour la production, c'est le comportement au sein des outils que les développeurs utilisent réellement.
Troisièmement, le positionnement concurrentiel honnête par rapport à Claude Opus 4.6 est notable. Plutôt que de prétendre à une supériorité sur toute la ligne, DeepSeek propose une évaluation nuancée : meilleur que Sonnet 4.5, approchant le mode sans réflexion d'Opus 4.6, derrière le mode réflexion d'Opus 4.6. Cette spécificité rend les affirmations plus crédibles.
Pour les développeurs évaluant des modèles pour des flux de travail agentiques, le traitement de longs documents ou des tâches de raisonnement complexe, DeepSeek-V4-Pro est désormais un concurrent open source sérieux. Pour les pipelines optimisés en termes de coûts ou sensibles à la latence, V4-Flash offre une alternative plus légère et crédible.
Essayez DeepSeek-V4 sur Atlas Cloud
Atlas Cloud est une plateforme d'IA de qualité production conçue pour les développeurs et les équipes qui souhaitent un accès fiable et rentable aux principaux modèles d'IA mondiaux sans avoir à gérer l'infrastructure. Avec une API unifiée, une tarification transparente et une conformité de niveau entreprise (alignée SOC 2, prête pour HIPAA), Atlas Cloud vous permet de vous concentrer sur le développement, et non sur les opérations.
DeepSeek sur Atlas Cloud. Nous prenons déjà en charge la famille de modèles DeepSeek, y compris DeepSeek V3.2, V3.2 Fast, V3.2 Speciale et V3.2 Exp disponibles aujourd'hui via un point de terminaison API unique à un tarif compétitif. Les modèles DeepSeek sur Atlas Cloud sont optimisés pour les charges de travail à long contexte et les pipelines d'agents, avec une prise en charge complète de la fenêtre de contexte et aucune perte due à la quantification. Au-delà de DeepSeek, Atlas Cloud vous donne accès à plus de 300 modèles dans tout le paysage LLM.
DeepSeek-V4 arrive sur Atlas Cloud. Nous travaillons activement à l'intégration de DeepSeek-V4-Pro et V4-Flash. Restez à l'écoute pour l'annonce du lancement — et en attendant, explorez tout ce qui est déjà disponible sur la plateforme.






