Début avril, un modèle nommé « HappyHorse-1.0 » est soudainement apparu. Il a dominé quatre catégories du classement vidéo d'Artificial Analysis, surpassant largement Seedance 2.0 de ByteDance et Kling.
Aucun communiqué de presse, aucun article de blog, et le nom de l'entreprise était dissimulé. La page du modèle indiquait simplement « à venir ».
Le 10 avril, la division ATH d'Alibaba a reconnu le projet. HappyHorse est un projet de R&D interne de l'unité d'innovation d'ATH et est actuellement en bêta privée. L'API sera publiée le 30 avril.
De plus, HappyHorse-1.0 sera entièrement open source. Il est présenté comme le premier modèle vidéo open source capable de générer nativement l'audio et la vidéo simultanément.
Ce « lancement discret » suivi d'une « annonce spectaculaire » devient une tendance parmi les entreprises d'IA chinoises. Xiaomi a procédé ainsi avec le nom de code « Hunter Alpha », et Zhipu a utilisé « Pony Alpha » pour son nouveau modèle GLM.
Dans cet article, nous dévoilons les faits connus sur HappyHorse et ce qu'ils signifient.
Position de HappyHorse sur le classement
Artificial Analysis gère quatre classements : texte vers vidéo sans audio, image vers vidéo sans audio, texte vers vidéo avec audio, et image vers vidéo avec audio.
Les données au 13 avril à midi sont les suivantes :
- Texte vers vidéo (sans audio) : 1384 Elo. Il a 111 points d'avance sur Seedance 2.0.
- Image vers vidéo (sans audio) : 1413 Elo. Il s'agit du score le plus élevé jamais enregistré sur la plateforme.
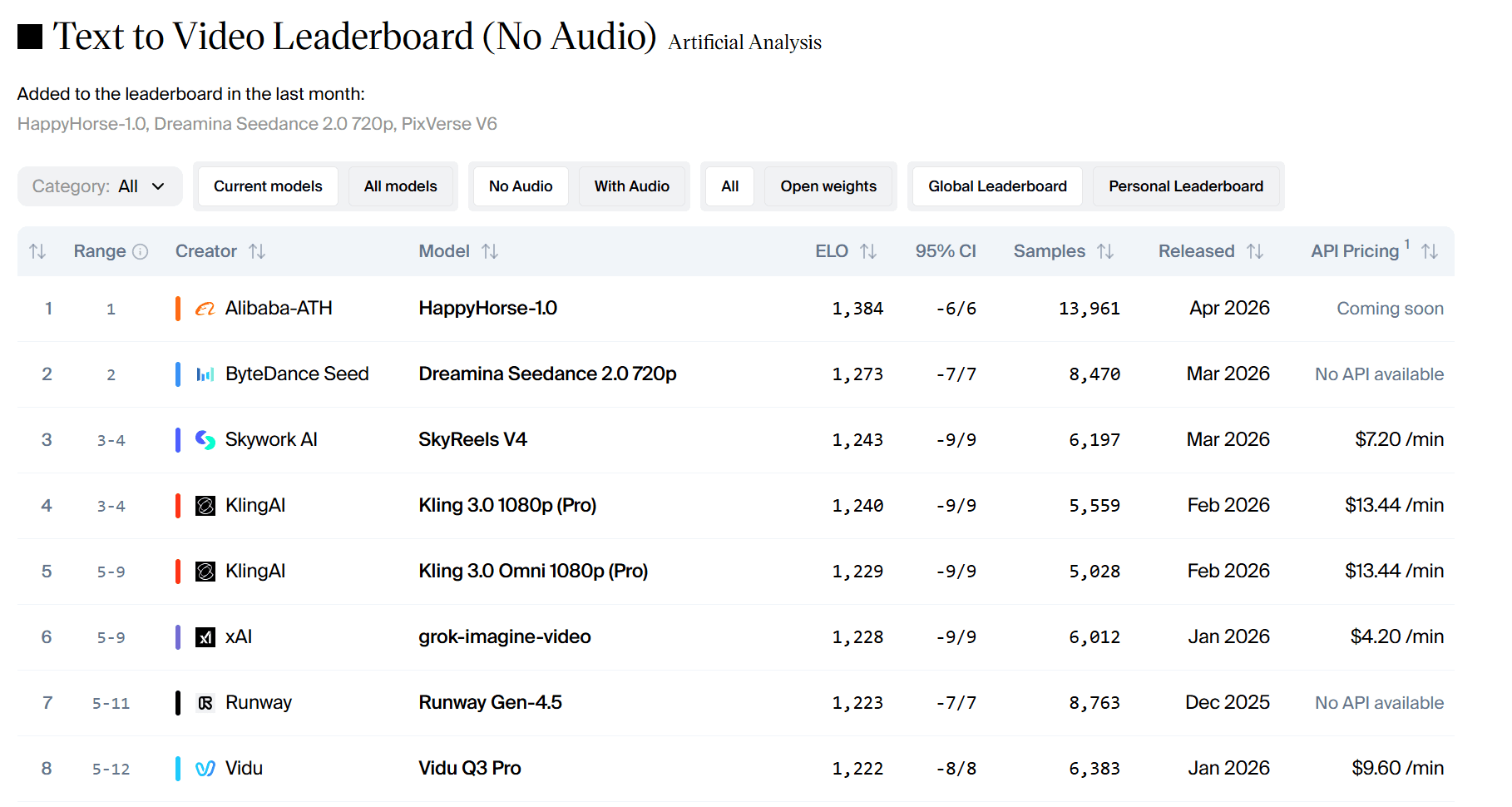
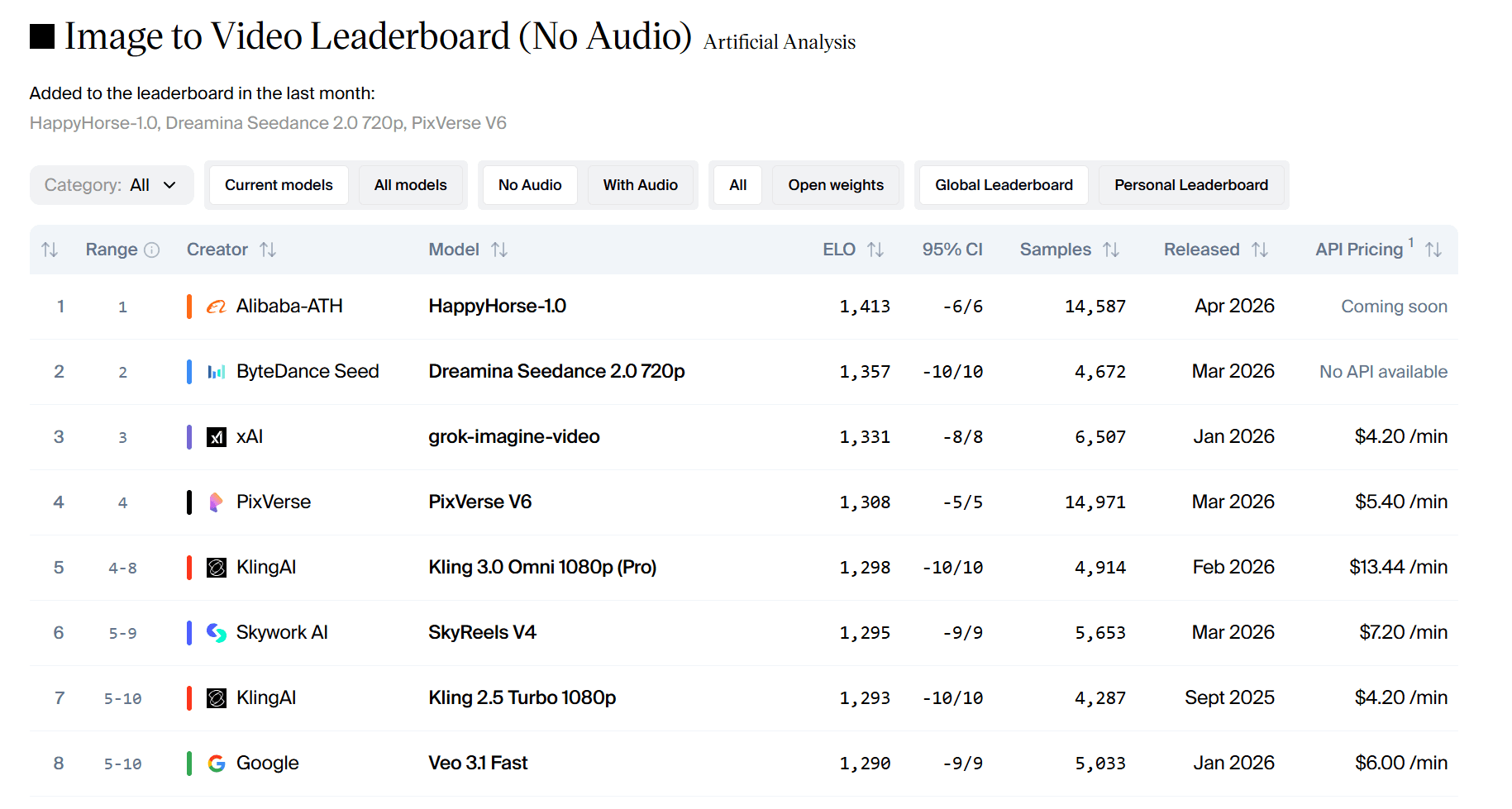
En termes de scores Elo, une différence de plus de 60 points indique une préférence claire. Une différence de 111 points signifie que les utilisateurs ont massivement choisi HappyHorse lors des tests en aveugle.
Cependant, la situation change lorsque l'audio est inclus. La différence se réduit à seulement 1 ou 2 points, ce qui constitue un match nul. Cela montre que la synchronisation audiovisuelle et la qualité sonore de HappyHorse ne sont pas radicalement supérieures. À cet égard, il est à peu près à égalité avec Seedance.
Comparaison entre HappyHorse et Seedance 2.0
| Élément | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| Nature du modèle | Open Source | Système commercial fermé |
| Architecture | Unified Transformer | Bidirectional Diffusion Transformer (DB-DiT) |
| Capacité multimodale | Génération simultanée Audio/Vidéo (One-pass) | Entrée multimodale (Texte, Image, Vidéo, Audio) |
| Mode de génération vidéo | Génération en un passage (One-pass) | Génération basée sur un pipeline |
| Durée de génération vidéo | Env. 5–10 secondes (1080p) | Jusqu'à env. 60 secondes (2K) |
Les deux représentent des philosophies différentes.
HappyHorse‑1.0 : Open source. Unified Transformer. Génération simultanée audio/vidéo. Traitement en un passage. Support natif de la synchronisation labiale pour 7 langues. 15 milliards de paramètres. Il faut 38 secondes pour générer une vidéo 1080p de 5 secondes dans un environnement H100.
Seedance 2.0 : Système commercial fermé. Bidirectional Diffusion Transformer (DB‑DiT). Entrée multimodale. Capable de générer des vidéos 2K de 60 secondes. Supporte la synchronisation labiale pour 8+ langues.
En ce qui concerne la qualité visuelle pure, HappyHorse est clairement préféré lors des tests en aveugle. Concernant la synchronisation audiovisuelle et la qualité sonore, les deux sont à peu près équivalents. Sur le plan de la facilité d'utilisation, Seedance fournit déjà une API mature via des services comme Volcano Engine. L'API de HappyHorse est prévue pour le 30 avril, et ses performances en bêta privée sont toujours en cours de vérification.
Comparaison d'exemples de génération entre HappyHorse-1.0 et Dreamina Seedance 2.0 (Texte vers vidéo avec audio) par Artificial Analysis :
Prompt : Un court métrage d'animation de style Pixar sur un petit cône de signalisation timide qui rêve d'être le cône à la ligne d'arrivée d'une grande course. Les autres cônes se moquent de son ambition. Un ouvrier du bâtiment l'installe accidentellement à la ligne d'arrivée d'un marathon. Alors que les coureurs passent, l'expression peinte sur le cône passe de la peur à la joie. Des confettis pleuvent au-dessus. Les autres cônes le regardent à la télévision et sont inspirés. Audio : Du bruit de circulation aux acclamations de la foule, puis une musique entraînante.
À propos de l'architecture
HappyHorse adopte une approche inhabituelle.
Il compte 15 milliards de paramètres et utilise un Transformer à auto-attention unifié de 40 couches. Les jetons de texte, de vidéo et d'audio sont tous injectés dans la même séquence et modélisés conjointement. C'est très différent du pipeline courant consistant à « générer la vidéo d'abord, puis ajouter l'audio ». Ici, le son et la scène existent dans le même espace sémantique dès le départ.
Ce modèle utilise la distillation DMD-2 et une optimisation complète du graphe via MagiCompiler. Sur un seul GPU H100, il faut environ 38 secondes pour générer une vidéo 1080p de 5 secondes.
Il prend en charge nativement la synchronisation labiale pour 7 langues : anglais, mandarin, cantonais, japonais, coréen, allemand et français. Son taux d'erreur sur les mots (WER) est parmi les plus bas de tous les modèles open source.
Les participants au test en aveugle d'Artificial Analysis affirment que HappyHorse excelle particulièrement dans la représentation des personnages. La texture de la peau et la fluidité des mouvements sont supérieures. Le fait que plus de 60 % des échantillons de test soient des portraits ou des clips de personnes parlant a été un facteur ayant propulsé ce modèle au sommet.
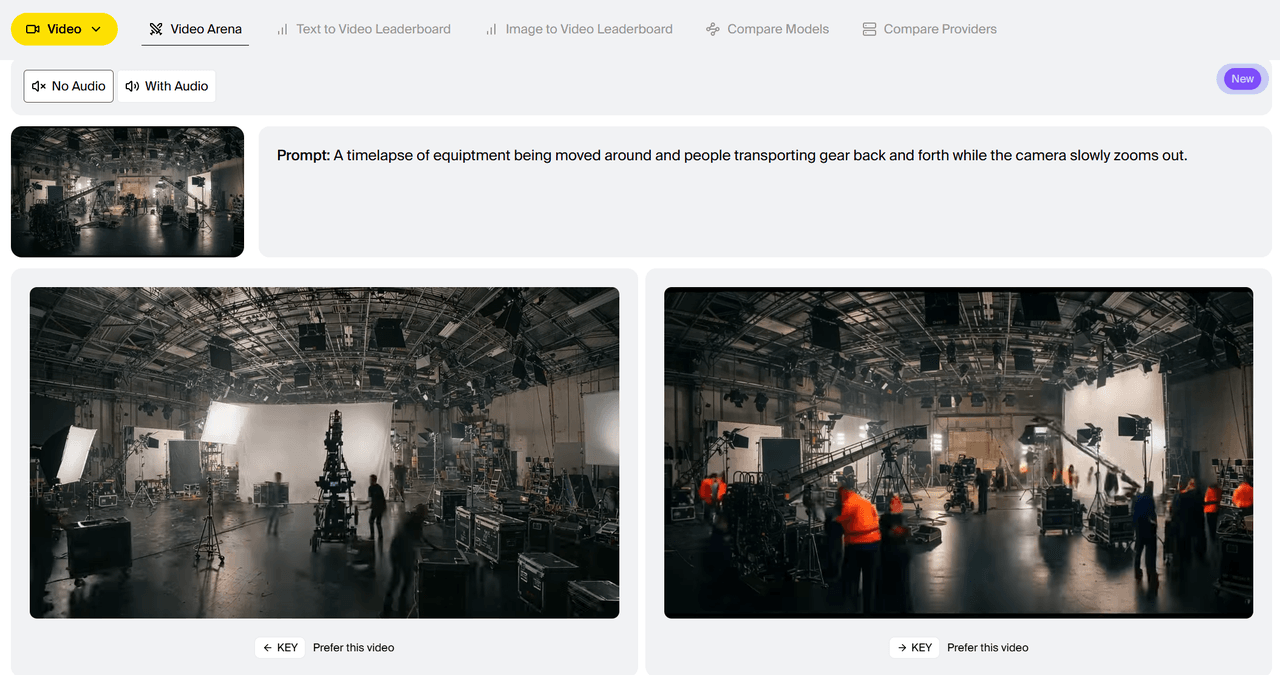
Cependant, il existe des critiques. Des vidéos divulguées ont souligné des ondulations non naturelles, des artefacts de rayures sur les sujets en mouvement rapide et une dégradation de la qualité d'image sur les grands écrans.
Open Source et plan d'accès
Le 9 avril, HappyHorse‑1.0 a annoncé qu'il serait entièrement open source. Le dépôt GitHub est en ligne, les poids sont totalement ouverts, et il n'y a aucune restriction commerciale.
Le site officiel propose des démos en ligne pour la conversion texte-vidéo et image-vidéo. Selon ATH d'Alibaba, l'API devrait être publiée au public le 30 avril.
Cependant, un mot de prudence : selon l'équipe officielle, la plupart des « sites web officiels » circulant en ligne sont des faux. Le vrai site n'est pas encore pleinement opérationnel.
Impact sur le marché et importance
HappyHorse est apparu deux semaines après qu'OpenAI ait arrêté le développement de Sora. Son mouvement a été perçu comme un signe de stagnation dans le domaine de la vidéo IA, mais un modèle chinois a repris le flambeau.
Le marché a réagi rapidement. Le cours de l'action Alibaba a bondi de plus de 7 % après la confirmation et a continué d'augmenter. À la clôture de la séance du 10 avril, elle était en hausse de plus de 3 % à 126,6 HK$.
Au niveau stratégique, HappyHorse montre qu'ATH possède une deuxième équipe capable de créer des modèles multimodaux de premier plan. Cette équipe a une expérience commerciale et comprend les besoins des utilisateurs ainsi que les scénarios commerciaux. Cela a créé une structure à double moteur : le laboratoire Tongyi (axé sur la recherche fondamentale) et l'unité d'innovation (créant des applications à partir de défis commerciaux réels).
Regardons la chronologie. Lin Junyang a démissionné début mars, et ATH a été créé le 16 mars. Le 2 avril, Qwen 3.6 Plus a pris la première place en volume d'appels mondial sur OpenRouter, et le 8 avril, HappyHorse a dominé la liste d'Artificial Analysis. En seulement un mois, Alibaba a produit des résultats puissants à la fois en modèles de langage et en modèles vidéo.
Parcours de l'équipe : Zhang Di et Alibaba ATH
Derrière HappyHorse se trouve le poids lourd Zhang Di.
Il était à l'origine vice-président chez Kuaishou et a servi de leader technique pour Kling AI. Il est connu comme le « père de Kling ». Il a quitté Kuaishou en novembre 2025 et a pris la tête du « Future Life Lab » d'Alibaba, rapportant directement au directeur scientifique Zheng Bo.
Cinq mois plus tard, son équipe a construit HappyHorse‑1.0 et a battu Kling et Seedance 2.0 de ByteDance.
Cette équipe faisait initialement partie du Future Life Lab de Taobao, mais a été transférée à l'unité d'innovation en IA du groupe commercial ATH suite à la dernière réorganisation d'Alibaba.
ATH signifie « Alibaba Token Hub », établi par le PDG Wu Yongming le 16 mars, qui le dirige personnellement. Sa mission est la « création, la fourniture et l'application de jetons », et il intègre le laboratoire Tongyi, la ligne commerciale MaaS, le département Qianwen, le département Wukong et l'unité d'innovation en IA.
FAQ
Quel type de GPU est nécessaire pour faire tourner HappyHorse localement ?
Ce modèle possède 15 milliards de paramètres et n'est en aucun cas petit. Dans un environnement avec un seul H100, il faut environ 38 secondes pour générer une vidéo 1080p de 5 secondes. Les GPU grand public comme la RTX 4090 (24 Go de VRAM) nécessiteront une quantification ou un déchargement. Il est probable qu'il dépasse les 24 Go pour l'inférence FP16. Certains utilisateurs ont rapporté des succès avec la quantification 4 bits, mais la qualité est réduite. Pour une utilisation sérieuse, un GPU cloud avec plus de 40 Go de VRAM est recommandé. Sinon, il est sage d'attendre la sortie de l'API le 30 avril.
Puis-je affiner (fine-tune) HappyHorse avec mes propres données ?
Oui, conformément à la licence. Il n'y a pas de restrictions d'utilisation commerciale. Cependant, affiner un modèle vidéo de 15 milliards de paramètres n'est pas facile. Cela nécessite un cluster H100 ou A100, un grand ensemble de données de paires vidéo-audio, et des ressources d'ingénierie significatives. Le dépôt GitHub ne contient actuellement pas de scripts d'affinage et ne prend en charge que l'inférence. L'équipe a laissé entendre qu'elle publierait le code d'entraînement à l'avenir, mais aucune date n'a été fixée.
Existe-t-il des groupes de communauté Discord ou WeChat ?
Il en existe, mais ils sont non officiels. Plusieurs communautés d'IA ont ouvert des discussions sur Discord et WeChat. L'équipe officielle n'a pas encore ouvert de canaux communautaires formels. Si vous rejoignez un groupe, méfiez-vous des faux liens et des escroqueries par hameçonnage. Il est préférable de consulter le dépôt GitHub et les annonces officielles d'Alibaba ATH pour les dernières informations.
Ce modèle est-il disponible sur Hugging Face ?
Pas au moment de la rédaction. L'équipe a déclaré qu'elle travaillait sur une publication sur Hugging Face, mais ce n'est pas encore terminé. Actuellement, les poids ne sont que sur GitHub. Des membres de la communauté ont commencé à télécharger des points de contrôle convertis sur Hugging Face, mais ceux-ci ne sont pas officiels. Par mesure de sécurité, veuillez utiliser la source GitHub jusqu'à ce que la page officielle Hugging Face apparaisse.






