MiniMax M3 est disponible, et voici l'essentiel : utilisez-le si vous avez besoin d'un modèle à poids ouverts capable de traiter nativement l'image et la vidéo, de gérer un million de jetons de contexte à faible coût, et d'exécuter de longues boucles de codage et d'agents sans réinitialisation. C'est son cas d'usage privilégié ; si vous faites tourner des agents de manière autonome pendant que vous dormez, nous vous recommandons de le tester ! M3 est désormais disponible sur Atlas Cloud.
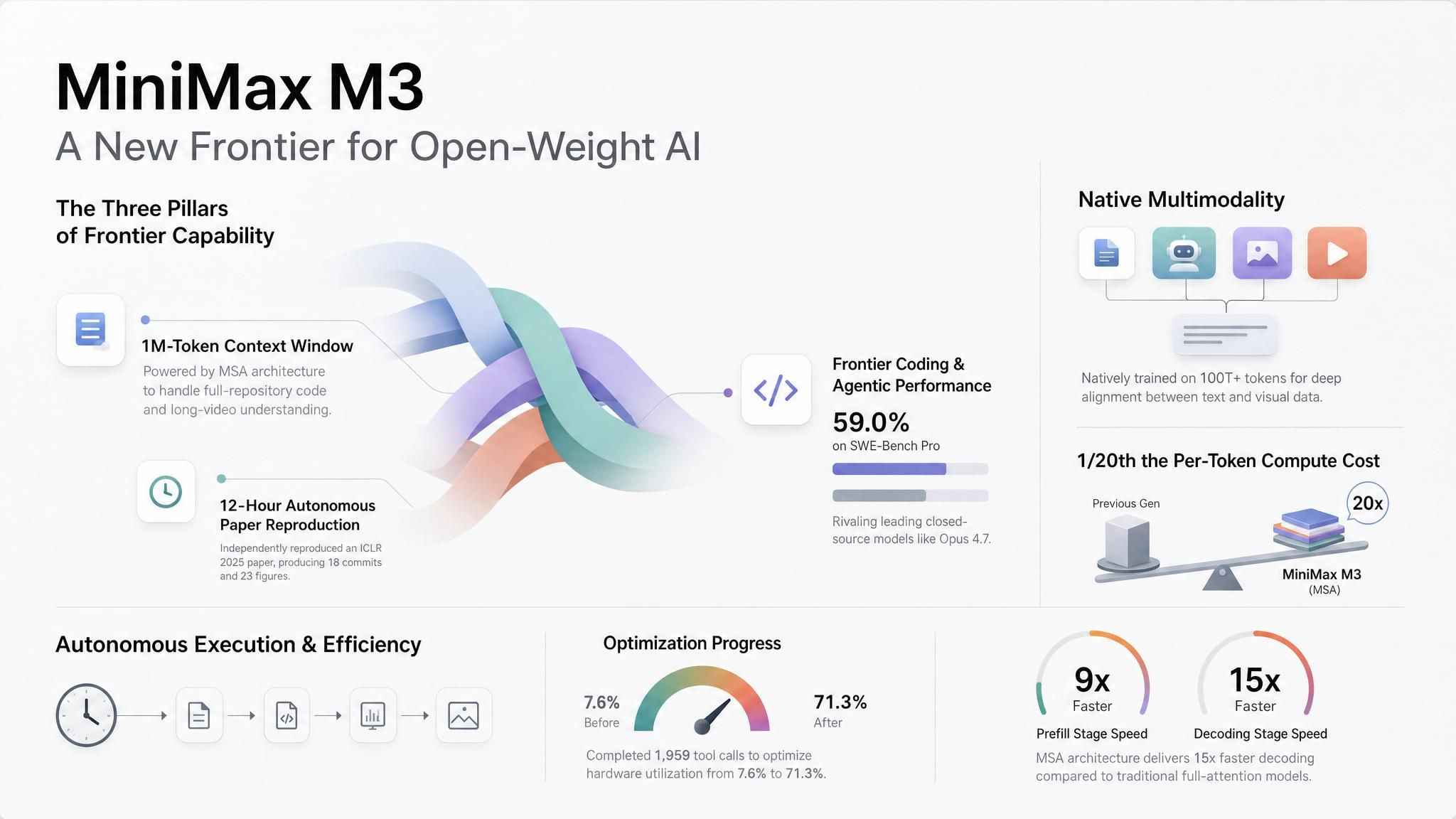
Si vous n'utilisez pas d'agents longue durée, M3 mérite tout de même votre attention pour la direction prise par MiniMax. Ils ont maintenu un contexte de 1M à un coût abordable grâce à une architecture d'attention creuse (MiniMax Sparse Attention, ou MSA) qui réduit le calcul par jeton à environ 1/20e de la génération précédente à contexte complet. Ils y sont parvenus en choisissant la voie la plus rentable compatible avec les infrastructures de service actuelles, plutôt que la plus exotique. Nous prévoyons que cela deviendra la norme pour tous les grands fournisseurs : un contexte long et économique via une attention creuse ou compressée. Cela fait passer la fenêtre de 1M d'un facteur de différenciation à une exigence de base, déplaçant la véritable concurrence à un niveau supérieur : la capacité à router efficacement entre les modèles, plutôt que de tout miser sur un seul d'entre eux.
MiniMax a annoncé M3 le 1er juin 2026. L'API est disponible dès maintenant, et l'entreprise prévoit de publier le rapport technique et les poids dans les 10 jours suivant l'annonce.
Si vous utilisez déjà un autre modèle de pointe
M3 mérite d'être testé lorsque vos besoins nécessitent un espace de travail plus vaste, un contexte visuel, ou une boucle d'agent plus longue que ce que gère votre modèle habituel. La colonne importante ici est la dernière : ce que M3 apporte réellement par rapport au modèle que vous utilisez déjà.
| Modèle actuel | Pour cet usage | Ce que M3 apporte réellement |
|---|---|---|
| GPT-5.5 ou GPT-5.5 Pro | Codage agentique, utilisation d'ordinateur, recherche, analyse de données et automatisation | Entrée vidéo native et une voie vers des poids ouverts — une seconde route d'agent avec une courbe de coût différente que vous pourrez auto-héberger. (GPT-5.5 gère déjà l'image, testez donc la vidéo et le modèle économique.) |
| Claude Opus 4.8 | Agents de codage longue durée, recherche documentaire intensive et utilisation d'outils | Une alternative à poids ouverts et moins coûteuse pour comparer les performances sur des dépôts complets et le coût par tâche. Opus 4.8 offre déjà 1M de contexte et la vision ; le test réel porte sur le prix, l'entrée vidéo et l'économie de la tâche. |
| Qwen3.7-Plus (multimodal) | Agents de vision et GUI, capture d'écran vers code, automatisation de navigateur | Une multimodalité comparable avec un positionnement plus fort sur le codage/agentique et une voie vers des poids ouverts. (Qwen3.7-Plus est propriétaire, via API uniquement.) |
| Qwen3.7-Max (flagship texte) | Raisonnement textuel, agents à long horizon, automatisation de bureau | Entrée image et vidéo native dans le même contexte. Qwen3.7-Max est limité au texte ; pour la vision, vous devriez normalement basculer sur la version Plus. |
| DeepSeek-V4-Pro ou Flash | Raisonnement, codage, appels d'outils et contexte long à prix maîtrisé | Multimodalité native (image et vidéo) en plus du contexte long. DeepSeek-V4 est limité au texte, M3 est l'alternative multimodale dès qu'un signal visuel est présent. |
Le test pratique est simple. Essayez M3 si vous cherchez à :
- conserver le dépôt, l'historique des tâches, les journaux et le plan actuel dans un contexte unique ;
- laisser un agent poursuivre son travail après des dizaines d'appels d'outils au lieu de réinitialiser la conversation ;
- raisonner sur du code, du texte, des captures d'écran, des graphiques, des PDF et des images vidéo en un seul passage ;
- réduire les transferts entre un modèle de texte, un modèle de vision et une couche de récupération séparée ;
- comparer le coût par tâche complétée en contexte long, et non le simple prix par million de jetons.
Ne changez pas simplement parce qu'un graphique de lancement est impressionnant. Changez lorsque M3 complète une tâche que votre stack actuelle échoue à traiter, tronque, facture trop cher ou répartit sur trop de modèles.
Où M3 se révèle utile
Des agents avec de l'espace pour travailler. Les exemples de lancement de MiniMax vont au-delà des démos de chat habituelles. Lors d'un test, M3 a reproduit les expériences principales d'un article distingué à l'ICLR 2025 après près de 12 heures d'exécution, produisant 18 commits et 23 figures expérimentales. Dans un autre, il a travaillé pendant 24 heures sur un noyau CUDA FP8 GEMM, effectuant 147 soumissions de benchmark et 1 959 appels d'outils, faisant passer l'utilisation matérielle de 7,6 % à 71,3 %.
Ne voyez pas ces exemples comme la preuve qu'un agent d'une journée fonctionnera dès votre premier prompt. Ils montrent pourquoi M3 doit figurer sur votre liste de présélection pour les flux de travail où le modèle doit planifier, utiliser des outils, inspecter les résultats, réviser et poursuivre après un échec initial.
Contexte à l'échelle du dépôt et du document. M3 prend en charge jusqu'à 1M de jetons via l'API, avec un minimum garanti de 512K. À une longueur de 1M de jetons, MiniMax indique un coût de calcul par jeton 20 fois inférieur à la génération précédente, avec un pré-remplissage 9x plus rapide et un décodage 15x plus rapide.
Cela change la conception des produits. Un agent de codage peut "voir" davantage de code. Un assistant de recherche peut conserver une traînée de preuves plus longue. Un outil de revue de contrat peut garder le matériau source et l'analyse dans le même espace de travail.
Contexte visuel dans la même requête. MiniMax a entraîné M3 avec des données multimodales dès le départ. Le modèle accepte des entrées image et vidéo, et peut traiter du texte, des images et des vidéos entrelacés dans un même contexte.
Cela réduit les transferts entre modèles. Un flux de support peut lire le message de l'utilisateur et inspecter la capture d'écran. Un agent d'utilisation d'ordinateur peut observer l'écran et décider de l'action suivante sans transférer l'étape visuelle vers un modèle tiers.
Accès hébergé maintenant, poids bientôt. MiniMax traite M3 comme une version à poids ouverts, mais l'accès initial se fait par API hébergée. Cela offre une séquence utile : testez le modèle hébergé maintenant, puis décidez si la future version des poids convient à un déploiement privé ou un fine-tuning.
Une tarification claire. Les appels API inférieurs ou égaux à 512K jetons en entrée utilisent le tarif standard. Une tarification spécifique pour le contexte long s'applique au-delà de 512K. M3 propose également une option de "réflexion" au même prix, permettant aux équipes d'utiliser un mode de raisonnement pour les tâches complexes ou un mode rapide pour les complétions sensibles à la latence.
À quoi ressemble le coût opérationnel
MiniMax M3 sur Atlas Cloud est tarifé à USD0.30/M jetons en entrée et USD1.20/M jetons en sortie. Claude Opus 4.7 est à USD5/M en entrée et USD25/M en sortie, tandis que GPT-5.5 est à USD5/M en entrée et USD30/M en sortie.
Cela rend M3 :
- 94 % moins cher en entrée qu'Opus 4.7 et GPT-5.5 ;
- 95,2 % moins cher en sortie qu'Opus 4.7 ;
- 96 % moins cher en sortie que GPT-5.5.
Le prix des jetons ne compte qu'après avoir été rapporté à la nature de la charge de travail. Un agent de codage avec un gros dépôt consomme surtout de l'entrée. Un flux de recherche avec de longues explications consomme plus de sortie.
| Modèle | Tarif utilisé | 100K entrée + 5K sortie | 500K entrée + 20K sortie | Lecture du coût |
|---|---|---|---|---|
| MiniMax M3 | USD0.30 / USD1.20 | USD0.04 | USD0.17 | Route multimodale bas coût. |
| DeepSeek V4 Flash | USD0.14 / USD0.28 | USD0.02 | USD0.08 | Moins cher pour le texte pur. |
| DeepSeek V4 Pro | USD0.435 / USD0.87 | USD0.05 | USD0.23 | Proche de M3, mais texte uniquement. |
| Qwen3.7-Plus | Tarifs variables | USD0.05 | USD0.70 | Compétitif pour les appels courts. |
| Claude Opus 4.8 | USD5 / USD25 | USD0.63 | USD3.00 | Premium pour codage haute fiabilité. |
| GPT-5.5 | USD5 / USD30 | USD0.65 | USD5.90 | Pour l'usage d'outils avancé. |
Notre recommandation : Traitez les modèles coûteux comme des routes qui doivent justifier leur prix. Si GPT-5.5 ou Opus 4.8 termine une tâche difficile en un essai alors que M3 nécessite trois tentatives et une correction humaine, l'option "bon marché" ne l'était pas. Si M3 atteint le niveau de qualité requis pour vos analyses multimodales, le triage de code ou l'automatisation, ses performances économiques en font un sérieux candidat.
Lisez les benchmarks comme des données fournisseurs
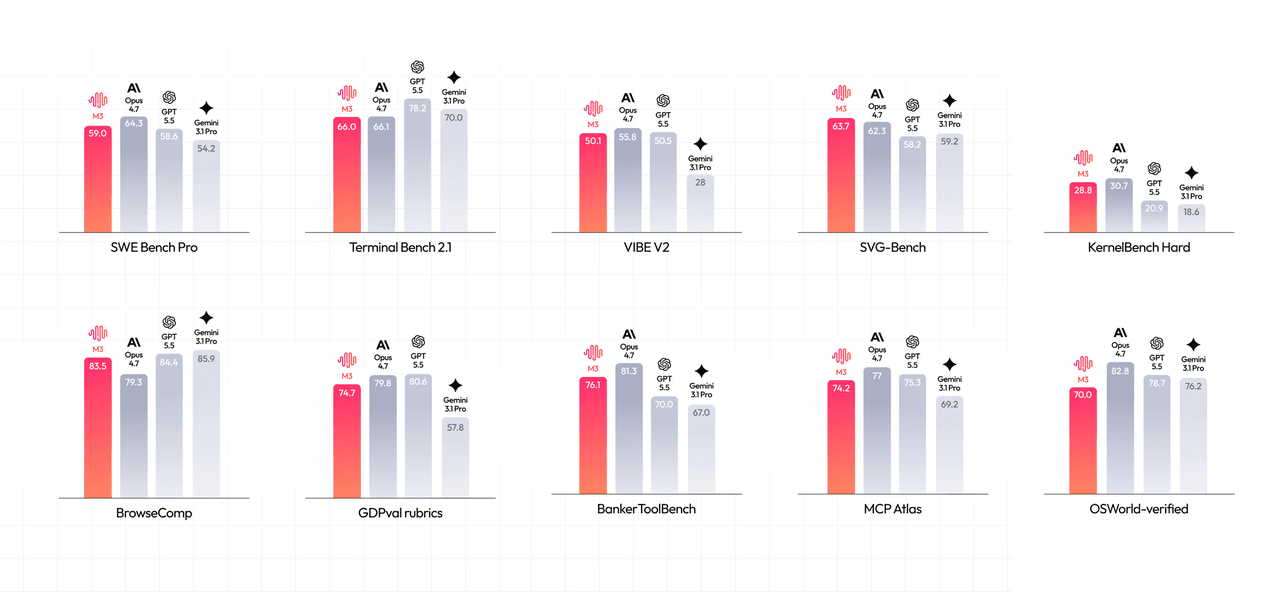
MiniMax rapporte des scores solides en codage et tâches agentiques :
- SWE-Bench Pro : 59,0 %
- Terminal-Bench 2.1 : 66,0 %
- SWE-fficiency : 34,8 %
- KernelBench Hard : 28,8 %
- MCP-Atlas (benchmark tiers) : 74,2 %
- BrowseComp : 83,5 (vs 79,3 pour Claude Opus 4.7)
Une remarque sur ce dernier point : MiniMax compare M3 à Opus 4.7, alors qu'Opus 4.8 est sorti quatre jours avant M3. La comparaison était déjà obsolète dès le premier jour.
Ces scores sont utiles pour le triage, mais insuffisants pour une décision de production. Avant d'utiliser un score dans une décision d'architecture, réexécutez la tâche avec vos propres documents, prompts et objectifs de latence.
Comment évaluer M3 face aux modèles actuels
Utilisez M3 comme candidat à l'évaluation, pas comme choix par défaut. Une fenêtre de 1M peut masquer une architecture médiocre si vous la saturez de fichiers inutiles.
Réalisez ces six tests :
- Codage sur dépôt complet : Donnez à chaque modèle le même problème, accès aux outils et timeout. Scorez la qualité des patchs et le taux d'édition inutile.
- Récupération en contexte long : Placez des détails pertinents au début, au milieu et à la fin. Ajoutez des distracteurs.
- Endurance des boucles d'outils : Exécutez une tâche nécessitant 30 à 100+ appels d'outils. Observez si le modèle maintient un plan stable.
- Travail d'agent visuel : Soumettez un ticket de support avec captures d'écran, ou des graphiques. Mesurez le coût du transfert vers un modèle de vision dédié pour les modèles texte-seulement.
- Latence en contexte réel : Comparez le temps au premier jeton (TTFT) à 128K, 512K et 1M.
- Coût par tâche complétée : Prenez en compte les retries et les appels d'outils.
C'est ici que la plupart des équipes se trompent : elles demandent quel modèle a le meilleur benchmark de lancement. La question de production est : quel modèle complète ce flux de travail à la qualité, latence et coût que mon produit peut tolérer ?
Comment MSA maintient l'utilisabilité du contexte long
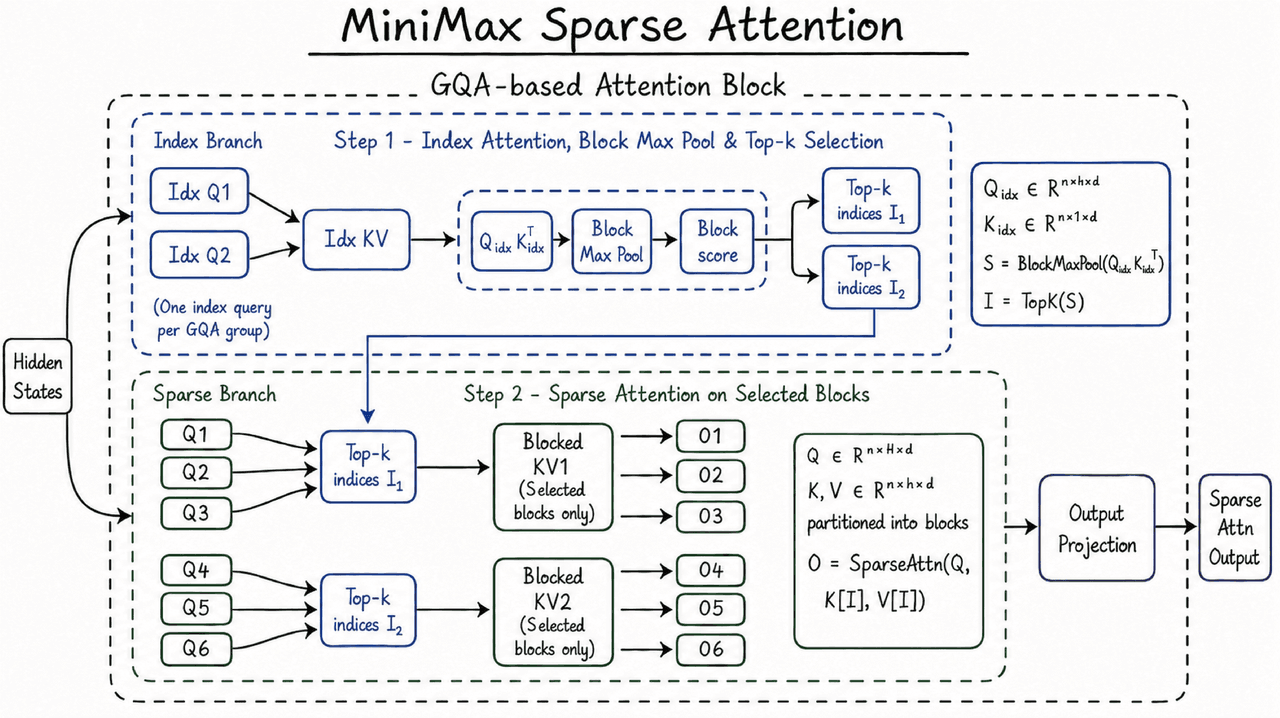
La fenêtre de contexte de M3 repose sur la MiniMax Sparse Attention (MSA).
L'attention complète permet à chaque jeton de se focaliser sur tout autre jeton, avec une complexité quadratique. L'attention creuse ajoute une étape de sélection pour se concentrer sur les parties les plus pertinentes du contexte précédent.
MiniMax indique que MSA partitionne le cache KV en blocs et effectue la sélection au niveau du bloc. Cette conception est plus de 4x plus rapide que les solutions open-source "Flash-Sparse-Attention". Cette avancée technique est cruciale car une fenêtre de 1M est inutile si elle est inabordable ou trop lente.
La tendance : les lancements de modèles deviennent des événements de routage
La tendance est claire : en six semaines, quatre modèles 1M-contexte sont sortis (DeepSeek V4, Qwen3.7-Max, Claude Opus 4.8, MiniMax M3). La fenêtre 1M n'est plus un différenciateur, c'est devenu la norme.
L'avantage d'un modèle spécifique s'estompera plus vite que le travail d'intégration qui l'entoure. Le gagnant n'est pas l'équipe qui choisit un modèle et le défend pendant un an. Le gagnant est celle qui peut tester M3 aujourd'hui, le comparer à GPT-5.5, Claude Opus 4.8, Qwen3.7 et DeepSeek-V4 demain, et transférer le trafic dès que les indicateurs le dictent.
Pourquoi passer par Atlas Cloud
Atlas Cloud offre une clé API unique pour 300+ modèles. Cela permet de tester M3 face à vos modèles actuels, de router le trafic là où il est le plus performant, et de garder votre surface d'intégration stable.
Utilisez M3 là où son contexte long et sa multimodalité sont rentables. Gardez les autres modèles là où ils excellent. Changez en fonction des évaluations, pas de la hype de la semaine de lancement.
[CTA : Exécuter M3 sur Atlas Cloud -> atlascloud.ai/models | Obtenir une clé API -> console.atlascloud.ai]






