Gemini Omni marque un changement majeur par rapport aux systèmes d'IA traditionnels. Il fonctionne comme un modèle d'IA tout-en-un qui traite l'information de manière naturelle dès le départ. Plutôt que de combiner différents outils pour chaque type de média, il s'appuie entièrement sur un moteur neuronal universel. En traitant le texte, l'image, l'audio et la vidéo au sein d'un espace vectoriel cross-modal unique, il élimine totalement les silos de données obsolètes et les goulots d'étranglement de communication.
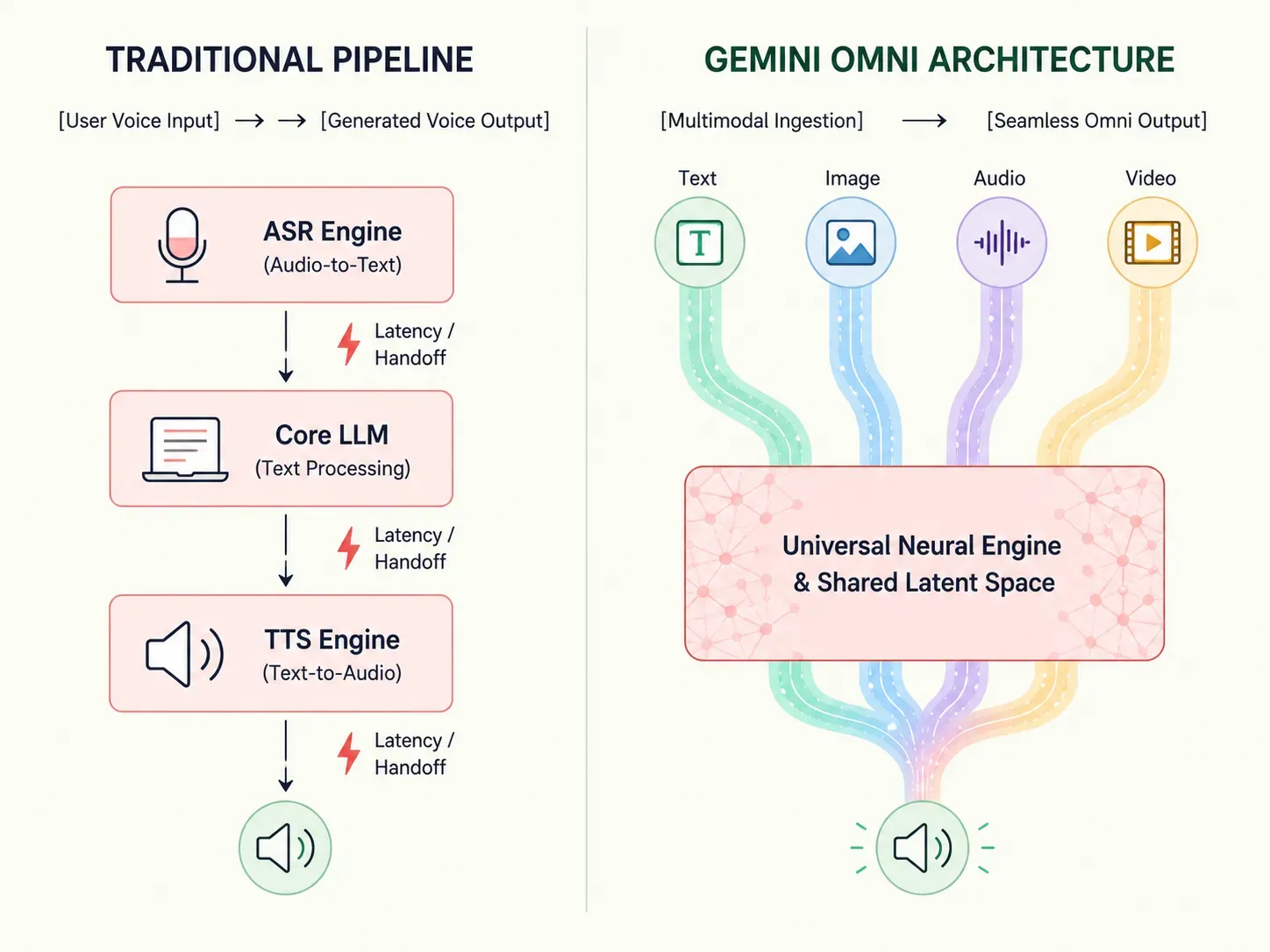
L'intelligence artificielle traditionnelle repose sur des pipelines échelonnés, convertissant la voix en texte avant même qu'un modèle linguistique ne puisse commencer à traiter une réponse. Gemini Omni redéfinit fondamentalement ce flux de travail.
- Ingestion native : Le système traite les jetons (tokens) textuels, les pixels d'image, les fréquences audio et les trames vidéo simultanément.
- Préservation du contexte : Le traitement de bout en bout permet d'éviter que les émotions subtiles, les repères visuels et les petits détails ne soient perdus entre les différentes couches.
Ce changement structurel améliore l'efficacité du traitement et réduit les délais à des temps de réponse proches de ceux de l'humain. Les développeurs et les entreprises peuvent désormais se passer de configurations multi-modèles complexes et s'appuyer sur un système robuste conçu pour une véritable informatique multisensorielle.
Comment un seul modèle calcule quatre modalités simultanément
Pour comprendre comment les fonctionnalités de Gemini Omni traitent le texte, les images, l'audio et la vidéo simultanément, il faut examiner directement sa couche de données fondamentale. Les systèmes traditionnels acheminent différents types de fichiers via des sous-modèles distincts et isolés. Gemini Omni contourne complètement cette méthode fragmentée. Il implémente un framework de tokenisation unifié qui traduit nativement toutes les entrées dans un langage unique compris par le cœur de l'IA.
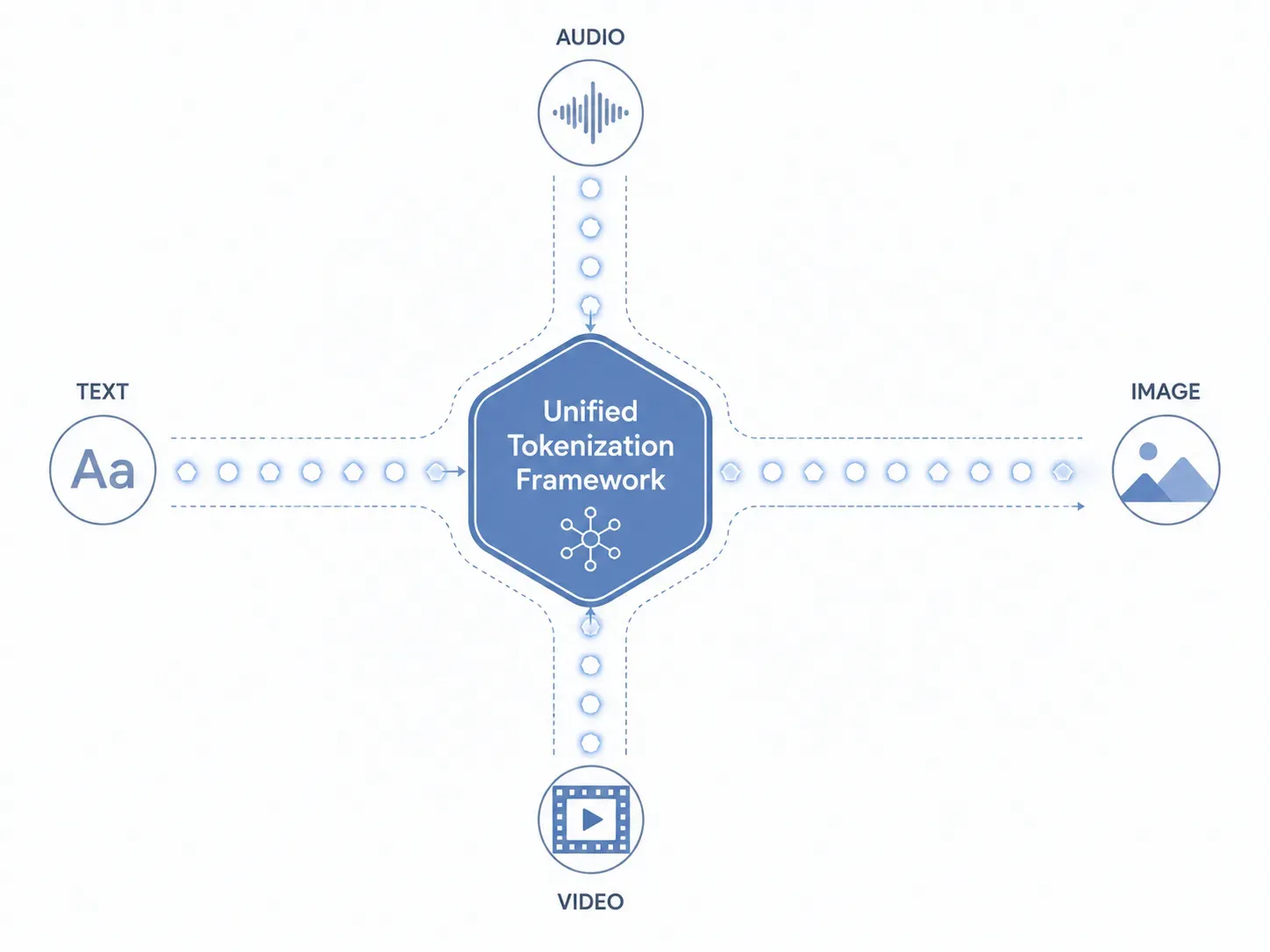
Les mécanismes de la tokenisation unifiée
Comment Gemini Omni gère-t-il différents types de fichiers sans sous-modèles séparés ? La réponse réside dans la manière dont les données sont ingérées et décomposées avant le début de l'inférence :
- Texte : Les caractères alphanumériques sont convertis en jetons textuels sémantiques standard.
- Images : Les éléments visuels sont découpés en petits patchs de pixels et mappés en tant que jetons visuels.
- Audio : Les ondes sonores continues sont échantillonnées, capturant la fréquence et le ton, puis transformées en jetons acoustiques.
- Vidéo : Les images animées sont traitées comme une séquence continue de trames temporelles, établissant des jetons spatio-temporels.
Poids partagés et traitement tensorial natif
Une fois cette ingestion de données multimodales diversifiée terminée, tous les types de données entrent dans une architecture à poids partagés. Au lieu d'utiliser des encodeurs spécialisés individuels qui échangent des données via des ponts générateurs de latence, un seul réseau neuronal central traite tous les jetons uniformément.
Grâce au traitement tensorial natif, le modèle exécute des calculs mathématiques sur les jetons textuels, audio et visuels au sein des mêmes couches matricielles. Comme tout partage le même espace de calcul, le réseau comprend directement la relation entre un mot parlé, une phrase écrite, un pixel d'image et une trame vidéo, sans aucune étape de traduction intermédiaire.
Pour voir ces principes d'ingénierie et la tokenisation native déployés à grande échelle dans des scénarios réels, regardez la présentation « Research Vision » du MIT Media Lab. Cette présentation souligne l'évolution de l'industrie vers la connexion directe des modèles d'IA avec un riche spectre de signaux du monde physique et multisensoriel.
Les piliers des modalités : Carte de traitement cross-média
Pour saisir la puissance de Gemini Omni, il faut voir au-delà de la simple ingestion de données. Le modèle utilise une architecture unifiée où le texte, les images, l'audio et la vidéo coexistent au sein d'une cartographie d'espace latent partagée. Lorsqu'une entrée change dans une modalité, cela ne déclenche pas seulement une réaction isolée : cela modifie dynamiquement les paramètres mathématiques des trois autres formats simultanément.
La matrice d'interdépendance multimodale
Cette inférence cross-média en temps réel repose sur des flux de données interdépendants. Au lieu de traiter les données par blocs séquentiels, le modèle synchronise en permanence les quatre piliers pour obtenir un alignement multimodal parfait.
La carte de traitement ci-dessous décrit exactement comment ces entrées en direct s'influencent mutuellement au sein du réseau neuronal universel :
| Entrée média primaire | Modalités co-traitées | Opération système | Intention technique profonde |
| Formes d'ondes acoustiques | Texte + Trames vidéo | Suit la cadence vocale pour indexer les séquences vidéo temporelles | Alignement sensoriel en temps réel |
| Images statiques | Audio brut + Texte | Traduit les spectres de couleurs visuels en acoustiques contextuelles correspondantes | Synthèse cross-modale |
| Code alphanumérique | Tableaux vidéo + Texte | Modifie les variables vidéo structurelles directement via la logique de programmation | Exécution de code génératif |
| Séquences vidéo temporelles | Pistes audio + Code | Calcule les mises à jour spatio-temporelles sur des pistes de données multicouches | Analyse vidéo-audio unifiée |
Synchronisation des paramètres en temps réel
Lorsque Gemini Omni traite un flux vidéo en direct, il ne sépare pas les visuels de la piste sonore. Si l'entrée audio enregistre un pic soudain de fréquence — comme une personne qui crie — le modèle met instantanément à jour ses attentes en matière de jetons visuels. Il anticipe un mouvement physique rapide ou un changement dans les trames vidéo avant même qu'ils ne se produisent.
Cette influence croisée profonde empêche la dérive du contexte. Comme l'ensemble du réseau équilibre ces variables simultanément, la sortie reste parfaitement cohérente, que le modèle génère un résumé vidéo synchronisé ou traduise un flux multisensoriel en direct.
Éliminer la latence et la dérive de contexte : L'avantage des poids unifiés
Pour apprécier la vitesse de Gemini Omni, il est utile d'observer les inefficacités mathématiques des pipelines d'IA traditionnels « assemblés ». Historiquement, la création d'un assistant capable de gérer la voix ou la vidéo nécessitait d'enchaîner des couches logicielles distinctes à usage unique.
plaintext1[Entrée vocale utilisateur] 2 │ 3 ▼ 4 1. Moteur ASR (Transcription audio-vers-texte) 5 │ 6 ▼ 7 2. Couche LLM centrale (Traitement de génération de texte) 8 │ 9 ▼ 10 3. Moteur TTS (Synthèse texte-vers-audio) 11 │ 12 ▼ 13[Sortie vocale générée]
Cette orchestration en plusieurs étapes force les données à transiter par des ponts logiciels, ce qui aggrave les délais d'exécution. Le moteur de synthèse vocale distinct ne peut pas « entendre » l'enregistrement audio original. Cela entraîne une perte massive de données entre les différents types de médias. Les signaux vocaux importants, comme le ton sarcastique, les hésitations ou la détresse émotionnelle de l'utilisateur, disparaissent complètement une fois aplatis en texte brut.
Atteindre une réduction réelle de la latence du pipeline
Gemini Omni contourne ces limites en opérant sur des poids neuronaux unifiés. Comme un seul réseau neuronal évalue nativement le texte, l'audio et les pixels sous un même toit mathématique, il augmente considérablement les vitesses d'exécution. Cette disposition permet une réduction profonde de la latence du pipeline.
Selon les rapports d'analyse de Google DeepMind, les architectures multimodales natives exécutant des flux audio en direct réduisent les temps de réponse de bout en bout à moins de 150 millisecondes. Ce changement correspond effectivement au tempo naturel d'une conversation humaine en temps réel.
Optimisation de la rétention de contexte
Au-delà de la vitesse pure, l'exécution unifiée garantit un haut niveau d'optimisation de la rétention de contexte. Lorsque vous parlez au modèle, les poids traitent simultanément vos fréquences audio et vos définitions textuelles.
- Traitement de l'intonation : Le réseau capture les modulations vocales directement, répondant avec l'empathie ou l'urgence appropriée.
- Synchronisation visuelle : Les micro-expressions faciales subtiles ou les mouvements spatiaux dans une trame vidéo se traduisent directement dans la sortie conversationnelle sans erreurs d'analyse.
En supprimant les étapes de traduction intermédiaires, Gemini Omni empêche les petits détails de s'estomper. Cela constitue une base solide pour des interactions fluides et naturelles entre les humains et les machines, à travers tous les sens.
Construire des workflows d'entreprise avec des systèmes d'IA omnicanaux
Ce passage à la multimodalité native change la manière dont les entreprises créent et déploient leurs outils numériques. En utilisant une configuration d'IA tout-en-un, les entreprises peuvent remplacer des pièces logicielles disparates et complexes par des workflows unifiés. Cela leur permet d'exécuter facilement des systèmes interactifs multimédias à grande échelle.
L'architecture API unique
Les développeurs n'ont plus besoin de coordonner des fonctions cloud disparates pour la reconnaissance vocale, l'analyse de texte et le traitement d'image. Au lieu de cela, une intégration API unifiée connecte la couche applicative directement au réseau central, comme l'API de modèle Atlas Cloud AI. Ce chemin simplifié permet aux équipes de construire des pipelines cross-média avancés avec un framework de requête unique.
plaintext1 ┌─────────────────────────────────┐ 2 │ Unified Gemini API │ 3 └────────────────┬────────────────┘ 4 │ 5 ┌─────────────────────────┼─────────────────────────┐ 6 ▼ ▼ ▼ 7┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ 8│ Code en direct │ │ Données multimédia │ │ Tableaux de bord │ 9│ & Sync actifs │ │ Couche automat. │ │ multisensoriels │ 10└──────────────────┘ └──────────────────┘ └──────────────────┘
Par exemple, une plateforme de formation en entreprise peut traiter un flux vidéo en direct, suivre la cadence audio d'un intervenant, traduire le dialogue et mettre à jour dynamiquement un tableau de bord de données visuelles simultanément — le tout piloté par un seul système backend.
Avantages du déploiement stratégique
Quels sont les avantages de déploiement lors du passage à une architecture de modèle tout-en-un ?
Passer des anciennes configurations multi-modèles à un réseau neuronal unique offre des avantages immédiats et solides pour les systèmes informatiques des entreprises :
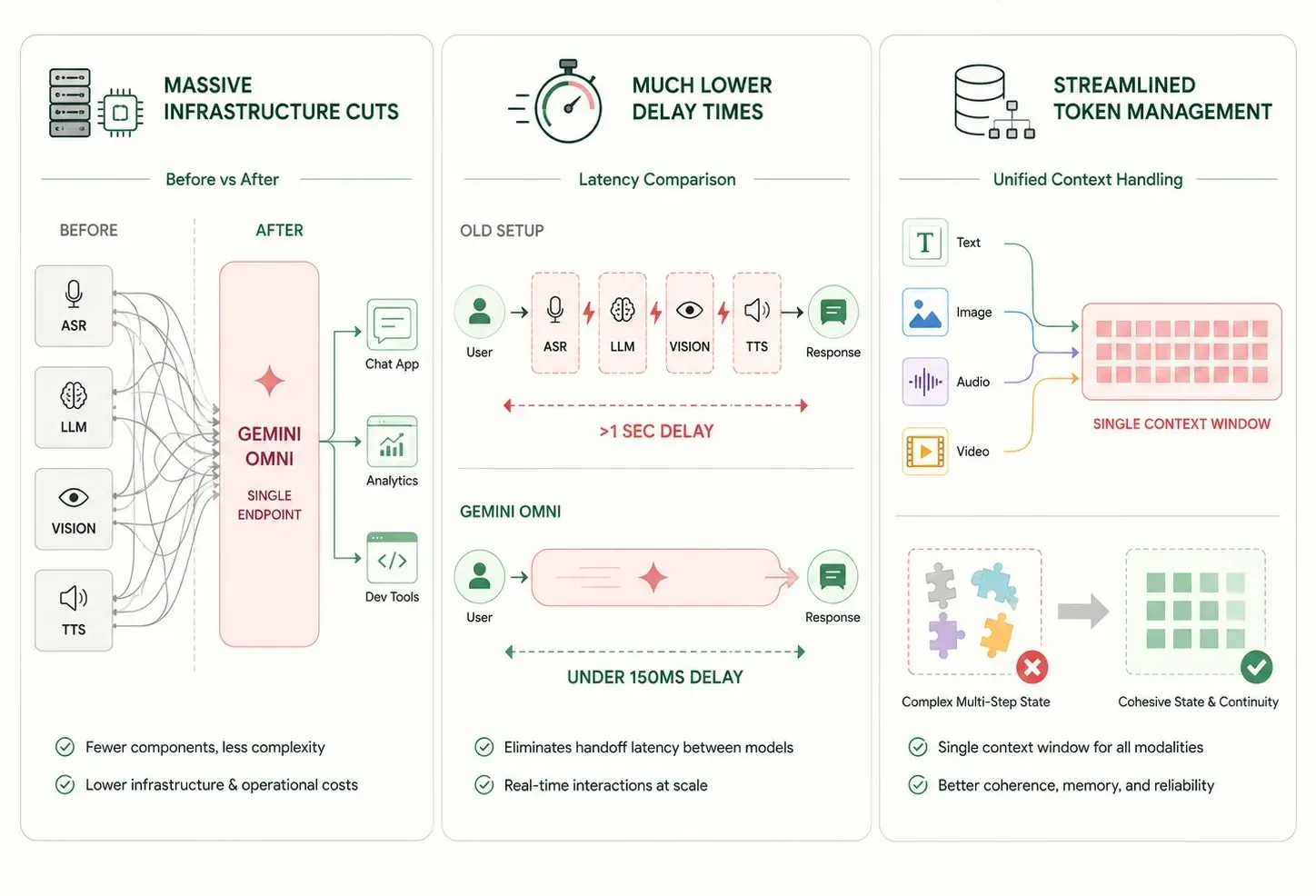
- Réduction massive des infrastructures : Regrouper les tâches de texte, de vision et de son dans un seul modèle réduit le nombre de terminaux logiciels séparés. Cela facilite grandement la maintenance à long terme.
- Temps de latence fortement réduits : Ignorer les étapes réseau supplémentaires entre de petits outils spécialisés fait chuter les temps de réponse à moins d'une seconde. Cela permet des expériences utilisateur réellement en temps réel.
- Gestion rationalisée des jetons : Une fenêtre de contexte unique suivant uniformément toutes les modalités réduit les problèmes complexes de gestion d'état dans les processus en plusieurs étapes.
Parvenir à un déploiement multimodal évolutif
En opérant via des frameworks comme la Gemini Enterprise Agent Platform, les entreprises peuvent coordonner en toute transparence des réseaux de sous-agents autonomes. Ce système unique facilite l'exécution de projets multimédias à grande échelle. Il utilise des configurations gérées qui assurent le suivi du contexte d'arrière-plan et de l'identité de l'utilisateur à travers des flux de travail durant plusieurs jours. En conservant les différentes entrées dans un espace sécurisé, les entreprises peuvent automatiser les tâches sur différents médias du début à la fin sans perdre de données ni le fil conducteur.
Contraintes de calcul et optimisation matérielle pour l'inférence d'IA mondiale
Bien que le traitement de quatre flux de données distincts sous une architecture réseau unifiée permette des workflows cross-média fluides, cela impose des exigences inédites sur l'infrastructure matérielle moderne. Naviguer dans cet environnement nécessite une gestion méticuleuse des ressources de calcul pour surmonter les pénalités physiques extrêmes associées au traitement multisensoriel simultané à l'échelle mondiale.
La surcharge de la tokenisation multimodale
Le défi d'ingénierie principal provient de la surcharge des jetons multimodaux. Contrairement aux jeux de données textuels alphanumériques standard, les images haute définition, les fréquences audio brutes et les fichiers vidéo séquentiels génèrent des quantités massives de données numériques.
- Traitement de texte : Une seule page d'écriture se transforme en environ 1 000 jetons significatifs et denses.
- Traitement visuel : Une minute de vidéo brute, lorsqu'elle est découpée en étapes de trames stables et en blocs de pixels, se décompose en centaines de milliers de jetons visuels.
Lorsqu'un cœur de modèle unique traite ces types de médias ensemble, cela provoque une poussée exponentielle de la densité de la fenêtre de contexte. Le mécanisme d'attention du système doit évaluer comment chaque jeton se rapporte à tous les autres, menaçant de saturer la mémoire à haute bande passante (HBM) sur la puce et les couches de traitement.
Accélération des charges de travail via le clustering TPU
Pour contrer ce goulot d'étranglement, les infrastructures d'entreprise s'appuient sur des plateformes matérielles spécialisées conçues spécifiquement pour l'informatique multisensorielle. L'architecture la plus récente de Google utilise le clustering TPU pour distribuer ces charges de travail de jetons unifiés intensifs dans des environnements de centres de données multicouches.
plaintext1 ┌─────────────────────────┐ 2 │ Jetons Gemini Unifiés │ 3 └────────────┬────────────┘ 4 │ 5 ┌───────────────────────┴───────────────────────┐ 6 ▼ ▼ 7┌─────────────────────────────────┐ ┌─────────────────────────────────┐ 8│ TensorCore Array │ │ TensorCore Array │ 9│ (Arithmétique matricielle par.)│ │ (Arithmétique matricielle par.)│ 10└────────────────┬────────────────┘ └────────────────┬────────────────┘ 11 │ │ 12 └───────────────┬───────────────────────┘ 13 ▼ 14 ┌─────────────────────────┐ 15 │ Interconnexion optique │ 16 │ (ICI à très faible lat.)│ 17 └─────────────────────────┘
Les configurations matérielles comme la plateforme Trillium TPU v6e offrent une augmentation impressionnante de 4,7x des performances de calcul de pointe par puce par rapport aux générations matérielles précédentes. Cette architecture spécialisée gère ces demandes massives en combinant des unités d'exécution matricielle optimisées avec des dispositions d'infrastructure physique profonde :
| Couche moteur matériel | Spécifications architecturales | Fonction système centrale |
| Tableaux TensorCore étendus | Double de la zone d'unité de multiplication matricielle (MXU) | Exécute une arithmétique parallèle intensive sur des tenseurs vidéo denses. |
| HBM haute bande passante | Jusqu'à 32 Go de HBM par puce | Loge des tableaux de jetons massifs entièrement sur silicium pour éviter les goulots d'étranglement mémoire. |
| Interconnexion inter-puce | Bande passante bidirectionnelle de 800 Go/s | Synchronise les variables de paramètres sur des dizaines de milliers de puces sans latence. |
En utilisant un tissu de mise en réseau optique personnalisé parallèlement à ces configurations de mémoire profonde, les infrastructures cloud peuvent évoluer dynamiquement pour gérer des paramètres d'entrée de plusieurs millions de jetons. Cela permet aux entreprises de déployer des agents d'IA avancés en temps réel à l'échelle mondiale sans risque de blocage de mémoire ou de défaillance d'exécution du système.
Une API unifiée pour la génération vidéo de production
Alors que Google déploie Gemini Omni Flash au sein de l'application Gemini et Google Flow pour les utilisateurs finaux, les développeurs et les équipes produit qui souhaitent intégrer le même moteur vidéo multimodal dans leurs propres workflows ont besoin d'une couche API stable et prévisible.
Atlas Cloud propose Gemini Omni Flash via une API unifiée et compatible avec OpenAI, aux côtés de plus de 300 autres modèles d'image, de vidéo et de LLM. Vous pouvez donc intégrer le modèle multimodal natif de Google sans jongler avec des comptes fournisseurs, des portails de facturation ou des SDK séparés.
Les deux variantes de Gemini Omni Flash sont disponibles sur Atlas Cloud :
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Idéal pour | Entrées | Résolution | Durée | Prix de départ |
| Gemini Omni Flash Text-to-Video (Développeur) | Génération cinématographique par prompt | Texte (jusqu'à 20 000 car.) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
| Gemini Omni Flash Image-to-Video (Développeur) | Vidéo cohérente basée sur des ref. réelles | Texte + jusqu'à 7 images de réf. | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
Démarrage rapide — Générez une vidéo Gemini Omni Flash en 5 lignes :
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "Une forêt brumeuse à l'heure dorée, plan travelling cinématique", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
L'API renvoie immédiatement un ID de prédiction — interrogez /api/v1/model/prediction/{id} pour obtenir l'URL MP4 rendue. Le schéma complet, des échantillons de code dans 7 langages et un Playground sans code sont disponibles sur les pages de modèles liées ci-dessus.
Conclusion : Préparer l'avenir de l'intelligence machine unifiée
L'arrivée de Gemini Omni modifie fondamentalement les paradigmes de conception des développeurs, faisant passer l'industrie de l'assemblage d'outils séparés au déploiement de solutions unifiées à couche unique. Au lieu de gérer des ponts d'intégration complexes entre des API isolées, les ingénieurs peuvent désormais s'appuyer sur des frameworks d'apprentissage automatique de nouvelle génération qui traitent naturellement les flux de données interdépendants sous un même toit mathématique.
plaintext1[Pipeline logiciel hérité] 2API Texte séparée ──┐ 3API Audio séparée ──┼──► Briques de pipeline manuelles ──► Production fragile 4API Vidéo séparée ──┘ 5 6[Architecture Omni unifiée] 7Jetons universels ──► Modèle natif monocouche ──► Automatisation transparente
Ce changement structurel nécessite une refonte complète de la façon dont nous construisons les produits numériques. Pour rester compétitives, les équipes techniques doivent s'éloigner des silos de données statiques et préparer les écosystèmes logiciels standard aux systèmes multisensoriels natifs.
En opérant directement sur une dorsale cloud hautement optimisée comme l'infrastructure Google Cloud AI, les entreprises peuvent faire évoluer ces charges de travail intensives sans risquer de dérive de contexte systémique ou de pénalités de latence. En fin de compte, pérenniser votre pipeline de développement signifie concevoir des solutions autour d'un moteur unique et cohérent, construit pour appréhender le monde physique de manière holistique.






