RSpqXx0wq8Q
Le 19 mai 2026, lors de Google I/O, DeepMind a dévoilé Gemini Omni. Le jour même, le guide de prompt Gemini Omni a été mis en ligne sur le site de documentation de DeepMind, niché entre la fiche technique du modèle Omni Flash et les notes API. La plupart des gens ont regardé les démos de la keynote. Le document est resté largement ignoré.
Commençons par les faits. Gemini Omni est le nouveau modèle de génération multimodale de DeepMind. Le premier produit, Gemini Omni Flash, génère des vidéos allant jusqu'à 10 secondes à partir de n'importe quelle combinaison d'entrées texte, image, audio ou vidéo. Chaque sortie comporte un filigrane SynthID. Les abonnés AI Plus, AI Pro et AI Ultra ont eu un accès immédiat ; les utilisateurs de YouTube Shorts et de l'application YouTube Create bénéficient d'un accès gratuit à partir de cette semaine de lancement (selon Gagadget). L'accès API est « prévu dans les semaines à venir » selon Google.
Revenons au guide de prompt. Le guide de Google DeepMind explique directement le changement dans la section « Compréhension du monde » :
Avec Veo, vous devez fournir des instructions précises pour obtenir les meilleurs résultats. Mais avec Gemini Omni, vous n'avez pas besoin d'être aussi prescriptif. Dites simplement à Omni ce que vous souhaitez créer – et laissez le raisonnement et les connaissances du monde du modèle donner vie aux détails.
En résumé : écrivez moins.
Comparez cela aux guides de prompt publiés par ByteDance et Kuaishou pour leurs propres modèles vidéo. Les approches diffèrent, mais vont dans le même sens.
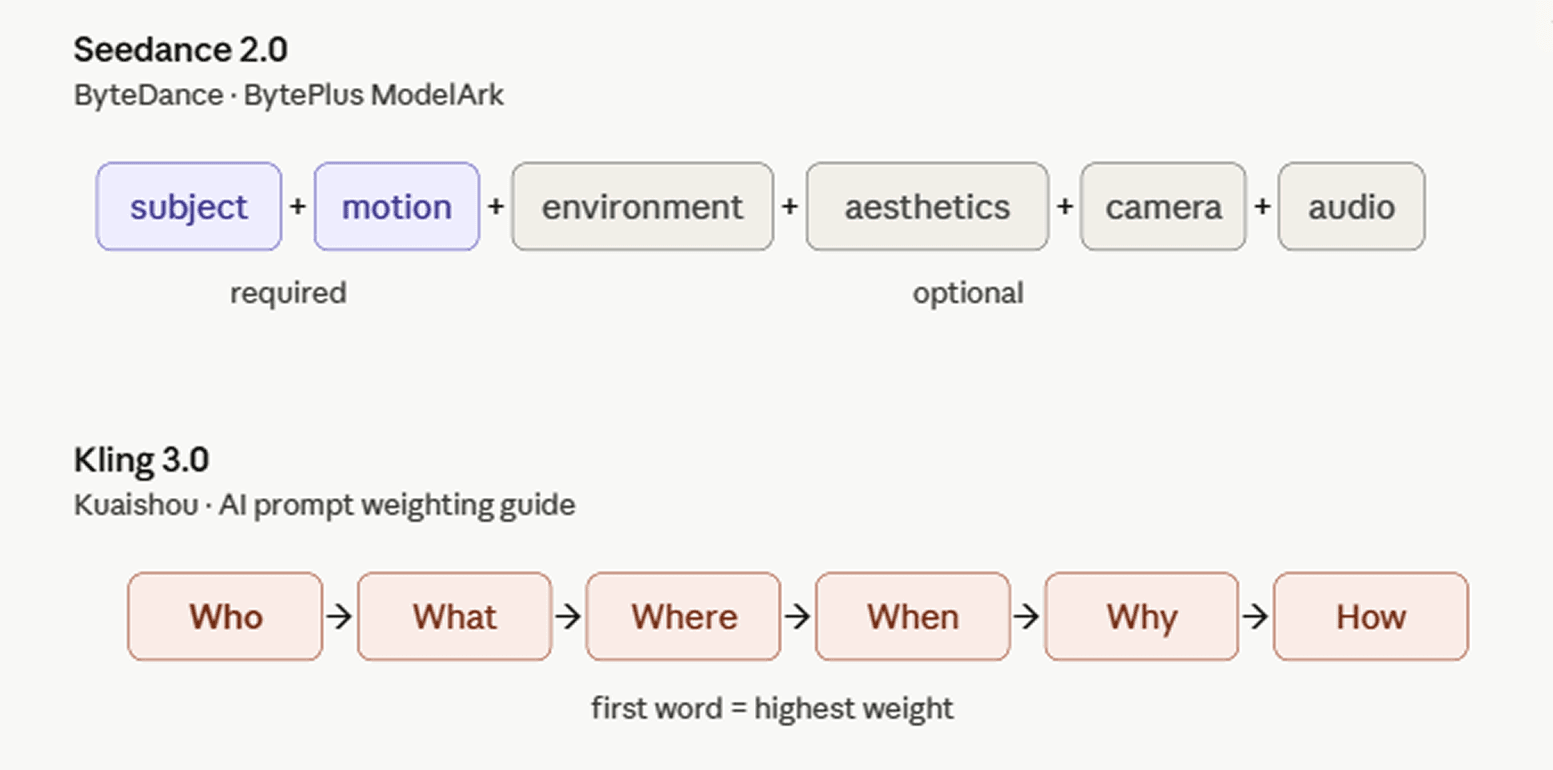
ByteDance documente Seedance 2.0 sur sa plateforme internationale pour développeurs via le guide de prompt BytePlus ModelArk. La structure recommandée est : sujet + mouvement (+ environnement + esthétique + mouvement de caméra/coupe + audio). Chaque composant n'est pas obligatoire, vous choisissez ce qui convient au plan.
Le guide de pondération des prompts AI de Kuaishou s'articule autour de la formule 5W1H : Qui + Quoi + Où + Quand + Pourquoi + Comment. Le « Qui » — le sujet — a généralement la priorité la plus élevée et ouvre le prompt, car la position des mots détermine le poids dans Kling 3.0 : ce qui apparaît en premier bénéficie de la plus grande attention computationnelle. Les choix stylistiques comme le médium ou la perspective fonctionnent mieux à la fin, agissant comme un filtre sur la scène déjà établie. Le guide déconseille l'accumulation aveugle d'éléments ; trop de mots-clés contradictoires dégradent la qualité.
Trois entreprises ont abouti à ce conseil indépendamment, ce qui suggère que leurs modèles ont atteint un niveau de capacité similaire au même moment. Google vous conseille d'écrire moins, ByteDance considère la plupart des composants comme optionnels, et Kuaishou privilégie l'ordre des mots au volume pur. Les approches spécifiques diffèrent, mais les trois laboratoires orientent les créateurs vers des prompts plus libres et naturels.
Voyons maintenant comment le guide de prompt Gemini Omni fonctionne en pratique.
Structure de prompt Gemini Omni : les 5 dimensions utilisées par Google DeepMind
Le guide s'ouvre sur un exemple complet :
Un plan de suivi grand-angle glisse doucement au-dessus d'un lac serein, révélant un objet colossal en forme de haricot, réfléchissant et chromé, lévitant sans effort et tournant lentement pour révéler les reflets déformés de falaises majestueuses et un objet similaire plus petit partiellement immergé dans l'eau azur claire en dessous, tandis qu'un soleil éclatant pointe derrière l'anomalie flottante, baignant toute la scène dans une lumière du jour nette et éthérée avec des tons bleus et verts vibrants, créant une ambiance cinématographique impressionnante soulignée par une partition orchestrale majestueuse et surnaturelle qui souligne l'immensité et le mystère du paysage extraterrestre, avec de faibles bourdonnements profonds émanant de l'objet en lévitation.
Plus de 90 mots. Décomposez-le et vous obtenez 5 dimensions.
- Cadrage et mouvement de caméra. Grand-angle, moyen ou gros plan ? La caméra doit-elle glisser doucement ou bouger soudainement ? Les deux verbes produisent un résultat sensiblement différent, donc quelques essais valent la peine lorsque vous cherchez le bon rendu de mouvement.
- Style. Réaliste, cinématographique, éthéré, majestueux ? Cette dimension n'a pas besoin de détails. Indiquez au modèle le ton émotionnel et cela suffit.
- Éclairage. D'où vient la lumière ? Le soleil, un lampadaire, à l'écran ou hors champ ? L'ambiance doit-elle être nette, chaude ou éthérée ?
- Scène. Une ligne du guide mérite d'être soulignée : « vous n'avez pas besoin de décrire chaque petit détail, car Omni travaillera avec votre intention globale. » Cela rejoint ce que Seedance et Kling disent dans leurs documents officiels.
- Action et interaction. Qui et quoi se trouve dans la scène, comment ils bougent, comment ils interagissent.
Édition conversationnelle Gemini Omni vs réécriture de prompt Veo
Omni et Veo produisent une qualité de génération comparable. La vraie différence réside dans ce que vous pouvez faire après la génération de la vidéo.
Auparavant, modifier un détail signifiait réécrire tout le prompt, régénérer et espérer que la cohérence entre les images était maintenue. Omni remplace cette étape par une conversation.
Le guide officiel donne quelques exemples.
Une vidéo style stop-motion d'un petit garçon. Première édition : « remplacez le papillon par une abeille. » Ensuite : « transformez l'abeille en un petit essaim de lucioles. » Un élément change par tour ; les autres images sont préservées automatiquement.
La caméra fonctionne de la même manière. Une vidéo d'un violoniste reçoit trois commandes successives : « transportez le violoniste dans l'environnement de l'image », « rendez le violon invisible », « changez l'angle de caméra pour qu'il soit au-dessus de l'épaule du violoniste. » Échange d'environnement, suppression d'objet, repositionnement de caméra, le tout via le langage naturel.
Il y a un piège à signaler. Des examinateurs tiers notent que si votre instruction d'édition est trop vague, Omni a tendance à trop éditer, modifiant des éléments que vous vouliez conserver. Le conseil de Google : modifiez une variable par tour et indiquez explicitement ce qui doit rester identique.
L'exemple de synchronisation intermodale est plus intéressant. Prenez une vidéo nocturne d'un immeuble d'habitation, ajoutez l'instruction « les lumières des appartements commencent à s'allumer en synchronisation avec la musique. » Le modèle analyse les battements de la bande sonore et aligne les lumières des fenêtres sur ceux-ci. Faire cela dans After Effects nécessite une timeline, un métronome et une animation image par image manuelle.
Les 4 capacités avancées de Gemini Omni : connaissance du monde, rendu de texte, référence d'action, entrées multiples
La seconde moitié du guide détaille 4 capacités.
Connaissance du monde appliquée
Le prompt exemple : Expliquez la différence entre l'informatique classique et l'informatique quantique. Visualisez cette phrase en utilisant un style contemporain « flat-media » qui mélange des formes vectorielles minimalistes avec des textures organiques riches. L'esthétique est définie par une palette de couleurs « électriques » à fort contraste : néons roses, cyans et verts tilleul sur fond bleu marine profond. Une caractéristique de ce style est l'utilisation d'ombrages en pointillés et de dégradés granuleux, ce qui ajoute une qualité tactile, semblable au risographe, aux formes géométriques simples. En combinant des bords nets avec ces transitions douces et tachetées, l'illustration obtient un aspect ludique et éditorial.
Le modèle sait déjà ce qu'est la superposition quantique et comment la transmettre à travers une série de plans comparatifs. L'utilisateur n'a pas à expliquer la mécanique quantique, seulement le ton visuel.
Cela fonctionne parce qu'Omni s'exécute sur un modèle de raisonnement de pointe, ce que les modèles vidéo purement génératifs ne peuvent égaler. Demis Hassabis, dans une interview accordée à Semafor après l'I/O, a présenté Omni comme une étape dans le projet de création d'une IA qui comprend mieux le monde réel. Il a souligné que Waymo, la division de conduite autonome d'Alphabet, teste déjà des modèles du monde similaires pour donner aux voitures autonomes une sorte d'« imagination » pour gérer les situations imprévisibles. La génération vidéo n'est que l'application la plus visible de cette architecture.
Rendu de texte
Le prompt exemple : mot par mot, un mot à l'écran à la fois, chaque mot avec un style animé différent, rythme parfait avec la musique, sizzle reel.
Référence d'action complexe
Exemple de prompt : éditez ceci en gardant tout à l'identique, ajoutez des effets de mouvement animés sortant du skateboard.
Référence d'entrées multiples
Exemple de prompt : Les oiseaux de la vidéo forment vaguement la silhouette imparfaite d'un oiseau basée sur l'image. Ils bougent sur la musique de l'audio et se dissipent en volant.
Transfert de style
Exemple de prompt : Créez une progression stylistique en quatre parties de la référence vidéo qui commence avec une esthétique de crayon de couleur vibrante, avec des traits riches, cireux, texturés et des designs de personnages dessinés à la main ludiques sur un fond de papier fortement granulé. Transition fluide vers un croquis au crayon graphite sur papier texturé, utilisant des hachures croisées, des épaisseurs de trait variables et un effet de « ligne bouillante » à 12 images/seconde pour accentuer le côté fait main. Ensuite, morphing vers un style verre translucide 3D hyper-réaliste, caractérisé par des réfractions de lumière complexes, des motifs caustiques et des lueurs internes douces dans un studio minimaliste. Concluez la séquence avec un look d'impression risographe tactile, utilisant une palette limitée de trois couleurs, des textures en demi-teintes granuleuses et des superpositions d'enregistrement intentionnelles pour une finition rétro et mécanique.
Référence de storyboard
Prompt : Montrez-moi dans cette histoire. Suivez l'histoire exactement dans l'ordre en commençant en haut à gauche. Toute l'histoire en 10 secondes. Cinématographique.
Cohérence entre les plans
Pourquoi les conseils de prompt pour Gemini Omni, Seedance de ByteDance et Kling de Kuaishou convergent
Revenons à l'observation précédente. La similitude des conseils de prompt de Seedance, Kling et Omni n'est pas le résultat d'un emprunt mutuel. Il est plus plausible que cette génération de modèles ait atteint un niveau de capacité similaire par elle-même.
Une fois qu'un modèle peut gérer le langage naturel au niveau de la scène, compléter les détails avec des connaissances du monde et déduire ce que l'utilisateur veut réellement dire, la sur-prescription devient un goulot d'étranglement. Les trois laboratoires ne sont pas d'accord sur la quantité de structure à réintégrer, mais conviennent que la solution n'est pas de continuer à écrire davantage.
C'est le résultat de deux années de modèles de diffusion entraînés conjointement avec de grands modèles de langage. Omni pousse le résultat vers un état relativement complet.
Appeler Gemini Omni via Atlas Cloud : API unifiée pour Seedance, Kling, Veo
Gemini Omni arrive sur Atlas Cloud. Atlas Cloud regroupe plus de 300 modèles d'IA pour le texte, l'image, la vidéo et l'audio. Les principaux modèles vidéo fonctionnent déjà sur la plateforme : Seedance 2.0, Kling 3.0, Wan 2.7, Veo, et d'autres. Pour une comparaison côte à côte, consultez le comparatif Wan 2.7 vs Seedance 2.0 vs Kling 3.0 d'Atlas Cloud.
Un seul compte gère tout le pipeline. Pas besoin de s'inscrire, de payer ou de gérer des clés API sur plusieurs plateformes régionales. Le Playground prend en charge le débogage interactif. Une API unifiée compatible avec OpenAI s'intègre aux flux de travail existants.
La bibliothèque de prompts d'Atlas Cloud propose plus de vingt catégories de prompts prêts à l'emploi couvrant l'anime, la science-fiction, le mystère, la nourriture et les formats de vlog. Chaque prompt est accompagné d'une vidéo exemple et de notes sur les paramètres. Copiez, échangez quelques mots, lancez.
Une API unifiée pour la génération vidéo en production
Alors que Google déploie Gemini Omni Flash dans l'application Gemini et Google Flow pour les utilisateurs finaux, les développeurs et les équipes produit qui souhaitent intégrer le même moteur vidéo multimodal dans leurs propres flux de travail ont besoin d'une couche API stable et prévisible.
Atlas Cloud propose Gemini Omni Flash via une API unifiée compatible avec OpenAI, aux côtés de plus de 300 autres modèles d'image, de vidéo et LLM — vous pouvez donc intégrer le modèle multimodal natif de Google sans jongler avec des comptes fournisseurs, des portails de facturation ou des SDK distincts.
Les deux variantes de Gemini Omni Flash sont en ligne sur Atlas Cloud :
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Idéal pour | Entrées | Résolution | Durée | Prix de départ |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Développeur) | Génération cinématographique par prompt | Texte (jusqu'à 20 000 car.) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/s |
| Gemini Omni Flash Image-to-Video (Développeur) | Vidéo cohérente basée sur des références réelles | Texte + jusqu'à 7 images réf. | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/s |






