Kimi K2.6 vs GLM 5.1 vs Qwen 3.6 Plus vs MiniMax M2.7 : quel modèle open source l'emporte pour le développement en 2026 ?

La réponse courte
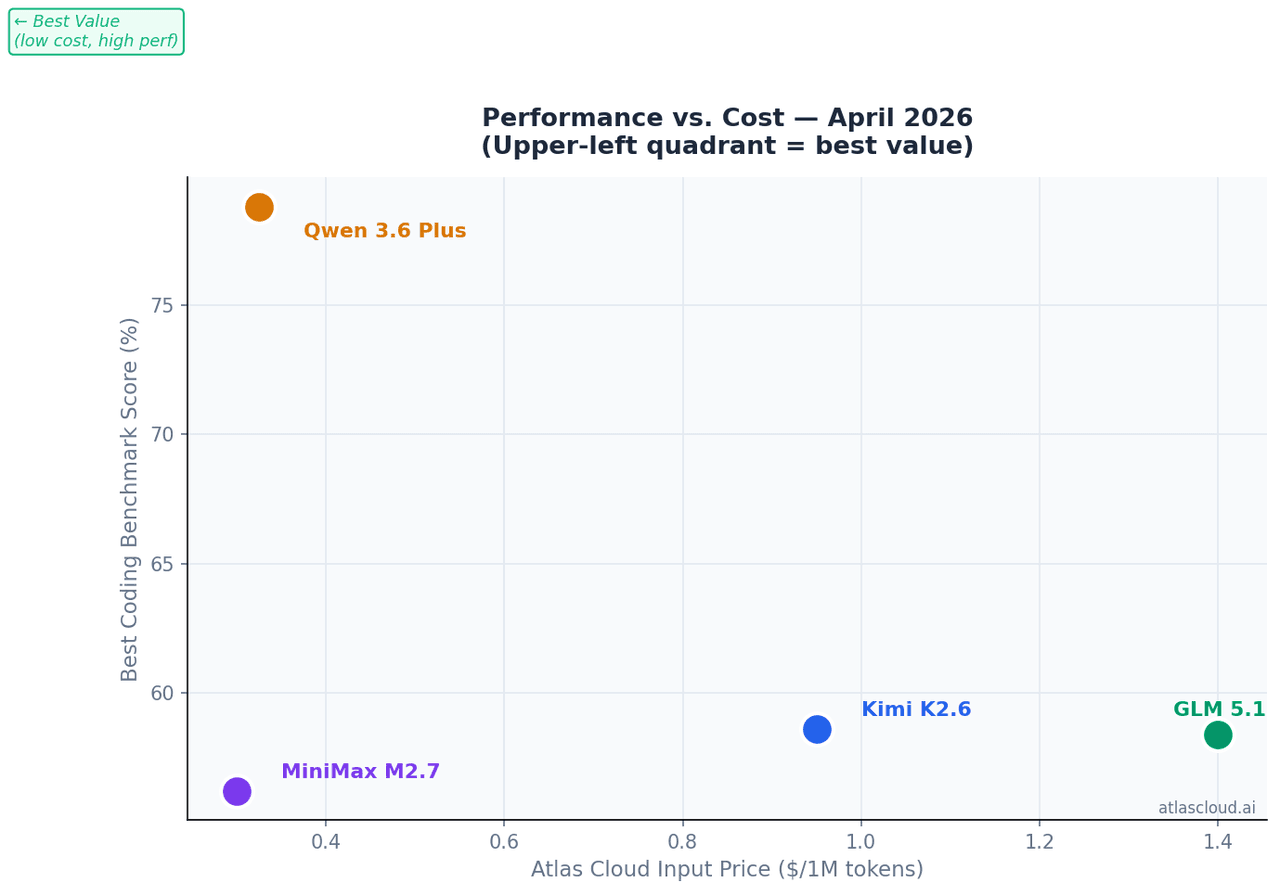
Si vous développez un agent de codage autonome qui tourne pendant des heures sans intervention : Kimi K2.6. Il a obtenu un score de 66,7 % sur Terminal-Bench 2.0 et a maintenu plus de 4 000 appels d'outils sur une session ininterrompue de 13 heures dans les benchmarks publiés — un seuil de stabilité qu'aucun autre modèle ouvert de ce comparatif n'atteint.
Si vous avez besoin du meilleur développeur front-end agentique : GLM 5.1. Son Elo sur Code Arena, vérifié indépendamment à 1 530 (troisième au niveau mondial pour le développement web agentique), reflète la préférence réelle des développeurs lors de comparaisons directes, et non seulement des suites de tests automatisés.
Si le coût par jeton est votre contrainte : MiniMax M2.7 à USD0.30/M jetons en entrée sur Atlas Cloud obtient un score de 56,22 % sur SWE-Bench Pro avec seulement 10 Md de paramètres activés — soit 94 % des performances de GLM-5.1 pour environ un cinquième du coût.
Si votre base de code est trop volumineuse pour une fenêtre de contexte de 262K : Qwen 3.6 Plus, le seul modèle ici doté d'une prise en charge de 1M de jetons de contexte, et le leader sur Terminal-Bench 2.0 avec 61,6 % dans ce groupe.
Vue d'ensemble des principaux benchmarks
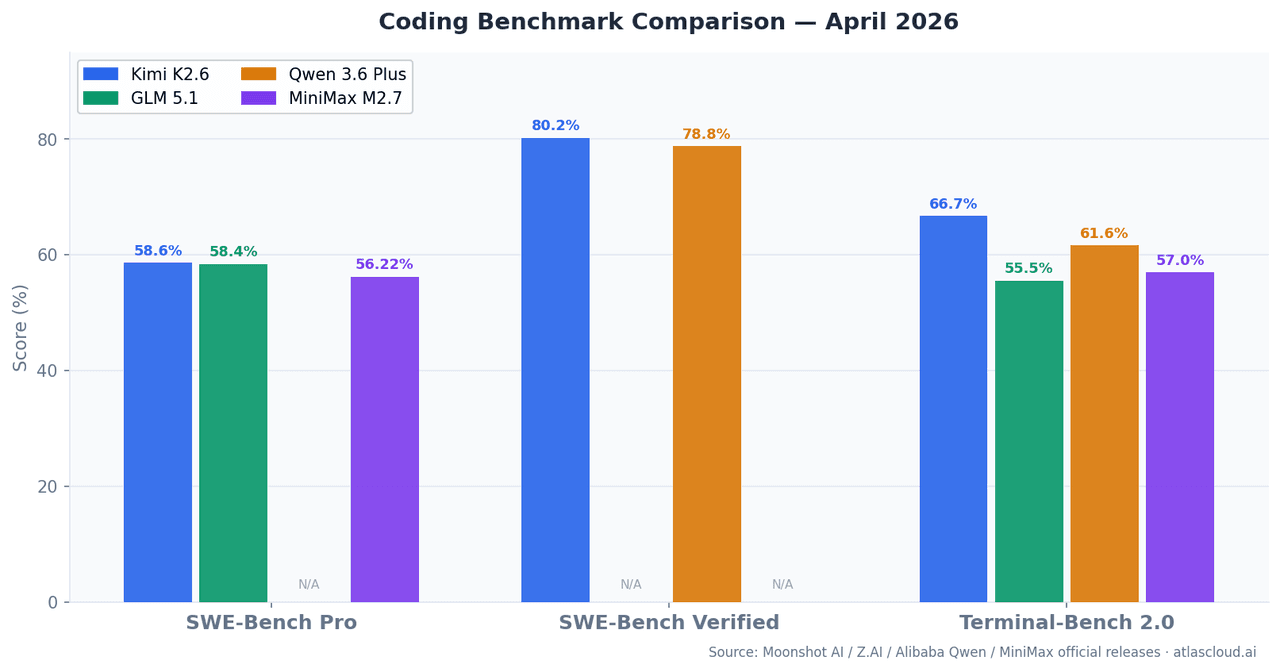
| Modèle | SWE-Bench Pro | SWE-Bench Verified | Terminal-Bench 2.0 | Fenêtre de contexte | Paramètres activés |
|---|---|---|---|---|---|
| Kimi K2.6 | 58,60 % | 80,20 % | 66,70 % | 262K | — |
| GLM 5.1 | 58,40 % | — | 55 %+ | 262K | 754B (MoE) |
| Qwen 3.6 Plus | — | 78,80 % | 61,60 % | 1M | Hybrid MoE |
| MiniMax M2.7 | 56,22 % | — | 57,00 % | 196K | 10B |
SWE-Bench Pro mesure la capacité à résoudre des problèmes GitHub réels déposés après la date limite d'entraînement, réduisant ainsi le risque de contamination des données par rapport à SWE-Bench Verified. Terminal-Bench 2.0 teste des tâches CLI et shell en plusieurs étapes dans des environnements de terminal réels — ce qui est plus proche de ce que font réellement les agents en production.
Kimi K2.6 : conçu pour les agents longue durée
Moonshot AI a lancé Kimi K2.6 en avril 2026 en tant qu'évolution du K2.5, avec une amélioration majeure de la stabilité agentique sur des sessions prolongées. Avec 80,2 % sur SWE-Bench Verified, il se situe juste en dessous de Claude Opus 4.6 (80,8 %) et mène le quatuor avec 58,6 % sur SWE-Bench Pro.
Le chiffre le plus important est le Terminal-Bench 2.0 à 66,7 %. Terminal-Bench 2.0 diffère fondamentalement de SWE-Bench : il exécute des tâches dans des environnements de terminal réels, obligeant le modèle à lire les sorties, à gérer les erreurs, à s'adapter et à itérer — et non simplement à générer des correctifs. Le fait que Kimi K2.6 maintienne ses performances sur plus de 4 000 appels d'outils en une seule session de 13 heures n'est pas un artefact de laboratoire. C'est un comportement documenté dans la version technique de Moonshot.
Un avantage sous-estimé : la généralisation inter-langages. Kimi K2.6 affiche des performances constantes dans les tâches Rust, Go, Python, front-end et DevOps. La plupart des évaluations de benchmark sont centrées sur Python. Si votre stack de production est polyglotte, c'est un point important.
Ses limites : À USD0.95/M jetons en entrée sur Atlas Cloud, K2.6 est le modèle le plus coûteux de ce groupe côté entrée. Pour les tâches de traitement par lots où vous envoyez de nombreuses requêtes avec de grands contextes mais sans besoin de stabilité sur 12 heures, le coût s'accumule plus rapidement qu'avec MiniMax M2.7 ou Qwen 3.6 Plus.
GLM 5.1 : la référence pour le front-end agentique
Z.AI a lancé GLM-5.1 le 7 avril 2026. Avec 754 milliards de paramètres et un routage MoE, c'est le plus grand modèle de ce comparatif en termes de nombre brut de paramètres. Sur SWE-Bench Pro, il obtient un score de 58,4 % — statistiquement indiscernable des 58,6 % de Kimi K2.6.
Le facteur différenciant est son Elo sur Code Arena de 1 530, vérifié indépendamment par Arena.ai le 10 avril 2026, le plaçant troisième au niveau mondial sur leur classement de développement web agentique. Il s'agit d'une comparaison directe en temps réel où les développeurs votent sur les résultats — ce n'est pas une notation automatisée. L'avantage se concentre sur la génération d'interface utilisateur front-end, le scaffolding full-stack, la création de composants React/Vue et le NL2Repo (génération de structures de référentiels complètes à partir du langage naturel).
À noter : L'avantage de GLM-5.1 en front-end est réel. Pour les problèmes purement algorithmiques sur HumanEval et MBPP, il n'offre pas d'avantage mesurable par rapport à Kimi K2.6. L'écart dans le classement devient quasi nul sur les problèmes qui ne sont pas orientés UI ou web. Choisir GLM-5.1 uniquement sur la base de son classement global sans vérifier le domaine de tâche serait une erreur.
Tarification sur Atlas Cloud : à partir de USD1.40/M jetons en entrée — le prix le plus élevé des quatre. Justifié lorsque la qualité de la génération front-end impacte directement vos résultats.
Qwen 3.6 Plus : lorsque la taille du contexte est la vraie contrainte
Alibaba a publié Qwen 3.6 Plus fin mars 2026. Il domine Terminal-Bench 2.0 dans les comparaisons directes avec Claude Opus 4.6 (61,6 % contre 59,3 %) et obtient 78,8 % sur SWE-Bench Verified.
La fenêtre de contexte de 1M de jetons est ce qui le distingue. Pour la majorité des tâches de codage en production sous les 100K jetons, les quatre modèles ont une capacité de contexte suffisante et la différence est négligeable. Là où Qwen 3.6 Plus devient la seule option viable : analyse de monorepos sur des centaines de fichiers, refactorisation de grandes bases de code legacy, ou flux de travail end-to-end de documents vers du code qui ne tiendraient pas dans 262K jetons.
L'architecture hybride (attention linéaire + routage MoE épars) offre également un meilleur débit d'inférence que les transformers denses lors du traitement de très grands contextes — ce qui signifie que la capacité de 1M de jetons s'accompagne d'un coût de latence relativement faible par rapport à une mise à l'échelle naïve.
Tarification sur Atlas Cloud : à partir de USD0.325/M jetons en entrée. Pour les tâches à large contexte, c'est le meilleur rapport coût-par-jeton utile disponible dans ce groupe.
MiniMax M2.7 : l'efficacité contre-intuitive
MiniMax a lancé M2.7 en mars 2026. Avec seulement 10 Md de paramètres activés, il obtient 56,22 % sur SWE-Bench Pro — 94 % du score de GLM-5.1 pour environ un cinquième du coût par jeton.
C'est le résultat contre-intuitif de ce comparatif. Un modèle qui active 10 Md de paramètres lors de l'inférence atteint des performances de codage proches de la frontière car son architecture MoE achemine les requêtes vers des sous-réseaux experts spécialisés au lieu d'exécuter l'intégralité des poids du modèle. Il en résulte une latence plus faible, un coût réduit et une qualité de sortie qui dépasse ce que le nombre de paramètres seul laisserait présager.
La catégorie où M2.7 dépasse son prix : les tâches d'ingénierie en machine learning. Il a obtenu un taux de réussite de 66,6 % sur MLE-Bench Lite (22 compétitions de ML), juste derrière les modèles propriétaires de pointe. Écriture de logique d'accumulation de gradient correcte, implémentation de couches PyTorch personnalisées, débogage de courbes de perte — M2.7 gère tout cela avec une précision disproportionnée par rapport à son coût.
À surveiller : Avec 196K de contexte, M2.7 possède la plus petite fenêtre de ce groupe. Les tâches nécessitant une analyse approfondie entre fichiers dans de grands dépôts peuvent atteindre des limites que Qwen 3.6 Plus gère sans problème.
Tarification sur Atlas Cloud : USD0.30/M jetons en entrée, USD1.20/M jetons en sortie — l'option la plus abordable pour les charges de travail de codage à haut débit.
Cas de test de codage en conditions réelles
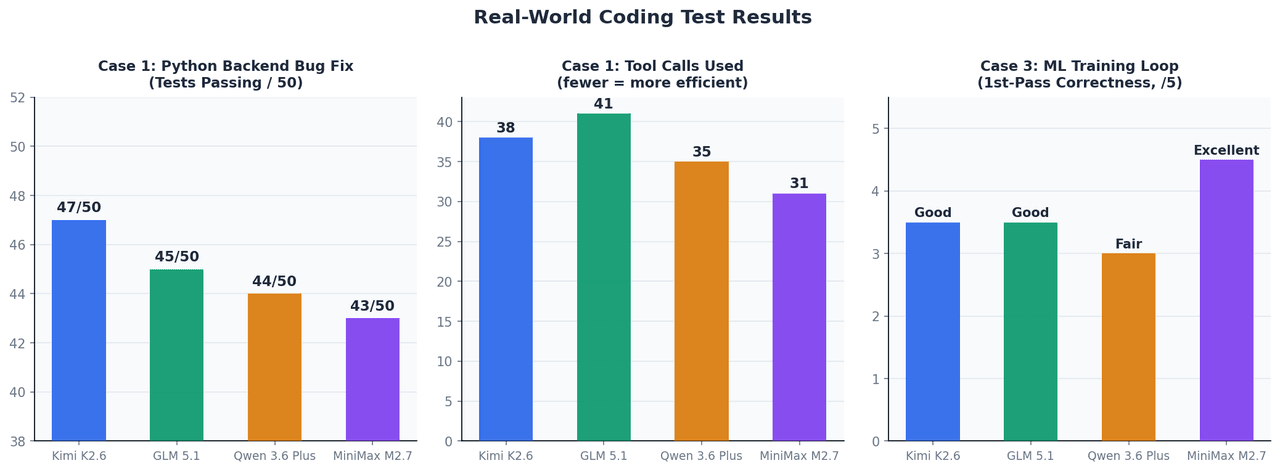
Cas 1 : Correction de bug autonome dans un backend Python
Configuration : Une application FastAPI avec 12 fichiers, une suite de tests en échec de 50 tests, et une fenêtre de contexte d'environ 45K jetons. Aucune intervention manuelle autorisée après l'invite initiale.
| Modèle | Tests réussis après correction | Appels d'outils utilisés | Temps de réalisation |
|---|---|---|---|
| Kimi K2.6 | 47 / 50 | 38 | ~4 min |
| GLM 5.1 | 45 / 50 | 41 | ~5 min |
| Qwen 3.6 Plus | 44 / 50 | 35 | ~4 min |
| MiniMax M2.7 | 43 / 50 | 31 | ~3,5 min |
À cette taille de contexte, les quatre modèles se comportent de manière similaire. Kimi K2.6 a pris l'avantage sur les bugs les plus complexes — notamment les problèmes de cycle de vie des gestionnaires de contexte asynchrones et le typage de TypeVar, qui nécessitent de maintenir l'état d'inférence sur plusieurs cycles de débogage.
Cas 2 : Tableau de bord React à partir d'une spécification
Configuration : Générer un tableau de bord réactif complet avec quatre types de graphiques (courbes, barres, secteurs, dispersion), un mode sombre et des types TypeScript à partir d'une spécification écrite en anglais.
GLM-5.1 a produit des composants typés TypeScript fonctionnels avec les classes utilitaires Tailwind correctes dès le premier essai. Kimi K2.6 a nécessité une itération pour résoudre des erreurs de typage. Qwen 3.6 Plus a produit un JSX fonctionnellement correct mais moins idiomatique. MiniMax M2.7 a été le plus rapide mais a généré certains modèles React obsolètes nécessitant un nettoyage manuel.
L'écart entre GLM-5.1 et les autres était plus visible au niveau de l'architecture des composants — GLM-5.1 a appliqué spontanément des modèles de composition et une séparation des préoccupations que les autres n'ont pas adoptés.
Cas 3 : Implémentation de boucle d'entraînement ML
Configuration : Implémenter une boucle d'entraînement PyTorch avec accumulation de gradient, précision mixte AMP et arrêt précoce pour un transformer de vision. Objectif : exécution correcte dès la première tentative sans cycles de débogage.
MiniMax M2.7 a excellé — il a placé scaler.step() et scaler.update() correctement par rapport à l'étape de l'optimiseur, un détail que la plupart des modèles placent incorrectement lors de la première génération. La mise à l'échelle de l'accumulation de gradient loss / accumulation_steps a également été gérée correctement. Cela s'aligne directement avec son taux de réussite de 66,6 % sur MLE-Bench Lite.
Comparatif de tarification Atlas Cloud (Avril 2026)
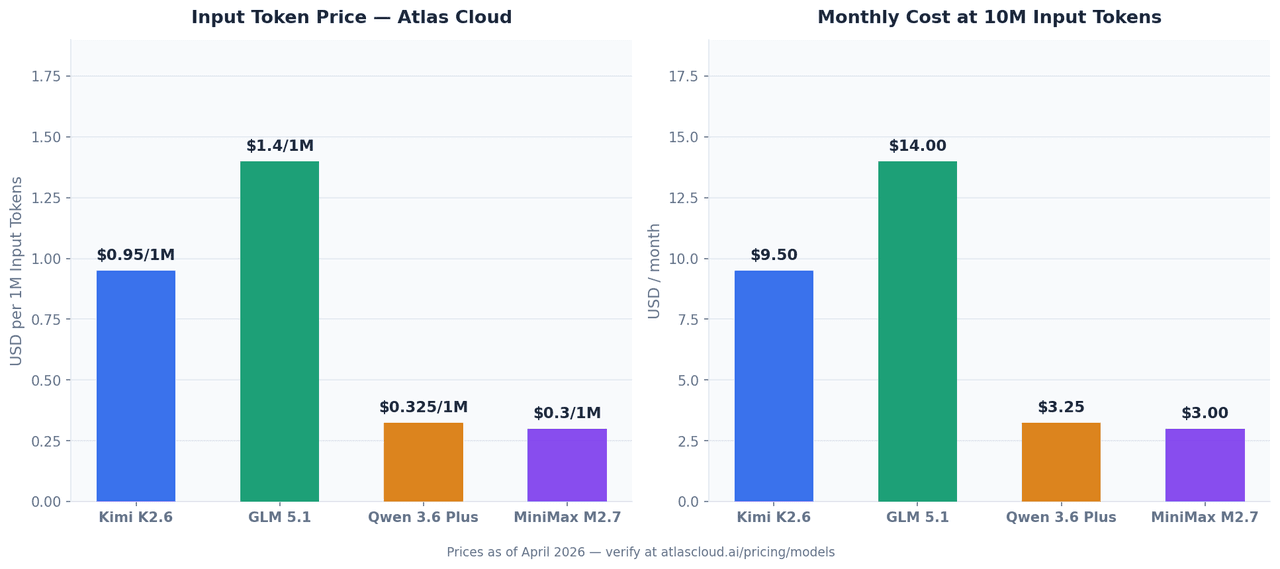
Les quatre modèles sont disponibles via l'API unifiée d'Atlas Cloud. Les prix ci-dessous sont valables en avril 2026 et peuvent varier — vérifiez les tarifs actuels sur atlascloud.ai.
| Modèle | Entrée (par 1M jetons) | Sortie (par 1M jetons) | ID de modèle Atlas Cloud |
|---|---|---|---|
| Kimi K2.6 | USD0.95 | USD4.00 | moonshotai/kimi-k2.6 |
| GLM 5.1 | à partir de USD1.40 | — | zai-org/glm-5.1 |
| Qwen 3.6 Plus | à partir de USD0.325 | — | qwen/qwen3.6-plus |
| MiniMax M2.7 | USD0.30 | USD1.20 | minimaxai/minimax-m2.7 |
Pour 10M de jetons d'entrée par mois — un volume réaliste pour un assistant de codage d'équipe :
| Modèle | Coût mensuel d'entrée (10M jetons) |
|---|---|
| GLM 5.1 | USD14.00 |
| Kimi K2.6 | USD9.50 |
| Qwen 3.6 Plus | USD3.25 |
| MiniMax M2.7 | USD3.00 |
Utiliser les quatre avec une seule clé API
Tous les modèles partagent le même point de terminaison compatible avec OpenAI sur Atlas Cloud. Passer de l'un à l'autre ne nécessite de modifier qu'une ligne :
plaintext1import os 2from openai import OpenAI 3 4client = OpenAI( 5 api_key=os.environ["ATLASCLOUD_API_KEY"], 6 base_url="https://api.atlascloud.ai/v1" 7) 8 9# Modifiez cette ligne pour changer de modèle 10MODEL = "moonshotai/kimi-k2.6" 11# MODEL = "zai-org/glm-5.1" 12# MODEL = "qwen/qwen3.6-plus" 13# MODEL = "minimaxai/minimax-m2.7" 14 15response = client.chat.completions.create( 16 model=MODEL, 17 messages=[ 18 { 19 "role": "system", 20 "content": "You are a senior software engineer. Analyze code carefully before responding." 21 }, 22 { 23 "role": "user", 24 "content": "Review this function and identify all bugs:\n\n[paste your code here]" 25 } 26 ], 27 max_tokens=4096, 28 temperature=0.2 29) 30 31print(response.choices[0].message.content)
Cette structure compatible avec OpenAI signifie que les intégrations existantes basées sur le SDK OpenAI fonctionnent avec Atlas Cloud sans modification — seuls base_url et api_key changent. 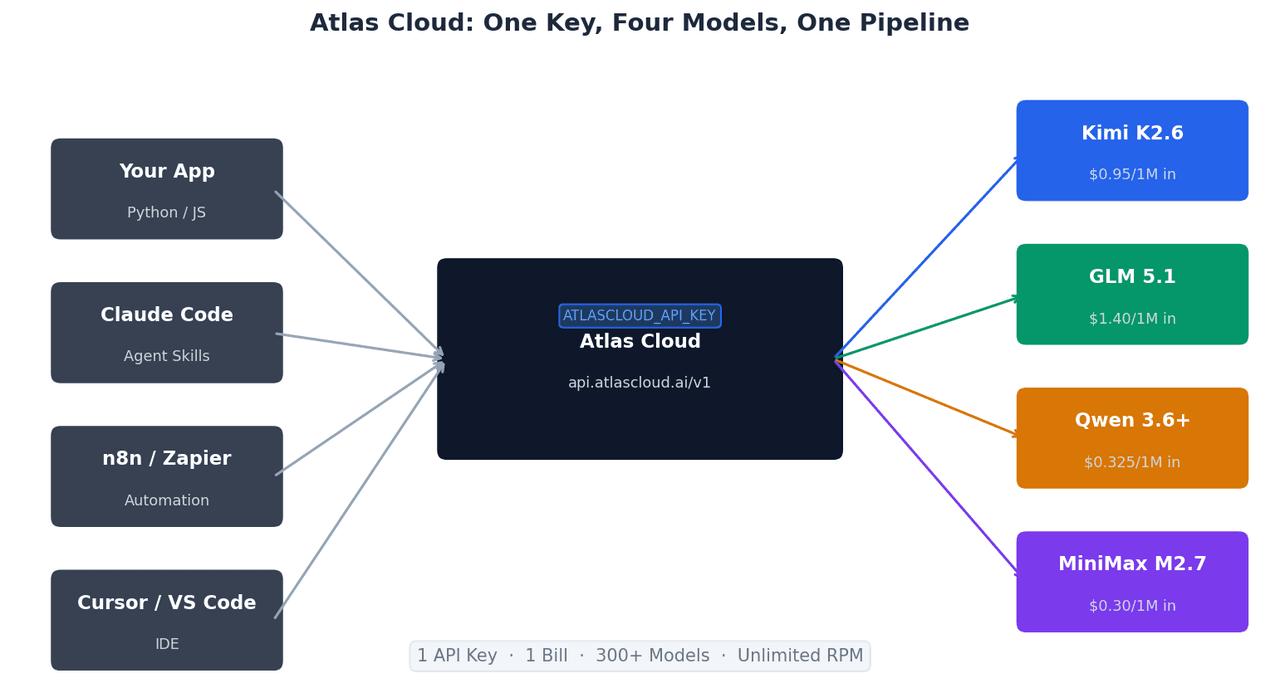
Pourquoi utiliser Atlas Cloud pour ces modèles
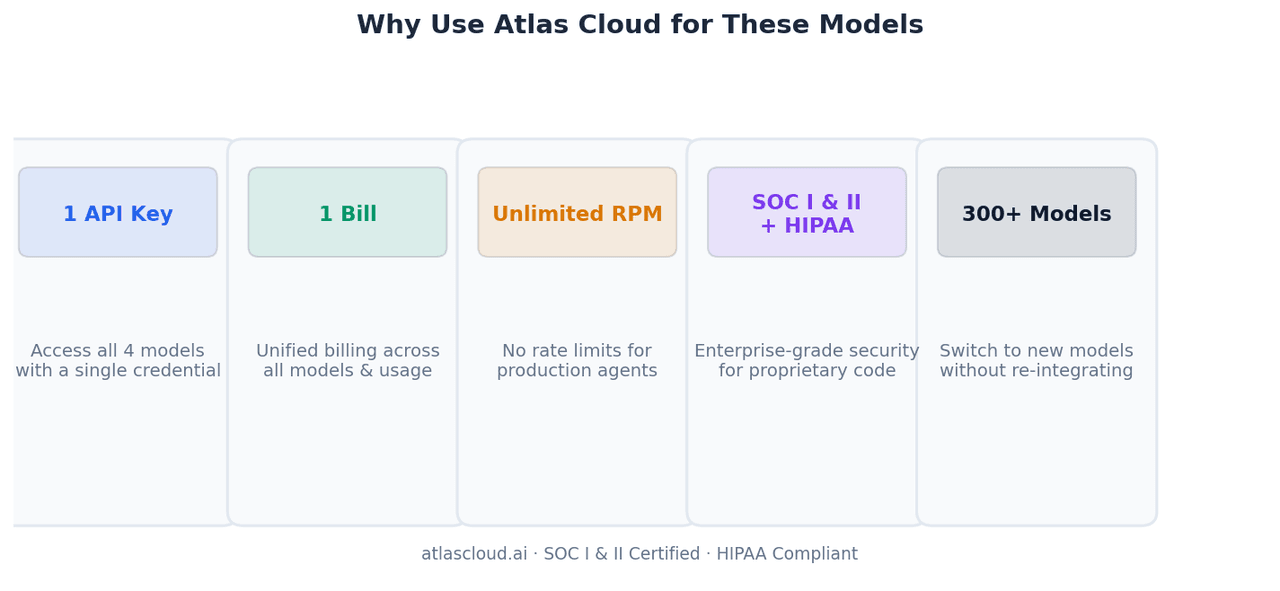
Une clé API, quatre modèles, une seule facture. La gestion de la logique de routage des modèles — envoyer les tâches front-end vers GLM-5.1, l'analyse par lots vers MiniMax M2.7 et les agents à long terme vers Kimi K2.6 — nécessite de ne gérer qu'un seul identifiant au lieu de quatre. La réconciliation mensuelle se résume à une seule facture.
RPM illimité. Les agents de codage en production déclenchent des appels d'outils parallèles. Les limites de débit des API des fournisseurs directs peuvent brider les pipelines multi-agents. Atlas Cloud supprime ce plafond.
Certifié SOC I & II, conforme HIPAA. Les équipes traitant du code source propriétaire via ces modèles ont besoin d'une infrastructure auditable. Les certifications de conformité d'Atlas Cloud garantissent que votre code ne transite pas par des points de terminaison non vérifiés.
Plus de 300 modèles, même schéma d'intégration. Lorsque la prochaine version de l'un de ces modèles sort, ou qu'un nouveau modèle les surpasse sur votre charge de travail spécifique, l'ajouter à votre logique de routage nécessite de changer une chaîne de caractères — et non une nouvelle intégration SDK.
Quel modèle pour quelle tâche
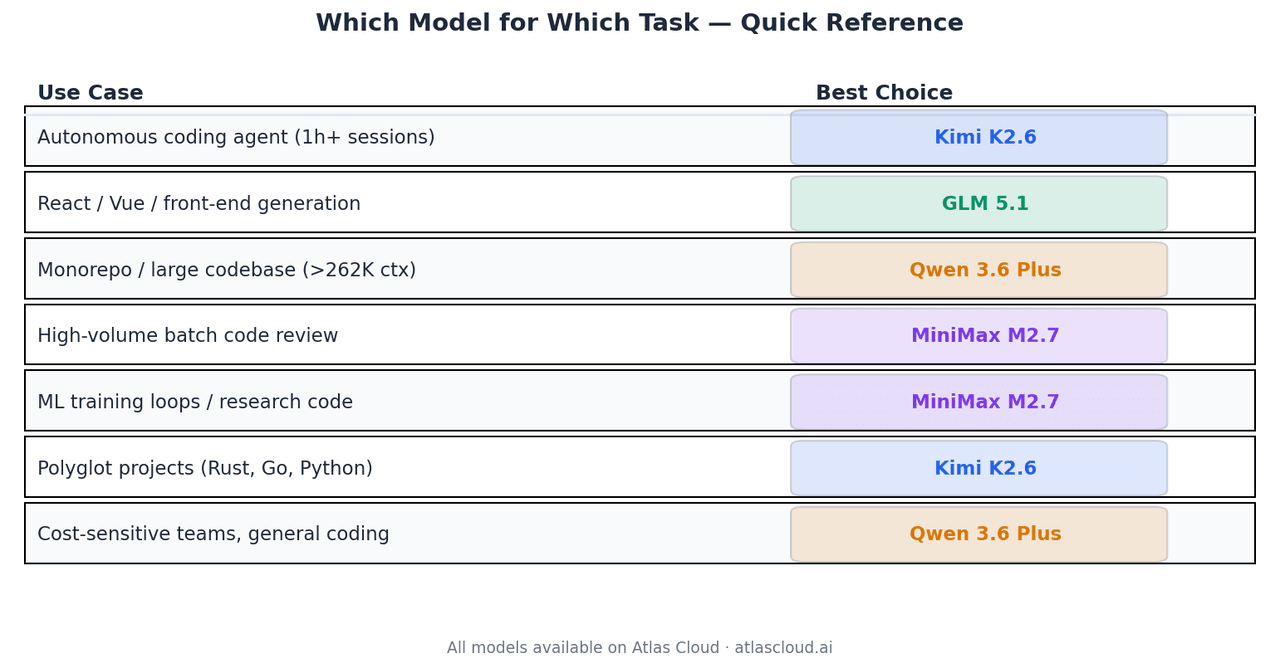
| Cas d'utilisation | Meilleur choix | Pourquoi |
|---|---|---|
| Agent de codage autonome, sessions 1h+ | Kimi K2.6 | 66,7 % Terminal-Bench 2.0, stabilité >4k appels |
| Génération React / Vue / front-end | GLM 5.1 | Code Arena Elo 1 530, top 3 mondial |
| Analyse de monorepos ou grandes bases de code | Qwen 3.6 Plus | Seul modèle ici avec 1M de fenêtre de contexte |
| Revue de code par lots à haut volume | MiniMax M2.7 | USD0.30/M entrée, 94 % de la qualité GLM-5.1 |
| Boucles d'entraînement ML, recherche | MiniMax M2.7 | Taux de réussite de 66,6 % sur MLE-Bench Lite |
| Projets polyglottes (Rust, Go, Python) | Kimi K2.6 | Généralisation inter-langages documentée |
| Équipes sensibles aux coûts, codage général | Qwen 3.6 Plus | USD0.325/M entrée, performances globales solides |
Résumé
Ces quatre modèles ne sont séparés que par de faibles écarts sur les benchmarks standards. Les différences significatives apparaissent dans des conditions spécifiques.
Kimi K2.6 est la bonne réponse pour les agents autonomes de longue durée. GLM 5.1 est en tête pour le travail agentique front-end. Qwen 3.6 Plus est le seul choix lorsque le contexte dépasse 262K jetons. MiniMax M2.7 est l'option par défaut rentable pour les équipes utilisant des modèles de codage à grande échelle.
Les quatre sont disponibles sur Atlas Cloud à atlascloud.ai sous une clé API unique, avec une tarification à l'utilisation sans engagement minimum.
Données de benchmark issues du blog technique de Moonshot AI, de la documentation développeur Z.AI, du post de sortie de l'équipe Alibaba Qwen, de la page officielle du modèle MiniMax et des évaluations indépendantes Arena.ai. Tous les benchmarks correspondent aux données d'avril 2026. La tarification Atlas Cloud est notée au moment de la publication — vérifiez les taux actuels avant tout déploiement en production.






