
MiniMax vient de dévoiler une accélération de décodage de 15,6× pour une fenêtre de 1M de jetons. Si ces chiffres se confirment, le coût d'exécution d'un contexte d'un million de jetons chutera de près d'un ordre de grandeur — et la génération deviendra plus rapide, et non plus lente, en le faisant.
Pour quiconque développe sur ces modèles, cela redéfinit ce qui est abordable. Des charges de travail auparavant non rentables deviennent viables : fournir à un agent de codage l'intégralité de votre base de code au lieu de simples fragments, des exécutions d'agents durant plusieurs heures accumulant d'énormes historiques, ou une recherche sur des ensembles complets de documents plutôt que sur des extraits tronqués. La question que chaque équipe se pose — combien puis-je en mettre dans la fenêtre de contexte avant que la facture ou la latence ne tuent le produit ? — voit son plafond considérablement rehaussé.
Le mécanisme est l'attention creuse (sparse attention), et MiniMax n'est pas seul. DeepSeek l'a déployé sur trois gammes de modèles, Qwen possède sa propre version, et maintenant MiniMax. La tendance est actée. Ce qui change, ce sont les conséquences : quand chaque modèle de pointe peut gérer un contexte long à bas coût, le modèle lui-même cesse d'être un avantage compétitif (moat) — et c'est cet aspect qui mérite votre attention, sur lequel nous reviendrons à la fin.
Deux avertissements honnêtes d'abord, car ils comptent pour quiconque souhaite déployer ceci :
- Il s'agit des chiffres de MiniMax, issus d'un seul diagramme teaser d'un modèle non publié, sur leur configuration. C'est un signal fort de la direction prise, pas un benchmark tiers. Considérez cela comme "ce que prétend MiniMax" et testez sur votre propre charge de travail lorsque les poids seront disponibles.
- M3 n'est pas encore public. Nous prévoyons de l'intégrer à Atlas Cloud avec un accès dès le premier jour lors de sa sortie — plus de détails à la fin.
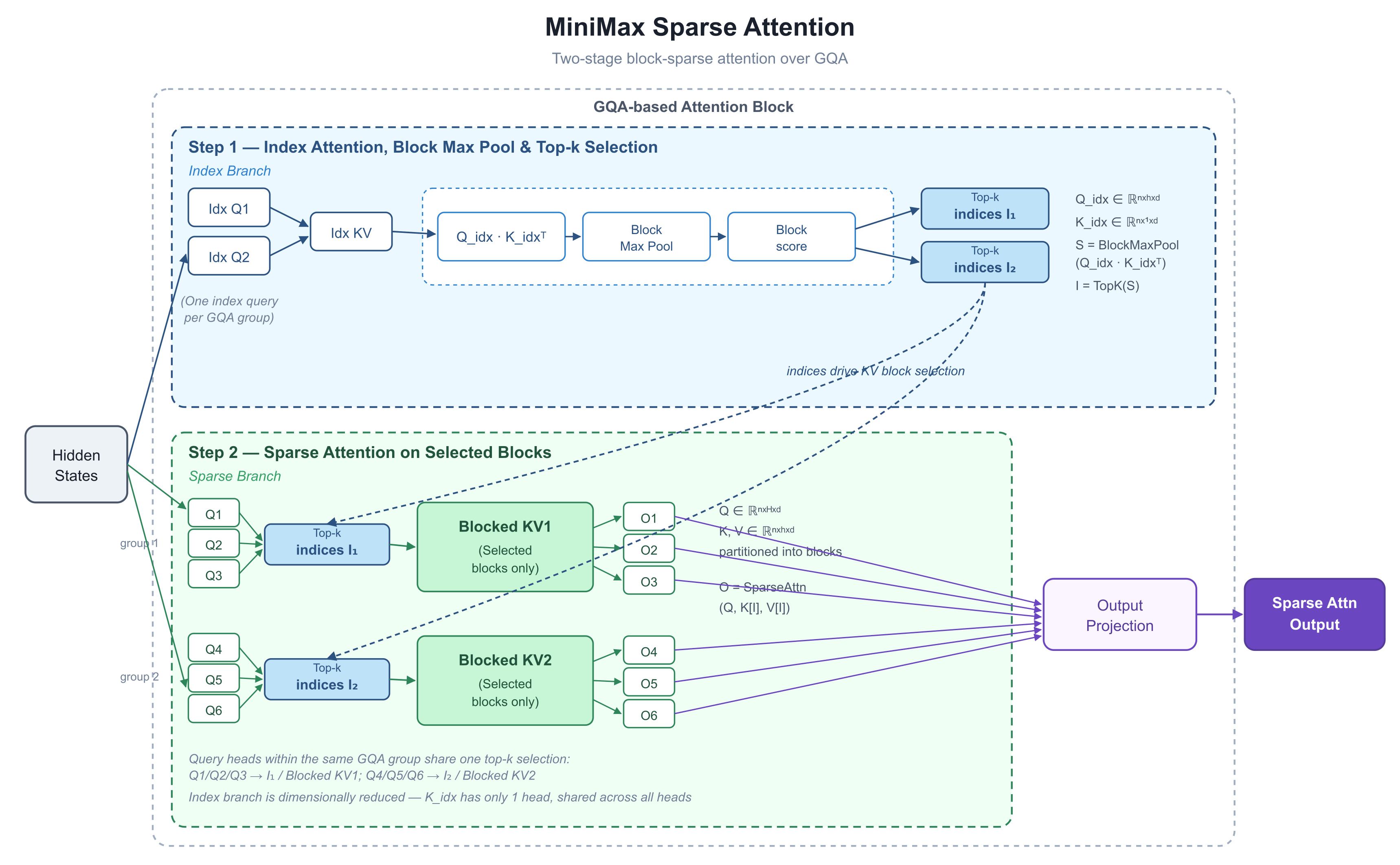
Alors, comment MiniMax réussit-il ce tour de force ? Le 26 mai, le responsable R&D de MiniMax, Skyler Miao, a publié un diagramme sur X — palette sobre, beaucoup d'informations condensées — intitulé MiniMax Sparse Attention, avec deux courbes portant les chiffres qui ont retenu l'attention de tous : preremplissage (prefill) 9,7× plus rapide, décodage 15,6× plus rapide à 1M de jetons. La communauté l'a interprété presque unanimement comme le teaser du M3. Nous l'avons analysé pour comprendre l'architecture derrière ces chiffres.
Un peu de contexte avant l'analyse. Trois termes résument toute l'histoire :
- Le Prefill (preremplissage) est la passe où un modèle lit votre entrée en une seule fois.
- Le Decode (décodage) est la phase plus lente, jeton par jeton, où il écrit la sortie — et avec un contexte long, c'est cette phase qui coûte cher, car chaque nouveau jeton doit examiner tout ce qui le précède.
- L'Attention creuse est la solution : au lieu que chaque jeton prête attention à tous les autres jetons (le comportement par défaut, dont le coût augmente avec le carré de la longueur de la séquence), le modèle se concentre sur un sous-ensemble soigneusement choisi — conservant la majeure partie de la qualité pour une fraction du calcul. La manière de choisir ce sous-ensemble est ce qui différencie chaque laboratoire.
Et la raison pour laquelle ce teaser a du poids : en octobre dernier, MiniMax a publié un article intitulé Pourquoi le M2 a fini par être un modèle à attention complète ? — inhabituellement direct, expliquant que le M2 avait ignoré la "Lightning Attention" efficace du M1 car celle-ci n'était pas prête pour la production. Six mois plus tard, le M3 apparaît avec l'attention creuse au premier plan. Le sous-texte tient en une phrase : cette fois, c'est le cas.
1. Ce que montre le diagramme : deux étapes — choisir avant de calculer
Le diagramme représente le déploiement interne d'un bloc d'attention unique. Son mouvement clé est de séparer le "quels jetons regarder" du "comment calculer l'attention sur eux" en deux étapes clairement distinctes.
Une remarque sur le substrat, car il revient sans cesse : M3 est construit sur GQA — Grouped-Query Attention. Dans une couche d'attention standard, chaque "tête de requête" possède son propre ensemble de clés et de valeurs, ce qui est expressif mais alourdit le cache KV (le cache key/value — les clés et valeurs stockées de tous les jetons précédents, conservées pour éviter de les recalculer à chaque étape). GQA divise les têtes de requête en groupes, et chaque groupe partage un ensemble de clés et de valeurs. C'est la disposition standard d'économie de mémoire utilisée par la plupart des modèles en production aujourd'hui. Gardez cela en tête — c'est le fondement de toute la conception.
Étape 1 : Branche d'indexation — tout noter à bas coût
La moitié supérieure est la branche d'indexation. Elle fonctionne parallèlement au chemin principal avec une mission : dire au reste du bloc quels blocs de jetons valent la peine d'être regardés.
Chaque groupe GQA partage une requête d'index (le diagramme montre six têtes réelles associées à deux requêtes d'index, "Idx Q" — une par groupe). Le côté clé de cette branche est volontairement simplifié :

Notez que K_idx n'a qu'une seule tête — chaque tête partage la même clé d'index. Cela rend l'étape de notation (Q_idx · K_idxᵀ) pratiquement gratuite.
Le Block Max Pool compresse ensuite ces scores au niveau jeton en scores au niveau bloc (il découpe la séquence en blocs de taille fixe et conserve le meilleur score dans chacun) :

Enfin, TopK — "garder les k éléments ayant les scores les plus élevés" — décide quels blocs KV survivent pour cette couche et ce groupe. Le résultat est une courte liste d'indices : I₁, I₂.
Étape 2 : Branche creuse — où l'attention s'exécute réellement
La moitié inférieure est le calcul réel. Les requêtes, clés et valeurs sont toujours sous la forme GQA standard. En utilisant I₁ et I₂ de l'étape 1, le bloc extrait uniquement les sous-ensembles sélectionnés des clés et valeurs complètes, et exécute l'attention sur ceux-ci uniquement :

Le choix de conception le plus important : chaque tête de requête dans un groupe partage une seule sélection top-k. Dans le diagramme, Q1/Q2/Q3 utilisent tous I₁ ; Q4/Q5/Q6 utilisent tous I₂. C'est le principe d'alignement matériel sur lequel insiste l'article NSA de DeepSeek — un groupe de requêtes charge un ensemble de blocs KV, cet ensemble tient dans la SRAM (la petite mémoire ultra-rapide embarquée sur la puce GPU) en une seule passe, et les noyaux de type FlashAttention standards (l'implémentation d'attention optimisée dominante) peuvent être réutilisés sans modification.
2. Trois soustractions délibérées par rapport à la famille DeepSeek
La communauté a immédiatement comparé cela aux trois conceptions d'attention creuse de DeepSeek :
- NSA — Native Sparse Attention. "Native" signifie que la rareté est apprise dès le début du pré-entraînement, et non ajoutée après. Trois branches parallèles (compression + sélection + fenêtre glissante) plus une porte apprise.
- DSA — DeepSeek Sparse Attention. La variante livrée dans DeepSeek V3.2 ; sélection au niveau jeton avec un indexeur très léger.
- CSA — raccourci communautaire pour la direction au niveau bloc associée à DeepSeek V4. (Ce label est moins standardisé que NSA/DSA, considérez-le comme un nom de travail).
Le résumé communautaire en une ligne : M3 utilise GQA plutôt que MLA, une sélection au niveau bloc dans l'esprit de CSA, mais il calcule l'attention sur les vraies clés et valeurs.
Détaillé dans un tableau :
| Dimension | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (inféré) |
|---|---|---|---|---|
| Substrat KV | MLA (latent) | GQA | MLA | GQA |
| Granularité de sélection | niveau jeton | niveau bloc | niveau bloc | niveau bloc |
| Branches parallèles | 1 (indexeur + sélection) | 3 (compress + select + sliding) | 1 | 1 (sélection seule) |
| Où tourne l'attention | vraies K/V | fusion triple | KV compressées | vraies K/V |
| Coût indexeur | Indexeur Lightning | branche compression | résumés de bloc | K tête unique + Block Max Pool |
| Gating | aucun | porte apprise | aucun | aucun |
Ce tableau cache un autre acronyme qui mérite d'être défini : MLA — Multi-head Latent Attention, l'astuce signature de DeepSeek. Au lieu de mettre en cache des clés et valeurs complètes, MLA les compresse en un petit vecteur "latent" partagé, le met en cache et le décompresse à la volée. Le cache KV diminue considérablement — mais les mathématiques ne correspondent plus à l'attention standard, nécessitant donc des noyaux personnalisés. Ce contraste explique le premier des trois compromis de M3.
Première soustraction : GQA comme substrat, pas MLA. Parce que M3 reste sur du GQA pur, la pile de service standard — vLLM et SGLang (les deux serveurs d'inférence open source largement utilisés) plus FlashAttention — fonctionne avec peu ou pas de modification. Aucun ingénierie nécessaire pour contourner les KV latents de MLA. Pour un laboratoire ciblant la "prêt pour la production", c'est la voie la moins risquée. C'est l'idée la plus accessible commercialement dans toute la conception : MiniMax a optimisé pour ce qui fonctionne immédiatement sur le matériel et les logiciels que tout le monde possède déjà.
Deuxième soustraction : sélection au niveau bloc, mais l'attention tourne sur les vraies clés et valeurs. Contrairement à CSA, qui calcule l'attention sur des KV compressées, M3 conserve toute la puissance expressive de l'attention softmax standard. Le coût : le cache KV ne rétrécit pas avec la sparsification — mais échanger un peu de mémoire contre une qualité préservée est un compromis judicieux.
Troisième soustraction : les deux autres branches de NSA ont disparu. NSA exécute trois chemins parallèles (compression + sélection + fenêtre glissante) plus une porte apprise. M3 ne conserve que la sélection. Un résumé communautaire l'a qualifié de NSA rationalisée et simplifiée. En une phrase : l'ingénierie d'abord. Des deux branches supprimées, la fenêtre glissante est très probablement remplacée par RoPE (Rotary Position Embedding — la manière standard dont les modèles encodent la position des jetons) plus un puits d'attention (attention sink), ou simplement par une attention dense en secours par couche, comme le font Gemma 3 et Qwen3-Next. La branche de compression est absorbée dans ce "K tête unique + Block Max Pool" minimal.
3. Comment lire les chiffres
| Étape | Accélération @ 1M | Ce que cela signifie |
|---|---|---|
| Prefill | 9,7× | Traiter 1M de jetons d'entrée en une seule passe |
| Decode | 15,6× | Générer jeton par jeton |
Le décodage surpassant le pré-remplissage est logique. Pendant le pré-remplissage, la branche d'indexation doit toujours scanner la longueur totale de l'entrée, l'économie ne s'applique donc qu'à l'attention principale. Pendant le décodage, chaque nouveau jeton n'interagit qu'avec ses blocs KV sélectionnés, et la pression de la bande passante mémoire sur le cache KV chute d'environ un ordre de grandeur — ce qui est exactement là où réside le coût du décodage.
En déduisant le taux de sélection : supposons une taille de bloc de 64 jetons, donc 1M de jetons représentent ~16 000 blocs. Une accélération de décodage de 15,6× implique que chaque requête ne touche réellement qu'environ 6 à 7 % des blocs — un champ récepteur effectif d'environ 60k à 70k jetons. Ce ratio se situe presque exactement sur le taux de rareté rapporté par l'article NSA (6-10%). Ce n'est pas une coïncidence — c'est le point idéal pour ce type de conception à l'échelle du million.
4. Inférences sur le reste du M3
En extrapolant de ce bloc d'attention unique au modèle complet — clairement étiqueté comme inférence, car un diagramme ne montre qu'une partie des choses :
- La structure MoE reste probablement.MoE — Mixture of Experts (mélange d'experts) — est l'épine dorsale du modèle (distincte de l'attention) : au lieu d'acheminer chaque jeton via un réseau géant, un routeur envoie chaque jeton vers quelques sous-réseaux "experts" spécialisés, vous obtenez donc la qualité d'un grand modèle avec le calcul actif d'un petit modèle. M2 a été lancé avec 230B de paramètres totaux / ~10B actifs / routage Top-2 ; M2.7 a déjà porté le nombre d'experts à 256. Aucune raison pour que M3 abandonne cela — le changement probable est plus profond et plus large.
- La pile d'attention complète est remplacée par une GQA creuse par blocs. Il est peu probable que la Lightning Attention du M1 revienne. M3 ne mise pas à nouveau sur l'attention linéaire ; il prend la voie "expressivité softmax + sélection de blocs top-k" — coût sous-quadratique tout en préservant la qualité.
- Plus que probablement une rareté entraînée nativement. C'est la leçon centrale de l'article NSA : le motif creux doit entrer dans les gradients pendant le pré-entraînement, sinon le comportement de récupération du modèle est brouillé. MiniMax a sa propre ligne de recherche sur les têtes de récupération, ils ne devraient donc pas tomber dans ce piège.
- Le champ de bataille est le contexte 1M+. M1 a été entraîné à 1M et extrapolé à 4M en inférence. M3 semble prêt à verrouiller cela tout en réduisant le coût d'inférence — une cadence produit très naturelle.
5. Placer le M3 dans l'espace de conception 2026
Entre 2025 et 2026, les conceptions d'attention creuse ont rapidement divergé :
- DeepSeek V3.2 DSA : MLA + top-k au niveau jeton, indexeur très léger ; qualité la plus stable, mais ingénierie noyau lourde.
- DeepSeek NSA : GQA, trois branches + porte ; plafond de qualité le plus élevé, plus complexe à mettre en œuvre.
- Qwen3-Next : mélange par couche d'attention dense et linéaire ; robuste mais relativement conservateur.
- MiniMax M3 : GQA + sélection de bloc à branche unique ; minimaliste, profitant du vent favorable du matériel.
Le sous-texte de la conception du M3 est sans ambiguïté : ne poursuivez pas l'attention théoriquement optimale — poursuivez celle qui fonctionne immédiatement, qui est rapide et qui permet de réutiliser les noyaux existants. C'est cohérent avec la décision de revenir à l'attention complète dans le M2 : stabiliser la qualité avec des méthodes traditionnelles d'abord, puis remplacer proprement une fois la technologie réellement mature.
6. Ce que cela signifie si vous construisez la prochaine vague d'applications IA
Prenez du recul par rapport à l'architecture, il existe une tendance plus large. Chaque laboratoire sérieux propose désormais une version de l'attention creuse entraînée — DeepSeek sur trois gammes, Qwen avec son mélange par couche, maintenant MiniMax. La direction est établie, et la conséquence est simple : quand chaque modèle de pointe peut gérer un contexte long à bas coût, le modèle lui-même cesse d'être un avantage compétitif. Le coût brut de l'inférence se rapproche de celui d'une commodité. La différenciation monte d'un niveau — vers quel modèle vous utilisez pour quelle charge de travail, comment vous acheminez entre eux, et à quelle vitesse vous adoptez le suivant quand il sort six semaines plus tard.
C'est un problème plus difficile que "trouver le point de terminaison le moins cher". Une équipe gérant une application en production équilibre quatre choses en même temps — qualité, latence, coût et le résultat commercial que la fonctionnalité génère réellement — et la bonne réponse diffère selon la charge de travail et change à chaque cycle de publication. Le M2 était en attention complète en octobre ; le M3 est en sparse par bloc en mai. Ce sur quoi vous étiez branché au dernier trimestre a déjà une étape de retard.
Choisir le modèle le moins cher n'est plus une stratégie gagnante pour les développeurs. Ce seront plutôt ceux qui auront construit sur une couche leur permettant de choisir, d'acheminer et de changer de modèle sans réintégrer à chaque fois que la frontière bouge — et qui consacrent leur budget d'ingénierie à leur propre produit au lieu de suivre les notes de version toutes les quelques semaines.
C'est la couche sur laquelle opère Atlas Cloud : une API sur plus de 300 modèles couvrant LLM, vidéo, image et audio, avec un routage intelligent et un accès dès le premier jour aux nouveaux lancements. La même lentille que nous avons utilisée pour démonter ce diagramme est celle que nous utilisons pour décider ce que nous intégrons et comment nous l'acheminons. Le M3 n'est pas encore public — quand il le sera, nous prévoyons de l'intégrer à Atlas avec un accès dès le premier jour, afin que les équipes qui construisent déjà avec nous puissent le proposer à leurs propres utilisateurs le jour de sa sortie, et non le trimestre suivant.
Pensées finales
Beaucoup de choses ne peuvent être confirmées à partir d'un seul diagramme : si le motif creux est mélangé couche par couche, s'il y a une solution de secours dense, si la branche d'indexation partage des embeddings avec le réseau principal, si le top-k lors de l'entraînement est dur ou souple, comment la perte de la branche d'indexation est formulée. Tout cela attend l'article officiel ou les poids.
Mais une chose est déjà actée : après DeepSeek, un autre laboratoire majeur a assemblé attention creuse + contexte long + poids ouverts dans une pile fonctionnelle. Au second semestre 2026, un contexte de 1M en open source passera probablement d'un argument de vente à une norme — et cela, en soi, compte plus que n'importe quel benchmark unique.
Références
- Skyler Miao (Responsable R&D MiniMax), publication originale sur X : Something BIG is coming — https://x.com/SkylerMiao7/status/2059285750458544561
- Résumé communautaire : MiniMax détaille son architecture d'attention creuse M3 — https://digg.com/ai/78gnmbpg
- Blog MiniMax : Pourquoi le M2 a fini par être un modèle à attention complète ? — https://www.minimax.io/news/why-did-m2-end-up-as-a-full-attention-model
- Article NSA de DeepSeek : Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention — https://arxiv.org/pdf/2502.11089
- Article sur DSA de DeepSeek V3.2 : Architectural Efficiency in LLMs: DeepSeek-V3.2-Exp and DSA — https://gregrobison.medium.com/architectural-efficiency-in-large-language-models-a-comprehensive-analysis-of-deepseek-v3-2-exp-e9802adfcdbd
- Sebastian Raschka : A Technical Tour of the DeepSeek Models from V3 to V3.2 — https://magazine.sebastianraschka.com/p/technical-deepseek
- Rapport technique MiniMax-01 : Scaling Foundation Models with Lightning Attention — https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf






