yxUS-H6oB1A
1. D'où tout a commencé : la rencontre de deux modèles
Avril 2026.
OpenAI a lancé GPT Image 2 — rendu de texte, connaissances sur le monde et esthétique, tout a été poussé à son paroxysme.
« À partir d'aujourd'hui, les images générées par IA, tout comme les textes générés par IA, sont officiellement entrées dans une ère où le commun des mortels ne peut plus les distinguer de la réalité. »
Au même moment, deux publications à fort engagement ont fait surface sur X :
@AI_Jasonyu :
GPT-Image 2 (beta) + Seedance 2.0 — associez les deux et vous obtenez un combo mortel. Le workflow est simple : GPT-Image 2 produit d'abord le storyboard ; une fois validé, on le transmet à Seedance 2.0 pour générer la vidéo longue. C'est ainsi que la vidéo par IA devrait fonctionner.
@arrakis_ai :
Le pipeline Codex + GPT Image 2 est tout bonnement révolutionnaire. C'est le workflow IA le plus disruptif que j'aie vu cette année. J'ai soumis un manuscrit avec une seule ligne — « convertis ceci en bande dessinée » — et le résultat était une BD complète et cohérente.
Les deux publications pointent vers la même chose : le meilleur modèle d'image + le meilleur modèle vidéo, chaînés dans un seul pipeline.
Le problème : pour exécuter ce pipeline auparavant, il fallait un quota OpenAI GPT Image 2, un accès à ByteDance Seedance 2.0 et du code personnalisé pour gérer les prompts, le polling et le CDN aux deux extrémités.
Ce n'est plus le cas.
2. Atlas Cloud intègre désormais GPT Image 2 : une seule clé, tout est relié
Atlas Cloud vient d'ajouter GPT Image 2 à son catalogue de modèles, rejoignant toute la gamme Seedance 2.0 (Text-to-Video / Image-to-Video / Reference-to-Video / Fast / Upscaled).
| Avant | Maintenant |
|---|---|
| Demander un quota OpenAI + intégrer Seedance séparément | Une seule clé API Atlas Cloud |
| Deux SDK, deux systèmes de facturation, deux doc différentes | Point de terminaison unifié : https://api.atlascloud.ai/api/v1 |
| Gestion manuelle du polling / CDN / erreurs | SDK officiel / MCP / modèles de compétences prêts à l'emploi |
Il n'y a en réalité que deux points de terminaison :
# Générer des images (GPT Image 2 / Seedream / Qwen Image ...) POST https://api.atlascloud.ai/api/v1/model/generateImage?utm_source=blog&utm_medium=article&utm_campaign=ultimate-drama-workflow-gpt-image-2-seedance-2-0 # Générer des vidéos (Seedance 2.0 / Kling / Vidu ...) POST https://api.atlascloud.ai/api/v1/model/generateVideo?utm_source=blog&utm_medium=article&utm_campaign=ultimate-drama-workflow-gpt-image-2-seedance-2-0 # Point de terminaison de polling partagé GET https://api.atlascloud.ai/api/v1/model/prediction/{id}
Authentification par Bearer token. export ATLASCLOUD_API_KEY=... et vous êtes prêt.
Note de conformité : Chaque personnage de ce tutoriel est rendu comme un personnage numérique photoréaliste par GPT Image 2. Aucune ressemblance avec une personne réelle n'est impliquée ou souhaitée.
3. Le meilleur modèle d'image GPT Image 2 + le meilleur modèle vidéo Seedance 2.0
La plupart des tutoriels vidéo par IA adoptent l'une des deux approches suivantes :
Approche A : Pur text-to-video (prompt direct → vidéo de 15s)
- Problème : pari risqué, gaspillage de calcul à chaque tentative.
Approche B : Segments multi-plans (6–12 plans × 5s chacun, assemblés ensuite)
- Problème : lent (6× génération d'image + 6× génération vidéo), coûteux, la cohérence des personnages se perd facilement.
drama-director emprunte une troisième voie :
Approche C : Une page de BD 9 cases + une vidéo animée de 15 secondes
- GPT Image 2 génère une seule page de 9 cases (9 cadres de storyboard dessinés dans une seule image, comme une planche de BD).
- Seedance 2.0 I2V utilise cette page + un prompt de mouvement et produit une vidéo de 15s en un seul appel — Seedance traite l'image à 9 cases comme son ADN visuel et sa référence de storyboard (personnages, garde-robe, lieux, éclairage, palette de couleurs verrouillés depuis l'image) et produit un plan cinématographique de 15 secondes de la scène réelle — vous voyez littéralement des nanofilaments se tendre, un paquebot approcher, des plaques de métal se déchirer, des colonnes d'eau jaillir — et non "une caméra qui zoome sur une page de BD".
Les trois avantages de ce combo :
| Dimension | Voie 9 cases | Voie segmentée 6-8 plans |
|---|---|---|
| Coût | 1 gén. image + 1 gén. vidéo | 6-8× gén. images + 6-8× gén. vidéos |
| Temps | ~3-5 min | ~8-15 min |
| Cohérence des persos | 9 cases sur une seule toile — garantie naturelle | Chaque plan généré séparément, nécessite un ancrage |
| Coût d'itération | Ajuster l'image_prompt, regénérer une image | Un changement de plan affecte tout le pipeline |
| Résultat final | Une vidéo de drama-BD complète, prête à poster | Nécessite un montage post-production |
Le point 3 — la cohérence des personnages — est le plus gros casse-tête des workflows chaînés. Une grille de 9 cases, c'est littéralement "9 régions sur la même toile", donc GPT Image 2 garantit naturellement que le même personnage garde la même apparence et la même tenue sur les 9 cases. Cette décision de design unique élimine une énorme partie de l'ingénierie en aval.
4. drama-director : un message, pipeline complet
Ce que vous faites
Dans Claude Code, il suffit de :
Transforme ce passage de roman en un drama BD :
Claude détecte les déclencheurs ("drama BD" / "storyboard" / "9 cases" / ...), charge la compétence drama-director, et :
- Lit le texte → le résume en 9 temps forts (ordre de lecture 3×3)
- Construit un
image_promptcomplet (descriptions des cases + contraintes de style) et vous le soumet pour validation - Appel unique à GPT Image 2 → page de BD 9 cases (
.jsonavecimage_url) - Vous montre l'image ; une fois validée, appel unique à Seedance 2.0 I2V → animation BD de 15 secondes (
.jsonavecvideo_url) - Émet un rapport Markdown.
Vous n'avez tapé que deux messages du début à la fin : le script, et "confirmer".
Modèles utilisés
| Étape | ID du modèle (par défaut) | Notes |
|---|---|---|
| Page 9 cases | openai/gpt-image-2/text-to-image | Fallback sur openai/gpt-image-1.5 si indisponible |
| Vidéo animée | bytedance/seedance-2.0/image-to-video | 15s / 720p / 1:1, configurable |
| Variante rapide | bytedance/seedance-2.0-fast/image-to-video | Moins cher, plus rapide |
5. Installation en 3 minutes
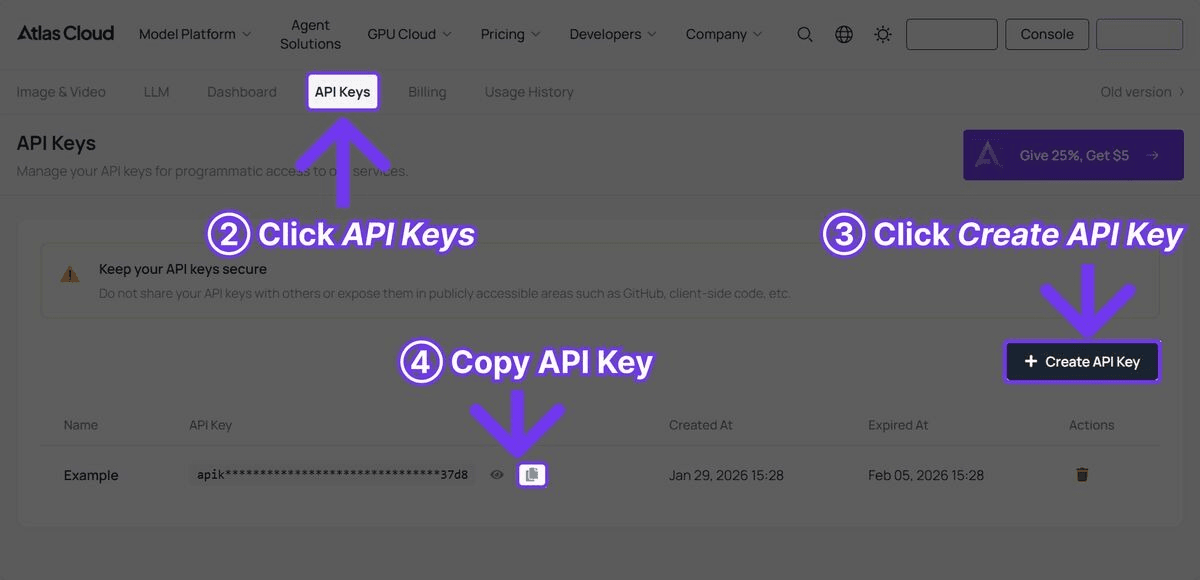
Étape 1 — Obtenir une clé API
Inscrivez-vous sur atlascloud.ai et générez une clé depuis la page API Keys.
export ATLASCLOUD_API_KEY="sk-votre-clé" echo 'export ATLASCLOUD_API_KEY="sk-votre-clé"' >> ~/.zshrc
Étape 2 — Installer la compétence drama-director
Clonez depuis GitHub dans le répertoire de compétences de Claude :
mkdir -p ~/.claude/skills git clone https://github.com/kianaliang-dev/drama-director-skill ~/.claude/skills/drama-director
Vérifiez :
ls ~/.claude/skills/drama-director/ # Attendu : SKILL.md scripts/
La compétence est entièrement autonome —
SKILL.mdintègre le routeur d'archétype de scène, les contraintes strictes du moteur Seedance et les règles de coupe, tout est inclus. Aucune autre compétence requise.
Étape 3 — Test de fumée des scripts
python3 ~/.claude/skills/drama-director/scripts/generate_image.py \ --prompt "a cinematic 3x3 comic book page with 9 panels showing a cyberpunk chase scene, bold black gutters, film noir palette" \ --aspect 1:1
Après ~30 secondes, vous devriez voir un bloc JSON avec image_url. Ouvrez l'URL dans un navigateur — si vous voyez une page de BD à 9 cases, le pipeline fonctionne.
6. Démo : Opération Guzheng du Problème à trois corps → 15s de drama BD
Pourquoi cette scène ?
L'une des séquences les plus explosives visuellement du roman de Liu Cixin — un paquebot tranché par des nanofilaments sur le canal de Panama. Une action cinématographique extrêmement dense, pile 9 temps forts :
Canal de Panama, nuit. 50 nanofilaments, chacun moins d'un dixième du diamètre d'un cheveu humain, sont tendus au-dessus de l'eau comme les cordes d'un guzheng géant.
Le paquebot Judgment Day approche. L'étrave entre en contact avec le réseau de filaments. Le navire continue d'avancer — et est tranché en 45 couches horizontales.
Les tranches se décalent, se désalignent et s'effondrent en séquence. D'énormes plaques de métal tombent dans le canal comme des cartes à jouer, envoyant des colonnes d'eau hautes de plusieurs étages.
Sur la rive, tout le monde retient son souffle. C'est la première fois dans l'histoire humaine qu'une telle méthode est utilisée pour anéantir chaque âme à bord d'un navire massif.
Déroulement de la conversation
Vous collez dans Claude Code :
Transforme ce passage du Problème à trois corps en un drama BD (grille 9 cases + vidéo 15s) : Canal de Panama, nuit. 50 nanofilaments tendus au-dessus de l'eau... (passage complet collé)
Ce que fait Claude :
- Détecte les déclencheurs, charge la compétence
drama-director. - Découpe le passage en 9 temps forts.
- Vous montre l'
image_promptcomplet pour validation :
A cinematic 3x3 comic book page with 9 panels depicting "Operation Guzheng" from Three-Body Problem: nanofilaments slicing a cruise ship on the Panama Canal at night. ... (Style et détails)
Vous répondez "confirmer".
generate_image.pys'exécute → page 9 cases retournée en ~1 minute.- Vous dites "OK, continue".
- Claude choisit Impact (le moment décisif), applique les contraintes Seedance + la structure en trois sections (Style & Ambiance → Dynamique → Statique), et écrit un
motion_promptdécrivant l'action réelle de la scène — l'image n'est ici que l'ADN visuel :
(Contenu du motion_prompt détaillé selon la structure requise par Seedance)
Concept clé à comprendre : Seedance I2V traite l'image à 9 cases comme ADN visuel, puis génère un plan cinématographique réel basé sur le motion_prompt — ce n'est pas un "zoom sur une page de BD". Donc le motion_prompt doit décrire ce qui se passe réellement dans la scène.
- 2-3 minutes plus tard, la vidéo est prête.
video_urlet/tmp/drama_output/report.mdlivrés.
Estimation des coûts
| Élément | Appels | Prix approx. |
|---|---|---|
| GPT Image 2 (1:1, 1024×1024) | 1 | Selon prix Atlas Cloud |
| Seedance 2.0 I2V (15s) | 1 | ~1,5 $ |
| Total | ~1,5-2 $ par épisode |
7. Variantes courantes
- Style anime japonais : "Use Japanese anime style, Studio Ghibli palette"
- Style comics US : "Use American superhero comic style"
- Look cinématographique : "Use photorealistic cinematic Netflix style, 16:9, 8K"
- Format TikTok : "Use 9:16 nine-panel layout"
- Économiser : "Use seedance-2.0-fast"
8. MCP et repos officiels (pour les développeurs)
Si vous voulez câbler votre propre pipeline :
Repo des compétences
npx skills add AtlasCloudAI/atlas-cloud-skills
Repo : https://github.com/AtlasCloudAI/atlas-cloud-skills
Serveur MCP officiel (9 outils)
claude mcp add atlascloud -- npx -y atlascloud-mcp
npm : https://www.npmjs.com/package/atlascloud-mcp
9. Décisions de design
1. Pourquoi 9 cases ? 3×3 équilibre lisibilité et densité d'informations.
2. Pourquoi une seule image + une vidéo suffit ? Le coût, le temps et la cohérence. Seedance 2.0 I2V est désormais assez performant pour transformer un storyboard en vidéo animée sans montage humain complexe.
3. Pourquoi le motion_prompt décrit "l'action de la scène" et non "le panoramique de la BD" ? Pour éviter que le modèle ne filme littéralement une BD physique. L'image est l'ADN, le prompt est l'action.
10. FAQ
Q : Combien coûte l'API ? A : Atlas Cloud est au paiement à l'utilisation, sans abonnement. ~1,5-2 $ par épisode.
Q : GPT Image 2 n'est pas encore dans la liste ? A : generate_image.py bascule automatiquement sur gpt-image-1.5.
Q : Comment rendre les cases bien séparées ? A : Renforcez le prompt — "bold black borders between panels, clear white gutters".
Q : Temps de production ? A : ~3-5 minutes au total.






