
Lors de la création d'applications IA ou du prototypage de workflows agentiques, nous devons fréquemment expérimenter avec plusieurs grands modèles de langage pour trouver celui qui convient le mieux. Cependant, comme les différents fournisseurs utilisent des structures d'API et des protocoles distincts, passer de l'un à l'autre nécessite généralement une refonte fastidieuse du code et des mises à jour constantes de votre logique backend.
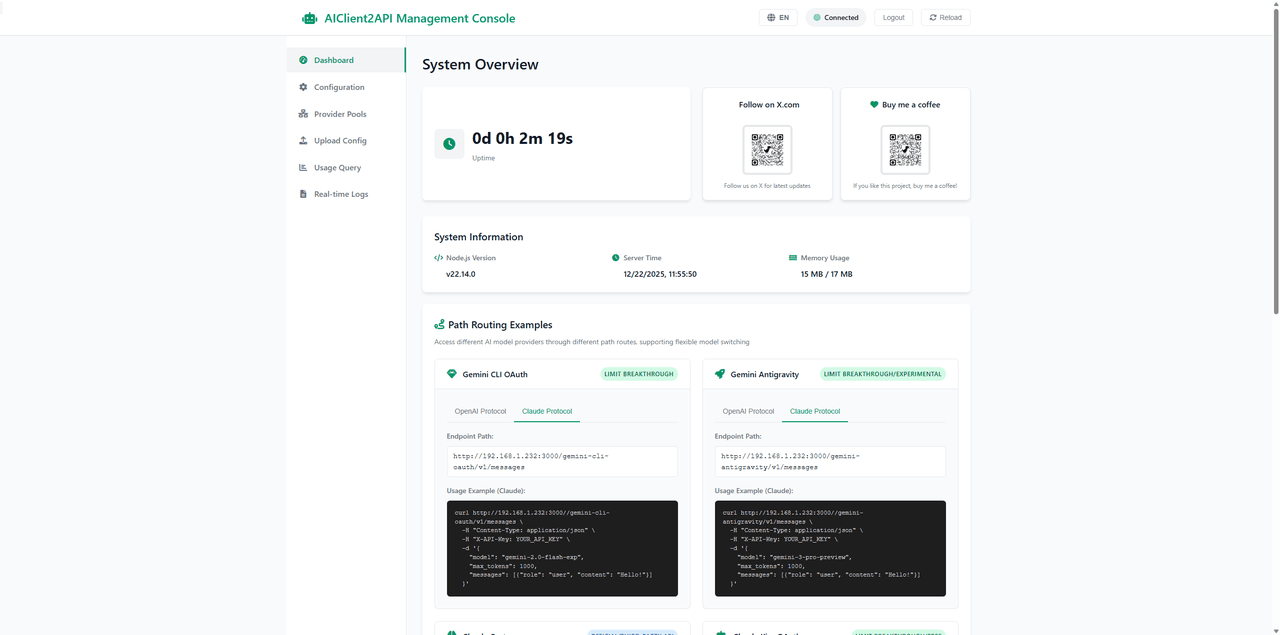
AIClient2API répond précisément à ce défi. Il agit comme une couche proxy intelligente qui simule les requêtes client provenant de plateformes comme Gemini CLI, Antigravity, Codex, Grok et Kiro, en les encapsulant dans une interface API unique et standardisée, compatible avec OpenAI. En plus de l'unification des protocoles, il fournit un tableau de bord Web pour surveiller l'état en direct de chaque nœud.
Fonctionnalités principales
- Changement de modèle sans coût de développement : Écrivez votre code d'intégration une seule fois en utilisant les formats standard du SDK OpenAI, et changez de fournisseur backend dynamiquement sans modifier votre logique métier.
- Console de gestion visuelle : Inclut un tableau de bord Web pour la gestion de la configuration en temps réel, le suivi de l'état de santé, les tests d'API via un Playground intégré et l'audit des journaux de requêtes.
Architecture technique et implémentation
Le projet s'appuie sur une architecture modulaire « AI-first » construite sur Node.js pour gérer la traduction de protocoles et maintenir une haute disponibilité :
plaintext1[ Votre application (Cherry-Studio / Cline / Code personnalisé) ] 2 │ (Requête standard OpenAI / Claude) 3 ▼ 4 ┌─────────────────────────────┐ 5 │ Passerelle AIClient2API │ 6 └──────────────┬──────────────┘ 7 │ 8 ┌─────────────┴─────────────┐ 9 ▼ ▼ 10 ┌──────────────┐ ┌──────────────┐ 11 │ Adaptateurs │ │ Pool fournisseurs│ 12 └───────┬──────┘ └───────┬──────┘ 13 │ │ (Vérification santé / Refroidissement) 14 ▼ ▼ 15 ┌──────────────┐ ┌──────────────┐ 16 │ Sidecar TLS │ │ Failover & │ 17 │ (Go uTLS) │ │ Repli │ 18 └───────┬──────┘ └───────┬──────┘ 19 │ │ 20 └─────────────┬─────────────┘ 21 ▼ 22 [ Backends : Gemini, Grok, Kiro...]
1. Stratégies et modèles d'adaptateurs
Lorsqu'une requête atteint la passerelle, le système identifie le couple modèle-fournisseur ciblé et l'achemine via un adaptateur de service spécifique. L'adaptateur traduit les payloads standard OpenAI ou Claude dans la structure exacte requise par le client amont (comme la structure CLI interne de Gemini ou les endpoints de Grok), gérant de manière transparente les réponses standard et en streaming (text/event-stream).
2. Pools de fournisseurs intelligents et chaînes de repli
Pour garantir une fiabilité de niveau production, le proxy gère un pool de comptes et d'endpoints :
- Vérification de santé et refroidissement automatisés : Le système effectue des heartbeats périodiques. Si un nœud tombe en panne ou déclenche une limite de 429 Too Many Requests, il est placé dans une file d'attente de refroidissement temporaire et automatiquement évité.
- Repli inter-types : Si un type de fournisseur est à court de quota, la passerelle peut rediriger les requêtes vers une chaîne de repli préconfigurée (par exemple, passer de gemini-cli-oauth à gemini-antigravity) tant que les protocoles correspondent.
3. Simulation d'empreinte TLS (Sidecar TLS)
Certains services en amont imposent des contrôles réseau stricts et bloquent les requêtes qui ne correspondent pas aux empreintes TLS des navigateurs. Pour résoudre ce problème, le projet intègre un proxy Sidecar TLS écrit en Go (utilisant uTLS). Il émule les handshakes TLS standard de Chrome et gère automatiquement la négociation HTTP/2 pour éviter les erreurs 403 Forbidden.
Intégration de l'écosystème : Support natif d'AtlasCloud
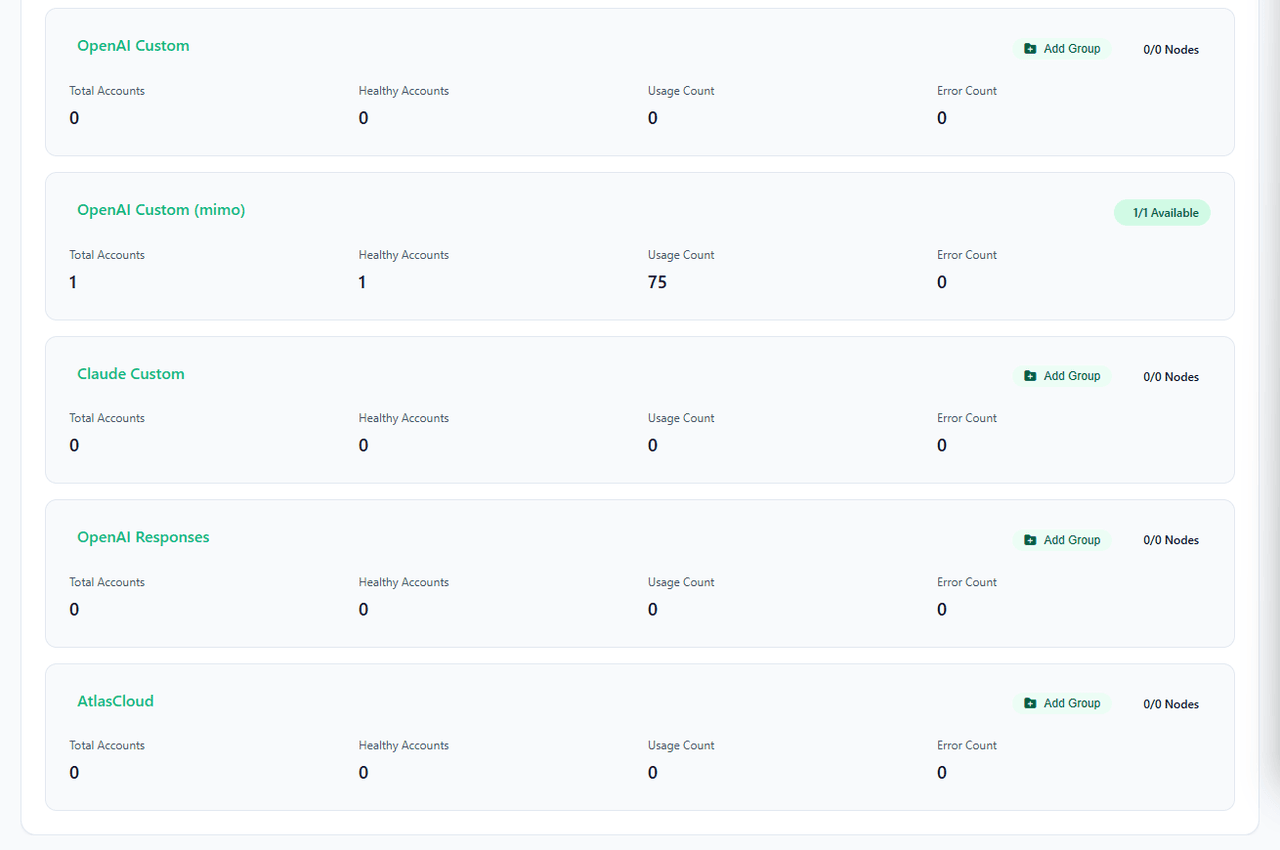
Dans les récentes mises à jour, AIClient2API a introduit un support natif pour AtlasCloud, une plateforme d'inférence IA multimodale tout-en-un.
AtlasCloud regroupe des modèles extrêmement rentables tels que Qwen 3.6, DeepSeek v4 pro, Kimi k2.6, GLM 5.1 sous un endpoint unique. L'intégration d'AtlasCloud dans votre pool AIClient2API offre des avantages spécifiques :
- Changement fluide et débit stable : Vous pouvez passer sans friction entre les capacités de raisonnement de DeepSeek, le traitement linguistique de Qwen et la génération multimodale. L'infrastructure d'entreprise sous-jacente assure des taux de concurrence stables.
- Modèles prêts à l'emploi : Le dépôt inclut des configurations prédéfinies dans
provider_pools.json.exampleainsi que des chemins de routage dédiés, vous permettant d'être opérationnel immédiatement.
Cette configuration est particulièrement bénéfique pour les développeurs participant à la Promotion Coding Plan économique d'AtlasCloud, afin de minimiser les frais d'infrastructure.
Démarrage rapide
- Déploiement via Docker :
- Bash
plaintext1docker run -d -p 3000:3000 -p 8085-8086:8085-8086 -p 1455:1455 -p 19876-19880:19876-19880 --restart=always -v "votre_chemin/configs:/app/configs" --name aiclient2api justlikemaki/aiclient-2-api
- Configuration via l'interface Web : Accédez à http://localhost:3000 (mot de passe par défaut : admin123) pour ajouter vos identifiants et gérer vos fournisseurs visuellement.
- Routage de votre trafic : Pointez votre client de bureau IA ou SDK backend préféré vers votre instance de passerelle locale.
Pour tous les détails d'implémentation, la documentation et les options de configuration avancées, visitez le dépôt GitHub.






