구글은 I/O 2026에서 타임라인이나 키프레임 편집 방식이 아닌, 자연어 대화로 영상을 편집하는 멀티모달 모델 Gemini Omni를 공개했습니다. 버블 조각상, 액체 거울, 바이올리니스트 데모가 입증하듯, 이는 단순한 '텍스트-투-비디오'를 넘어 '이미 가지고 있는 영상을 텍스트로 편집하는' 혁신적인 변화를 의미합니다. 영상 제작의 '아이폰 카메라 모먼트'라 할 수 있습니다. 다만, 음성 및 오디오 편집 기능과 Pro 등급이 의도적으로 제외된 점은 주목할 만합니다.
새벽 1시, 30초짜리 클립을 4시간째 편집 중입니다. 프로젝트 파일에는 47개의 레이어가 쌓여 있고, 키프레임을 조절하느라 손목은 비명을 지릅니다. 그때 클라이언트로부터 메시지가 옵니다. "조명을 좀 더 따뜻하게 바꿀 수 있을까요?" 전문가인 당신은 결국 처음부터 다시 작업을 시작해야 합니다.
그게 바로 지금까지의 영상 편집이었습니다. 정말로, 그랬었습니다.
2026년 5월 19일, 구글은 그 관행을 조용히 종식시켰습니다.
I/O 2026에서 구글은 **Gemini Omni**를 발표했습니다. 이 멀티모달 모델은 영상 편집을 우리 모두가 10년 뒤에나 가능할 것이라 여겼던 수준, 즉 **'자연스러운 대화'**로 바꿔놓았습니다.
핵심 약속: 영상 편집을 '운영'하지 말고, '대화'하세요
이 모델의 본질은 간단합니다. 이제 영상을 직접 '편집'하는 것이 아니라, 원하는 바를 영상에 '말'하면 됩니다.
구글의 발표는 핵심을 명확히 짚습니다. "모든 지시는 이전 작업에 기반합니다. 캐릭터의 일관성이 유지되고, 물리학적 법칙이 적용되며, 장면은 이전 상황을 기억합니다."
이는 단순한 Veo 업데이트가 아닙니다. 구글 딥마인드 제품 페이지는 이를 더 알기 쉽게 설명합니다. "Gemini Omni를 영상 버전의 Nano Banana라고 생각하세요." 작년에 Nano Banana가 사진 편집을 텍스트 입력만으로 가능하게 만들었다면, 이제 Omni가 움직이는 영상에서 동일한 기능을 수행합니다.
이 제품군의 첫 번째 모델인 Gemini Omni Flash는 이미 Gemini 앱, Google Flow, YouTube Shorts에서 사용할 수 있습니다.
이번 발표의 성격을 재정의할 수 있는 중요한 코멘트가 있습니다. TechCrunch와 딥마인드 팀의 인터뷰에서 리서치 엔지니어 게이브 바스-마론(Gabe Barth-Maron)은 사용자들이 Omni로 만드는 결과물을 *"개인화된 밈(personalized memes)"*이라고 표현했습니다.
이것이 핵심입니다. 영상 제작은 이제 '기술'에서 '표현'의 영역으로 이동했습니다. 마치 아이폰이 DSLR의 성벽을 무너뜨리고 사진이라는 장르를 재편했듯이 말입니다.
트위터를 강타한 데모들
마케팅 문구는 제쳐두더라도, 이번 발표를 성공시킨 것은 실제 데모였습니다. 현재 가장 화제가 되는 3가지 사례입니다.
- 버블 조각상: 돌 조각상 클립을 Omni에 입력하고 *"조각상을 비눗방울로 바꿔줘"*라고 입력하면, 동일한 구도와 조명, 그림자를 유지하면서도 조각상은 주변 빛을 머금은 투명한 비누 재질로 변합니다.
- 액체 거울: 손이 거울에 닿는 장면에서 *"거울이 액체처럼 아름답게 일렁이게 하고, 사람의 팔을 거울 재질로 바꿔줘"*라고 명령합니다. Windows Report가 보도한 바와 같이, 물결이 물리적으로 퍼져 나가고 팔의 크롬 재질에 실제 방의 모습이 반사됩니다.
- 연쇄 편집: 구글의 바이올리니스트 데모는 세 단계의 편집을 보여줍니다. 무대 → 이동 중인 환경 → 어깨너머 카메라 앵글. 세 번의 편집 동안 인물, 얼굴, 자세, 악기 잡는 모양까지 모두 일관성 있게 유지됩니다.

이것은 텍스트-투-비디오가 아닙니다. **'기존 영상을 텍스트로 편집하는 것'**입니다. 이 작은 차이가 모든 것을 바꿉니다.
크리에이터들이 열광하는 이유
이번 모델 출시가 다른 때보다 강력하게 다가오는 이유는 간단합니다. Omni는 생성형 비디오의 가장 고통스러운 루프를 끊어버렸기 때문입니다.
기존 루프: 생성 → 결과물 불만족 → 전체 프롬프트 재작성 → 90초 대기 → 여전히 결과물 불만족 → 반복.
새로운 루프: 생성 → "조명을 골든 아워로 바꿔줘" → 완료 → "카메라 무빙을 느리게 해줘" → 완료.
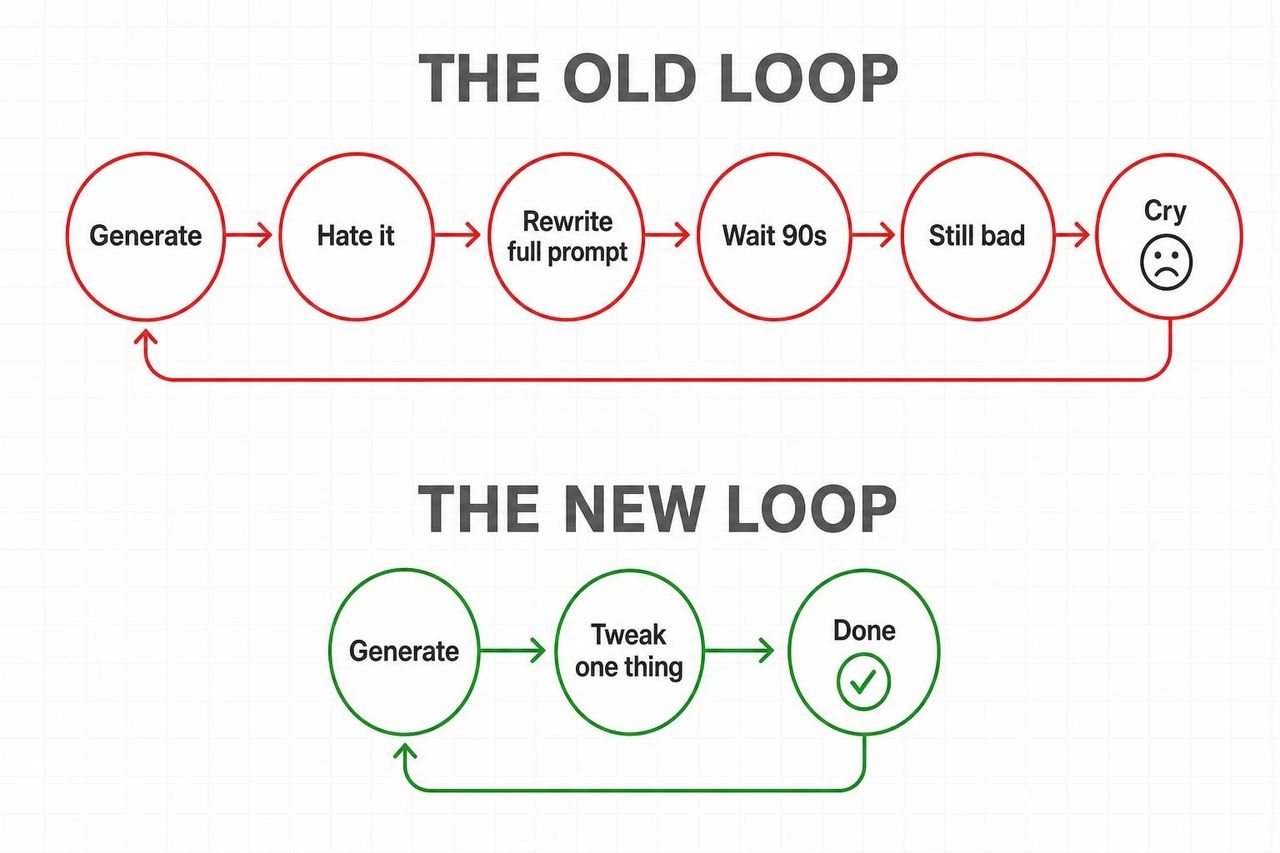
Android Central은 *"Gemini Omni로 인해 기존의 영상 편집 앱들이 고대 유물처럼 느껴질 수 있다"*고 단언했습니다. TechRadar 또한 프롬프트를 수정할 때마다 영상이 초기화되지 않고 움직임이 일관성 있게 유지된다는 점을 높게 평가했습니다.
개발자들도 즉각 반응하고 있습니다. 중국의 개발자 커뮤니티 V2EX에서 한 개발자는 *"영상 내 객체를 채팅 기반으로 수정하는 방식은 명확한 미래의 방향성이다. 속도와 일관성이 기대 이상"*이라고 평했습니다. 면역학자이자 AI 평론가인 Dr. Derya Unutmaz는 키노트 직후 트윗을 통해 *"구글 딥마인드의 새로운 멀티모달 모델 Gemini Omni는 정말 놀랍다. 영상 퀄리티가 매우 좋으니 꼭 써보길!"*이라고 전했습니다.
AI 전문가 커뮤니티와 개발자 포럼이 동시에 같은 반응을 보인다는 것은 업계의 실질적인 변곡점에 도달했음을 의미합니다.
구글이 조심스럽게 숨기고 있는 것들
물론 장밋빛 전망만 있는 것은 아닙니다.

Engadget은 *"Veo 3.1을 비롯한 영상 생성 모델들의 주된 문제는 사용자들이 거부감을 느끼는 '불쾌한 골짜기' 현상이다. 과연 실제 품질이 구글의 과장된 주장만큼 좋을지는 지켜봐야 한다"*고 지적했습니다.
DataCamp의 실사용 테스트에서는 투석기가 물체를 뒤로 발사하는 등 물리 법칙 오류가 발견되기도 했습니다. 독립적인 벤치마크 결과가 공개되기까지는 시간이 더 필요할 것으로 보입니다.
또한, 기존 영상 내의 음성 및 오디오 편집 기능은 의도적으로 제외되었습니다. 구글은 *"해당 기능을 책임감 있게 사용자에게 제공할 방법을 모색 중"*이라고 밝혔습니다. 즉, 딥페이크 위험이 너무 크기 때문에 가장 위험한 기능은 비공개로 유지하고 있는 것입니다.
모든 Omni 클립에는 구글의 보이지 않는 워터마크인 SynthID와 C2PA 콘텐츠 인증 정보가 포함됩니다. 이는 선택 사항이 아니라 이제 필수 표준이 되었습니다.
당신의 워크플로우에 미칠 실제 영향
과장된 내용을 걷어내고 나면, 몇 가지 분명한 변화가 보입니다:
- 도구는 '대화' 그 자체가 됩니다. 타임라인도, 레이어도, 키프레임도 필요 없습니다. 오직 언어만 있으면 됩니다.
- 피드백 루프가 압축됩니다. 90초 걸리던 재생성 시간이 10초 내의 수정 작업으로 바뀝니다.
- 전문가의 진입 장벽이 낮아집니다. 감각만 있다면 누구든 슬랙 메시지를 보내듯 빠르게 영상을 수정할 수 있게 되면서, 경쟁력은 '제작 기술'에서 '아이디어'로 옮겨갑니다.
마케팅 팀, 인디 크리에이터, 교육자 등 "빠르게 10초짜리 클립이 필요한" 모든 사람에게 이번 발표는 변곡점입니다. 모델이 완벽해서가 아니라, 상호작용 방식이 드디어 올바른 방향으로 정립되었기 때문입니다.
미래의 영상 편집에는 소프트웨어가 필요하지 않습니다. 어휘력만 있으면 됩니다.
영상 생성 프로덕션을 위한 하나의 통합 API
구글이 Gemini 앱과 Google Flow를 통해 Gemini Omni Flash를 일반 사용자에게 제공하는 한편, 자체 워크플로우에 동일한 멀티모달 비디오 엔진을 통합하려는 개발자와 제품 팀에게는 안정적이고 예측 가능한 API 계층이 필요합니다.
Atlas Cloud는 구글의 네이티브 멀티모달 모델을 별도의 벤더 계정, 결제 포털, SDK 관리 없이 사용할 수 있도록 OpenAI 호환 API를 통해 Gemini Omni Flash를 제공하며, 300개 이상의 이미지, 비디오, LLM 모델을 통합 지원합니다.
Gemini Omni Flash를 Atlas Cloud에서 지금 바로 사용해 보세요:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| 변형 모델 | 최적 활용 | 입력값 | 해상도 | 길이 | 시작 가격 |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Developer) | 프롬프트 기반 시네마틱 영상 생성 | 텍스트 (최대 20,000자) | 720p / 1080p / 4K | 4, 6, 8, 10초 | USD0.2 + USD0.1/초 |
| Gemini Omni Flash Image-to-Video (Developer) | 실사 기반 피사체 일관성 영상 생성 | 텍스트 + 최대 7개 참조 이미지 | 720p / 1080p / 4K | 4, 6, 8, 10초 | USD0.2 + USD0.1/초 |
퀵 스타트 — 5줄의 코드로 Gemini Omni Flash 영상 생성하기:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
API는 즉시 예측 ID를 반환하며, /api/v1/model/prediction/{id}를 폴링하여 렌더링된 MP4 URL을 확인할 수 있습니다. 전체 스키마와 7개 언어로 된 코드 샘플, 노코드 플레이그라운드는 위 링크된 모델 페이지에서 확인 가능합니다.
개발자를 위한 마지막 조언
이런 모델이 발표될 때마다 마주하게 되는 불편한 현실이 있습니다. 다음 분기만 되어도 "세계 최고의 영상 모델"이라는 타이틀을 단 새로운 발표들이 쏟아져 나올 것입니다. 각각의 모델은 다른 SDK, 다른 인증 방식, 다른 요금 체계를 가지고 있어, 팀은 매번 새로운 모델을 도입하고 이전 모델을 폐기하는 데 시간을 허비하게 될 것입니다.
이것이 바로 **Atlas Cloud**가 해결하고자 하는 문제입니다.
우리는 개발자에게 300개 이상의 모델에 액세스할 수 있는 단 하나의 엔드포인트를 제공합니다. 모든 주요 파운데이션 모델과 오픈 소스 기반의 전문 모델을 하나의 코드로 관리하세요. SDK 재통합 없이 모델을 교체하고 벤치마크를 수행할 수 있습니다. 오늘 가장 화제인 모델을 즉시 도입하고, 다음 달에 더 뛰어난 모델이 나오면 코드를 수정할 필요 없이 바로 교체하세요.
현재 AI 업계에서 유일하게 확실한 것은 리더보드가 매주 바뀐다는 사실입니다. 변화에 흔들리지 않는 환경을 구축하세요.






