4월 초, "HappyHorse-1.0"이라는 이름의 모델이 갑자기 등장했습니다. 이 모델은 Artificial Analysis 비디오 리더보드 4개 부문에서 1위를 차지하며, 바이트댄스의 Seedance 2.0과 Kling을 큰 격차로 따돌렸습니다.
보도 자료도, 블로그 게시물도 없었으며 회사 이름도 가려져 있었습니다. 모델 페이지에는 단순히 "coming soon(출시 예정)"이라는 문구만 적혀 있었습니다.
4월 10일, 알리바바의 ATH 부서는 해당 프로젝트를 인정했습니다. HappyHorse는 ATH 혁신 부서의 내부 R&D 프로젝트로, 현재 비공개 베타 테스트 중입니다. API는 4월 30일에 공개될 예정입니다.
더욱이 HappyHorse-1.0은 완전 오픈 소스로 전환될 예정입니다. 이 모델은 오디오와 비디오를 동시에 네이티브 방식으로 생성하는 최초의 오픈 소스 비디오 모델로 홍보되고 있습니다.
이러한 "조용한 출시" 후 "화려한 발표"는 중국 AI 기업들 사이에서 하나의 트렌드가 되고 있습니다. 샤오미는 "Hunter Alpha"라는 코드명으로, 지푸(Zhipu)는 새로운 GLM 모델에 "Pony Alpha"라는 이름을 사용하여 이러한 방식을 취한 바 있습니다.
이번 기사에서는 HappyHorse에 대해 알려진 사실과 그것이 의미하는 바를 분석합니다.
리더보드에서의 HappyHorse 위치
Artificial Analysis는 텍스트-비디오(오디오 없음), 이미지-비디오(오디오 없음), 텍스트-비디오(오디오 포함), 이미지-비디오(오디오 포함) 등 4가지 리더보드를 운영합니다.
4월 13일 정오 기준 데이터는 다음과 같습니다:
- 텍스트-비디오(오디오 없음): 1384 Elo. Seedance 2.0보다 111점 앞서 있습니다.
- 이미지-비디오(오디오 없음): 1413 Elo. 플랫폼에 기록된 역대 최고 점수입니다.
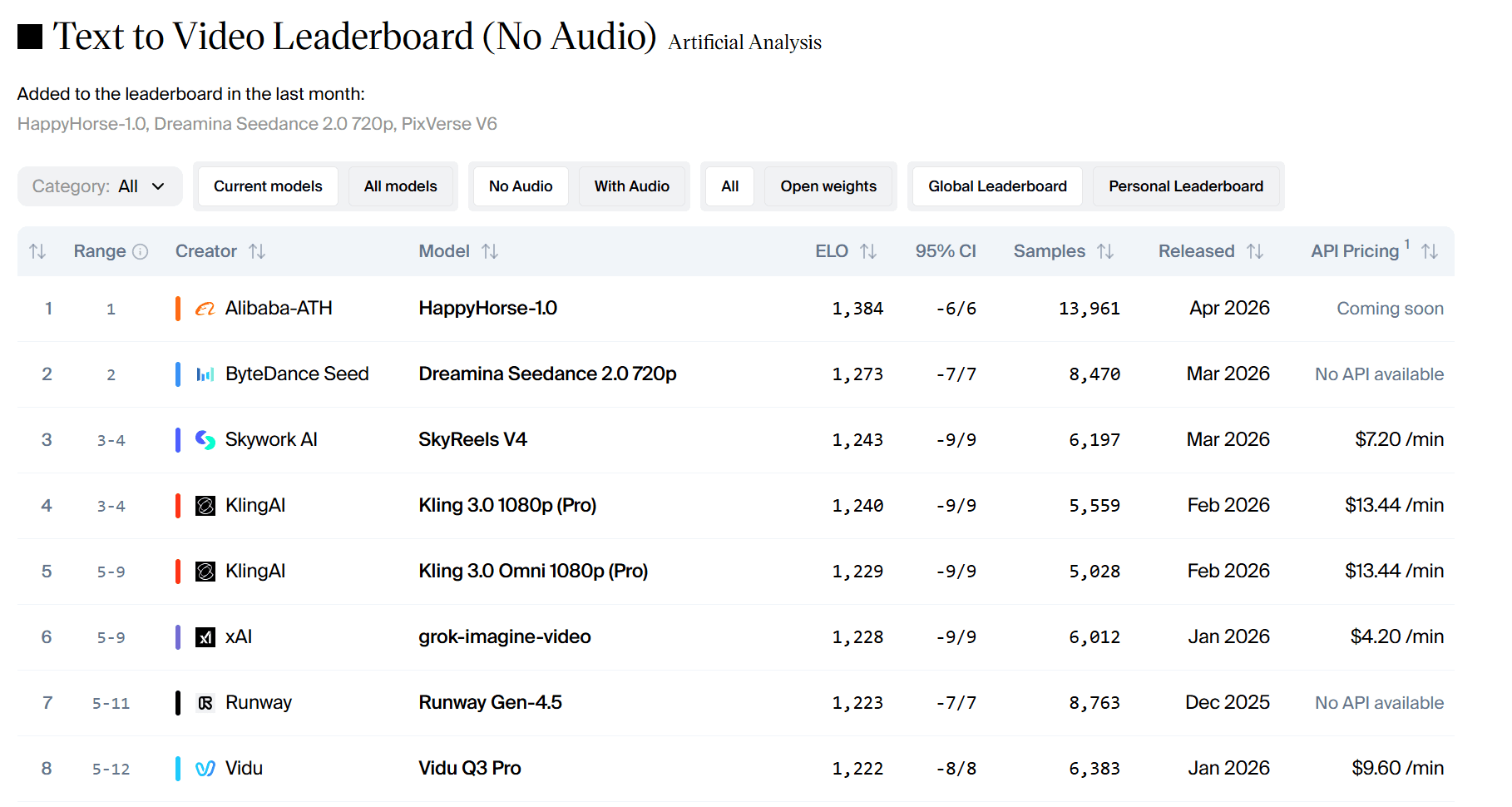
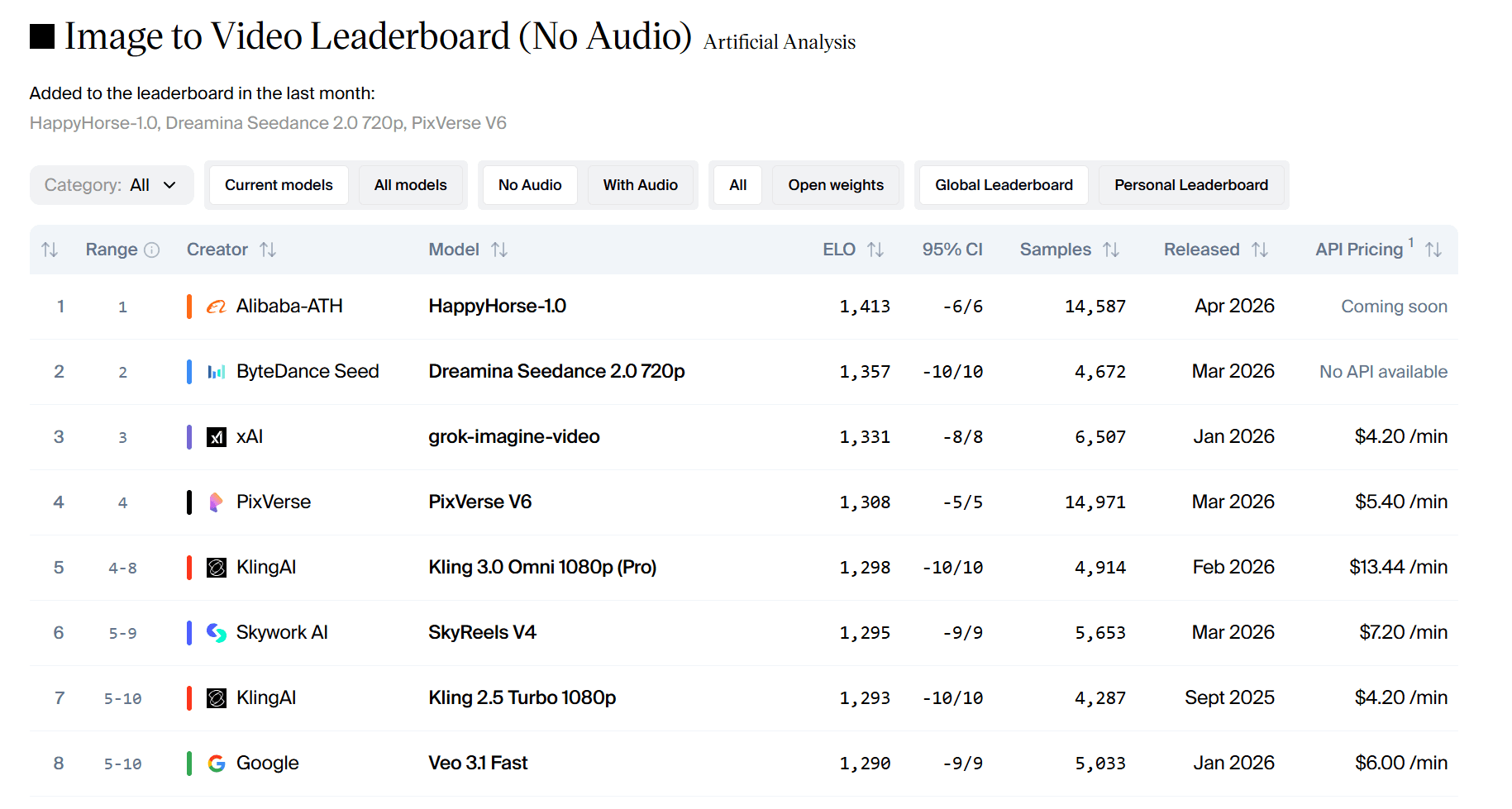
Elo 점수에서 60점 이상의 차이는 명확한 선호도를 나타냅니다. 111점의 차이는 블라인드 테스트에서 사용자들이 압도적으로 HappyHorse를 선택했음을 의미합니다.
그러나 오디오가 포함되면 상황이 달라집니다. 그 차이는 1~2점으로 줄어들어 사실상 동점 수준이 됩니다. 이는 HappyHorse의 시청각 동기화 및 음질이 비약적으로 우월하지는 않음을 보여줍니다. 이 점에 있어서는 Seedance와 거의 대등합니다.
HappyHorse와 Seedance 2.0 비교
| 항목 | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| 모델 성격 | 오픈 소스 | 폐쇄형 상용 시스템 |
| 아키텍처 | 통합 Transformer | 양방향 Diffusion Transformer (DB-DiT) |
| 멀티모달 역량 | 동시 오디오/비디오 생성 (One-pass) | 멀티모달 입력 (텍스트, 이미지, 비디오, 오디오) |
| 비디오 생성 방식 | 원패스(One-pass) 생성 | 파이프라인 기반 생성 |
| 비디오 생성 길이 | 약 5~10초 (1080p) | 최대 약 60초 (2K) |
두 모델은 서로 다른 철학을 보여줍니다.
HappyHorse‑1.0: 오픈 소스. 통합 Transformer. 오디오/비디오 동시 생성. 원패스 처리. 7개 언어의 네이티브 립싱크 지원. 150억 개의 파라미터. H100 환경에서 5초 분량의 1080p 비디오를 생성하는 데 38초가 소요됩니다.
Seedance 2.0: 폐쇄형 상용 시스템. 양방향 Diffusion Transformer (DB‑DiT). 멀티모달 입력. 60초 분량의 2K 비디오 생성 가능. 8개 이상의 언어 립싱크 지원.
순수 시각적 품질 면에서는 블라인드 테스트에서 HappyHorse가 확실히 선호됩니다. 시청각 동기화 및 음질 면에서는 두 모델이 거의 비슷합니다. 사용성 면에서는 Seedance가 이미 Volcano Engine과 같은 서비스를 통해 성숙한 API를 제공하고 있습니다. HappyHorse API는 4월 30일에 출시될 예정이며, 비공개 베타에서의 성능은 여전히 검증 중입니다.
Artificial Analysis에서 진행한 HappyHorse-1.0과 Dreamina Seedance 2.0의 생성 예시 비교 (텍스트-비디오, 오디오 포함):
프롬프트: 큰 경기의 결승선에 있는 원뿔이 되는 꿈을 꾸는 소심한 작은 교통 원뿔에 대한 픽사 스타일의 짧은 애니메이션. 다른 원뿔들은 그 야망을 비웃습니다. 공사 인부가 실수로 마라톤 결승선에 그것을 설치합니다. 주자들이 지나가면서 원뿔의 표정이 두려움에서 기쁨으로 바뀝니다. 머리 위로 꽃가루가 뿌려집니다. 다른 원뿔들이 TV로 이를 지켜보며 영감을 받습니다. 오디오: 교통 소음에서 관중들의 환호성으로, 그리고 고무적인 음악으로.
아키텍처 정보
HappyHorse는 독특한 접근 방식을 취합니다.
이 모델은 150억 개의 파라미터를 가지고 있으며, 40개 레이어의 통합 셀프 어텐션(Self-attention) Transformer를 사용합니다. 텍스트, 비디오, 오디오 토큰이 모두 동일한 시퀀스에 입력되어 공동으로 모델링됩니다. 이는 "비디오를 먼저 생성하고 오디오를 나중에 입히는" 일반적인 파이프라인과는 크게 다릅니다. 여기서는 소리와 장면이 처음부터 같은 의미 공간에 존재합니다.
이 모델은 DMD-2 증류와 MagiCompiler를 통한 전체 그래프 최적화를 사용합니다. 단일 H100 GPU에서 5초 분량의 1080p 비디오를 생성하는 데 약 38초가 걸립니다.
영어, 중국어(보통화), 광둥어, 일본어, 한국어, 독일어, 프랑스어 등 7개 언어의 네이티브 립싱크를 지원합니다. 단어 오류율(WER)은 오픈 소스 모델 중 가장 낮은 수준입니다.
Artificial Analysis 블라인드 테스트 참가자들은 HappyHorse가 특히 캐릭터 묘사에서 뛰어나다고 평가합니다. 피부 질감과 움직임의 부드러움이 우수합니다. 테스트 샘플의 60% 이상이 인물이나 토킹헤드 클립이었다는 점이 이 모델을 1위로 끌어올린 요인이었습니다.
그러나 비판도 존재합니다. 유출된 영상들에서는 부자연스러운 잔물결, 빠르게 움직이는 피사체에서의 줄무늬 아티팩트, 대형 화면에서의 이미지 품질 저하 등이 지적되었습니다.
오픈 소스 및 액세스 계획
4월 9일, HappyHorse‑1.0은 완전 오픈 소스화한다고 발표했습니다. GitHub 저장소는 공개되었으며, 가중치는 완전히 개방되었고 상업적 제한도 없습니다.
공식 웹사이트에서는 텍스트-비디오 및 이미지-비디오 온라인 데모를 제공합니다. 알리바바 ATH에 따르면 API는 4월 30일에 일반 공개될 예정입니다.
단, 주의할 점은 공식 팀에 따르면 온라인에서 유포되는 대부분의 "공식 웹사이트"는 가짜라는 것입니다. 진짜 사이트는 아직 완전히 운영되지 않고 있습니다.
시장 영향 및 의의
HappyHorse는 OpenAI가 Sora 개발을 중단한 지 2주 만에 등장했습니다. 그 움직임은 AI 비디오 분야의 정체 신호로 보였지만, 중국 모델이 바통을 이어받았습니다.
시장은 빠르게 반응했습니다. 알리바바의 주가는 확인 후 7% 이상 급등했으며 상승세를 이어갔습니다. 4월 10일 종가 기준으로 3% 이상 상승한 HK$126.6을 기록했습니다.
전략적 차원에서 HappyHorse는 ATH가 최고 수준의 멀티모달 모델을 구축할 수 있는 제2의 팀을 보유하고 있음을 보여줍니다. 이 팀은 비즈니스 배경을 가지고 있으며 사용자의 요구와 상업적 시나리오를 이해하고 있습니다. 이를 통해 통이 연구소(기초 연구 중심)와 혁신 부서(실제 비즈니스 과제로부터 애플리케이션 구축)라는 이중 엔진 구조가 만들어졌습니다.
타임라인을 살펴보겠습니다. 린 준양(Lin Junyang)이 3월 초 사임했고, 3월 16일 ATH가 설립되었습니다. 4월 2일에는 Qwen 3.6 Plus가 OpenRouter의 글로벌 호출량 1위를 차지했으며, 4월 8일에는 HappyHorse가 Artificial Analysis 리스트 정상에 올랐습니다. 불과 한 달 만에 알리바바는 언어 모델과 비디오 모델 모두에서 강력한 성과를 냈습니다.
팀 배경: 장 디(Zhang Di)와 알리바바 ATH
HappyHorse 뒤에는 거물급 인사 장 디(Zhang Di)가 있습니다.
그는 원래 콰이쇼우(Kuaishou)의 부사장이었으며 Kling AI의 기술 리더를 역임했습니다. 그는 "Kling의 아버지"로 알려져 있습니다. 그는 2025년 11월 콰이쇼우를 떠나 알리바바의 "Future Life Lab" 책임자로 부임하여 정 보(Zheng Bo) 최고 과학자에게 직접 보고하게 되었습니다.
5개월 후, 그의 팀은 HappyHorse‑1.0을 구축하여 Kling과 바이트댄스의 Seedance 2.0을 제압했습니다.
이 팀은 당초 타오바오의 Future Life Lab 소속이었으나, 알리바바의 최근 조직 개편에 따라 ATH 비즈니스 그룹의 AI 혁신 부서로 이동했습니다.
ATH는 3월 16일 우 용밍(Wu Yongming) CEO가 직접 설립하고 이끄는 "Alibaba Token Hub"를 의미합니다. 그 사명은 "토큰의 생성, 제공 및 적용"이며, 통이 연구소, MaaS 비즈니스 라인, 첸원(Qianwen) 부서, 우쿵(Wukong) 부서 및 AI 혁신 부서를 통합합니다.
FAQ
HappyHorse를 로컬에서 실행하려면 어떤 GPU가 필요한가요?
이 모델은 150억 개의 파라미터를 가지고 있어 결코 작지 않습니다. 단일 H100 환경에서 5초 분량의 1080p 비디오를 생성하는 데 약 38초가 소요됩니다. RTX 4090(24GB VRAM)과 같은 소비자용 GPU에서는 양자화나 오프로딩이 필요할 것입니다. FP16 추론 시 24GB를 초과할 가능성이 높습니다. 일부 사용자는 4비트 양자화로 성공했다고 보고했지만 품질이 저하됩니다. 본격적인 사용을 위해서는 40GB 이상의 VRAM을 갖춘 클라우드 GPU를 권장합니다. 아니면 4월 30일 API 출시를 기다리는 것이 현명합니다.
나만의 데이터로 HappyHorse를 파인튜닝할 수 있나요?
네, 라이선스 하에 가능합니다. 상업적 사용 제한은 없습니다. 그러나 150억 파라미터의 비디오 모델을 파인튜닝하는 것은 쉽지 않습니다. H100 또는 A100 클러스터, 대규모 비디오-오디오 쌍 데이터셋, 상당한 엔지니어링 자원이 필요합니다. GitHub 저장소에는 현재 파인튜닝 스크립트가 포함되어 있지 않으며 추론만 지원합니다. 팀은 향후 학습 코드를 공개할 것을 암시했지만 구체적인 날짜는 정해지지 않았습니다.
Discord나 WeChat 커뮤니티 그룹이 있나요?
있지만 비공식적입니다. 여러 AI 커뮤니티에서 Discord와 WeChat에 스레드를 개설했습니다. 공식 팀은 아직 공식 커뮤니티 채널을 열지 않았습니다. 그룹에 가입할 경우 가짜 링크와 피싱 사기를 주의하세요. GitHub 저장소와 알리바바 ATH의 공식 발표를 통해 최신 정보를 확인하는 것이 가장 좋습니다.
이 모델을 Hugging Face에서 사용할 수 있나요?
현재로서는 아닙니다. 팀은 Hugging Face 출시를 위해 노력 중이라고 밝혔지만 아직 완료되지 않았습니다. 현재 가중치는 GitHub에만 있습니다. 커뮤니티 멤버들이 변환된 체크포인트를 Hugging Face에 업로드하기 시작했지만, 이는 비공식적입니다. 안전을 위해 공식 Hugging Face 페이지가 나올 때까지 GitHub 소스를 사용하세요.






