MiniMax M3가 출시되었습니다. 핵심만 요약하자면, 네이티브 이미지 및 비디오 입력이 가능하고, 100만 토큰의 컨텍스트를 저렴하게 유지하며, 리셋 없이 긴 코딩 및 에이전트 루프를 실행할 수 있는 오픈 웨이트 모델이 필요하다면 바로 이 모델을 사용하세요. 이것이 M3의 주요 활용 사례이며, 밤사이 자율적으로 작업을 수행할 에이전트가 있다면 테스트해보시길 적극 권장합니다! M3는 지금 바로 Atlas Cloud에서 이용 가능합니다.
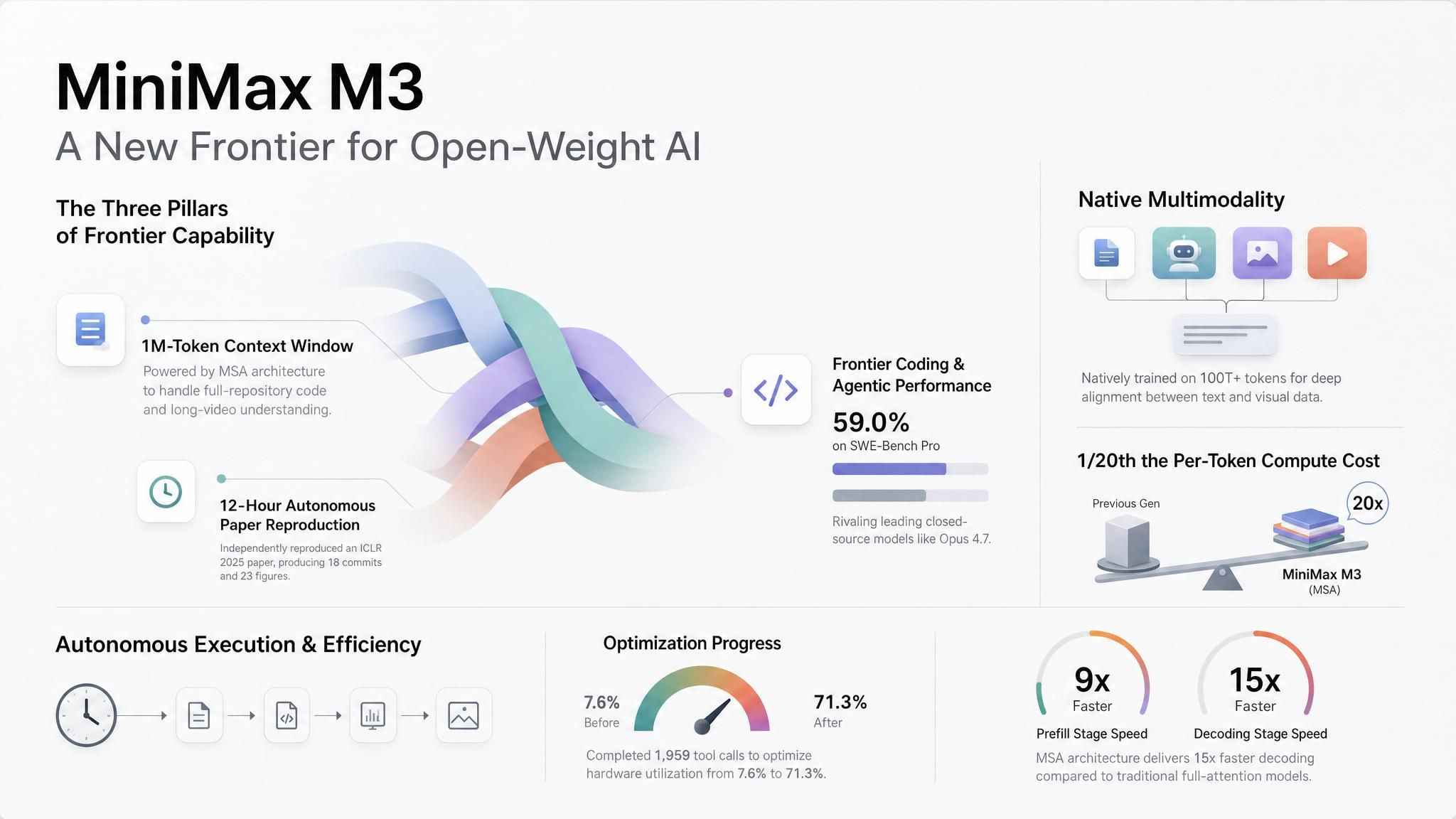
장기 실행 에이전트를 운영하지 않더라도, MiniMax가 해당 목표를 달성하기 위해 선택한 방향성은 주목할 만합니다. 그들은 희소 어텐션 아키텍처(MiniMax Sparse Attention, MSA)를 통해 100만 컨텍스트를 합리적인 비용으로 유지했습니다. 이는 전체 컨텍스트 사용 시 토큰당 연산량을 이전 세대의 약 1/20 수준으로 절감한 것으로, 가장 이질적인 기술이 아닌 현재의 서빙 스택에서 구동 가능한 가장 경제적인 경로를 선택한 결과입니다. 우리는 모든 주요 제공업체가 희소 또는 압축 어텐션을 통해 저렴한 긴 컨텍스트를 제공하는 것을 기본 방향으로 삼을 것으로 예상합니다. 이렇게 되면 100만 토큰 윈도우는 차별화 요소가 아닌 기본 사양이 되며, 실제 경쟁은 특정 모델에 올인하는 것이 아니라 모델 간 라우팅을 얼마나 잘 최적화하느냐의 영역으로 넘어가게 될 것입니다.
MiniMax는 2026년 6월 1일에 M3를 발표했습니다. API는 현재 이용 가능하며, MiniMax는 발표 후 약 10일 이내에 기술 보고서와 가중치(weights)를 공개할 예정이라고 밝혔습니다.
현재 다른 최첨단(frontier) 모델을 사용 중이라면
작업에 더 큰 작업 세트, 시각적 컨텍스트 또는 현재 기본 모델보다 더 긴 에이전트 루프가 필요할 때 M3는 테스트해볼 가치가 충분합니다. 가장 중요한 것은 마지막 열입니다. 즉, M3가 기존 모델 대비 실질적으로 어떤 이점을 제공하는지를 확인해야 합니다.
| 현재 사용 중인 모델 | 작업 내용 | M3의 추가적인 이점 |
|---|---|---|
| GPT-5.5 또는 GPT-5.5 Pro | 에이전트형 코딩, 컴퓨터 사용, 연구, 데이터 분석 및 지식 업무 자동화 | 네이티브 비디오 입력 및 발표된 오픈 웨이트 경로 제공 — 추후 자체 호스팅이 가능한 차별화된 비용 구조의 두 번째 에이전트 경로. (GPT-5.5는 이미 이미지 비전을 지원하므로, 이미지 지원보다는 비디오 및 경제성을 테스트하세요.) |
| Claude Opus 4.8 | 장기 실행 코딩 에이전트, 검색 중심의 지식 업무, 도구 사용 | 전체 리포지토리 코딩 및 작업 완료당 비용을 A/B 테스트할 수 있는 저비용 오픈 웨이트 대안. Opus 4.8은 이미 1M 컨텍스트 윈도우와 비전을 제공하므로, 진정한 테스트 항목은 윈도우 크기가 아닌 가격, 비디오 입력 및 작업 경제성입니다. |
| Qwen3.7-Plus (멀티모달) | 비전 및 GUI 에이전트, 스크린샷-투-코드, 브라우저 및 데스크톱 자동화 | 더 강력한 코딩/에이전트 포지셔닝과 오픈 웨이트 경로를 갖춘 동급 멀티모달 기능. (Qwen3.7-Plus는 독점적이며 API 전용입니다.) |
| Qwen3.7-Max (텍스트 전용 플래그십) | 텍스트 추론, 장기 호라이즌 에이전트, 사무 자동화 | 동일 컨텍스트 내 네이티브 이미지 및 비디오 입력. Qwen3.7-Max는 텍스트 전용이므로 비전 기능 사용 시 Plus로 전환해야 합니다. |
| DeepSeek-V4-Pro 또는 DeepSeek-V4-Flash | 비용 효율적인 추론, 코딩, 도구 호출 및 긴 컨텍스트 API 워크로드 | 긴 컨텍스트 위에서 네이티브 멀티모달리티(이미지 및 비디오) 제공. DeepSeek-V4는 텍스트 전용이므로 시각적 신호가 포함된 워크로드에서는 M3가 대안입니다. |
실제 테스트 방법은 간단합니다. 다음과 같은 작업을 수행하려는 경우 M3를 시도해보세요.
- 리포지토리, 작업 이력, 로그 및 현재 계획을 하나의 작업 컨텍스트에 모두 유지할 때
- 에이전트가 대화 초기화 없이 수십 번의 도구 호출을 지속해야 할 때
- 코드, 텍스트, 스크린샷, 차트, PDF, 비디오 프레임을 한 번에 추론해야 할 때
- 텍스트 모델, 비전 모델, 별도의 검색 레이어 간의 전환을 줄이고 싶을 때
- 백만 토큰당 가격이 아닌 작업 완료당 긴 컨텍스트 비용을 비교하고 싶을 때
출시 차트가 좋다고 해서 무작정 전환하지 마세요. 현재의 라우팅 스택이 놓치거나, 잘라내거나, 과도한 비용을 지불하거나, 너무 많은 모델로 분할하는 작업을 M3가 성공적으로 완수할 때 전환하십시오.
M3가 유용한 경우
에이전트가 충분히 작업할 공간 제공. MiniMax의 출시 예제는 일반적인 챗봇 데모 패턴을 뛰어넘습니다. 한 테스트에서 M3는 거의 12시간 동안 실행된 후 ICLR 2025 우수 논문의 핵심 실험을 재현했습니다. 이 과정에서 18개의 커밋과 23개의 실험 피겨를 생성했습니다. 또 다른 사례에서는 FP8 GEMM CUDA 커널에서 약 24시간 동안 작동하며 147개의 벤치마크 제출과 1,959회의 도구 호출을 수행했고, 하드웨어 활용률을 7.6%에서 71.3%로 끌어올렸습니다.
이 예제들이 첫 프롬프트부터 하루 종일 작동하는 에이전트를 보장한다고 이해해서는 안 됩니다. 하지만 모델이 계획을 세우고, 도구를 실행하고, 결과를 검사하고, 수정하고, 초기 시도가 실패한 후에도 계속 이어가야 하는 워크플로우에 M3가 우선순위 후보가 되어야 하는 이유는 충분히 보여줍니다.
리포지토리 및 문서 규모의 컨텍스트. M3는 API를 통해 최대 100만 토큰을 지원하며, MiniMax는 512K를 보장된 최소값으로 명시합니다. 100만 토큰 컨텍스트 길이에서 MiniMax는 이전 세대보다 1/20 수준의 토큰당 연산량을 기록하며, 프리필(prefill)은 9배 이상, 디코딩은 15배 이상 빠릅니다.
이는 제품 설계 방식을 바꿉니다. 코딩 에이전트는 더 많은 리포지토리를 볼 수 있고, 연구 보조 도구는 더 긴 증거 이력을 추적할 수 있습니다. 검색(Retrieval)도 여전히 중요하지만, 모델이 문제의 아주 작은 부분부터 시작할 필요는 없어졌습니다.
동일 요청 내 시각적 컨텍스트. MiniMax는 M3를 처음부터 멀티모달 데이터로 학습시켰습니다. 모델은 이미지와 비디오 입력을 허용하며, 하나의 컨텍스트 내에서 텍스트, 이미지, 비디오가 혼합된 형태를 처리할 수 있습니다.
이는 모델 간 전환을 줄여줍니다. 지원 워크플로우에서 사용자의 메시지를 읽고 스크린샷을 즉시 검사할 수 있습니다. 연구 워크플로우에서는 논문 내 차트를 추론할 수 있습니다. 컴퓨터 사용 에이전트는 화면을 보고 시각적 정보를 별도의 모델로 전송할 필요 없이 바로 다음 작업을 결정할 수 있습니다.
호스팅 액세스 즉시 제공, 가중치 공개 예정. MiniMax는 M3를 오픈 웨이트 릴리스로 취급하고 있지만, 첫 번째 출시 경로는 호스팅된 API 액세스입니다. 이를 통해 팀들은 유용한 시퀀스를 따를 수 있습니다. 즉, 지금 호스팅된 모델을 테스트한 후, 향후 가중치가 공개될 때 개인 배포, 파인튜닝 또는 내부 평가에 적합한지 결정하는 것입니다.
명확한 가격 체계. MiniMax는 512K 입력 토큰 이하의 API 호출에는 표준 요금을 적용한다고 밝힙니다. 512K를 초과하는 긴 컨텍스트 요금은 주로 전체 리포지토리, 전체 문서 또는 긴 비디오 워크로드를 실행하는 팀을 대상으로 합니다. M3는 동일 가격으로 사고(thinking) 토글을 지원하여, 팀들이 더 어려운 에이전트 작업을 위해 추론 모드를 사용하거나 지연 시간에 민감한 작업에는 더 빠른 모드를 사용할 수 있게 합니다.
운영 비용 구조
Atlas Cloud에서 MiniMax M3는 입력 토큰 100만 개당 USD0.30, 출력 토큰 100만 개당 USD1.20으로 책정되었습니다. Claude Opus 4.7은 입력 USD5/출력 USD25이며, GPT-5.5는 입력 USD5/출력 USD30입니다.
이를 비교하면 M3는 다음과 같습니다:
- 입력 비용: Opus 4.7 및 GPT-5.5 대비 94% 저렴
- 출력 비용: Opus 4.7 대비 95.2% 저렴
- 출력 비용: GPT-5.5 대비 96% 저렴
토큰 가격은 워크로드의 성격에 대입한 후에만 중요합니다. 컨텍스트 내에 대규모 리포지토리가 있는 코딩 에이전트는 입력 비용이 가장 큰 비중을 차지합니다. 긴 설명이 포함된 연구 또는 초안 작성 워크플로우는 출력 비용이 더 많이 듭니다. 멀티모달 GUI 에이전트는 시각적 컨텍스트에 대해서도 비용을 지불하며, 토큰 변환은 제공업체에 따라 다릅니다.
아래 표는 벤치마크가 아닌 요금표 비교입니다. USD 기준이며, 캐시 적중, 배치 할인, 지역별 프리미엄, 도구 호출 수수료, 재시도는 포함되지 않았습니다. GPT-5.5의 경우 OpenAI 정책에 따라 272K 입력 토큰 초과 시 전체 세션에 대해 입력 2배, 출력 1.5배의 요금이 적용되므로 긴 컨텍스트 예제에는 해당 높은 유효 요금을 사용했습니다.
| 모델 | 적용 요금 | 100K 입력 + 5K 출력 | 500K 입력 + 20K 출력 | 비용 분석 |
|---|---|---|---|---|
| MiniMax M3 on Atlas Cloud | $0.30 / $1.20 | $0.04 | $0.17 | 저비용 멀티모달 경로. DeepSeek Flash보다 비싸지만, 폐쇄형 최첨단 모델 요금보다 훨씬 낮음. |
| DeepSeek V4 Flash | $0.14 / $0.28 | $0.02 | $0.08 | 텍스트 전용 대용량 작업에 가장 저렴한 경로. 시각적 입력이 없는 작업에 적합. |
| DeepSeek V4 Pro | $0.435 / $0.87 | $0.05 | $0.23 | 순수 토큰 비용은 M3와 비슷하지만 텍스트 전용. 시각적 컨텍스트 없는 추론/코딩에 적합. |
| Qwen3.7-Plus | 256K까지 $0.40 / $1.60; 초과 시 $1.20 / $4.80 | $0.05 | $0.70 | 단기 멀티모달 호출 시 경쟁력 있음. 256K 초과 시 경제성이 변화함. |
| Qwen3.7-Max | $2.50 / $7.50 | $0.29 | $1.40 | GPT나 Claude보다 저렴하지만, 작업 점유율을 확보하지 못하면 대량 사용은 어려움. |
| Claude Opus 4.8 | $5 / $25 | $0.63 | $3.00 | 고난도 코딩, 도구 사용, 긴 컨텍스트 신뢰성을 위한 프리미엄 경로. |
| GPT-5.5 | 표준 $5 / $30; 272K 입력 초과 시 $10 / $45 | $0.65 | $5.90 | 모델의 도구 사용, 컴퓨터 사용 성능이 비용을 상쇄할 때 사용. |
| GPT-5.5 Pro | $30 / $180 | $3.90 | $18.60 | 최상위 난도 작업용. 예산 클래스가 완전히 다름. |
비용 요약: M3가 이 리스트에서 가장 저렴한 텍스트 모델은 아닙니다. 텍스트 전용의 대용량 워크로드라면 DeepSeek V4 Flash가 여전히 유리합니다. M3의 비용 전략은 다릅니다. 네이티브 이미지/비디오 입력, 긴 작업 컨텍스트, 에이전트형 코딩을 DeepSeek V4 Pro와 유사한, 그리고 GPT-5.5, GPT-5.5 Pro, Claude Opus 4.8보다 훨씬 저렴한 가격대에 제공합니다.
500K 입력, 20K 출력의 에이전트 작업에서 M3는 Claude Opus 4.8보다 약 17배, GPT-5.5의 긴 컨텍스트 배수를 적용할 경우 약 34배 더 저렴합니다. Qwen3.7-Plus보다 약 4배, Qwen3.7-Max보다 약 8배 저렴합니다. DeepSeek와의 비교는 모달리티에 따라 다릅니다. DeepSeek V4 Flash가 더 저렴하지만, 스크린샷, 차트, UI 상태 또는 비디오 프레임이 포함된 작업이라면 M3는 별도의 비전 모델로 라우팅하는 단계를 줄여 비용을 절감할 수 있습니다.
월간 규모로 보면 차이는 더욱 명확합니다. 입력 토큰 1,000만 개, 출력 토큰 100만 개의 워크로드는 M3에서 약 $4.20, DeepSeek V4 Flash는 $1.68, DeepSeek V4 Pro는 $5.22, Claude Opus 4.8은 $75, GPT-5.5는 $80, GPT-5.5 Pro는 $480입니다. Qwen3.7-Plus는 256K 경계에 따라 $5.60~$16.80 사이, Qwen3.7-Max는 약 $32.50입니다.
우리의 권장 사항: 비싼 모델들은 그 값을 하는 경우에만 사용하십시오. GPT-5.5나 Opus 4.8이 한 번의 실행으로 고난도 작업을 끝내는데 M3가 3번의 재시도와 사람의 개입이 필요하다면, 저렴한 모델이 더 비싼 결과를 초래한 셈입니다. 긴 컨텍스트의 멀티모달 분석, 리포지토리 규모의 코딩 분류, 스크린샷이 포함된 지원 티켓 자동화 등 M3가 품질 기준을 만족하는 작업이라면, 단순한 출시주기용 흥미거리가 아닌 실질적인 라우팅 후보로 활용하십시오.
벤치마크는 벤더의 데이터로 읽을 것
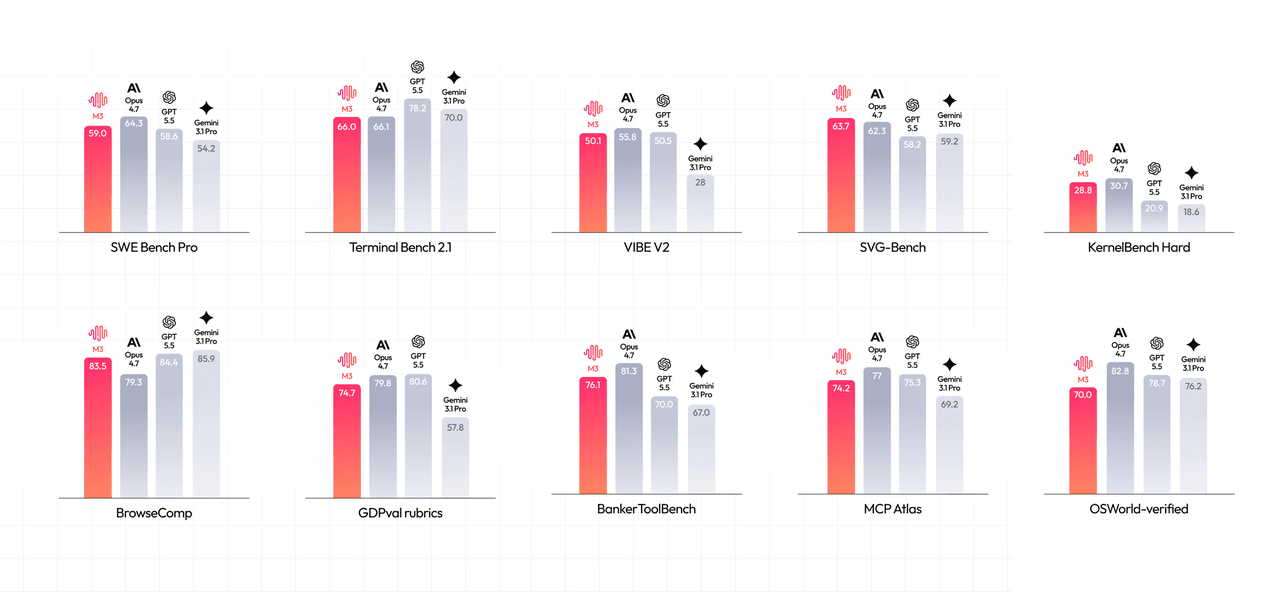
MiniMax는 코딩 및 에이전트 작업 전반에서 강력한 점수를 보고합니다:
- SWE-Bench Pro: 59.0%
- Terminal-Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- KernelBench Hard: 28.8%
- MCP-Atlas (제3자 MCP 도구 사용 벤치마크): 74.2%
- BrowseComp: 83.5 (Claude Opus 4.7의 79.3 대비)
마지막 항목에 대한 참고: MiniMax는 M3를 Opus 4.7과 비교했지만, Opus 4.8은 M3 출시 4일 전인 5월 28일에 출시되었습니다. 출시 첫날부터 비교 대상이 이미 한 버전 뒤처져 있었다는 점은 작지만, 뒤에서 설명할 중요한 시사점을 예고합니다.
12시간 내에 4개의 기반 모델을 합성, 학습, 평가 및 반복하도록 요구하는 PostTrainBench에서 MiniMax는 M3의 점수를 0.37(모델 페이지의 37.1점)로 보고합니다. 이는 Opus 4.7(0.42)과 GPT-5.5(0.39)보다 낮지만, 나머지 보고된 필드보다는 앞섭니다.
이 점수들은 분류(triage)에는 유용하지만, 생산 환경 도입 결정을 내리기에는 부족합니다. MiniMax는 자사 인프라에서 테스트를 수행했고, 여러 평가가 특정 스캐폴딩(scaffolding)을 사용했습니다. 팀이 영업용 자료나 아키텍처 결정에 이 점수를 사용하기 전에, 반드시 자사의 코드, 문서, 프롬프트, 지연 시간 목표 및 예산에 맞춰 직접 작업을 재실행해야 합니다.
M3를 기존 최첨단 모델과 비교 평가하는 방법
M3를 기본값이 아닌 평가 대상으로 사용하십시오. 100만 토큰 윈도우는 관련 없는 파일, 오래된 로그, 사용자가 보낸 모든 메시지로 채워버리면 잘못된 아키텍처를 숨길 수 있습니다.
GPT-5.5, Claude Opus 4.8, Qwen3.7-Plus/Max, DeepSeek-V4-Pro/Flash, 그리고 M3를 대상으로 동일한 테스트 셋을 실행하십시오. 그런 다음 제공업체의 명성이 아닌 작업별 결과로 비교하십시오.
6가지 테스트로 시작하세요:
- 전체 리포지토리 코딩: 각 모델에 동일한 이슈, 리포지토리 슬라이스, 도구 액세스, 시간 제한을 제공하십시오. 패치 품질, 테스트 통과율, Diff 크기, 불필요한 편집 여부를 점수화하세요.
- 긴 컨텍스트 검색: 컨텍스트의 시작, 중간, 끝에 관련 세부 정보를 배치하고 유사한 방해 요소를 추가하십시오. 각 모델이 단순히 일치하는 구문을 찾는 것이 아니라 올바른 인스턴스를 정확히 검색하는지 확인하세요.
- 도구 루프 내구성: 30, 60, 100회 이상의 도구 호출이 필요한 작업을 실행하십시오. 각 모델이 안정적인 계획을 유지하는지, 반복하는지, 초기 제약 조건을 잃어버리는지, 작업 완료 전에 중단되는지 관찰하세요.
- 비전 에이전트 작업: 멀티모달 모델에 지원 티켓과 스크린샷, 논문과 차트, 제품 사양과 UI 캡처를 제공하세요. 텍스트 전용이거나 비전 성능이 낮은 모델의 경우 별도 비전 모델로의 추가적인 전환 비용을 측정하세요.
- 실제 컨텍스트에서의 지연 시간: 128K, 512K, 1M 입력 토큰에서 첫 번째 토큰 생성 시간(TTFT)과 총 완료 시간을 비교하세요. 지연 시간 데이터 없는 100만 윈도우 주장은 신뢰하지 마세요.
- 작업 완료당 비용: 입력 토큰, 출력 토큰, 재시도, 도구 호출, 캐시 적중, 지연 시간, 인간 수정 횟수를 측정하세요. 더 저렴한 모델이라도 재시도가 3번 필요하면 결과적으로는 더 비용이 많이 들 수 있습니다.
대부분의 팀이 모델 선택에서 실수하는 지점입니다. 그들은 누가 최고의 출시 벤치마크를 가졌는지만 묻습니다. 생산 환경의 질문은 더 좁고 명확해야 합니다. 어떤 모델이 우리 제품이 허용하는 품질, 지연 시간, 비용 내에서 이 워크플로우를 완수하는가?
MSA가 긴 컨텍스트를 유지하는 원리
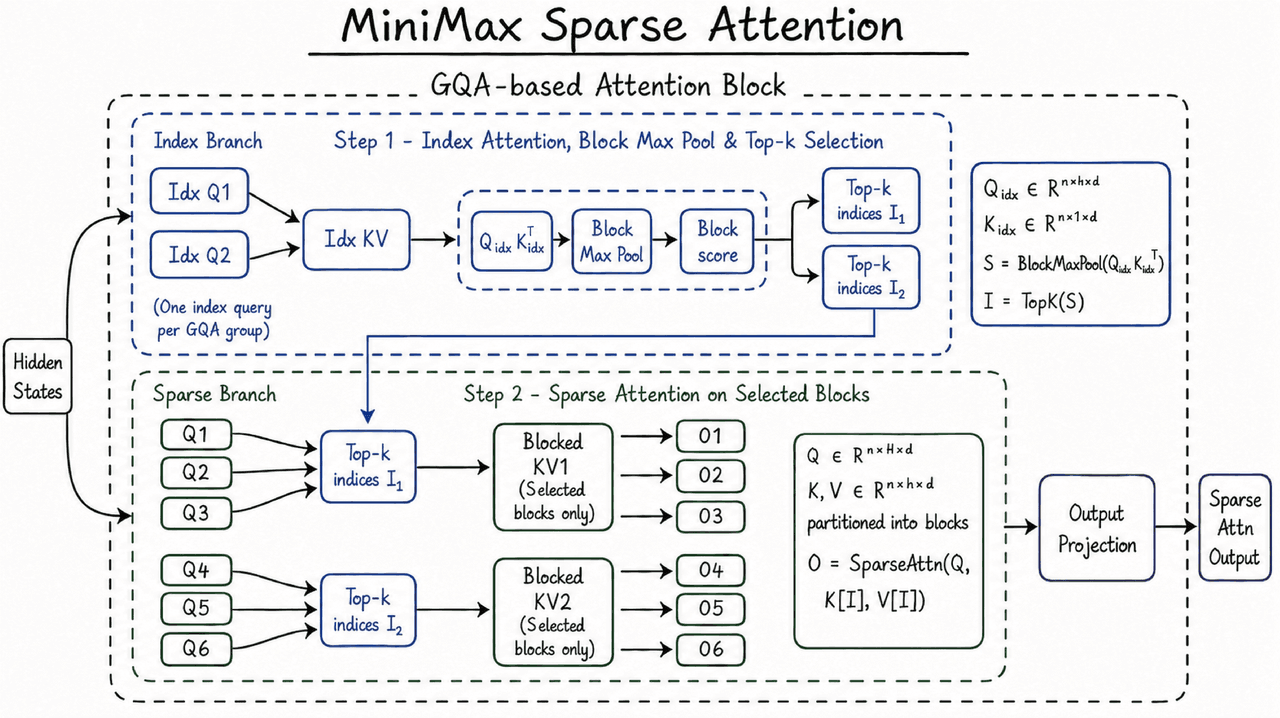
M3의 컨텍스트 윈도우는 MiniMax Sparse Attention(MSA)에 의존합니다.
전체 어텐션(full attention)은 각 토큰이 다른 모든 토큰에 주목하게 합니다. 시퀀스가 길어질수록 연산량은 길이의 제곱으로 증가합니다. 희소 어텐션은 선택 단계를 추가한 후 이전 컨텍스트 중 가장 중요한 부분에 대해서만 어텐션을 실행합니다.
MiniMax는 MSA가 KV 캐시를 블록 단위로 분할하고 블록 수준에서 선택한다고 설명합니다. KV 캐시는 이전 토큰의 키와 값 벡터를 저장하며, 긴 컨텍스트 추론에서 메모리 트래픽의 상당 부분을 차지합니다. 또한 MiniMax는 "KV outer gather Q"라는 연산자 설계를 설명합니다. KV 블록이 외부 루프가 되고, 블록에 도달하는 쿼리들이 그 블록으로 모이며, 각 블록을 한 번만 읽고 메모리 액세스를 연속적으로 유지하는 방식입니다.
MiniMax의 발표에 따르면, 이 설계는 M3의 헤드 구성 하에서 오픈 소스인 Flash-Sparse-Attention이나 flash-moba보다 4배 이상 빠르게 실행됩니다. 또한 MSA는 대다수의 제거 연구(ablations)에서 전체 어텐션과 대등한 성능을 보였습니다.
엔지니어링적 주장이 중요한 이유는 100만 토큰 윈도우라도 팀이 사용할 경제적 여력이 없다면 가치가 없기 때문입니다. MSA 덕분에 MiniMax는 긴 컨텍스트가 일회성 데모 모드가 아닌 M3의 정상적인 운영 모델의 일부라고 주장할 수 있는 것입니다. 이는 유일한 사례도 아닙니다. DeepSeek의 V4도 같은 이유로 압축 희소 어텐션과 고압축 어텐션을 혼합하여 사용합니다. 저렴한 긴 컨텍스트는 이제 아키텍처의 표준이 되어가고 있습니다.
더 큰 트렌드: 모델 출시는 라우팅 이벤트가 되고 있다
M3는 고립된 릴리스가 아닙니다. 시장 전반에 형성되고 있는 패턴의 일부입니다.
가장 분명한 트렌드는 일정입니다. 약 6주 동안 4개의 100만 컨텍스트 모델이 출시되었습니다:
- DeepSeek V4-Pro 및 V4-Flash — 4월 24일, 오픈 웨이트, 1M 컨텍스트, 사고/비사고 모드
- Qwen3.7-Max — 5월 20일, 텍스트 전용 추론 플래그십, 1M 컨텍스트 (멀티모달 Qwen3.7-Plus는 6월 초 출시)
- Claude Opus 4.8 — 5월 28일, Opus 제품군에 1M 컨텍스트 윈도우 적용
- MiniMax M3 — 6월 1일, 100만 컨텍스트 및 네이티브 멀티모달리티, 오픈 웨이트 경로
백만 토큰 윈도우는 한 분기 만에 차별화 요소에서 기본 사양이 되었습니다. 희소 어텐션, 사고 토글, 에이전트 벤치마크, 계층형 장기 컨텍스트 요금제도 마찬가지입니다. 모델 페이지들은 계속해서 동일한 주요 기능으로 수렴할 것입니다.
속도는 마케팅을 앞서갑니다. MiniMax의 M3 벤치마크는 Opus 4.7을 대상으로 하지만, Opus 4.8은 4일 먼저 출시되었습니다. 지난주에 벤치마크했던 모델은 경쟁자가 이번 주에 운영 중인 모델과 다를 수 있습니다. 이것이 바로 라우팅 이벤트의 세상입니다.
그렇다고 M3가 무의미한 것은 아니지만, 개발자가 무엇을 최적화해야 하는지는 바뀝니다.
모델의 우위는 그 주위의 통합 작업보다 빨리 쇠퇴할 것입니다. 팀이 특정 제공업체를 에이전트 스택에 하드코딩한다면, 모든 주요 릴리스가 마이그레이션 프로젝트가 될 것입니다. 작업, 가격, 지연 시간, 모달리티 및 평가 결과별로 라우팅한다면, 모든 주요 릴리스는 라우팅 업데이트가 될 뿐입니다.
승자는 하나의 모델을 선택하고 1년 동안 방어하는 팀이 아닙니다. 지금 M3를 테스트하고, 내일 GPT-5.5, Claude Opus 4.8, Qwen3.7, DeepSeek-V4와 비교하여 수치가 가리키는 방향으로 트래픽을 이동시킬 수 있는 팀이 승리합니다.
타사가 복제할 수 있는 것과 없는 것
제공업체는 표면적인 것은 먼저 복제할 수 있습니다:
- 더 긴 컨텍스트 윈도우
- 희소 어텐션 변형
- 사고 모드 On/Off
- 코딩 에이전트 벤치마크 페이지
- 멀티모달 출시 데모
- 오픈 웨이트 또는 그에 준하는 메시징
더 어려운 부분은 시간이 걸립니다:
- 실제 동시성 환경에서의 안정적인 긴 컨텍스트 서빙
- 특히 방해 요소가 있을 때의 컨텍스트 깊이 품질
- 많은 도구 호출 후의 에이전트 신뢰성
- 텍스트, 이미지, 차트, 비디오 전반의 멀티모달 정렬
- 고객이 전체 윈도우를 사용할 때도 유지되는 가격 체계
- 생산 환경 팀이 신뢰할 수 있는 명확한 모델 ID, 버전 관리 및 폴백(fallback)
이 격차에 개발자들은 평가 시간을 할애해야 합니다. 타 제공업체가 100만 윈도우를 광고할 수 있는지 여부만 묻지 마십시오. 모델이 750,000번째 토큰에 숨겨진 명령을 계속 따르는지, 유사한 두 개의 스크린샷을 혼동 없이 비교할 수 있는지, 지연 시간이 허용 범위 내에 있는지, 실제 사용자 트래픽에서도 경제성이 유지되는지 물어야 합니다.
Atlas Cloud를 사용해야 하는 이유
Atlas Cloud는 LLM, 이미지, 비디오, 오디오 워크로드 전반에 걸쳐 300개 이상의 모델을 하나의 API 키로 제공합니다. 모델 릴리스가 동일한 특징으로 수렴될수록 이 점은 더욱 중요해집니다.
스택에 이미 있는 모델들과 M3를 테스트하고, 성능이 좋은 곳으로 트래픽을 라우팅하며, 새로운 릴리스가 등장해도 통합 인터페이스를 안정적으로 유지할 수 있습니다. 컴퓨터 사용 작업에서 우위를 점하는 GPT-5.5, 장기 실행 코딩 에이전트에서 강력한 Claude Opus 4.8, 멀티모달 GUI 에이전트에 최적인 Qwen3.7-Plus, 가격 대비 성능이 뛰어난 DeepSeek-V4를 각각 활용하고, 긴 컨텍스트와 네이티브 멀티모달리티가 성과를 바꾸는 곳에 M3를 추가하세요.
긴 컨텍스트와 멀티모달리티가 제값을 하는 곳에 M3를 사용하십시오. 다른 모델이 여전히 앞서는 곳에는 해당 모델을 유지하세요. 출시 주간의 과대광고가 아닌, 평가에 근거하여 전환하십시오.
[CTA - builder intent: Run M3 on Atlas Cloud -> atlascloud.ai/models | Get an API key -> console.atlascloud.ai]






