RSpqXx0wq8Q
2026년 5월 19일, 구글 I/O에서 DeepMind는 Gemini Omni를 발표했습니다. 같은 날, Gemini Omni 프롬프트 가이드가 DeepMind 문서 사이트의 Omni Flash 모델 카드와 API 노트 사이에 게시되었습니다. 대부분의 사람들은 키노트 데모를 보았고, 이 문서는 거의 읽히지 않았습니다.
핵심부터 살펴보겠습니다. Gemini Omni는 DeepMind의 새로운 멀티모달 생성 모델입니다. 첫 번째 제품인 Gemini Omni Flash는 텍스트, 이미지, 오디오 또는 비디오 입력의 조합을 통해 최대 10초 분량의 영상을 생성합니다. 모든 출력물에는 SynthID 워터마크가 포함됩니다. AI Plus, AI Pro, AI Ultra 구독자는 즉시 사용할 수 있으며, YouTube Shorts 및 YouTube Create 앱 사용자는 이번 출시 주간부터 무료로 액세스할 수 있습니다(Gagadget 보도). 구글에 따르면 API 액세스는 "수주 내" 제공될 예정입니다.
다시 프롬프트 가이드로 돌아가 보겠습니다. 구글 DeepMind의 프롬프트 가이드는 "세계 이해(World understanding)" 섹션에서 이러한 변화를 직접적으로 설명합니다.
Veo의 경우 최상의 결과를 얻으려면 정밀한 지침을 공유해야 했습니다. 하지만 Gemini Omni에서는 프롬프트에 그렇게 구애받지 않아도 됩니다. 대신 Omni에게 만들고 싶은 것을 말하기만 하면 모델의 추론 능력과 세계에 대한 지식이 세부 사항을 현실로 구현하는 과정을 지켜볼 수 있습니다.
요약하자면: 더 짧게 쓰라는 것입니다.
ByteDance와 Kuaishou가 각자의 비디오 모델을 위해 발행한 프롬프트 가이드와 비교해 보세요. 틀은 다르지만 지향점은 같습니다.
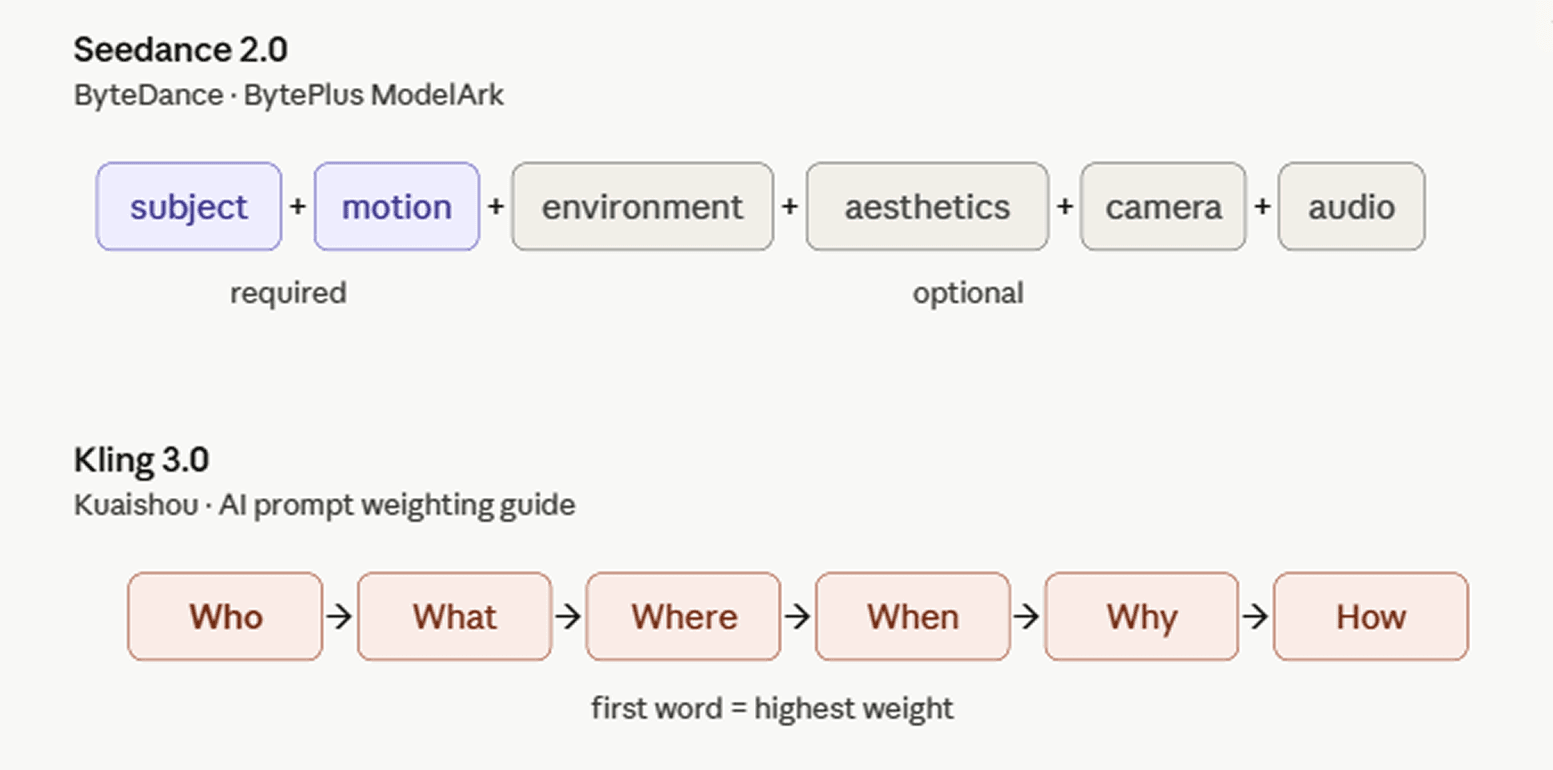
ByteDance는 자사의 글로벌 개발자 플랫폼에서 BytePlus ModelArk 프롬프트 가이드를 통해 Seedance 2.0을 문서화하고 있습니다. 권장 구조는 피사체 + 동작 (+ 환경 + 미학 + 카메라 움직임/컷 + 오디오)입니다. 모든 구성 요소가 필수는 아니며, 장면에 맞는 요소를 선택하면 됩니다.
Kuaishou의 AI 프롬프트 가중치(Weighting) 가이드는 5W1H 공식(누가, 무엇을, 어디서, 언제, 왜, 어떻게)을 통해 이를 설명합니다. Kling 3.0에서는 단어 위치가 가중치를 결정하기 때문에, 가장 먼저 나오는 단어가 가장 많은 계산적 관심을 받습니다. 따라서 '누가(주체)'가 일반적으로 가장 높은 우선순위를 가지며 프롬프트를 주도합니다. 매체나 시점 같은 스타일적 선택은 마지막에 배치하여 이미 설정된 장면 위에 필터처럼 작용하게 하는 것이 가장 좋습니다. 가이드는 요소를 무분별하게 쌓지 말라고 경고합니다. 상충하는 키워드가 너무 많으면 품질이 저하되기 때문입니다.
세 회사가 독립적으로 이러한 조언에 도달했다는 것은, 이들의 모델이 비슷한 시기에 유사한 수준의 역량에 도달했음을 시사합니다. 구글은 더 짧게 쓰라고 조언하고, ByteDance는 대부분의 요소를 선택 사항으로 분류하며, Kuaishou는 양보다 단어의 순서를 강조합니다. 구체적인 표현 방식은 다르지만, 세 연구소 모두 창작자들에게 더 자유롭고 자연스러운 프롬프트를 사용하도록 권장합니다.
이제 Gemini Omni 프롬프트 가이드가 실제 현장에서 어떻게 적용되는지 살펴보겠습니다.
Gemini Omni 프롬프트 구조: 구글 DeepMind가 사용하는 5가지 차원
가이드는 완전한 예시로 시작합니다.
평온한 호수를 가로질러 부드럽게 미끄러지는 광각 트래킹 샷. 위쪽에는 거대하고 반사되는 크롬 느낌의 콩 모양 물체가 힘들이지 않고 공중에 떠 있고, 천천히 회전하며 장엄한 절벽과 맑고 푸른 물 아래 부분적으로 잠긴 유사한 작은 물체의 왜곡된 반사를 드러낸다. 떠 있는 이상 현상 뒤로 찬란한 태양이 솟아오르며 선명하고 신비로운 일광이 전체 장면을 비추고, 생동감 넘치는 파란색과 녹색 톤이 어우러져 외계 풍경의 광활함과 신비로움을 강조하는 웅장하고 다른 세상의 오케스트라 스코어가 깔리며, 떠 있는 물체에서는 희미하고 깊은 웅웅거리는 소리가 흘러나온다.
_SpuwEI0tIU
90단어가 넘는 문장입니다. 이를 분해하면 5가지 차원이 도출됩니다.
- 샷 프레이밍 및 모션: 광각, 미디엄, 클로즈업 중 무엇인가? 카메라는 부드럽게 미끄러져야 하는가, 갑자기 달려가야 하는가? 두 동사는 확연히 다른 결과를 만들어내므로 올바른 동작 느낌을 찾으려면 몇 번의 테스트가 필요합니다.
- 스타일: 현실적인가, 영화 같은가, 신비로운가, 장엄한가? 이 차원에는 세부 사항이 필요 없습니다. 모델에게 감성적 톤만 전달해도 충분합니다.
- 조명: 빛은 어디서 오는가? 태양, 가로등, 카메라 방향인가 아니면 화면 밖인가? 선명하고 따뜻하며 신비로운 느낌이어야 하는가?
- 장면: 가이드의 한 문장은 강조할 가치가 있습니다. "Omni는 당신의 전반적인 의도에 맞춰 작업할 것이므로 모든 세부 사항을 일일이 묘사할 필요가 없습니다." 이는 Seedance와 Kling의 공식 문서와도 일치합니다.
- 동작 및 상호작용: 장면에 누가 무엇이 있는지, 어떻게 움직이고 어떻게 상호작용하는지 기술합니다.
Gemini Omni 대화형 편집 vs Veo 프롬프트 재작성
Omni와 Veo는 비슷한 수준의 생성 품질을 보여줍니다. 진짜 차이는 비디오 생성 이후의 작업에 있습니다.
이전에는 하나의 세부 사항을 변경하려면 프롬프트를 처음부터 다시 쓰고, 재생성한 뒤 프레임 간 일관성이 유지되길 바라야 했습니다. Omni는 이 단계를 '대화'로 대체합니다.
공식 가이드는 몇 가지 예시를 제공합니다.
작은 소년이 등장하는 스톱모션 스타일 영상. 첫 번째 편집: "나비를 벌로 바꿔줘." 다음: "벌을 작은 반딧불이 떼로 바꿔줘." 한 번에 하나의 요소만 변경되며, 다른 프레임은 자동으로 유지됩니다.
5zDLZZccPTY
카메라 작업도 동일하게 작동합니다. 바이올리니스트 영상에 세 가지 명령을 순차적으로 내립니다: "바이올리니스트를 이미지 환경으로 옮겨줘", "바이올린을 안 보이게 해줘", "카메라 각도를 바이올리니스트 어깨너머로 바꿔줘." 환경 교체, 객체 제거, 카메라 위치 변경이 모두 자연어 하나로 이루어집니다.
jXnbo0gBMHQ
주의할 점이 있습니다. 제3자 리뷰어들에 따르면 편집 지침이 너무 모호할 경우 Omni가 과도하게 편집하여 유지하고 싶었던 요소까지 변경하는 경향이 있다고 합니다. 구글의 권장 사항은 회당 하나의 변수만 변경하고 유지해야 할 요소를 명시적으로 언급하라는 것입니다.
교차 모달 동기화(Cross-modal sync) 예시는 더욱 흥미롭습니다. 밤의 아파트 건물 영상을 찍고 "음악 비트에 맞춰 아파트 불빛이 켜지게 해줘"라는 지침을 추가합니다. 모델은 사운드트랙의 비트를 분석하여 창문 불빛을 이에 맞춥니다. After Effects에서 이 작업을 하려면 타임라인, 메트로놈, 프레임 단위의 수동 키프레임 작업이 필요합니다.
93oo4Yvghl8
Gemini Omni의 4가지 고급 기능: 세계 지식, 텍스트 렌더링, 동작 참조, 다중 입력
가이드의 후반부에서는 4가지 기능을 집중적으로 다룹니다.
응용된 세계 지식(Applied world knowledge)
프롬프트 예시: 일반 컴퓨팅과 양자 컴퓨팅의 차이를 설명하라. 이 문장을 미니멀한 벡터 도형과 풍부한 유기적 질감이 어우러진 현대적인 플랫 미디어 스타일로 시각화하라. 미학은 짙은 네이비 배경에 대비가 강렬한 '일렉트릭' 색상 팔레트(네온 핑크, 시안, 라임)로 정의된다. 이 스타일의 특징은 점묘법과 거친 그라데이션을 사용하여 단순한 기하학적 형태에 리소그래프 같은 촉각적 품질을 더하는 것이다. 날카로운 모서리와 부드럽고 얼룩덜룩한 전환을 결합하여, 삽화는 장난스럽고 편집적인 느낌을 준다.
모델은 이미 양자 중첩이 무엇인지, 그리고 이를 비교하는 샷들을 통해 어떻게 전달해야 하는지 알고 있습니다. 사용자는 양자 역학을 설명할 필요 없이 시각적 톤만 전달하면 됩니다.
3b29A-7qHvE
이는 Omni가 프론티어 추론 모델 위에서 구동되기 때문에 가능하며, 생성 전용 비디오 모델은 이를 따라올 수 없습니다. I/O 이후 Semafor 인터뷰에서 Demis Hassabis는 Omni를 세상을 더 잘 이해하는 AI를 구축하는 프로젝트의 한 단계로 규정했습니다. 그는 알파벳의 자율주행 부서인 Waymo가 이미 자율주행차에 예측 불가능한 상황을 다룰 수 있는 일종의 "상상력"을 부여하기 위해 유사한 세계 모델을 테스트하고 있다고 언급했습니다. 비디오 생성은 그 아키텍처의 가장 눈에 띄는 응용 사례일 뿐입니다.
텍스트 렌더링
프롬프트 예시: 단어 단위로, 화면에 한 번에 한 단어씩, 각 단어마다 다른 애니메이션 스타일, 리듬에 맞는 완벽한 페이싱, 시즐 릴(sizzle reel).
_NV7lrxo6Ik
복합 동작 참조(Complex action reference)
프롬프트 예시: 이전과 동일하게 유지하면서 스케이트보드에서 나오는 애니메이션 모션 효과를 추가해줘.
b94aat8s22c
다중 입력 참조(Multi-input reference)
프롬프트 예시: 영상의 새들이 이미지의 새 형태를 느슨하게 형성한다. 오디오 음악에 맞춰 움직이다가 날아가며 흩어진다.
3jdeP-az3oQ
스타일 전송(Style transfer)
프롬프트 예시: 비디오 참조의 4단계 스타일 진행을 생성하라. 첫 번째는 풍부하고 왁스 질감이 살아있는 스트로크와 거친 종이 배경 위 장난스러운 수제 캐릭터 디자인이 돋보이는 활기찬 크레용 미학이다. 두 번째는 질감 있는 종이 위의 흑연 연필 스케치로 부드럽게 전환하며, 크로스해칭과 다양한 선 굵기, 12fps '라인 보일링' 효과를 사용해 수작업 느낌을 강조한다. 다음은 복잡한 빛의 굴절, 부식 패턴, 미니멀한 스튜디오 배경 내 부드러운 내부 광채가 특징인 초현실적 3D 반투명 유리 스타일로 변형한다. 시퀀스는 제한된 3색 팔레트, 거친 하프톤 질감, 의도적인 레지스트레이션 오버레이를 적용해 레트로한 기계적 마무리를 보여주는 촉각적 리소그래프 인쇄 느낌으로 마무리한다.
n9TesZsfVNw
스토리보드 참조
프롬프트: 이 스토리로 보여줘. 왼쪽 상단부터 순서대로 정확히 스토리를 따라가. 10초 안에 전체 스토리. 영화처럼.
uT937Ptk9fg
교차 샷 일관성(Cross-shot consistency)
RSpqXx0wq8Q
왜 Gemini Omni, ByteDance Seedance, Kuaishou Kling의 프롬프트 조언이 수렴하는가?
앞서 언급한 관찰로 돌아가겠습니다. Seedance, Kling, Omni의 프롬프트 조언이 유사한 것은 서로 베꼈기 때문이 아닙니다. 더 설득력 있는 이유는 이 세대 모델들이 독자적으로 비슷한 역량 수준에 도달했기 때문입니다.
모델이 장면 수준에서 자연어를 처리하고, 세계 지식으로 세부 사항을 보완하며, 사용자의 실제 의도를 추론할 수 있게 되면, 지나치게 상세한 묘사는 오히려 병목 현상이 됩니다. 세 연구소는 구조를 얼마나 추가할지에 대해서는 의견이 갈리지만, 정답이 "더 많이 쓰는 것"은 아니라는 점에는 동의합니다.
이는 대규모 언어 모델과 공동 학습된 확산 모델(diffusion models)의 2년 연구 결과입니다. Omni는 이러한 결과를 비교적 완성된 상태로 끌어올렸습니다.
Atlas Cloud를 통한 Gemini Omni 사용: Seedance, Kling, Veo를 위한 통합 API
Gemini Omni는 Atlas Cloud에 곧 추가됩니다. Atlas Cloud는 텍스트, 이미지, 비디오, 오디오 전반에 걸쳐 300개 이상의 AI 모델을 통합합니다. 주요 비디오 모델들은 이미 플랫폼에서 구동되고 있습니다: Seedance 2.0, Kling 3.0, Wan 2.7, Veo 등. 나란히 비교하려면 Atlas Cloud의 Wan 2.7 vs Seedance 2.0 vs Kling 3.0 심층 분석을 참조하세요.
하나의 계정으로 전체 파이프라인을 운영합니다. 여러 지역 플랫폼마다 등록, 결제, API 키를 관리할 필요가 없습니다. Playground는 대화형 디버깅을 지원합니다. 통합된 OpenAI 호환 API는 기존 워크플로우에 즉시 연결됩니다.
Atlas Cloud의 프롬프트 라이브러리에는 애니메이션, SF, 미스터리, 음식, 브이로그 형식 등을 아우르는 20개 이상의 카테고리의 바로 사용할 수 있는 프롬프트가 있습니다. 각 프롬프트에는 예제 영상과 매개변수 노트가 포함되어 있습니다. 복사하고 단어 몇 개만 바꾸면 바로 실행됩니다.
프로덕션 비디오 생성을 위한 하나의 통합 API
구글이 Gemini 앱과 Google Flow 내에서 Gemini Omni Flash를 일반 사용자에게 출시하는 동안, 동일한 멀티모달 비디오 엔진을 자체 워크플로우에 삽입하려는 개발자와 제품 팀은 안정적이고 예측 가능한 API 계층이 필요합니다.
Atlas Cloud는 Gemini Omni Flash를 OpenAI 호환 통합 API를 통해 제공합니다. 300개 이상의 다른 이미지, 비디오 및 LLM 모델과 함께 말이죠. 따라서 별도의 공급업체 계정, 결제 포털 또는 SDK를 관리할 필요 없이 구글의 네이티브 멀티모달 모델을 통합할 수 있습니다.
두 가지 Gemini Omni Flash 변형이 Atlas Cloud에서 라이브 상태입니다:
| 변형 | 최적 용도 | 입력 | 해상도 | 길이 | 시작 가격 |
|---|---|---|---|---|---|
| Gemini Omni Flash 텍스트-비디오 (개발자용) | 프롬프트 기반 영화적 생성 | 텍스트 (최대 20,000자) | 720p / 1080p / 4K | 4, 6, 8, 10초 | $0.2 + $0.1/초 |
| Gemini Omni Flash 이미지-비디오 (개발자용) | 실제 참조 기반의 피사체 일관성 비디오 | 텍스트 + 최대 7개 참조 이미지 | 720p / 1080p / 4K | 4, 6, 8, 10초 | $0.2 + $0.1/초 |
빠른 시작 — 5줄의 코드로 Gemini Omni Flash 영상 생성:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "골든 아워의 안개 낀 숲, 영화적인 돌리 샷", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
API는 즉시 예측 ID를 반환합니다. /api/v1/model/prediction/{id}를 폴링하여 렌더링된 MP4 URL을 확인하세요. 전체 스키마, 7개 언어로 된 코드 샘플 및 노코드 Playground는 위 링크된 모델 페이지에서 확인할 수 있습니다.






