Kling AI의 립싱크(Lip Sync) 기능을 사용하면 수동 키프레임 작업 없이도 1분 이내에 완벽하게 동기화된 토킹 헤드 영상을 제작할 수 있습니다. 다국어 콘텐츠 제작, 캐릭터 애니메이션, 글로벌 시청자를 위한 영상 더빙 등 어떤 작업이든 Kling 3.0을 활용하면 전문 소프트웨어 없이도 정교한 입모양 동기화가 가능합니다. 이 가이드에서는 오디오 파일 업로드부터 일반적인 출력 문제 해결까지, 전체 워크플로우를 단계별로 설명합니다.
핵심 요약
- Kling AI 립싱크는 오디오 파일 업로드 또는 내장 TTS(텍스트 음성 변환) 생성의 두 가지 모드를 지원합니다.
- Kling 웹 앱 인터페이스 기준, 최대 클립 길이는 60초입니다.
- Kling 3.0은 5개 언어(중국어, 영어, 일본어, 한국어, 스페인어)의 립싱크를 지원합니다.
- 주요 문제로는 텍스트 아티팩트 발생, 정면이 아닌 얼굴의 왜곡, 모바일 탐색의 어려움 등이 있습니다.
- Atlas Cloud는 Kling 3.0 API 액세스를 표준 모델 기준 초당 USD0.071에 제공합니다 (Atlas Cloud Kling 3.0 모델 페이지, 2026).
Kling AI 립싱크 기능이란?
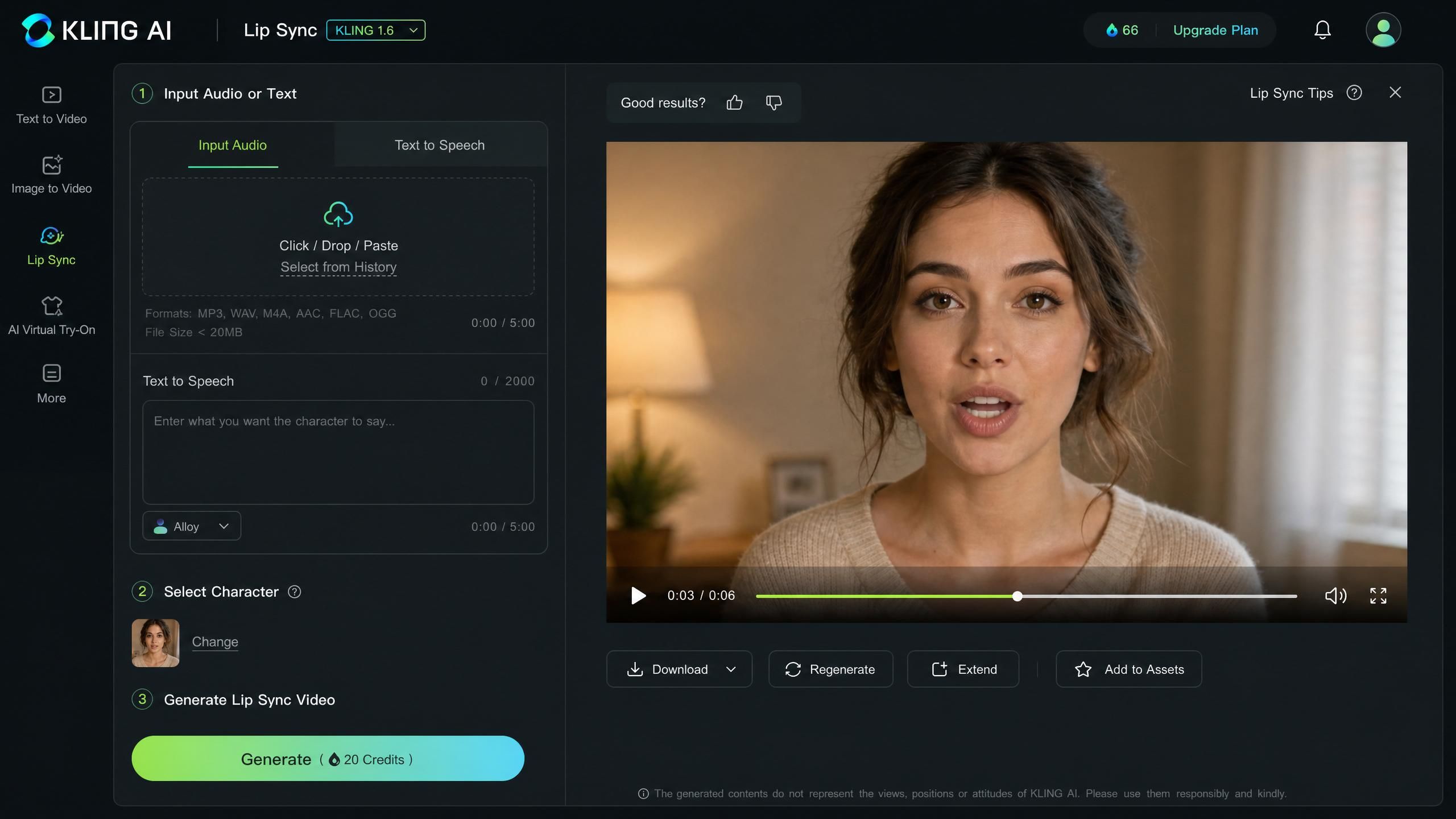
Kling AI는 자사의 립싱크 기능을 "수동 키프레임 작업 없이 1분 이내에 완벽하게 동기화된 토킹 헤드 영상을 생성하는 도구"로 정의합니다(kling.ai 공식 UI, 2026). 이 기능은 영상 클립과 오디오 소스를 입력받아 음성에 맞춰 입모양이 프레임별로 일치하는 새로운 영상을 생성합니다. 해당 기능은 Kling 웹 플랫폼 내 'AI Human' 섹션에서 바로 사용할 수 있습니다.
립싱크 도구는 두 가지 입력 모드를 제공합니다. 첫 번째는 직접적인 오디오 업로드 방식으로, 로컬에 저장된 음성이나 노래 파일을 제공하면 모델이 이를 기반으로 영상을 구동합니다. 두 번째는 내장된 TTS(텍스트 음성 변환) 엔진을 사용하는 방식으로, 스크립트를 입력하면 Kling이 이를 음성으로 변환한 뒤 동기화된 영상을 생성합니다. 두 모드 모두 동일한 형식의 최종 결과물을 제공합니다.
인용 정보: Kling AI의 공식 립싱크 기능은 로컬 오디오 파일 업로드 및 내장 TTS 생성이라는 두 가지 입력 모드를 지원하며, 수동 키프레임 작업 없이 1분 이내에 토킹 헤드 영상을 생성합니다(kling.ai 공식 UI, 2026).
Kling AI 립싱크 튜토리얼: 단계별 가이드
아래의 Kling AI 립싱크 튜토리얼은 kling.ai/app/ai-human/video/new의 표준 웹 UI 워크플로우를 따릅니다. 깔끔한 소스 영상을 사용한다고 가정할 때, 대부분의 크리에이터는 업로드부터 미리보기까지 5분 이내에 작업을 완료할 수 있습니다.
1단계: 립싱크 도구 열기
Kling AI 웹 플랫폼에 접속하여 메인 메뉴에서 AI Human을 선택합니다. New Video를 클릭하여 제작 인터페이스를 엽니다. 좌측 도구 패널에서 립싱크 옵션을 확인할 수 있습니다.
2단계: 소스 영상 업로드
영상 업로드 영역을 클릭하여 클립을 선택합니다. 영상 길이는 최대 60초여야 합니다. 제한 시간을 초과하는 클립은 거부되므로, 필요한 경우 업로드 전에 미리 길이를 편집하세요.
3단계: 오디오 입력 모드 선택
이 단계에서 두 가지 옵션이 나타납니다. 기존 보이스오버, 음악 보컬, 녹음된 나레이션을 사용하려면 Upload Audio를 선택하세요. 스크립트를 직접 입력하려면 Text to Speech를 선택합니다. TTS를 선택하는 경우, 진행하기 전에 언어와 음성 스타일을 지정하세요.
4단계: 오디오 콘텐츠 제공
오디오 업로드 시: 파일을 오디오 패널로 드래그합니다. TTS 사용 시: 텍스트 필드에 스크립트를 입력하거나 붙여넣고, 클립 길이에 맞춥니다. 스크립트가 너무 길면 잘리거나 정렬이 어긋날 수 있으므로 단어 수를 클립 길이에 맞게 신중하게 조절하세요.
5단계: 생성 및 검토
Generate를 클릭합니다. 일반적인 클립의 경우 생성 처리는 1분 이내에 완료됩니다. 다운로드하기 전에 플레이어에서 결과물을 미리 확인하세요. 입꼬리, 모음 모양, 단어 간의 전환이 정확한지 확인합니다.
6단계: 다운로드 또는 재생성
동기화 상태가 정확하다면 내보내기 버튼을 사용하여 영상을 다운로드합니다. 정렬이 어긋난 부분이 보인다면, 더 깨끗한 오디오로 다시 업로드하거나, 소스 영상에서 얼굴이 정면을 향하도록 하고, 오디오 파일의 배경 소음을 줄이는 등의 방법으로 해결할 수 있습니다.
인용 정보: kling.ai/app/ai-human/video/new에서의 Kling AI 립싱크 웹 UI 워크플로우는 오디오 업로드 또는 내장 TTS를 통해 1분 이내에 동기화된 토킹 헤드 영상을 처리합니다(kling.ai 공식 UI, 2026).
Kling AI 최대 클립 길이 및 입력 요구 사항
Kling 웹 앱 인터페이스에 따르면, 립싱크 기능의 Kling AI 최대 클립 길이는 60초입니다(kling.ai, 2026). 또한 인터페이스는 720p를 클립 표준으로 명시하고 있는데, 이는 입력 요구 사항이라기보다 최소 출력 해상도를 의미할 수 있습니다. 60초를 초과하는 클립은 처리 시작 전 거부되므로, 더 긴 콘텐츠는 별도의 세그먼트로 나누어야 합니다.
해상도 요구 사항.
소스 영상은 최소 720p 이상이어야 합니다. 보관용 영상이나 압축된 영상을 사용하는 경우, 가져오기 전에 업스케일링하세요. 더 높은 해상도도 지원되지만, 립싱크 정확도가 비례하여 향상되는 것은 아닙니다.
오디오 형식 고려 사항.
업로드 모드에서 표준 오디오 형식을 지원합니다. 최상의 결과를 얻으려면 배경 소음이 최소화된 깨끗한 모노 또는 스테레오 녹음본을 사용하세요. 심하게 압축된 오디오, 말소리 아래에 깔린 음악, 리버브가 심한 녹음은 모델의 음성 감지 신뢰도를 떨어뜨려 동기화 정확도가 낮아질 수 있습니다.
제한 시간 초과 시 발생하는 현상.
60초를 초과하는 클립을 업로드하면 즉시 오류가 반환됩니다. Kling은 영상을 자동으로 자르거나 일괄 처리하지 않습니다. 더 긴 영상을 제작하는 경우 60초 경계를 기준으로 편집 계획을 세우고, 영상 생성 후 편집기에서 세그먼트를 연결하세요.
인용 정보: Kling AI 립싱크의 최대 클립 길이는 60초이며, 이를 초과하는 클립은 자동으로 잘리지 않고 업로드 단계에서 거부됩니다(kling.ai 공식 UI, 2026).
Kling AI 립싱크 기능: 언어, 모드 및 Kling 3.0 개선 사항
Atlas Cloud Kling 3.0 모델 페이지에 따르면, Kling 3.0은 "다양한 언어 및 방언(중국어, 영어, 일본어, 한국어, 스페인어)에 대해 정밀한 립싱크를 구현하여 몰입감 있는 경험을 제공합니다"(Atlas Cloud, 2026). 이러한 5개 언어 지원 범위는 영어권만을 타겟으로 하는 많은 도구와 Kling을 차별화하는 요소입니다. 아시아 및 스페인어권 시장을 겨냥한 콘텐츠 제작자에게 특히 유용합니다.
지원 언어.
확인된 5개 언어는 중국어(CN), 영어(EN), 일본어(JP), 한국어(KR), 스페인어(ES)입니다. 각 언어는 음소와 비소(viseme) 매핑이 정확하게 조정되어 있어, 범용 영어 학습 모델에 의존하는 대신 각 언어의 실제 발음에 맞는 입모양을 생성합니다.
TTS 모드 vs 오디오 업로드 모드.
이 두 모드는 서로 다른 제작 워크플로우를 지원합니다. TTS 모드는 녹음된 오디오가 없는 프로토타입 스크립트나 짧은 형식의 콘텐츠 제작에 더 빠릅니다. 오디오 업로드 모드는 미묘한 나레이션, 노래, 전문적으로 녹음된 보이스오버 등 보컬 연기가 중요한 프로젝트에 적합합니다. 오디오가 깨끗하고 명확하게 녹음되었다면 두 모드의 출력 품질은 비슷합니다.
Kling 3.0 다국어 기능 개선.
Atlas Cloud 플랫폼은 Kling 3.0이 핵심 기능으로 "다국어 립싱크"를 지원한다고 언급합니다. 실제로 이는 제작자가 모델을 재학습하거나 교체할 필요 없이 세그먼트별로 언어를 전환할 수 있음을 의미합니다. 하나의 프로젝트 내에서 한 클립은 중국어 대화를, 다른 클립은 영어 대화를 사용하는 식으로 동일한 인터페이스 내에서 처리가 가능합니다.
인용 정보: Kling 3.0 립싱크는 방언별 튜닝을 통해 5개 언어(중국어, 영어, 일본어, 한국어, 스페인어)에서 정밀한 동기화를 달성한다고 Atlas Cloud Kling 3.0 모델 페이지에 명시되어 있습니다(Atlas Cloud, 2026).
Kling 3.0에서의 다중 캐릭터 대화
Kling 3.0을 사용하는 타사 플랫폼 연동 커뮤니티 튜토리얼에 따르면, "중첩된 대화와 전체 타이밍 제어를 위한 개별 트랙을 사용하여 한 프레임에 3~4명의 캐릭터를 애니메이션화하는 것"이 가능합니다(AI Master YouTube 채널, 2026년 3월). 이 기능은 립싱크 활용 범위를 단일 화자 토킹 헤드를 넘어선 수준으로 확장합니다. 샷을 나누지 않고도 대화, 그룹 발표, 여러 캐릭터가 등장하는 장면을 구현할 수 있습니다.
개별 트랙 작동 방식.
다중 캐릭터 모드는 프레임 내 각 캐릭터에게 독립적인 오디오 트랙을 할당합니다. 캐릭터 간 타이밍 오프셋을 개별적으로 제어할 수 있어 한 캐릭터가 말을 마친 후 다음 캐릭터가 이어지게 하거나, 자연스럽게 대화가 겹치게 할 수도 있습니다. 이는 개별 캐릭터를 따로 생성한 뒤 합성해야 했던 이전 버전에 비해 상당히 개선된 워크플로우입니다.
다중 캐릭터 샷을 위한 모범 사례.
커뮤니티 튜토리얼에 따르면 Kling AI는 얼굴 클로즈업 샷과 인간형 캐릭터에서 가장 좋은 성능을 발휘합니다(Tao Prompts 튜토리얼, 2024년 10월). 다중 캐릭터 장면의 경우, 각 얼굴이 선명하게 보이고 조명이 잘 갖춰진 풀샷을 사용하는 것이 좋습니다. 너무 작거나 가려져 있거나 극단적인 각도의 얼굴은 같은 클립 내에서 다른 캐릭터의 싱크는 성공해도 특정 캐릭터의 싱크 오류를 유발할 수 있습니다.

인용 정보: Kling 3.0은 AI Master YouTube 튜토리얼에 기록된 바와 같이, 개별 오디오 트랙을 통해 한 프레임 내 3~4명의 캐릭터에 대한 중첩 대화 및 독립적인 타이밍 제어를 지원합니다(AI Master, 2026년 3월).
Kling 립싱크의 일반적인 문제 해결
여러 커뮤니티의 사용자들이 Kling AI 립싱크 결과물과 관련하여 반복적으로 보고하는 세 가지 문제가 있습니다. 각 문제의 원인을 파악하면 더 빠르게 해결할 수 있습니다.
문제 1: 출력물에 텍스트 아티팩트 발생.
AI 영상 커뮤니티의 사용자들은 특히 TTS 모드 사용 시 예상치 못한 텍스트 문자가 출력 영상에 찍혀 나오는 버그를 보고합니다. [고유 통찰] 이 아티팩트는 TTS 파이프라인의 자막 렌더링 레이어가 영상 출력물에 섞여 들어오면서 발생하는 것으로 보입니다. TTS 엔진이 음성을 생성할 때 내부적으로 자막 트랙을 동시에 생성할 수 있는데, 렌더링 파이프라인이 자막 레이어를 시각적 출력물과 깔끔하게 분리하지 못하면 텍스트가 영상 프레임에 입혀집니다. 아티팩트가 나타나면 TTS 대신 오디오 업로드 모드를 사용하세요. 업로드 경로를 통하면 TTS 자막 레이어를 완전히 우회할 수 있기 때문입니다.
문제 2: 얼굴 왜곡.
Facebook의 AI 영상 그룹 사용자들은 "Kling AI 사용 시 립싱크 왜곡" 현상에 대해 자주 문의합니다. 이는 주로 소스 영상 속 얼굴이 정면에서 30도 이상 벗어난 각도일 때 발생합니다. 립싱크 모델은 기본적으로 정면 얼굴 데이터를 기반으로 학습되었기 때문에, 측면이나 3/4 측면 뷰에서는 포즈 추정 신뢰도가 낮아집니다. 모델이 입모양 기하학을 과도하게 보정하면서 왜곡이 나타나는 것입니다. 해결책: 카메라 각도를 더 정면으로 맞추어 영상을 다시 촬영하거나 선택하세요.
문제 3: 모바일 탐색의 혼란.
AI 영상 커뮤니티에서 자주 올라오는 질문 중 하나는 "모바일에서 Kling AI 립싱크 기능을 어디서 찾나요?"입니다. 해당 기능은 모바일 브라우저에서도 접근 가능하지만 탐색 경로가 데스크톱과 다릅니다. 모바일에서는 'AI Human' 섹션이 상단 네비게이션 항목이 아닌 햄버거 메뉴 안에 숨겨져 있습니다. 메뉴 아이콘을 탭하고, AI Human을 선택한 뒤, New Video를 선택하면 립싱크 도구를 찾을 수 있습니다.
인용 정보: 가장 많이 보고된 Kling AI 립싱크 문제 세 가지는 TTS 출력 시 텍스트 아티팩트, 정면이 아닌 각도에서의 얼굴 왜곡, 모바일에서 립싱크 패널을 찾는 과정의 어려움입니다(2024-2026).
Atlas Cloud API 연동
Atlas Cloud는 립싱크 기능을 포함한 Kling 3.0 API 액세스를 두 가지 가격 계층으로 제공합니다. Kling 3.0 표준(Standard)은 초당 USD0.071(정상 요금 USD0.084에서 15% 할인), 전문가용(Professional)은 초당 USD0.095(정상 요금 USD0.112에서 15% 할인)입니다. 두 요금 모두 생성된 출력 영상의 초 단위로 청구됩니다.
표준 vs 전문가 계층 선택 기준.
표준 계층은 배치 워크플로우, 프로토타이핑, 거의 완벽한 싱크 수준으로 충분한 콘텐츠에 적합합니다. 전문가 계층은 고객 납품용 결과물, 방송용 프로젝트, 모든 음소 전환이 검증되어야 하는 콘텐츠에 적합합니다. 약 34%의 가격 차이는 두 계층 간의 품질 격차를 반영합니다.
개발자 설정.
전체 API 문서는 Atlas Cloud API 문서에서 확인할 수 있습니다. 플랫폼은 API 키 인증 모델을 사용합니다. 개발자는 영상 및 오디오 입력을 제출하고, 5개 지원 언어 중 타겟 언어를 지정하여 출력 상태를 폴링(polling)할 수 있습니다. 이는 영상 생성 엔드포인트이며 OpenAI 채팅 완료 구조를 따르지 않는다는 점을 참고하세요.
Kling Video O3 및 음성 복제.
Atlas Cloud는 "영상 또는 이미지 입력에서 파생된 사용자 지정 피사체와 음성 복제"를 지원하는 전문가용 버전인 Kling Video O3에 대한 액세스도 제공합니다. 캐릭터 일관성이 중요한 콘텐츠 파이프라인을 구축하는 제작팀의 경우, 음성 복제 기능이 립싱크 기능과 직접 연동되어 세션 간 화자 정체성을 유지할 수 있습니다.
인용 정보: Atlas Cloud는 Kling 3.0 API 액세스를 초당 USD0.071(표준) 및 USD0.095(전문가)에 제공하며, Kling Video O3를 통해 영상이나 이미지에서 파생된 음성 복제 기능을 지원합니다(Atlas Cloud, 2026).
자주 묻는 질문
Kling AI로 립싱크가 가능한가요?
네. Kling AI는 웹 플랫폼의 AI Human 섹션 내에 전용 립싱크 기능을 포함하고 있습니다. 최대 60초 분량의 영상 클립을 받아 업로드된 오디오 파일이나 내장 TTS를 사용하여 동기화된 결과물을 생성합니다. 처리 과정은 보통 1분 이내에 완료됩니다(kling.ai 공식 UI, 2026).
Kling AI 립싱크는 무료인가요?
Kling AI는 웹 플랫폼에서 이용 제한이 포함된 무료 계층을 제공합니다. Atlas Cloud를 통한 API 액세스는 표준 계층 초당 USD0.071, 전문가 계층 초당 USD0.095로 과금됩니다. 무료 플랫폼 사용자는 이용자가 몰리는 시간대에 대기열 제한이나 생성 횟수 제한을 겪을 수 있습니다(Atlas Cloud 요금 정책, 2026).
Kling AI 립싱크의 최대 클립 길이는 얼마인가요?
Kling AI 최대 클립 길이는 60초입니다. 이 길이를 초과하는 클립은 업로드 시 거부됩니다. 더 긴 콘텐츠를 제작하려면 60초 이하의 세그먼트로 나누어 작업한 뒤 생성 후 연결하세요(kling.ai 공식 UI, 2026).
Kling AI 립싱크는 어떤 언어를 지원하나요?
Kling 3.0 립싱크는 중국어(CN), 영어(EN), 일본어(JP), 한국어(KR), 스페인어(ES)의 5개 언어를 지원합니다. Atlas Cloud Kling 3.0 모델 페이지에 명시된 바와 같이, 범용 모델이 아닌 각 언어의 방언별 음소-비소 매핑 방식을 사용합니다(Atlas Cloud, 2026).
Kling AI 립싱크는 모바일에서 작동하나요?
네, 하지만 탐색 경로가 데스크톱과 다릅니다. 모바일에서는 AI Human 섹션이 상단 네비게이션 바가 아닌 햄버거 메뉴 안에 있습니다. 메뉴 아이콘을 탭하고 AI Human을 선택한 뒤 New Video를 선택하면 립싱크 도구를 찾을 수 있습니다. 이러한 탐색 방식의 차이는 AI 영상 크리에이터 커뮤니티에서 자주 혼란을 겪는 부분입니다.
결론
Kling AI의 립싱크 기능은 두 가지 오디오 입력 모드, 5개 언어 지원, 60초 클립 시간 제한, Kling 3.0의 다중 캐릭터 지원 등 대부분의 크리에이터와 개발자 워크플로우의 핵심 요구 사항을 충족합니다. 텍스트 아티팩트, 얼굴 왜곡, 모바일 탐색 등 흔히 겪는 문제들은 모두 우회 방법이나 타사 도구 없이 해결 가능한 것으로 확인되었습니다.






