
Grok API: xAI Reasoning and Coding Models
xAI가 개발한 Grok은 실시간 인식과 최첨단 수준의 추론을 중심으로 구축된 대규모 언어 모델 시리즈입니다. Grok 4.3은 xAI의 고급 대화형 모델로 자연스러운 대화, 지식 탐색 및 1,000,000 토큰 컨텍스트 창에 걸친 다단계 추론에 최적화되어 있습니다. Grok Build 0.1은 다른 방향을 취합니다. 이 모델은 소프트웨어 개발을 위해 특별히 제작되었으며, 복잡한 개발자 워크플로 전반의 코드 생성, 디버깅 및 리팩터링에 중점을 둔 기능을 갖추고 있습니다. 두 모델 모두 OpenAI 호환 API 엔드포인트를 통해 Atlas Cloud에서 사용할 수 있으며, 백만 토큰당 1달러부터 시작합니다.
주요 모델 탐색
Atlas Cloud는 업계 최고의 최신 크리에이티브 모델을 제공합니다.


Grok API 모델 비교
Match each job to the right model: Grok 4.3 for reasoning across a 1M token context and Grok Build 0.1 for agentic coding, both reachable through one OpenAI-compatible key on Atlas Cloud.
| Model | Type | Best For | Context | Inputs | Function Calling | Structured Outputs | Prompt Caching | Status |
|---|---|---|---|---|---|---|---|---|
| Grok 4.3 | Flagship reasoning model | Logic, analysis, multi-step agents, long-document work | 1M tokens | Text, image | Yes | Yes | Yes | Flagship, GA |
| Grok Build 0.1 | Coding-focused model | Code generation, debugging, refactoring, coding agents | 256K tokens | Text, image | Yes | Yes | Yes | Early access |
Grok API Features
The Grok API brings xAI's reasoning and coding models to Atlas Cloud with a 1M token context window, always-on reasoning, function calling, structured outputs, vision input, and prompt caching, all behind one OpenAI-compatible key.

1M Token Context Window
Grok 4.3 handles up to one million tokens in a single request, enough for full contract sets, large codebases, or long multi-turn agent sessions. The wide context removes chunked retrieval and preserves cross-document reasoning that shorter models lose.
Always-On Reasoning with the Grok API
The Grok API runs Grok 4.3 with built-in step-by-step reasoning, tuned for accuracy-critical work like logic, math, and multi-step analysis. The model thinks before it answers, which lifts factual reliability and instruction following on complex prompts.
Agentic Tool Calling
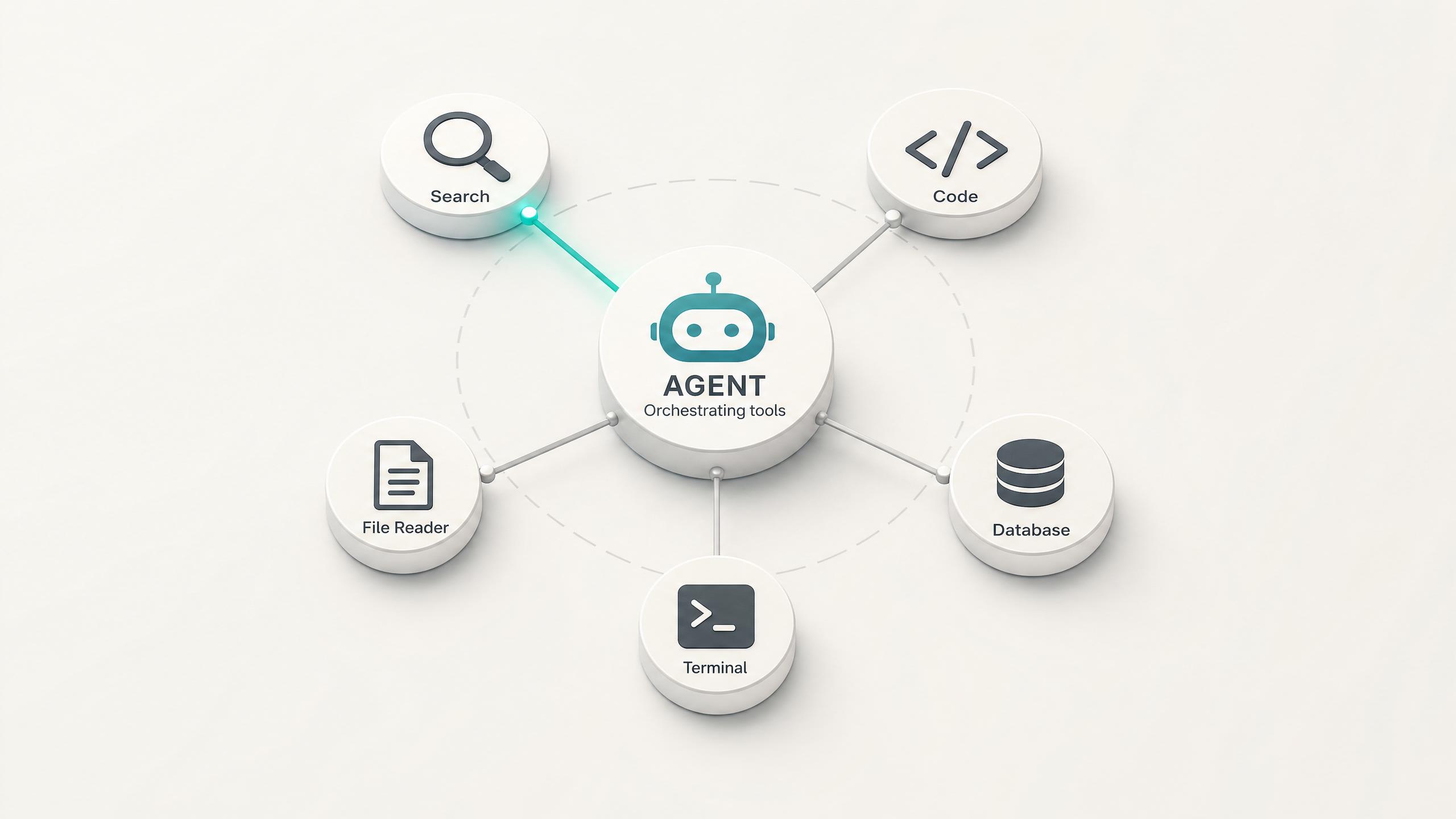
Grok 4.3 is built for agents: it plans, calls functions in sequence, and adjusts on intermediate results. Native function calling lets it trigger tools and APIs mid-task, the foundation for research agents, support bots, and automation that runs without a human in the loop.
Structured Outputs and Vision with the Grok API
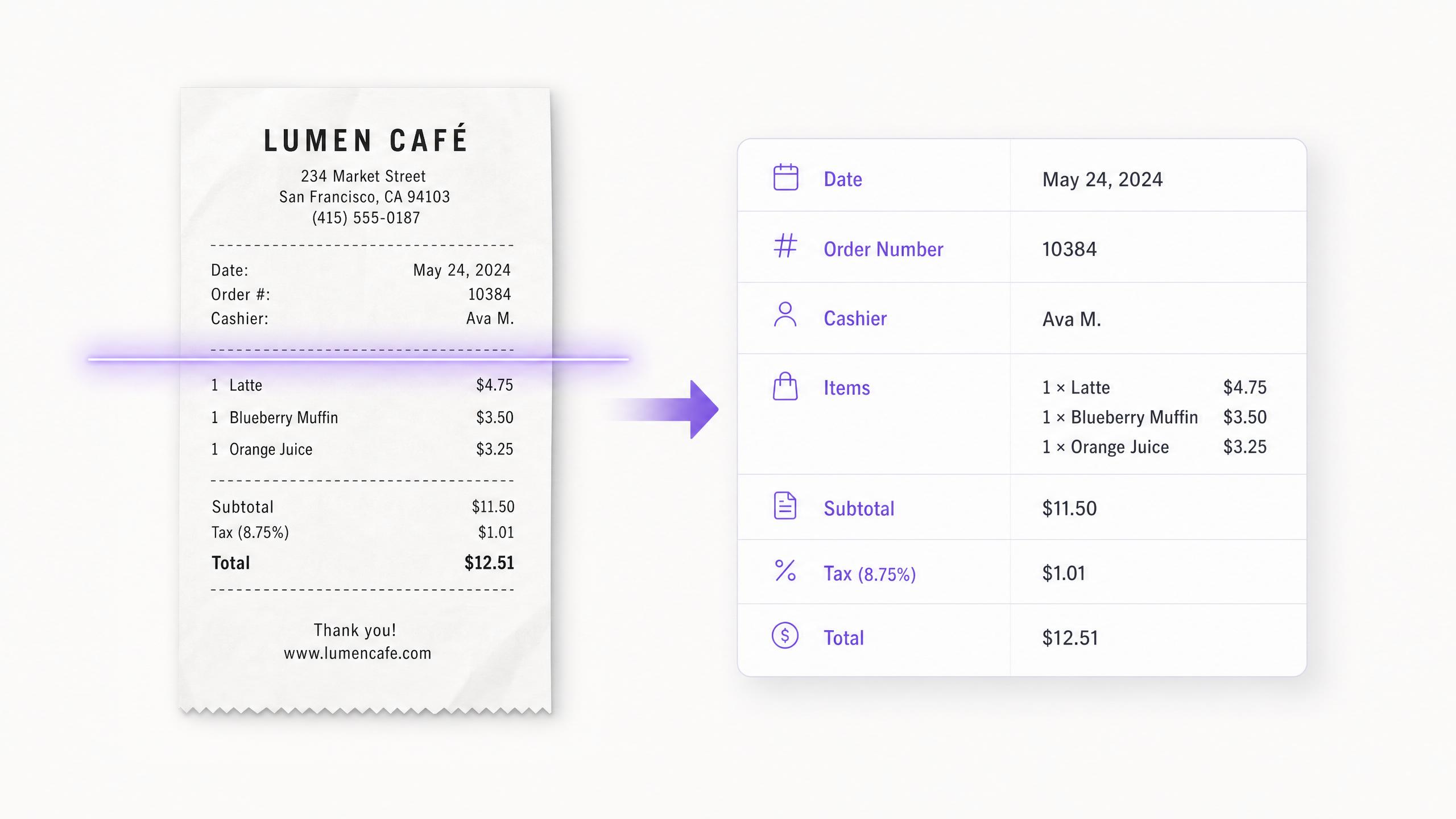
The Grok API returns structured JSON that matches your schema, so extracted data flows straight into downstream code. Grok 4.3 also accepts images alongside text, handling diagrams, screenshots, and UI mockups in the same call.

Coding with Grok Build 0.1
Grok Build 0.1 is xAI's coding-tuned model for code generation, debugging, and refactoring across developer workflows, with a 256K token context. It targets interactive coding agents and multi-step development tasks rather than general chat.

Prompt Caching on the Grok API
The Grok API supports prompt caching, which reuses a shared system prompt or context prefix at a lower token rate. For agentic loops that send the same instructions across many calls, this cuts repeated input cost without changing your code.
여러 모델에 걸친 단일 빌드 프롬프트
동일한 빌드 프롬프트를 Grok 및 Atlas Cloud의 다른 모델에 전달하고 각각이 완전하고 실행 가능한 웹 페이지를 생성하는 것을 관찰하여, 코딩 스타일과 출력 결과를 나란히 비교해 보십시오.
CDN에서 Three.js를 사용하여 대화형 3D 태양계를 보여주는 단일 독립형 HTML 파일을 구축하십시오. 색상과 후광으로 근사한 텍스처, 애니메이션된 궤도 및 별밭 배경을 갖춘 태양과 8개의 궤도 행성을 렌더링합니다. 사용자가 마우스로 카메라를 회전하고 확대/축소할 수 있게 하며, 행성을 클릭하면 카메라가 부드럽게 날아가 통계를 표시하도록 합니다. 우아한 오버레이 제목과 시간을 가속 또는 감속할 수 있는 제어 기능을 포함하십시오. Three.js CDN 가져오기를 포함하여 모든 것을 하나의 HTML 파일로 유지하십시오. 놀랍고 영화 같은 시각적 효과를 우선시하십시오.
Grok 4.3
GLM 5
Grok Build 0.1
애니메이션이 적용된 분석 대시보드 역할을 하는 단일 독립형 HTML 파일을 구축하십시오. 애니메이션 막대 차트, 로드 시 자체적으로 그려지는 꺾은선형 차트, 도넛형 차트 및 숫자가 올라가는 요약 통계 카드를 포함하십시오. 하드코딩된 샘플 데이터, 부드러운 진입 애니메이션 및 깔끔하고 모던한 다크 대시보드 레이아웃을 사용하십시오. 각 차트 요소에 미세한 호버 툴팁을 추가하십시오. 외부 라이브러리 없이 인라인 CSS와 canvas 또는 SVG를 사용한 순수 JavaScript(Vanilla JS)만 사용하십시오. 프리미엄 SaaS 대시보드처럼 보이게 만드십시오.
Grok 4.3
GLM 5
Grok Build 0.1
Atlas Cloud에서 Grok LLM API로 할 수 있는 작업
Grok 4.3은 100만 토큰의 컨텍스트 창과 실시간 웹 및 X 검색을 결합하여, 깊은 추론과 함께 최신 정보가 필요한 프로덕션 워크플로우에 실용적으로 사용할 수 있게 해줍니다.

실시간 연구 및 인텔리전스 파이프라인
연구 도구를 구축하는 팀은 Grok 4.3의 Web Search 및 X Search 애드온을 사용하여 별도의 검색 레이어 없이 웹과 X의 라이브 데이터를 생성 과정으로 직접 가져옵니다. 이는 모델의 학습 컷오프 이후에 게시된 정보에 따라 답변이 달라지는 경쟁 분석, 뉴스 요약 및 시장 인텔리전스 워크플로에 유용합니다. Web Search와 X Search는 xAI API에서 1,000회 호출당 5달러가 청구됩니다.

비용 효율적인 프로덕션 LLM 백엔드
GPT-4.1 또는 Claude Sonnet에서 전환하는 엔지니어링 팀은 Atlas Cloud의 OpenAI-compatible 엔드포인트를 통해 Grok 4.3을 드롭인 대체제로 사용합니다. 100만 입력 토큰당 1.25달러인 Grok 4.3은 입력 측면에서 GPT-4.1보다 약 37%, Claude Sonnet 4.6보다 58% 저렴합니다. 마이그레이션 시 기존 SDK 코드에서 base URL과 API 키만 변경하면 됩니다.

1M 컨텍스트 기반 긴 문서 분석
법무, 재무 및 연구 팀은 Grok 4.3의 100만 토큰 컨텍스트 창을 사용하여 단일 API 호출로 전체 계약서 세트, 재무 보고서 또는 기술 문서를 처리합니다. 이 대규모 컨텍스트는 청크 단위 검색 파이프라인의 필요성을 없애고, 짧은 컨텍스트 모델에서는 깨지기 쉬운 문서 간 추론 능력을 보존합니다. 여러 분석 호출에서 동일한 문서 컨텍스트를 재사용할 때 프롬프트 캐싱을 통해 비용을 추가로 절감할 수 있습니다.

멀티모달 코딩 및 시각 분석
개발자는 Grok 4.3의 이미지 이해 기능을 사용하여 다이어그램, 스크린샷, UI 모형 및 오류 로그를 동일한 API 호출에서 텍스트와 함께 전달합니다. 이는 오류의 스크린샷이나 시스템 아키텍처 다이어그램이 텍스트만으로는 제공할 수 없는 컨텍스트를 제공하는 디버깅 워크플로우에 유용합니다. 동일한 호출에서 함수 호출 및 구조화된 출력이 지원되므로 추출된 시각적 데이터를 다운스트림 처리에 준비된 스키마로 반환할 수 있습니다.

에이전트 기반 다단계 작업 실행
제품 팀은 Grok 4.3의 에이전트 최적화를 사용하여 중간에 사람의 프롬프트 없이도 여러 단계에 걸쳐 계획, 실행, 반복하는 에이전트를 구축합니다. 이 모델은 복잡한 작업 분해에 맞게 특별히 조정되었습니다. 즉, 높은 수준의 목표를 하위 작업으로 나누고 순차적으로 도구를 호출하며 중간 결과를 바탕으로 조정합니다. 함수 호출 및 Web Search 애드온과 결합하면 단일 에이전트 실행만으로 "경쟁사 찾기, 가격 분석, 비교 보고서 작성"과 같은 조사부터 출력까지의 워크플로우를 처리할 수 있습니다.

데이터 분석을 위한 컨텍스트 내 코드 실행
데이터 및 분석 팀은 Code Execution 애드온이 포함된 Grok 4.3을 사용하여 추론 호출 내에서 직접 Python을 실행하고 데이터를 처리하며 모델의 추론 과정과 함께 계산된 결과를 반환합니다. 이로 인해 데이터 분석 도구나 자동화된 보고 파이프라인을 구축할 때 별도의 코드 실행 환경이 필요하지 않습니다. Code Execution은 xAI API에서 1,000회 호출당 5달러가 청구되며, 토큰 비용과는 별도입니다.
Grok API 비교 분석
Atlas Cloud에서 컨텍스트, 입력 및 포커스 측면에서 Grok API가 다른 선도적인 LLMs와 어떻게 비교되는지 확인해 보세요. 이를 통해 단일 키로 각 작업을 적합한 모델에 라우팅할 수 있습니다.
| Model | Provider | Context Window | Inputs | Best For |
|---|---|---|---|---|
| Grok 4.3 | xAI | 1M tokens | Text | Agentic reasoning, long-document analysis, high factual accuracy |
| Grok Build 0.1 | xAI | 256K tokens | Text | Code generation, debugging, refactoring |
| DeepSeek V4 Pro | DeepSeek | 1M tokens | Text | Cost-efficient reasoning and agentic tool use at scale |
| Kimi K2.6 | Moonshot | 262K tokens | Text, image | Long-horizon coding agents and multimodal workflows |
| GLM 5.2 | Z.ai | 202.8K tokens | Text | Long-horizon agentic engineering and project-scale coding |
Atlas Cloud에서 Grok 사용하는 방법
몇 분 만에 시작하세요 — 간단한 단계를 따라 Atlas Cloud 플랫폼을 통해 모델을 통합하고 배포하세요.
Atlas Cloud 계정 생성
atlascloud.ai에서 가입하고 인증을 완료하세요. 신규 사용자는 플랫폼 탐색과 모델 테스트를 위한 무료 크레딧을 받습니다.
Atlas Cloud에서 Grok을(를) 사용하는 이유
고급 Grok 모델과 Atlas Cloud의 GPU 가속 플랫폼을 결합하여 비교할 수 없는 성능, 확장성 및 개발자 경험을 제공합니다.
성능 및 유연성
낮은 지연 시간:
실시간 추론을 위한 GPU 최적화 추론.
통합 API:
하나의 통합으로 Grok, GPT, Gemini 및 DeepSeek를 실행합니다.
투명한 가격:
Serverless 옵션을 포함한 예측 가능한 token당 청구.
엔터프라이즈 및 확장
개발자 경험:
SDK, 분석, 파인튜닝 도구 및 템플릿.
신뢰성:
99.99% 가동 시간, RBAC 및 규정 준수 로깅.
보안 및 규정 준수:
SOC 2 Type II, HIPAA 준수, 미국 내 데이터 주권.
Grok LLM에 대한 자주 묻는 질문
Atlas Cloud는 xAI의 현재 플래그십 LLM인 Grok 4.3을 호스팅하며, 100만 입력 토큰당 1.25달러에 제공됩니다. 이 모델은 단일 API에서 채팅, 추론, 함수 호출, 구조화된 출력 및 이미지 이해를 지원합니다. 추가되는 다른 Grok 버전은 Atlas Cloud xAI 컬렉션 페이지를 확인하십시오.
Grok 4.3은 100만 토큰의 컨텍스트 창을 지원합니다. 이는 단일 호출로 전체 코드베이스, 방대한 연구 문서 또는 확장된 멀티턴 에이전트 세션을 처리하기에 충분히 큰 규모입니다. 컨텍스트 제한은 텍스트 및 이미지 입력의 조합에 적용됩니다.
네. xAI API는 Web Search 및 X Search를 선택적 애드온으로 지원하며, 1,000회 호출당 5달러가 별도로 청구됩니다. 이를 통해 Grok는 생성 과정 중 웹이나 X에서 실시간 정보를 검색할 수 있습니다. 일반 API 호출과 함께 표준 API 엔드포인트를 통해 이러한 기능에 액세스하세요.
네. xAI API는 프롬프트 캐싱을 지원하여 동일한 시스템 프롬프트나 컨텍스트 접두사를 재사용하는 요청의 비용을 절감합니다. 캐시된 입력 토큰은 캐시되지 않은 토큰보다 훨씬 낮은 요율로 청구됩니다. 이는 여러 호출에 걸쳐 동일한 명령을 보내는 에이전트 워크플로우에 특히 유용합니다.
네. Grok 4.3은 멀티모달 입력을 지원하여 동일한 API 호출에서 텍스트와 함께 이미지를 허용합니다. 표준 메시지 형식을 통해 이미지 URL 또는 base64로 인코딩된 이미지를 전달할 수 있습니다. 이를 통해 시각적 질의응답, 문서 분석, 이미지 기반 코드 생성과 같은 사용 사례가 가능해집니다.
네. Grok 4.3은 함수 호출, 구조화된 출력 및 스트리밍 응답을 지원합니다. 이러한 기능은 표준 OpenAI 호환 함수 스키마와 함께 작동하므로 GPT 기반 통합의 기존 도구 정의가 직접 전송됩니다. 코드 실행도 1,000회 호출당 5달러의 선택적 추가 기능으로 사용할 수 있습니다.
프롬프트 캐싱은 긴 시스템 프롬프트나 공유 지침과 같이 반복되는 컨텍스트 접두사를 후속 호출 시 할인된 입력 토큰 요금으로 재사용합니다. 모든 요청에서 동일한 설정을 다시 전송하는 챗봇 및 에이전트의 경우, 코드를 변경하지 않고도 반복적인 입력 비용을 낮출 수 있습니다. 캐시가 적용되도록 정적 콘텐츠는 프롬프트의 시작 부분에, 가변적인 사용자 콘텐츠는 끝에 배치하세요.
속도 제한 및 동시성은 계정 등급에 따라 다르므로, 지수 백오프를 추가하고 429 응답 시 재시도하며 트래픽 급증 시 요청을 대기열에 넣으십시오. 대규모 오프라인 작업의 경우 일괄 처리를 통해 대량 작업이 실시간 제한에 영향을 주지 않도록 할 수 있습니다. 규모가 커질 때 흔히 발생하는 숨겨진 비용은 매 호출마다 전체 대화 기록을 다시 보내는 것입니다. 따라서 전체 스레드 대신 간략한 요약을 전달하고, 사용량이 증가함에 따라 지원팀에 문의하여 제한을 늘리십시오.
Grok API는 토큰 사용량을 기반으로 하는 종량제 요금 방식을 사용하며, 입력 및 출력 토큰은 요청당 측정되고 구독이 필요하지 않습니다. Atlas Cloud에서 300개 이상의 다른 모델과 함께 Grok을 실행하면 제공업체별로 별도의 계약을 맺을 필요 없이 하나의 계정과 하나의 청구서만 있으면 됩니다. 프롬프트 캐싱 및 일괄 처리를 통해 반복적이거나 오프라인인 워크로드의 실질적인 비용을 절감할 수 있습니다.
Atlas Cloud에서 계정을 생성하고 API 키를 발급받은 후, 기존의 OpenAI 호환 클라이언트를 Grok 모델 이름이 지정된 Atlas 엔드포인트로 지정하십시오. 추론을 위해서는 Grok 4.3으로, 코딩을 위해서는 Grok Build 0.1로 첫 번째 요청을 보낸 다음 필요에 따라 규모를 확장하십시오. 동일한 키로 300개 이상의 모델에 액세스할 수 있으므로 추가 설정 없이 다른 모델을 테스트할 수 있습니다.
더 많은 패밀리 탐색
Seedance 2.0
Seedance 2.0 API는 쿼드 모달 입력(텍스트, 이미지, 비디오, 오디오) 및 샷 간의 구도, 카메라 움직임, 캐릭터 액션을 고정하는 업계 최고의 "Universal Reference" 시스템을 갖춘 ByteDance의 멀티모달 비디오 모델에 대한 프로덕션 액세스를 제공합니다. 단 한 번의 API 호출로 디렉터급 제어를 통합하고, 초당 $0.09의 고정 요금, 즉각적인 키 발급 및 대기자 명단 없이 이용할 수 있으며, 엔터프라이즈급 가동 시간과 규정 준수를 보장합니다. Seedance 2.0 Native 4K가 이제 출시되었습니다!
Grok Imagine
Grok Imagine API는 개발자에게 xAI의 이미지, 비디오 및 오디오 생성 기능을 단일 제품군으로 제공합니다. 다국어 텍스트 렌더링이 포함된 최대 2K 해상도의 이미지를 생성하며, 기본 동기화된 오디오 및 참조 기반 편집 기능이 포함된 최대 15초 길이의 비디오를 생성합니다. Atlas Cloud에서는 단일 키로 모든 Grok Imagine 모드를 실행할 수 있으므로 별도의 설정 없이 이미지, 비디오, 오디오 간에 이동할 수 있으며, 요금은 이미지당 $0.02, 초당 $0.05부터 시작합니다.
Gemini Omni Flash
Gemini Omni API는 Google I/O 2026에서 공개된 Google DeepMind의 멀티모달 비디오 생성·편집 모델을 여러분의 스택으로 가져옵니다. Gemini Omni는 Gemini의 추론 엔진과 생성형 미디어를 결합해 텍스트, 이미지, 비디오, 오디오를 자유롭게 조합한 입력을 받아 일관되고 지식에 기반한 결과물을 만들어 냅니다. 자연스러운 대화로 결과를 다듬어 보세요. 물리 법칙과 캐릭터, 연속성은 그대로 유지한 채 오브젝트를 교체하고 장면을 다시 쓰고 스타일을 바꿀 수 있습니다. Atlas Cloud는 텍스트-투-비디오, 최대 7장의 참조 이미지를 지원하는 이미지-투-비디오, 참조-투-비디오까지 Gemini Omni Flash 전체 라인업을 하나의 통합 API로 제공하며, $0.112부터 시작하는 투명한 초당 과금에 구독도 필요 없습니다. 지금 바로 개발을 시작하세요.
GPT Image 2
GPT Image 2 API는 개발자들에게 GPT Image 1.5의 후속 모델인 OpenAI의 최신 이미지 모델에 대한 액세스를 제공합니다. 이 모델은 라틴 및 CJK 스크립트 전반에 걸쳐 정확한 텍스트 렌더링으로 이미지를 생성 및 편집하며, 포스터, 목업, 인포그래픽을 위한 강력한 구도를 지원합니다. Atlas Cloud에서는 300개 이상의 모델과 함께 하나의 통합된 API를 통해 이에 접근할 수 있으며, 무료 크레딧, 99.99%의 가동 시간을 제공하고 OpenAI 조직 인증이 필요하지 않습니다.
Google의 가장 강력한 크리에이티브 모델은 모두 Atlas Cloud에서 사용할 수 있습니다. Veo 3.1은 영화 수준의 비디오 생성을 제공하고, Nano Banana 2는 고충실도 이미지 생성을 지원하며, Gemini는 모든 워크플로우에 멀티모달 인텔리전스를 제공합니다. Day-0 가용성과 종량제(pay-as-you-go) 요금제로 단일 API key를 통해 전체 Google 모델 제품군에 액세스하세요.
Seedance 2.0 Mini
Seedance 2.0 Mini는 속도와 비용이 가장 중요한 워크플로우에 ByteDance의 멀티모달 비디오 생성 기능을 제공합니다. 더 빠른 생성, 비디오당 더 낮은 비용, 그리고 이미 사용 중인 것과 동일한 API 통합 등 더 가벼운 풋프린트로 Seedance 2.0의 핵심 기능을 제공합니다. 대규모 파이프라인을 운영하거나 대규모 프로토타이핑을 수행하는 팀에게 Mini는 실용적인 기본 선택입니다.
ByteDance
시네마틱 비디오 생성부터 고해상도 이미지 제작까지, ByteDance의 가장 강력한 모델들이 현재 Atlas Cloud에 라이브로 제공됩니다. 가장 낮은 추론 가격과 인프라 오버헤드 없이 대규모로 Seedance와 Seedream을 실행해 보세요.
Alibaba
Atlas Cloud는 Alibaba의 전체 모델 라인업을 단일 API로 통합합니다. 언어 및 이미지 작업을 위한 Qwen, 최대 1080p 비디오 생성을 위한 Wan을 제공합니다. 구독 없이 사용한 만큼만 지불하는(pay-as-you-go) 방식으로 모든 모델에 액세스하세요. Alibaba API는 기존의 OpenAI 호환 클라이언트를 사용하여 단일 기본 URL(base URL)을 통해 사용할 수 있습니다.
OpenAI
Atlas Cloud는 이미지 생성을 위한 GPT Image 2부터 비디오를 위한 Sora 2까지 전체 OpenAI API 라인업에 대한 액세스를 제공합니다. 모든 모델은 월간 약정 없이 종량제로 이용할 수 있습니다. OpenAI 호환 API를 사용하여 기본 URL 하나만 변경하면 쉽게 연동할 수 있습니다.
xAI
Atlas Cloud에서 xAI API를 사용하여 완벽한 이미지 및 비디오 파이프라인을 구축하십시오. 2K 해상도로 생성하고, 참조 이미지로 편집하며, 이미지를 오디오와 동기화된 클립으로 애니메이션화할 수 있습니다.
Kwaivgi
표준 가격보다 15% 저렴한 Kwaivgi API. Atlas Cloud는 종량제 요금과 사용자 수 제한 없이 새로운 Kling 릴리스에 대한 Day-0 액세스를 제공합니다. 단일 계정, 단일 키로 표준에서 마스터 티어에 이르는 모든 Kling 모델을 이용하세요.
Seedream 5.0 Pro
Seedream 5.0 Pro API는 개발자에게 Atlas Cloud에서 ByteDance의 제어 가능한 이미지 편집 모델을 제공합니다. 앵커와 좌표로 편집을 정확하게 배치하고, 이미지를 편집 가능한 레이어로 분리하고, 여러 참조를 융합하며, 정확한 색상과 재질을 일치시키고, 2K 및 3K에서 다국어 텍스트를 지원합니다. Atlas Cloud에서는 단일 키로 액세스할 수 있습니다!


