Gemini Omni Flash API for Conversational Video Editing
Gemini Omni API는 Google I/O 2026에서 공개된 Google DeepMind의 멀티모달 비디오 생성·편집 모델을 여러분의 스택으로 가져옵니다. Gemini Omni는 Gemini의 추론 엔진과 생성형 미디어를 결합해 텍스트, 이미지, 비디오, 오디오를 자유롭게 조합한 입력을 받아 일관되고 지식에 기반한 결과물을 만들어 냅니다. 자연스러운 대화로 결과를 다듬어 보세요. 물리 법칙과 캐릭터, 연속성은 그대로 유지한 채 오브젝트를 교체하고 장면을 다시 쓰고 스타일을 바꿀 수 있습니다. Atlas Cloud는 텍스트-투-비디오, 최대 7장의 참조 이미지를 지원하는 이미지-투-비디오, 참조-투-비디오까지 Gemini Omni Flash 전체 라인업을 하나의 통합 API로 제공하며, $0.112부터 시작하는 투명한 초당 과금에 구독도 필요 없습니다. 지금 바로 개발을 시작하세요.
주요 모델 탐색
Atlas Cloud는 업계 최고의 최신 크리에이티브 모델을 제공합니다.







Gemini Omni Flash API로 생성하는 4가지 방법
텍스트-비디오 변환 및 이미지-비디오 변환부터 참조 기반 생성 및 대화형 편집에 이르기까지 작업에 적합한 Gemini Omni Flash API 엔드포인트를 선택하세요.
| 모달리티 | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | 텍스트 프롬프트만 있으신가요? Gemini Omni Flash Text-to-Video API는 이를 한 번의 처리로 동기화된 오디오가 포함된 720p 클립으로 변환하며, 최대 10초 분량의 영상에 대해 장면, 모션, 카메라 전반에 걸쳐 추론 기반 제어를 따릅니다. |
| Gemini Omni Flash Image-to-Video API (I2V) | Gemini Omni 연산 Flash Image-to-Video API는 원본 이미지를 시작 프레임으로 고정하여 정지 이미지를 동영상으로 애니메이션화합니다. 자연스러운 움직임과 동기화된 오디오를 통해 제품 사진, 인물 사진 및 콘셉트를 720p 해상도로 생생하게 구현합니다. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Gemini Omni Flash Reference-to-Video API를 사용하여 최대 7개의 참조 이미지와 3개의 짧은 비디오 클립으로 생성 과정을 가이드하십시오. 클립 전체에서 캐릭터, 스타일, 장면의 일관성을 유지하므로 브랜드 및 시리즈 콘텐츠에 이상적입니다. |
| Gemini Omni Flash Video Edit API | 클립을 수정해야 할 때, Gemini Omni Flash Video Edit API는 상태 저장(stateful) Interactions API를 통해 자연어 명령을 적용합니다. 턴(turn) 전반에 걸쳐 나머지 영상은 그대로 유지하면서 요소를 교체하고, 조명을 조정하며, 장면의 스타일을 다시 지정합니다. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
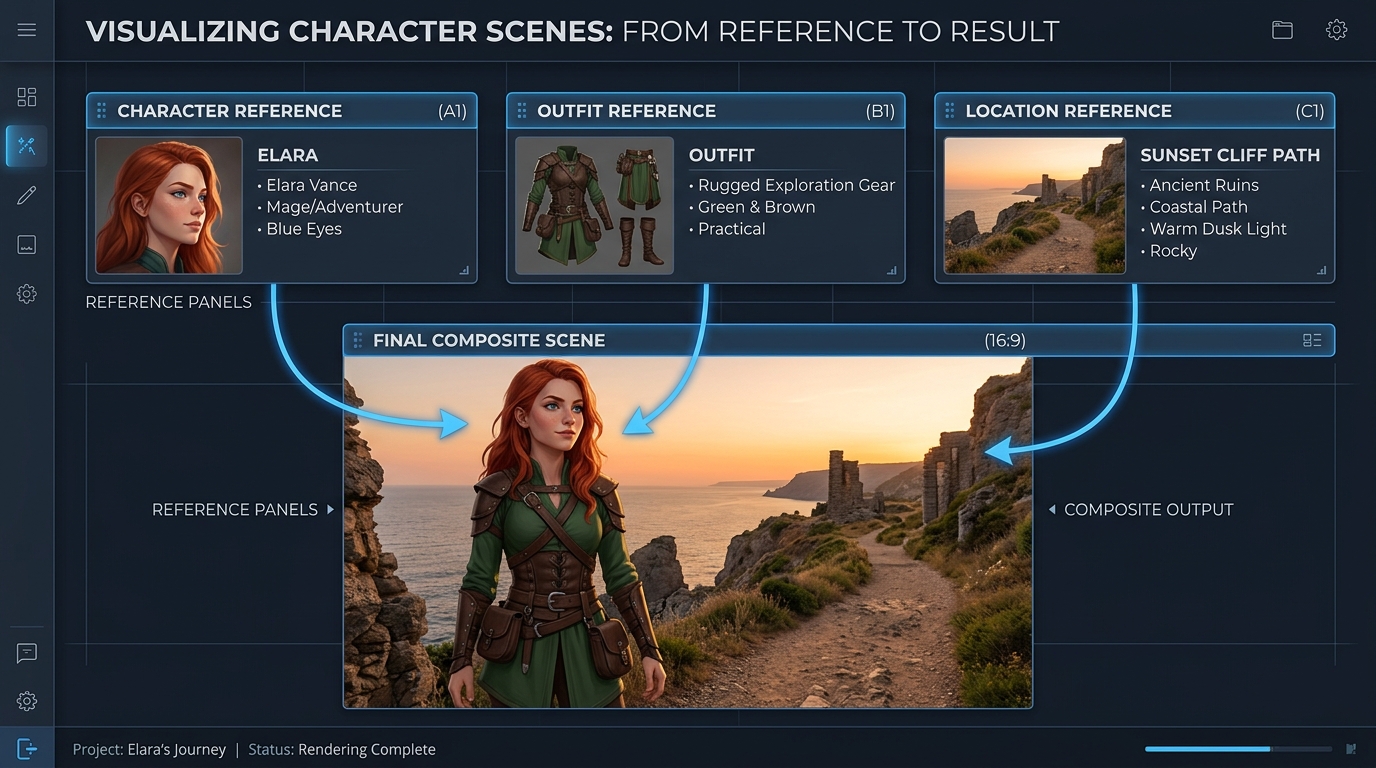
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Gemini Omni Flash API 비교 분석
다양한 프로바이더의 모델 비교 — 성능, 가격, 고유한 강점을 비교하여 현명한 선택을 하세요.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | 대화를 통한 완성된 영상 편집 | Yes | 네, 상태 유지 | 텍스트, 이미지, 비디오, 오디오 |
| Veo 3.1 | 장면 확장 기능을 갖춘 시네마틱 클립 | Yes | No | 텍스트, 이미지, 참조 |
| Seedance 2.0 | 최상급 품질의 레퍼런스 제어 비디오 | Yes | No | 텍스트, 이미지, 비디오, 오디오 |
| Kling 3.0 | 멀티 샷 AI 감독 스토리텔링 | Yes | No | 텍스트, 이미지, 참조 |
Atlas Cloud에서 Gemini Omni Flash 사용하는 방법
몇 분 만에 시작하세요 — 간단한 단계를 따라 Atlas Cloud 플랫폼을 통해 모델을 통합하고 배포하세요.
Atlas Cloud 계정 생성
atlascloud.ai에서 가입하고 인증을 완료하세요. 신규 사용자는 플랫폼 탐색과 모델 테스트를 위한 무료 크레딧을 받습니다.
Atlas Cloud에서 Gemini Omni Flash을(를) 사용하는 이유
고급 Gemini Omni Flash 모델과 Atlas Cloud의 GPU 가속 플랫폼을 결합하여 비교할 수 없는 성능, 확장성 및 개발자 경험을 제공합니다.
성능 및 유연성
낮은 지연 시간:
실시간 추론을 위한 GPU 최적화 추론.
통합 API:
하나의 통합으로 Gemini Omni Flash, GPT, Gemini 및 DeepSeek를 실행합니다.
투명한 가격:
Serverless 옵션을 포함한 예측 가능한 token당 청구.
엔터프라이즈 및 확장
개발자 경험:
SDK, 분석, 파인튜닝 도구 및 템플릿.
신뢰성:
99.99% 가동 시간, RBAC 및 규정 준수 로깅.
보안 및 규정 준수:
SOC 2 Type II, HIPAA 준수, 미국 내 데이터 주권.
Google Gemini Omni Flash API 관련 자주 묻는 질문
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
더 많은 패밀리 탐색
Seedance 2.0
Seedance 2.0 API는 쿼드 모달 입력(텍스트, 이미지, 비디오, 오디오) 및 샷 간의 구도, 카메라 움직임, 캐릭터 액션을 고정하는 업계 최고의 "Universal Reference" 시스템을 갖춘 ByteDance의 멀티모달 비디오 모델에 대한 프로덕션 액세스를 제공합니다. 단 한 번의 API 호출로 디렉터급 제어를 통합하고, 초당 $0.09의 고정 요금, 즉각적인 키 발급 및 대기자 명단 없이 이용할 수 있으며, 엔터프라이즈급 가동 시간과 규정 준수를 보장합니다. Seedance 2.0 Native 4K가 이제 출시되었습니다!
Grok Imagine
Grok Imagine API는 개발자에게 xAI의 이미지, 비디오 및 오디오 생성 기능을 단일 제품군으로 제공합니다. 다국어 텍스트 렌더링이 포함된 최대 2K 해상도의 이미지를 생성하며, 기본 동기화된 오디오 및 참조 기반 편집 기능이 포함된 최대 15초 길이의 비디오를 생성합니다. Atlas Cloud에서는 단일 키로 모든 Grok Imagine 모드를 실행할 수 있으므로 별도의 설정 없이 이미지, 비디오, 오디오 간에 이동할 수 있으며, 요금은 이미지당 $0.02, 초당 $0.05부터 시작합니다.
Gemini Omni Flash
Gemini Omni API는 Google I/O 2026에서 공개된 Google DeepMind의 멀티모달 비디오 생성·편집 모델을 여러분의 스택으로 가져옵니다. Gemini Omni는 Gemini의 추론 엔진과 생성형 미디어를 결합해 텍스트, 이미지, 비디오, 오디오를 자유롭게 조합한 입력을 받아 일관되고 지식에 기반한 결과물을 만들어 냅니다. 자연스러운 대화로 결과를 다듬어 보세요. 물리 법칙과 캐릭터, 연속성은 그대로 유지한 채 오브젝트를 교체하고 장면을 다시 쓰고 스타일을 바꿀 수 있습니다. Atlas Cloud는 텍스트-투-비디오, 최대 7장의 참조 이미지를 지원하는 이미지-투-비디오, 참조-투-비디오까지 Gemini Omni Flash 전체 라인업을 하나의 통합 API로 제공하며, $0.112부터 시작하는 투명한 초당 과금에 구독도 필요 없습니다. 지금 바로 개발을 시작하세요.
GPT Image 2
GPT Image 2 API는 개발자들에게 GPT Image 1.5의 후속 모델인 OpenAI의 최신 이미지 모델에 대한 액세스를 제공합니다. 이 모델은 라틴 및 CJK 스크립트 전반에 걸쳐 정확한 텍스트 렌더링으로 이미지를 생성 및 편집하며, 포스터, 목업, 인포그래픽을 위한 강력한 구도를 지원합니다. Atlas Cloud에서는 300개 이상의 모델과 함께 하나의 통합된 API를 통해 이에 접근할 수 있으며, 무료 크레딧, 99.99%의 가동 시간을 제공하고 OpenAI 조직 인증이 필요하지 않습니다.
Google의 가장 강력한 크리에이티브 모델은 모두 Atlas Cloud에서 사용할 수 있습니다. Veo 3.1은 영화 수준의 비디오 생성을 제공하고, Nano Banana 2는 고충실도 이미지 생성을 지원하며, Gemini는 모든 워크플로우에 멀티모달 인텔리전스를 제공합니다. Day-0 가용성과 종량제(pay-as-you-go) 요금제로 단일 API key를 통해 전체 Google 모델 제품군에 액세스하세요.
Seedance 2.0 Mini
Seedance 2.0 Mini는 속도와 비용이 가장 중요한 워크플로우에 ByteDance의 멀티모달 비디오 생성 기능을 제공합니다. 더 빠른 생성, 비디오당 더 낮은 비용, 그리고 이미 사용 중인 것과 동일한 API 통합 등 더 가벼운 풋프린트로 Seedance 2.0의 핵심 기능을 제공합니다. 대규모 파이프라인을 운영하거나 대규모 프로토타이핑을 수행하는 팀에게 Mini는 실용적인 기본 선택입니다.
ByteDance
시네마틱 비디오 생성부터 고해상도 이미지 제작까지, ByteDance의 가장 강력한 모델들이 현재 Atlas Cloud에 라이브로 제공됩니다. 가장 낮은 추론 가격과 인프라 오버헤드 없이 대규모로 Seedance와 Seedream을 실행해 보세요.
Alibaba
Atlas Cloud는 Alibaba의 전체 모델 라인업을 단일 API로 통합합니다. 언어 및 이미지 작업을 위한 Qwen, 최대 1080p 비디오 생성을 위한 Wan을 제공합니다. 구독 없이 사용한 만큼만 지불하는(pay-as-you-go) 방식으로 모든 모델에 액세스하세요. Alibaba API는 기존의 OpenAI 호환 클라이언트를 사용하여 단일 기본 URL(base URL)을 통해 사용할 수 있습니다.
OpenAI
Atlas Cloud는 이미지 생성을 위한 GPT Image 2부터 비디오를 위한 Sora 2까지 전체 OpenAI API 라인업에 대한 액세스를 제공합니다. 모든 모델은 월간 약정 없이 종량제로 이용할 수 있습니다. OpenAI 호환 API를 사용하여 기본 URL 하나만 변경하면 쉽게 연동할 수 있습니다.
xAI
Atlas Cloud에서 xAI API를 사용하여 완벽한 이미지 및 비디오 파이프라인을 구축하십시오. 2K 해상도로 생성하고, 참조 이미지로 편집하며, 이미지를 오디오와 동기화된 클립으로 애니메이션화할 수 있습니다.
Kwaivgi
표준 가격보다 15% 저렴한 Kwaivgi API. Atlas Cloud는 종량제 요금과 사용자 수 제한 없이 새로운 Kling 릴리스에 대한 Day-0 액세스를 제공합니다. 단일 계정, 단일 키로 표준에서 마스터 티어에 이르는 모든 Kling 모델을 이용하세요.
Seedream 5.0 Pro
Seedream 5.0 Pro API는 개발자에게 Atlas Cloud에서 ByteDance의 제어 가능한 이미지 편집 모델을 제공합니다. 앵커와 좌표로 편집을 정확하게 배치하고, 이미지를 편집 가능한 레이어로 분리하고, 여러 참조를 융합하며, 정확한 색상과 재질을 일치시키고, 2K 및 3K에서 다국어 텍스트를 지원합니다. Atlas Cloud에서는 단일 키로 액세스할 수 있습니다!


