Gemini Omni representa uma mudança significativa em relação aos sistemas de IA tradicionais. Ele funciona como um modelo de IA tudo-em-um que processa informações naturalmente desde o início. Em vez de conectar diferentes ferramentas para diferentes tipos de mídia, ele é executado inteiramente em um único mecanismo neural universal. Ao processar texto, imagem, áudio e vídeo dentro de um espaço vetorial multimodal singular, ele elimina completamente os silos de dados legados e os gargalos de comunicação.
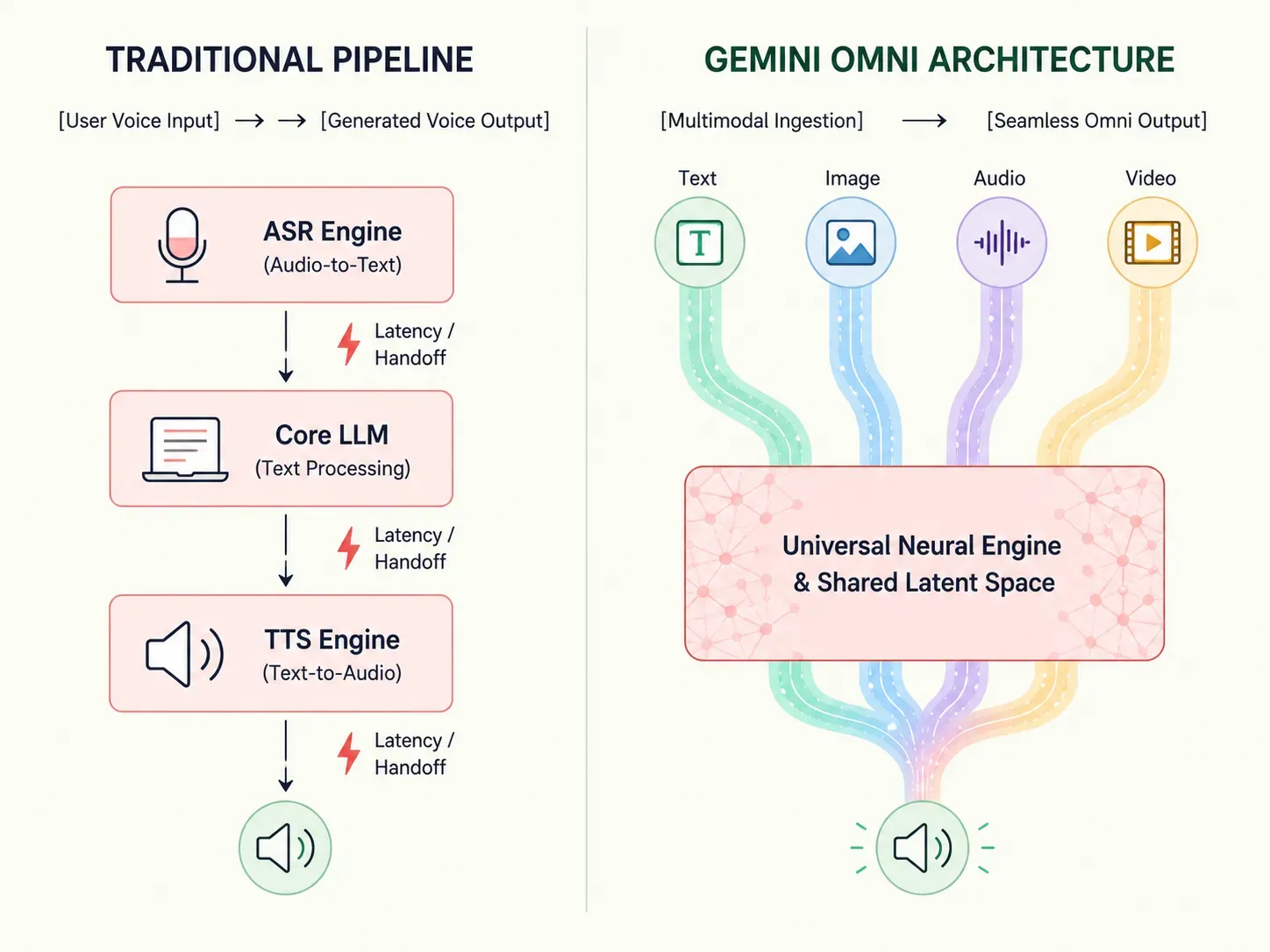
A inteligência artificial tradicional depende de pipelines escalonados — convertendo voz em texto antes mesmo que um modelo de linguagem possa começar a processar uma resposta. O Gemini Omni redefine fundamentalmente esse fluxo de trabalho.
- Ingestão Nativa: O sistema processa tokens de texto, pixels de imagem, frequências de áudio e quadros de vídeo ao mesmo tempo.
- Preservação de Contexto: O processamento de dados de ponta a ponta evita que emoções sutis, pistas visuais e pequenos detalhes se percam entre diferentes camadas.
Essa mudança estrutural aumenta a eficiência do processamento e reduz os atrasos para tempos de resposta quase humanos. Desenvolvedores e empresas agora podem ignorar configurações complexas de múltiplos modelos e confiar em um sistema sólido construído para a verdadeira computação multissensorial.
Como um modelo computa quatro modalidades simultaneamente
Para entender como os recursos do Gemini Omni processam texto, imagens, áudio e vídeo exatamente ao mesmo tempo, precisamos olhar diretamente para sua camada central de dados. Sistemas tradicionais direcionam diferentes tipos de arquivos através de submodelos isolados e separados. O Gemini Omni ignora completamente esse método fragmentado. Ele implementa uma estrutura de tokenização unificada que traduz nativamente todas as entradas para uma linguagem singular que o núcleo da IA compreende.
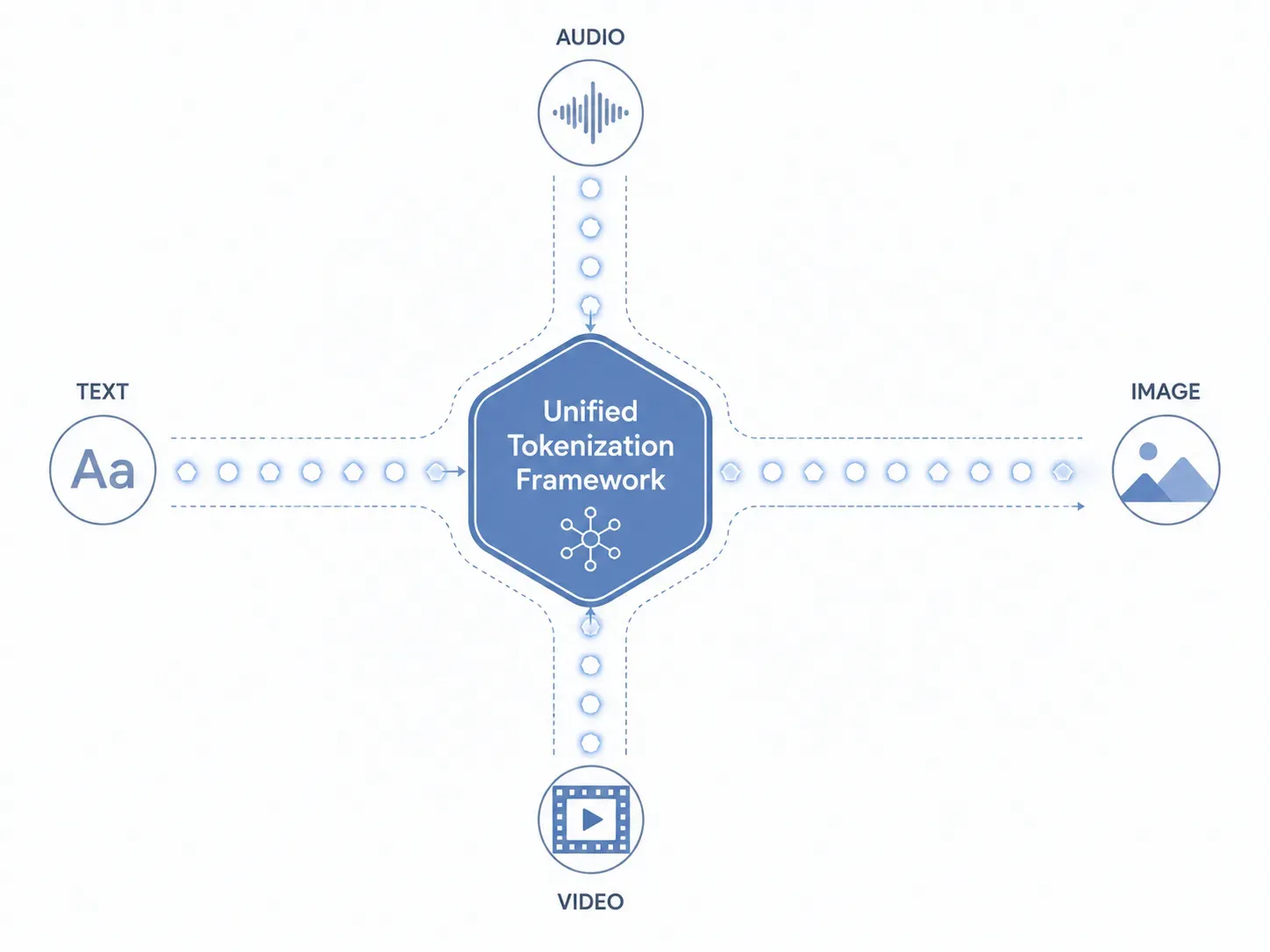
A mecânica da tokenização unificada
Como o Gemini Omni lida com diferentes tipos de arquivos sem submodelos separados? A resposta reside em como os dados são ingeridos e divididos antes que a inferência comece:
- Texto: Caracteres alfanuméricos são convertidos em tokens de texto semântico padrão.
- Imagens: Elementos visuais são fatiados em pequenos blocos de pixels e mapeados como tokens visuais.
- Áudio: Ondas sonoras contínuas são amostradas, capturando frequência e tom, e transformadas em tokens acústicos.
- Vídeo: Imagens em movimento são tratadas como uma sequência contínua de quadros temporais, estabelecendo tokens espaço-temporais.
Pesos compartilhados e processamento nativo de tensores
Uma vez que essa ingestão multimodal de dados diversa é concluída, todos os tipos de dados entram em uma arquitetura de pesos compartilhados. Em vez de usar codificadores especializados individuais que passam dados de um lado para o outro sobre pontes que causam latência, uma única rede neural central processa todos os tokens uniformemente.
Usando processamento nativo de tensores, o modelo executa cálculos matemáticos em tokens de texto, áudio e visuais dentro das mesmas camadas matriciais. Como tudo compartilha o mesmo espaço computacional, a rede compreende diretamente a relação entre uma palavra falada, uma frase escrita, um pixel de imagem e um quadro de vídeo sem uma única etapa de tradução.
Para ver esses princípios de engenharia e tokenização nativa implantados em escala em cenários do mundo real, assista à Apresentação da Visão de Pesquisa do MIT Media Lab. Esta apresentação descreve a mudança da indústria a longo prazo em direção à conexão direta de modelos de IA com um rico espectro de sinais do mundo físico e multissensorial:
Os pilares centrais da modalidade: Mapa de processamento cross-media
Para realmente compreender o poder do Gemini Omni, é preciso ir além da simples ingestão de dados. O modelo utiliza uma arquitetura unificada onde texto, imagens, áudio e vídeo existem dentro de um mapeamento de espaço latente compartilhado. Quando uma entrada muda em uma modalidade, ela não apenas dispara uma reação isolada — ela altera dinamicamente os parâmetros matemáticos dos outros três formatos ao mesmo tempo.
A matriz de interdependência multimodal
Essa inferência cross-media em tempo real depende de fluxos de dados interdependentes. Em vez de processar dados em blocos sequenciais, o modelo sincroniza continuamente todos os quatro pilares para alcançar um alinhamento multimodal impecável.
O mapa de processamento abaixo descreve exatamente como essas entradas ao vivo influenciam umas às outras dentro da rede neural universal:
| Entrada de Mídia Primária | Modalidades Co-processadas | Operação do Sistema | Intenção Técnica Profunda |
| Formas de Onda Acústicas | Texto + Quadros de Vídeo | Rastreia a cadência da voz para indexar sequências de vídeo temporais | Alinhamento sensorial em tempo real |
| Imagens Estáticas | Áudio Bruto + Texto | Traduz espectros de cores visuais em acústica contextual correspondente | Síntese cross-modal |
| Código Alfanumérico | Matrizes de Vídeo + Texto | Modifica variáveis de vídeo estruturais diretamente via lógica de programação | Execução de código generativo |
| Sequências de Vídeo Temporais | Trilhas de Áudio + Código | Computa atualizações espaço-temporais em trilhas de dados multicamadas | Análise unificada de vídeo-áudio |
Sincronização de parâmetros em tempo real em ação
Quando o Gemini Omni processa um feed de vídeo ao vivo, ele não separa o visual da trilha de fundo. Se a entrada de áudio registra um pico repentino de frequência — como uma pessoa gritando — o modelo atualiza instantaneamente suas expectativas de tokens visuais. Ele antecipa movimentos físicos rápidos ou uma mudança nos quadros de vídeo antes mesmo que eles ocorram.
Essa influência cruzada profunda evita o desvio de contexto. Como toda a rede equilibra essas variáveis simultaneamente, a saída permanece perfeitamente coerente, esteja o modelo gerando um resumo de vídeo sincronizado ou traduzindo um fluxo multissensorial ao vivo.
Eliminando latência e desvio de contexto: A vantagem dos pesos unificados
Para apreciar a velocidade do Gemini Omni, ajuda observar as ineficiências matemáticas dos pipelines de IA "costurados" tradicionais. Historicamente, construir um assistente capaz de lidar com voz ou vídeo exigia encadear camadas de software separadas e de propósito único.
plaintext1[Entrada de voz do usuário] 2 │ 3 ▼ 4 1. Mecanismo ASR (Transcrição de Áudio para Texto) 5 │ 6 ▼ 7 2. Camada LLM Central (Processamento de Geração de Texto) 8 │ 9 ▼ 10 3. Mecanismo TTS (Síntese de Texto para Áudio) 11 │ 12 ▼ 13[Saída de voz gerada]
Essa orquestração em várias etapas força os dados a viajar através de pontes de software contínuas, aumentando os atrasos de execução. O mecanismo de texto para fala separado não consegue "ouvir" a gravação de áudio original. Isso causa uma enorme perda de dados entre diferentes tipos de mídia. Pistas vocais importantes, como o tom sarcástico de um usuário, hesitações ou sofrimento emocional, desaparecem completamente quando tudo é nivelado em texto simples.
Realizando a redução real de latência do pipeline
O Gemini Omni contorna esses limites operando com pesos neurais unificados. Como uma única rede neural avalia nativamente texto, áudio e pixels sob o mesmo teto matemático, ela escala as velocidades de execução dramaticamente. Esse layout gera uma profunda redução de latência do pipeline.
De acordo com relatórios de benchmarking do Google DeepMind, arquiteturas multimodais nativas executando fluxos de áudio ao vivo reduzem os tempos de resposta de ponta a ponta para menos de 150 milissegundos. Essa mudança corresponde efetivamente ao ritmo natural da conversação humana em tempo real.
Otimização da retenção de contexto
Além da velocidade pura, a execução unificada garante um alto nível de otimização da retenção de contexto. Quando você fala com o modelo, os pesos processam suas frequências de áudio juntamente com suas definições textuais simultaneamente.
- Processamento de Entonação: A rede captura modulações vocais diretamente, respondendo com a empatia ou urgência apropriada.
- Sincronização Visual: Microexpressões faciais sutis ou movimentos espaciais dentro de um quadro de vídeo traduzem-se diretamente na saída conversacional sem erros de análise.
Ao remover etapas intermediárias de tradução, o Gemini Omni evita que pequenos detalhes desapareçam. Isso constrói uma base sólida para interações suaves e naturais entre diferentes sentidos entre humanos e máquinas.
Construindo fluxos de trabalho empresariais com sistemas de IA Omni-Channel
Essa mudança em direção à multimodalidade nativa altera a forma como as empresas constroem e escalam ferramentas digitais. Usando uma configuração de IA única e tudo-em-um, as empresas podem substituir peças de software desordenadas e separadas por fluxos de trabalho unificados. Isso permite que executem sistemas interativos de mídia mista facilmente em larga escala.
A arquitetura de API única
Os desenvolvedores não precisam mais coordenar funções de nuvem díspares para reconhecimento de fala, análise de texto e processamento de imagem. Em vez disso, uma única integração de API unificada conecta a camada de aplicativo diretamente à rede central, como a API do modelo Atlas Cloud AI. Esse caminho simplificado permite que as equipes construam pipelines cross-media avançados com uma estrutura de solicitação única.
plaintext1 ┌─────────────────────────────────┐ 2 │ API Gemini Unificada │ 3 └────────────────┬────────────────┘ 4 │ 5 ┌─────────────────────────┼─────────────────────────┐ 6 ▼ ▼ ▼ 7┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ 8│ Código em Tempo │ │ Camada de Automa-│ │ Painéis Multi- │ 9│ Real & Sincronia │ │ ção de Mídia │ │ sensoriais │ 10└──────────────────┘ └──────────────────┘ └──────────────────┘
Por exemplo, uma plataforma de treinamento empresarial pode processar um fluxo de vídeo ao vivo, rastrear a cadência de áudio de um palestrante, traduzir o diálogo e atualizar dinamicamente um painel de dados visual simultaneamente — tudo impulsionado por um único sistema de backend.
Vantagens de implantação estratégica
Quais são as vantagens de implantação ao mudar para uma arquitetura de modelo tudo-em-um?
Mudar de configurações antigas de múltiplos modelos para uma única rede neural oferece benefícios imediatos e sólidos para sistemas de TI empresariais:
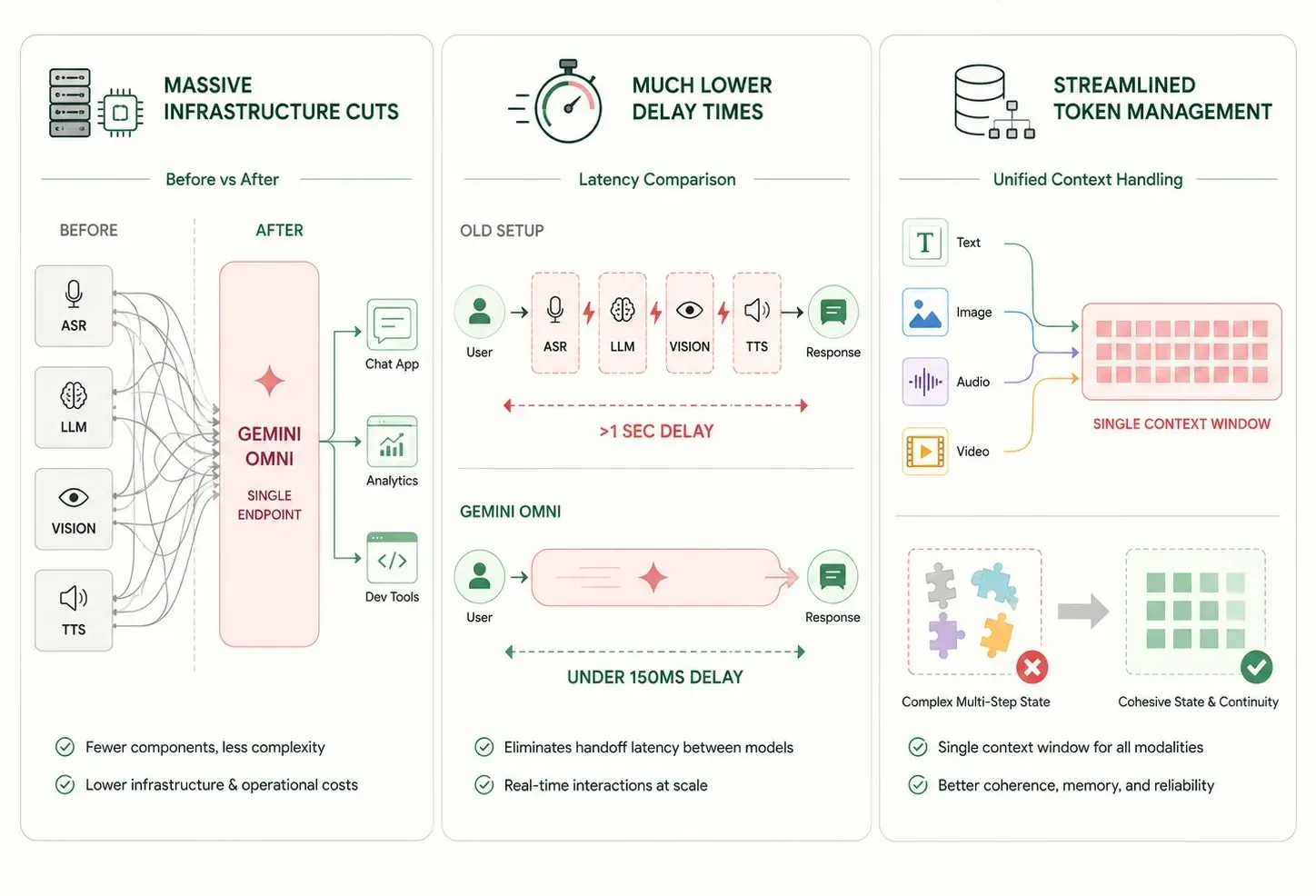
- Cortes Massivos de Infraestrutura: Colocar tarefas de texto, visão e som em um único modelo reduz o número de terminais de software separados. Isso torna a manutenção a longo prazo muito mais fácil.
- Tempos de Atraso Muito Menores: Pular etapas extras de rede entre ferramentas pequenas e especializadas reduz os tempos de resposta para menos de um segundo. Isso permite experiências de usuário verdadeiramente em tempo real.
- Gerenciamento de Tokens Simplificado: Uma única janela de contexto que rastreia todas as modalidades uniformemente reduz problemas complexos de gerenciamento de estado em processos de várias etapas.
Alcançando implantação multimodal escalável
Operando através de estruturas como a Plataforma de Agentes Empresariais Gemini, as empresas podem coordenar perfeitamente redes de subagentes autônomos. Este sistema único torna fácil executar projetos de multimídia em larga escala. Ele usa configurações gerenciadas que rastreiam o contexto de fundo e a identidade do usuário em fluxos de trabalho que duram dias. Mantendo diferentes entradas em um espaço seguro, as empresas podem automatizar tarefas em diferentes mídias do início ao fim sem perder dados ou perder o controle do tópico principal.
Restrições computacionais e otimização de hardware para inferência global de IA
Embora processar quatro fluxos de dados separados sob uma arquitetura de rede unificada desbloqueie fluxos de trabalho cross-media contínuos, isso também introduz demandas sem precedentes na infraestrutura de hardware moderna. Navegar neste ambiente requer um gerenciamento meticuloso de recursos de computação para superar as penalidades físicas extremas associadas ao processamento multissensorial simultâneo em escala global.
A sobrecarga da tokenização multimodal
O principal desafio de engenharia decorre da sobrecarga de tokens multimodais. Ao contrário dos conjuntos de dados de texto alfanumérico padrão, imagens de alta definição, frequências de áudio brutas e arquivos de vídeo sequenciais geram quantidades massivas de dados numéricos.
- Processamento de Texto: Uma única página de escrita transforma-se em aproximadamente 1.000 tokens significativos densos.
- Processamento Visual: Um minuto de filmagem de vídeo bruto, quando cortado em etapas de quadro constantes e blocos de pixels, divide-se em centenas de milhares de tokens visuais.
Quando um único núcleo de modelo processa esses tipos de mídia juntos, isso causa um aumento exponencial na densidade da janela de contexto. O mecanismo de Atenção do sistema deve avaliar como cada token se relaciona com todos os outros tokens, ameaçando sobrecarregar a Memória de Alta Largura de Banda (HBM) no chip e saturar as camadas de processamento.
Acelerando cargas de trabalho via escalonamento de clusters TPU
Para combater esse gargalo, as infraestruturas empresariais dependem de plataformas de hardware especializadas projetadas especificamente para computação multissensorial. A arquitetura mais recente do Google utiliza escalonamento de clusters TPU para distribuir essas cargas de trabalho de token unificadas e intensivas em ambientes de data center multicamadas.
plaintext1 ┌─────────────────────────┐ 2 │ Tokens Gemini Unificados│ 3 └────────────┬────────────┘ 4 │ 5 ┌───────────────────────┴───────────────────────┐ 6 ▼ ▼ 7┌─────────────────────────────────┐ ┌─────────────────────────────────┐ 8│ Matriz TensorCore │ │ Matriz TensorCore │ 9│ (Aritmética de Matriz Paralela)│ │ (Aritmética de Matriz Paralela)│ 10└────────────────┬────────────────┘ └────────────────┬────────────────┘ 11 │ │ 12 └───────────────┬───────────────────────┘ 13 ▼ 14 ┌─────────────────────────┐ 15 │ Interconexão Óptica │ 16 │ (ICI de Ultra-Baixa │ 17 │ Latência) │ 18 └─────────────────────────┘
Configurações de hardware como a plataforma Trillium TPU v6e oferecem um aumento impressionante de 4,7x no desempenho de computação de pico por chip em comparação com gerações de hardware mais antigas. Essa arquitetura especializada lida com essas demandas massivas combinando unidades de execução de matriz otimizadas com layouts de infraestrutura física profunda:
| Camada do Mecanismo de Hardware | Especificações Arquiteturais | Função Central do Sistema |
| Matrizes TensorCore Expandidas | Dobro da área da Unidade de Multiplicação de Matriz (MXU) | Executa aritmética paralela intensiva em tensores de vídeo densos. |
| HBM de Alta Largura de Banda | Até 32 GB de HBM por chip | Aloja matrizes de tokens massivas inteiramente em silício para evitar gargalos de memória. |
| Interconexão Chip-a-Chip de Próxima Geração | Largura de banda bidirecional de 800 GBps | Sincroniza variáveis de parâmetros em dezenas de milhares de chips sem atraso. |
Utilizando tecido de rede óptica personalizado ao lado dessas configurações de memória profunda, as infraestruturas de nuvem podem escalar dinamicamente para lidar com parâmetros de entrada de milhões de tokens. Isso permite que as empresas implantem agentes de IA avançados e em tempo real globalmente sem arriscar travamentos de memória ou falhas de tempo de execução do sistema.
Uma API unificada para geração de vídeo em produção
Enquanto o Google lança o Gemini Omni Flash dentro do aplicativo Gemini e do Google Flow para usuários finais, desenvolvedores e equipes de produto que desejam incorporar o mesmo mecanismo de vídeo multimodal em seus próprios fluxos de trabalho precisam de uma camada de API estável e previsível.
A Atlas Cloud disponibiliza o Gemini Omni Flash através de uma API unificada e compatível com OpenAI, juntamente com mais de 300 outros modelos de imagem, vídeo e LLM — para que você possa integrar o modelo multimodal nativo do Google sem ter que gerenciar contas de fornecedores, portais de faturamento ou SDKs separados.
Ambas as variantes do Gemini Omni Flash estão ativas na Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Melhor Para | Entradas | Resolução | Duração | Preço Inicial |
| Gemini Omni Flash Text-to-Video (Developer) | Geração cinematográfica puramente baseada em prompt | Texto (até 20.000 caracteres) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
| Gemini Omni Flash Image-to-Video (Developer) | Vídeo consistente com o assunto a partir de referências reais | Texto + até 7 imagens de referência | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
Início rápido — Gere um vídeo Gemini Omni Flash em 5 linhas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "Uma floresta enevoada na hora dourada, tomada cinematográfica dolly", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
A API retorna um ID de previsão imediatamente — consulte /api/v1/model/prediction/{id} para obter a URL do MP4 renderizado. O esquema completo, exemplos de código em 7 linguagens e um Playground sem código estão disponíveis nas páginas dos modelos vinculadas acima.
Conclusão: Preparando-se para a Inteligência de Máquina Unificada
A chegada do Gemini Omni altera fundamentalmente os paradigmas de design dos desenvolvedores, mudando a indústria de conectar ferramentas separadas para implantar soluções unificadas de camada única. Em vez de gerenciar pontes de integração complexas entre APIs isoladas, os engenheiros agora podem confiar em estruturas de aprendizado de máquina de próxima geração que processam naturalmente fluxos de dados interdependentes sob um único teto matemático.
plaintext1[Pipeline de Software Legado] 2API de Texto Separada ──┐ 3API de Áudio Separada ─┼──► Blocos de Pipeline Manuais ──► Produção Frágil 4API de Vídeo Separada ──┘ 5 6[Arquitetura Omni Unificada] 7Tokens Universais ──► Modelo de Camada Única Nativo ──► Automação Contínua
Essa mudança estrutural exige uma revisão completa de como construímos produtos digitais. Para permanecer competitivas, as equipes técnicas devem abandonar os silos de dados estáticos e preparar ecossistemas de software padrão para sistemas multissensoriais nativos.
Operando diretamente em um backbone de nuvem altamente otimizado como a infraestrutura do Google Cloud AI, as empresas podem escalar essas cargas de trabalho de tokens intensivas sem arriscar desvio de contexto sistêmico ou penalidades de latência. Em última análise, preparar seu pipeline de desenvolvimento para o futuro significa projetar soluções em torno de um mecanismo singular e coeso construído para compreender o mundo físico de forma holística.






