
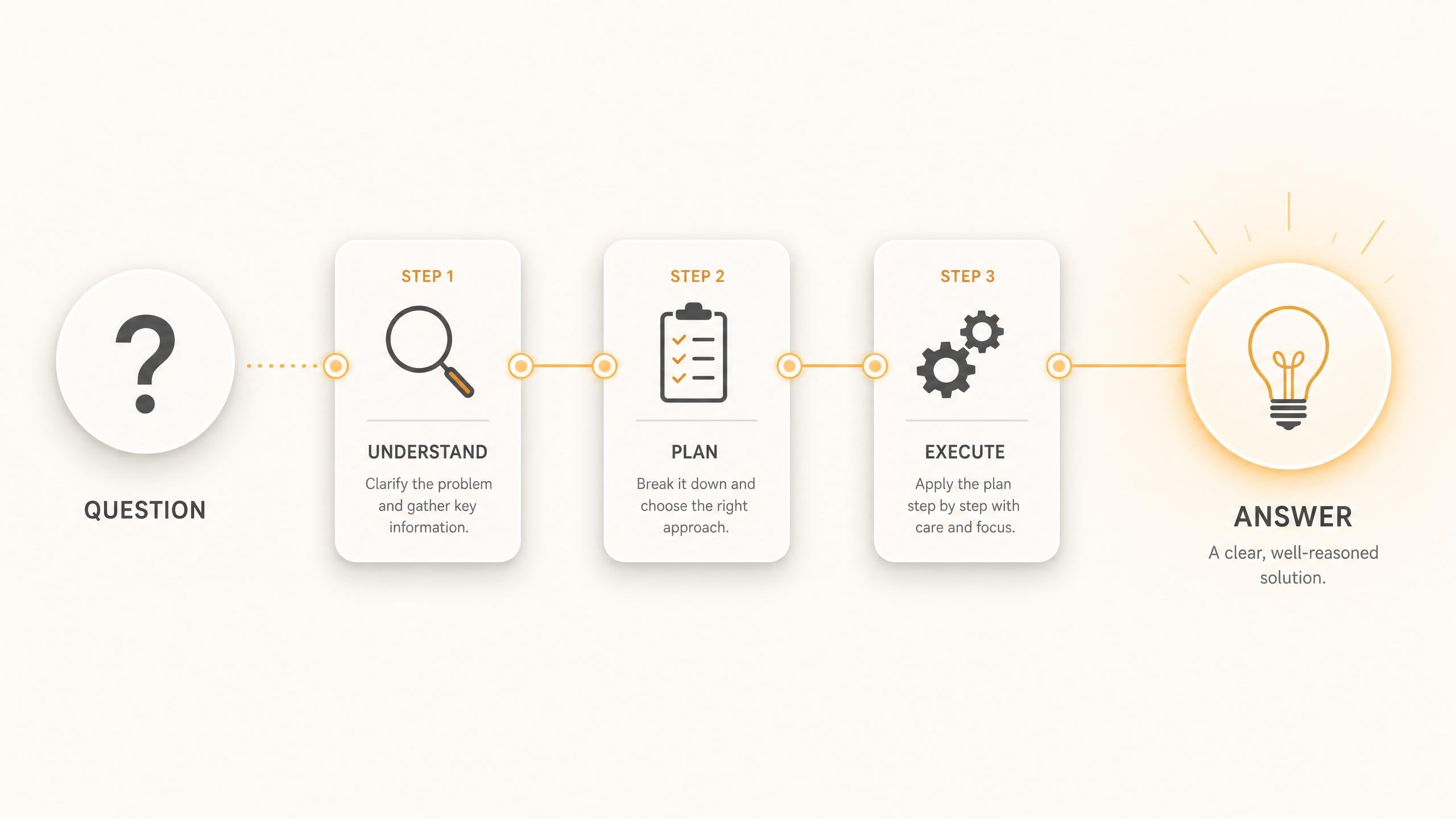
Grok API: xAI Reasoning and Coding Models
由 xAI 開發的 Grok 是一系列圍繞即時感知和前沿級推理構建的大型語言模型。Grok 4.3 是 xAI 的高級對話模型,針對自然對話、知識探索以及跨 1,000,000 個 token 上下文窗口的多步推理進行了優化。Grok Build 0.1 則採用了不同的方向——它專為軟體開發而構建,其功能集中在複雜開發者工作流中的代碼生成、調試和重構上。這兩種模型均可透過兼容 OpenAI 的 API 端點在 Atlas Cloud 上使用,起價為每百萬 token 1美元。
探索領先模型
Atlas Cloud 為您提供最新的行業領先創意模型。


比較 Grok API 模型
Match each job to the right model: Grok 4.3 for reasoning across a 1M token context and Grok Build 0.1 for agentic coding, both reachable through one OpenAI-compatible key on Atlas Cloud.
| Model | Type | Best For | Context | Inputs | Function Calling | Structured Outputs | Prompt Caching | Status |
|---|---|---|---|---|---|---|---|---|
| Grok 4.3 | Flagship reasoning model | Logic, analysis, multi-step agents, long-document work | 1M tokens | Text, image | Yes | Yes | Yes | Flagship, GA |
| Grok Build 0.1 | Coding-focused model | Code generation, debugging, refactoring, coding agents | 256K tokens | Text, image | Yes | Yes | Yes | Early access |
Grok API Features
The Grok API brings xAI's reasoning and coding models to Atlas Cloud with a 1M token context window, always-on reasoning, function calling, structured outputs, vision input, and prompt caching, all behind one OpenAI-compatible key.

1M Token Context Window
Grok 4.3 handles up to one million tokens in a single request, enough for full contract sets, large codebases, or long multi-turn agent sessions. The wide context removes chunked retrieval and preserves cross-document reasoning that shorter models lose.
Always-On Reasoning with the Grok API
The Grok API runs Grok 4.3 with built-in step-by-step reasoning, tuned for accuracy-critical work like logic, math, and multi-step analysis. The model thinks before it answers, which lifts factual reliability and instruction following on complex prompts.
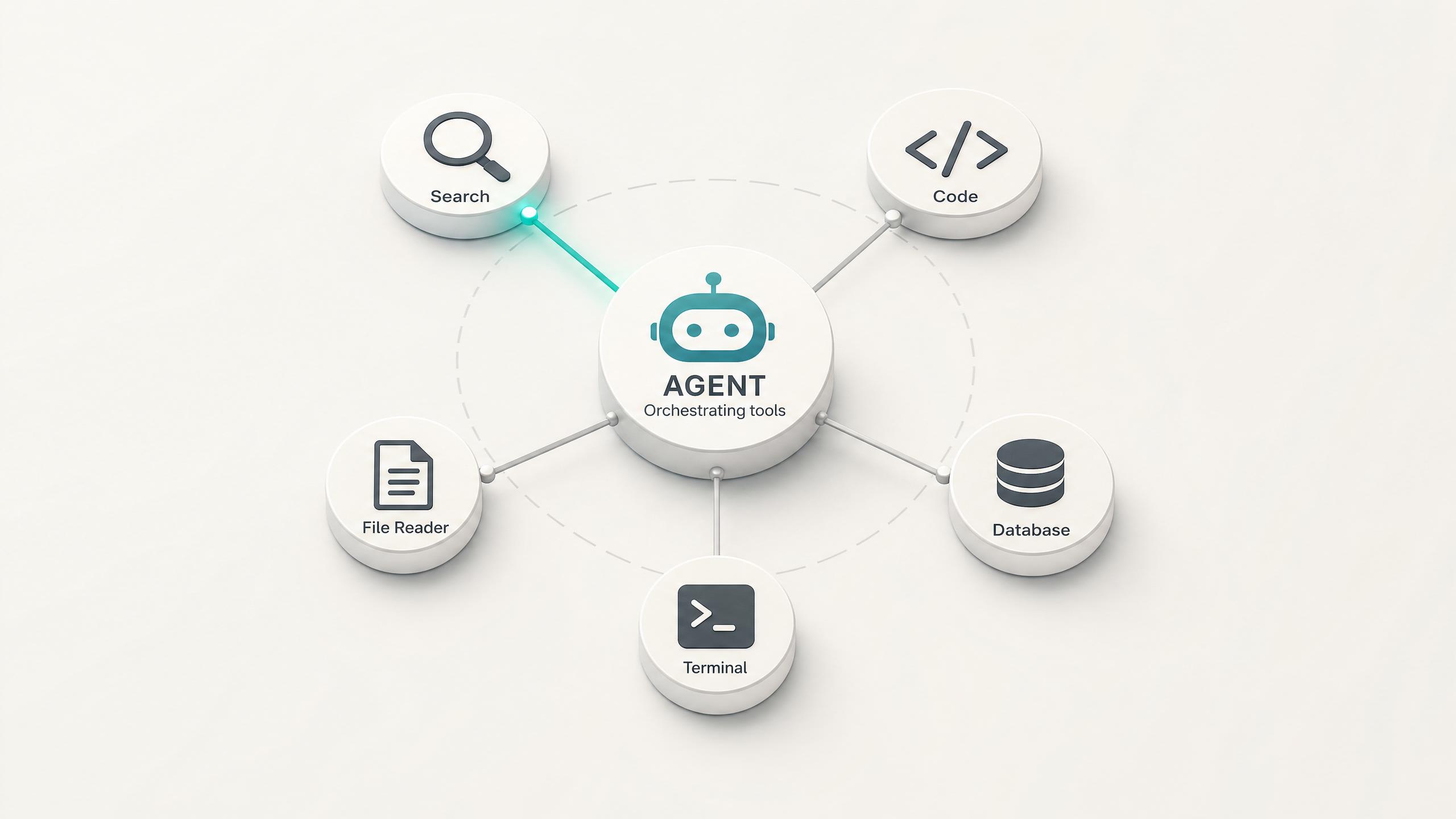
Agentic Tool Calling
Grok 4.3 is built for agents: it plans, calls functions in sequence, and adjusts on intermediate results. Native function calling lets it trigger tools and APIs mid-task, the foundation for research agents, support bots, and automation that runs without a human in the loop.
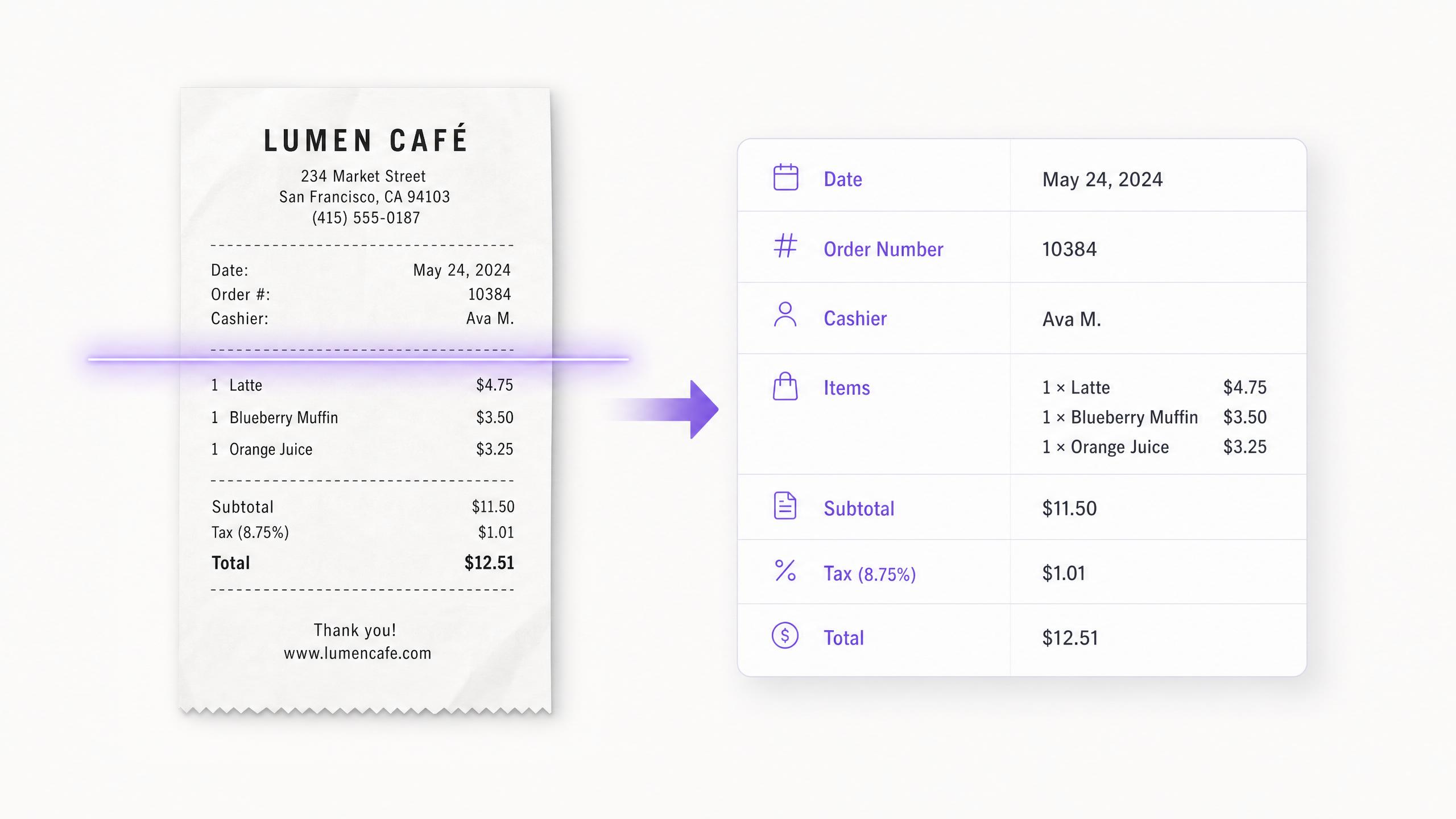
Structured Outputs and Vision with the Grok API
The Grok API returns structured JSON that matches your schema, so extracted data flows straight into downstream code. Grok 4.3 also accepts images alongside text, handling diagrams, screenshots, and UI mockups in the same call.

Coding with Grok Build 0.1
Grok Build 0.1 is xAI's coding-tuned model for code generation, debugging, and refactoring across developer workflows, with a 256K token context. It targets interactive coding agents and multi-step development tasks rather than general chat.

Prompt Caching on the Grok API
The Grok API supports prompt caching, which reuses a shared system prompt or context prefix at a lower token rate. For agentic loops that send the same instructions across many calls, this cuts repeated input cost without changing your code.
跨模型單一建構提示詞
將相同的建置提示詞交給Grok和Atlas Cloud上的其他模型,觀察它們分別產生一個完整、可執行的網頁,以便您並排比較它們的程式碼風格與輸出結果。
建立一個單一且獨立的 HTML 檔案,展示一個使用透過 CDN 引入的 Three.js 製作的互動式 3D 太陽系。渲染太陽和八顆環繞行星,透過顏色和發光效果模擬紋理,並包含軌道動畫和星空背景。允許使用者使用滑鼠旋轉和縮放相機,點擊行星時相機平滑拉近並顯示其統計資料。加入優雅的疊加標題以及用於加速或減緩時間的控制項。確保所有程式碼與 Three.js 的 CDN 引入都保存在同一個 HTML 檔案中。優先呈現令人驚豔的電影級視覺效果。
Grok 4.3
GLM 5
Grok Build 0.1
建立一個單一的、自包含的 HTML 檔案,該檔案是一個動畫分析儀表板。包含一個動畫長條圖、一個在載入時自動繪製的折線圖、一個環形圖以及數字遞增的摘要統計卡片。使用硬編碼的樣本資料、平滑的入口動畫以及簡潔現代的深色儀表板佈局。在每個圖表元素上加入微妙的懸停提示框。僅使用內聯 CSS 和帶有 canvas 或 SVG 的原生 JavaScript,不使用任何外部函式庫。使其看起來像一個高級的 SaaS 儀表板。
Grok 4.3
GLM 5
Grok Build 0.1
您在 Atlas Cloud 上使用 Grok LLM API 可以做什麼
Grok 4.3 將 100萬 Token 的上下文視窗與即時的網路及 X 搜尋相結合,使其非常適合需要最新資訊與深度推理的生產工作流程。

即時研究與智能管線
構建研究工具的團隊使用 Grok 4.3 的 Web Search 和 X Search 附加元件,將來自網路和 X 的即時數據直接提取到生成過程中,而無需單獨的檢索層。這對於競爭分析、新聞摘要和市場情報工作流程非常有用,因為這些工作流程的答案取決於模型訓練截止日期之後發布的資訊。在 xAI API 上,Web Search 和 X Search 的計費標準為每 1,000 次呼叫 5 美元。

高性價比生產級LLM後端
從 GPT-4.1 或 Claude Sonnet 切換的工程團隊,透過 Atlas Cloud 的 OpenAI-compatible 端點,將 Grok 4.3 作為隨插即用的替代方案。Grok 4.3 的輸入價格為每百萬輸入 tokens 1.25 美元,比 GPT-4.1 便宜約 37%,比 Claude Sonnet 4.6 便宜 58%。該遷移過程僅需在現有 SDK 程式碼中變更 base URL 和 API 金鑰。

100萬上下文長文件分析
法務、財務和研究團隊利用 Grok 4.3 的 100 萬 Token 上下文視窗,在單次 API 呼叫中處理完整的合約集、財務文件或技術文件。大上下文消除了對分塊檢索管線的需求,並保留了在短上下文模型中容易遺失的跨文件推理能力。當相同的文件上下文在多次分析呼叫中被重複使用時,提示詞快取可進一步降低成本。

多模態編程與視覺分析
開發者利用 Grok 4.3 的圖像理解功能,在同一次 API 呼叫中將圖表、螢幕截圖、UI 模型和錯誤日誌與文本一起傳遞。這對於除錯工作流程非常有用,因為錯誤截圖或系統架構圖能提供單靠文本無法提供的上下文。同一次呼叫支援函數呼叫和結構化輸出,因此提取的視覺數據可以按照準備好供下游處理的結構描述返回。

代理式多步任務執行
產品團隊利用 Grok 4.3 的代理優化功能來建構代理程式,使其能夠在沒有人工提示的情況下,跨多個步驟進行計畫、執行和迭代。該模型專為複雜的任務分解而調優——將高階目標分解為子任務,按順序呼叫工具,並根據中間結果進行調整。結合函數呼叫和 Web Search 附加元件,它能在單次代理運行中完成從研究到輸出的工作流程,例如「查找競爭對手、分析定價、草擬比較報告」。

針對資料分析的上下文程式碼執行
數據和分析團隊使用帶有 Code Execution 附加元件的 Grok 4.3,直接在推理呼叫中執行 Python、處理數據,並將計算結果與模型的推理過程一併返回。這消除了在建構數據分析工具或自動化報告流水線時對獨立程式碼執行環境的需求。在 xAI API 上,Code Execution 的計費標準為每 1,000 次呼叫 5 美元,與 token 成本分開計算。
Grok API 比較分析
查看 Grok API 在 Atlas Cloud 上如何依上下文、輸入和側重點與其他領先的 LLMs 進行比較,以便您可以將每項任務路由到最適合的模型,所有操作均透過單一金鑰完成。
| Model | Provider | Context Window | Inputs | Best For |
|---|---|---|---|---|
| Grok 4.3 | xAI | 1M tokens | Text | Agentic reasoning, long-document analysis, high factual accuracy |
| Grok Build 0.1 | xAI | 256K tokens | Text | Code generation, debugging, refactoring |
| DeepSeek V4 Pro | DeepSeek | 1M tokens | Text | Cost-efficient reasoning and agentic tool use at scale |
| Kimi K2.6 | Moonshot | 262K tokens | Text, image | Long-horizon coding agents and multimodal workflows |
| GLM 5.2 | Z.ai | 202.8K tokens | Text | Long-horizon agentic engineering and project-scale coding |
如何在 Atlas Cloud 上使用 Grok
幾分鐘即可上手 — 按照以下簡單步驟,透過 Atlas Cloud 平台整合和部署模型。
建立 Atlas Cloud 帳戶
在 atlascloud.ai 註冊並完成驗證。新用戶可獲得免費額度,用於探索平台和測試模型。
為何在 Atlas Cloud 使用 Grok
將先進的 Grok 模型與 Atlas Cloud 的 GPU 加速平台相結合,提供無與倫比的效能、可擴展性和開發體驗。
效能與靈活性
低延遲:
GPU 最佳化推理,實現即時回應。
統一 API:
一次整合,暢用 Grok、GPT、Gemini 和 DeepSeek。
透明定價:
按 Token 計費,支援 Serverless 模式。
企業與規模
開發者體驗:
SDK、資料分析、微調工具和模板一應俱全。
可靠性:
99.99% 可用性、RBAC 權限控制、合規日誌。
安全與合規:
SOC 2 Type II 認證、HIPAA 合規、美國資料主權。
關於 Grok LLM 的常見問題解答
Atlas Cloud 託管了 xAI 目前的旗艦 LLM Grok 4.3,價格為每百萬輸入 token 1.25 美元。該模型在單一 API 中支援聊天、推理、函式呼叫、結構化輸出和圖像理解。請隨時查看 Atlas Cloud xAI 集合頁面,以獲取後續新增的任何其他 Grok 版本。
Grok 4.3 支援 100 萬 token 的上下文視窗。這足以在單次呼叫中處理完整的程式碼庫、冗長的研究文件或擴展的多輪代理會話。此上下文限制適用於文字和圖像輸入的組合。
是的。xAI API 支援將 Web Search 和 X Search 作為可選附加元件,單獨計費,價格為每 1,000 次呼叫 5 美元。這使得 Grok 能夠在生成過程中從網路或 X 檢索即時資訊。您可以與常規 API 呼叫一起,透過標準 API 端點存取這些功能。
是的。xAI API 支援提示詞快取,這降低了重複使用相同系統提示或上下文前綴的請求成本。快取的輸入 token 的計費標準顯著低於未快取的 token。這對於在多次呼叫中發送相同指令的代理工作流程尤為實用。
是的。Grok 4.3 支援多模態輸入,在同一次 API 呼叫中可同時接受影像與文字。您可以透過標準訊息格式傳遞影像 URL 或 base64 編碼的影像。這支援了諸如視覺問答、文件分析和影像引導的程式碼生成等應用場景。
是的。Grok 4.3 支援函數呼叫、結構化輸出與串流回應。這些功能與標準的相容 OpenAI 的函數綱要配合使用,因此來自基於 GPT 整合的現有工具定義可以直接轉移。程式碼執行也作為可選的附加功能提供,價格為每 1,000 次呼叫 5 美元。
提示詞快取會在後續呼叫中,以較低的輸入 token 費率重複使用重複的上下文前綴(例如較長的系統提示詞或共用指令)。對於在每次請求中都會重新發送相同設定的聊天機器人和智能體而言,這能在不更改程式碼的情況下降低重複輸入成本。請將靜態內容放在提示詞的開頭,將可變的使用者內容放在結尾,以便套用快取。
速率限制和併發量因帳戶層級而異,因此請加入指數退避演算法並在收到429回應時進行重試,同時在流量尖峰期間對請求進行排隊。對於大型離線任務,批次處理可使大量工作避免占用您的即時限制額度。在規模化應用中,一個常見的隱性成本是在每次呼叫時重新發送完整的對話歷史記錄,因此請傳遞簡明的摘要而非整個對話執行緒,並隨著您的業務成長聯絡支援團隊以提高限制。
Grok API 採用基於 token 使用量的隨付隨用計費模式,輸入和輸出 token 均按次請求計量,無需訂閱。在 Atlas Cloud 上將 Grok 與 300 多種其他模型一起運行,意味著只需一個帳戶和一份帳單,而無需與每個供應商單獨簽訂合約。提示詞快取和批次處理可降低重複性或離線工作負載的實際成本。
在 Atlas Cloud 上建立一個帳戶,產生一個 API 金鑰,並將您現有相容於 OpenAI 的用戶端指向帶有 Grok 模型名稱的 Atlas 端點。向 Grok 4.3 發送您的第一個推理請求,或向 Grok Build 0.1 發送編碼請求,然後根據需要進行擴展。由於同一個金鑰可以存取 300 多個模型,因此您無需任何額外設定即可測試其他模型。
探索更多系列
Seedance 2.0
Seedance 2.0 API 為您提供 ByteDance 多模態影片模型的生產級存取權限——支援四模態輸入(文字、影像、影片、音訊),以及業界領先的「Universal Reference」(通用參考)系統,可在不同鏡頭間鎖定構圖、運鏡與角色動作。只需一次 API 呼叫即可整合導演級控制,固定費率為 $0.09/秒,即時取得金鑰,無需排隊——由企業級正常運行時間與合規性提供保障。Seedance 2.0 原生 4K 現已上線!
Grok Imagine
Grok Imagine API 為開發者提供 xAI 的圖像、影片和音訊生成一站式套件。它可以生成解析度高達 2K 且支援多語言文本渲染的圖像,以及長達 15 秒且帶有原生同步音訊和基於參考圖像編輯功能的影片。在 Atlas Cloud 上,只需一個金鑰即可執行每個 Grok Imagine 模式,因此您可以在圖像、影片和音訊之間無縫切換,無需單獨設定,每張圖像 0.02 美元起,每秒 0.05 美元起。
Gemini Omni Flash
Gemini Omni API 將 Google DeepMind 於 Google I/O 2026 發表的多模態影片生成與編輯模型帶進你的技術棧。Gemini Omni 將 Gemini 的推理引擎與生成式媒體融合,可接受文字、圖片、影片與音訊的任意組合輸入,產生一致且以知識為根據的輸出。透過自然對話持續打磨成果:替換物件、改寫場景、切換風格,同時維持物理規律、角色與畫面連貫性不變。Atlas Cloud 透過單一整合 API 提供完整的 Gemini Omni Flash 系列——文字生成影片、支援最多 7 張參考圖片的圖片生成影片,以及參考圖生成影片——採每秒計費、價格透明,$0.112 起,無需訂閱。立即開始打造。
GPT Image 2
GPT Image 2 API 為開發者提供了訪問 OpenAI 最新圖像模型的途徑,它是 GPT Image 1.5 的繼任者。該模型可生成和編輯圖像,能夠在拉丁和 CJK 文字上實現準確的文本渲染,並在海報、樣機和資訊圖表方面具備強大的排版能力。在 Atlas Cloud 上,您可以透過一個統一的 API 與 300 多個模型一起訪問它,並享受免費額度、99.99% 的正常運行時間,且無需 OpenAI 組織驗證。
Google最強大的創意模型現已在Atlas Cloud上全面可用。Veo 3.1提供電影等級的影片生成,Nano Banana 2支援高保真圖像建立,而Gemini為每個工作流程帶來多模態智慧。透過單一API key即可存取完整的Google模型套件,提供Day-0可用性和隨用隨付(pay-as-you-go)定價。
Seedance 2.0 Mini
Seedance 2.0 Mini 將 ByteDance 的多模態影片生成技術引入到對速度和成本要求極高的工作流程中。它以更輕量的佔用空間提供 Seedance 2.0 的核心能力——更快的生成速度、更低的單支影片成本,並且使用您現有的同款 API 整合。對於運行高吞吐量流水線或進行大規模原型設計的團隊來說,Mini 是最實用的預設選擇。
ByteDance
從電影級影片生成到高保真影像建立,ByteDance 最強大的模型現已在 Atlas Cloud 上線。以最低的推論定價和零基礎設施開銷,大規模執行 Seedance 和 Seedream。
Alibaba
Atlas Cloud 將 Alibaba 的全系模型陣容整合至同一個 API 中:Qwen 適用於語言和圖像任務,Wan 適用於高達 1080p 的影片生成。所有模型均採用按需付費模式,無需訂閱。您可以使用現有的 OpenAI 兼容客戶端,透過單一的 base URL 存取 Alibaba API。
OpenAI
Atlas Cloud 為您提供存取完整 OpenAI API 產品線的權限,從用於圖像生成的 GPT Image 2 到用於影片的 Sora 2。每個模型均採用按需付費模式,無月度消費限制。使用相容 OpenAI 的 API,只需簡單替換基礎 URL 即可輕鬆接入。
xAI
在 Atlas Cloud 上使用 xAI API 建構完整的影像與影片處理管線。以 2K 解析度生成、使用參考影像進行編輯,並將影像動畫化為音訊同步的影片片段。
Kwaivgi
Kwaivgi API 價格低於標準定價 15%。Atlas Cloud 提供對最新 Kling 版本的零日(Day-0)存取權限,採用按需付費定價且無席位限制。一個帳戶,一個金鑰,暢享從標準版到大師版的所有 Kling 模型。
Seedream 5.0 Pro
Seedream 5.0 Pro API 為開發者在 Atlas Cloud 上提供了字節跳動的可控圖像編輯模型。它透過錨點和座標精確定位編輯,將圖像分離為可編輯圖層,融合多個參考,並精準匹配顏色和材質,支援 2K 和 3K 解析度的多語言文本。在 Atlas Cloud 上,您只需一個金鑰即可存取!


