Gemini Omni Flash API for Conversational Video Editing
Gemini Omni API 將 Google DeepMind 於 Google I/O 2026 發表的多模態影片生成與編輯模型帶進你的技術棧。Gemini Omni 將 Gemini 的推理引擎與生成式媒體融合,可接受文字、圖片、影片與音訊的任意組合輸入,產生一致且以知識為根據的輸出。透過自然對話持續打磨成果:替換物件、改寫場景、切換風格,同時維持物理規律、角色與畫面連貫性不變。Atlas Cloud 透過單一整合 API 提供完整的 Gemini Omni Flash 系列——文字生成影片、支援最多 7 張參考圖片的圖片生成影片,以及參考圖生成影片——採每秒計費、價格透明,$0.112 起,無需訂閱。立即開始打造。
探索領先模型
Atlas Cloud 為您提供最新的行業領先創意模型。







使用 Gemini Omni Flash API 生成的四種方法
選擇適合該任務的 Gemini Omni Flash API 端點,涵蓋從文字生成影片、圖像生成影片,到參考驅動生成以及對話式編輯等功能。
| 模態 | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | 只有文字提示詞?Gemini Omni Flash Text-to-Video API 可以在一步操作中將其轉化為帶有同步音訊的 720p 影片,並在長達10秒的影片中透過推理驅動的控制來精準掌握場景、動作和鏡頭。 |
| Gemini Omni Flash Image-to-Video API (I2V) | Gemini Omni Flash Image-to-Video API 能夠將靜態圖像轉化為動態影片,並將原圖作為起始影格。憑藉自然的運動效果和同步音訊,它以 720p 的畫質讓產品特寫、人像以及概念設計煥發生機。 |
| Gemini Omni Flash Reference-to-Video API (R2V) | 使用 Gemini Omni Flash Reference-to-Video API,透過最多七張參考圖像和三段短影片片段來引導生成過程。它能在整個片段中保持角色、風格和場景的一致性,是品牌和系列內容的理想選擇。 |
| Gemini Omni Flash Video Edit API | 當影片片段需要修改時,Gemini Omni Flash Video Edit API 會透過有狀態的 Interactions API 應用自然語言指令。它可以替換元素、調整光照並重塑場景風格,同時在多輪互動中保持其餘畫面完好無損。 |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
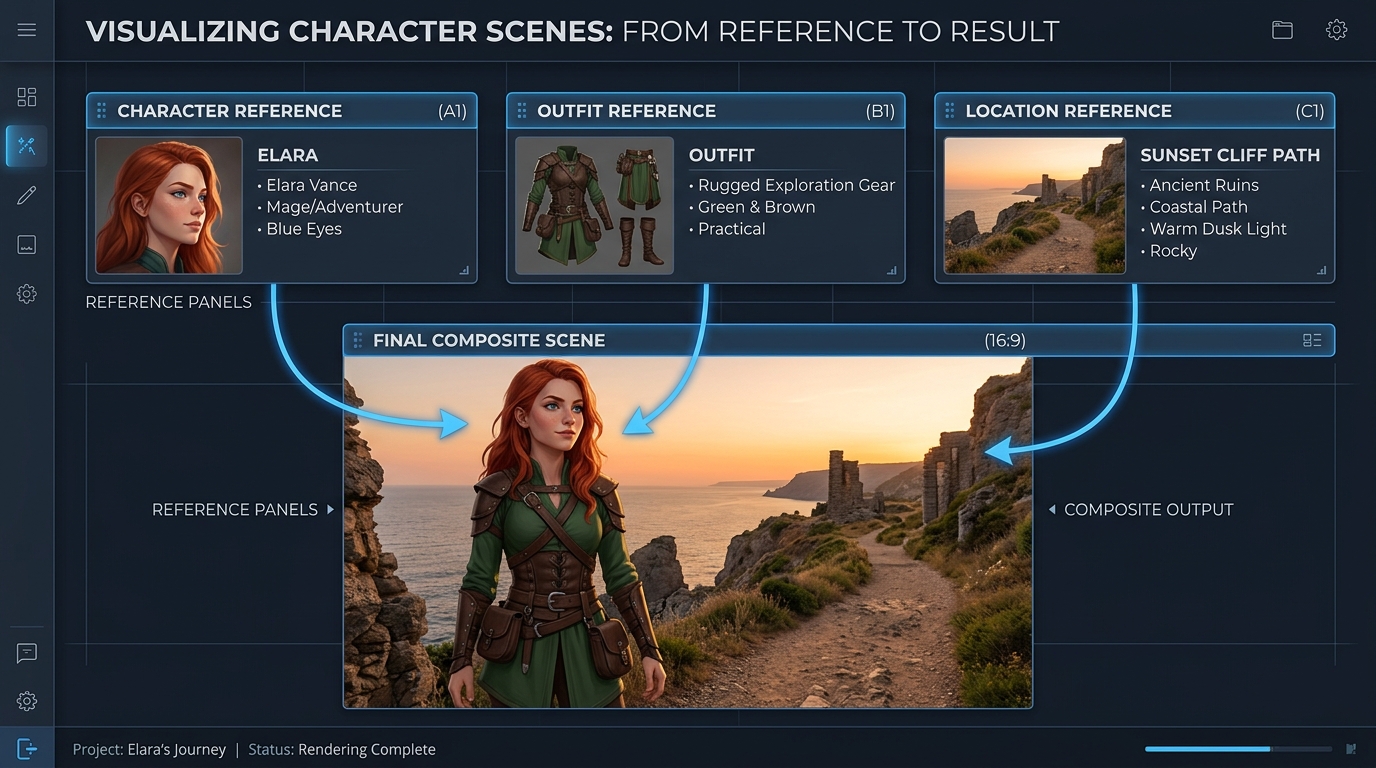
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Gemini Omni Flash API 比較分析
查看不同廠商的模型表現 — 對比效能、價格和獨特優勢,做出明智決策。
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | 透過對話編輯成品影片 | Yes | 是的,有狀態 | 文字、影像、影片、音訊 |
| Veo 3.1 | 支援場景擴展的電影級片段 | Yes | No | 文本、圖像、參考 |
| Seedance 2.0 | 旗艦級參考控制影片 | Yes | No | 文字、圖像、影片、音訊 |
| Kling 3.0 | 多鏡頭AI導演敘事 | Yes | No | 文本、圖像、參考 |
如何在 Atlas Cloud 上使用 Gemini Omni Flash
幾分鐘即可上手 — 按照以下簡單步驟,透過 Atlas Cloud 平台整合和部署模型。
建立 Atlas Cloud 帳戶
在 atlascloud.ai 註冊並完成驗證。新用戶可獲得免費額度,用於探索平台和測試模型。
為何在 Atlas Cloud 使用 Gemini Omni Flash
將先進的 Gemini Omni Flash 模型與 Atlas Cloud 的 GPU 加速平台相結合,提供無與倫比的效能、可擴展性和開發體驗。
效能與靈活性
低延遲:
GPU 最佳化推理,實現即時回應。
統一 API:
一次整合,暢用 Gemini Omni Flash、GPT、Gemini 和 DeepSeek。
透明定價:
按 Token 計費,支援 Serverless 模式。
企業與規模
開發者體驗:
SDK、資料分析、微調工具和模板一應俱全。
可靠性:
99.99% 可用性、RBAC 權限控制、合規日誌。
安全與合規:
SOC 2 Type II 認證、HIPAA 合規、美國資料主權。
關於 Google Gemini Omni Flash API 的常見問題解答
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
探索更多系列
Seedance 2.0
Seedance 2.0 API 為您提供 ByteDance 多模態影片模型的生產級存取權限——支援四模態輸入(文字、影像、影片、音訊),以及業界領先的「Universal Reference」(通用參考)系統,可在不同鏡頭間鎖定構圖、運鏡與角色動作。只需一次 API 呼叫即可整合導演級控制,固定費率為 $0.09/秒,即時取得金鑰,無需排隊——由企業級正常運行時間與合規性提供保障。Seedance 2.0 原生 4K 現已上線!
Grok Imagine
Grok Imagine API 為開發者提供 xAI 的圖像、影片和音訊生成一站式套件。它可以生成解析度高達 2K 且支援多語言文本渲染的圖像,以及長達 15 秒且帶有原生同步音訊和基於參考圖像編輯功能的影片。在 Atlas Cloud 上,只需一個金鑰即可執行每個 Grok Imagine 模式,因此您可以在圖像、影片和音訊之間無縫切換,無需單獨設定,每張圖像 0.02 美元起,每秒 0.05 美元起。
Gemini Omni Flash
Gemini Omni API 將 Google DeepMind 於 Google I/O 2026 發表的多模態影片生成與編輯模型帶進你的技術棧。Gemini Omni 將 Gemini 的推理引擎與生成式媒體融合,可接受文字、圖片、影片與音訊的任意組合輸入,產生一致且以知識為根據的輸出。透過自然對話持續打磨成果:替換物件、改寫場景、切換風格,同時維持物理規律、角色與畫面連貫性不變。Atlas Cloud 透過單一整合 API 提供完整的 Gemini Omni Flash 系列——文字生成影片、支援最多 7 張參考圖片的圖片生成影片,以及參考圖生成影片——採每秒計費、價格透明,$0.112 起,無需訂閱。立即開始打造。
GPT Image 2
GPT Image 2 API 為開發者提供了訪問 OpenAI 最新圖像模型的途徑,它是 GPT Image 1.5 的繼任者。該模型可生成和編輯圖像,能夠在拉丁和 CJK 文字上實現準確的文本渲染,並在海報、樣機和資訊圖表方面具備強大的排版能力。在 Atlas Cloud 上,您可以透過一個統一的 API 與 300 多個模型一起訪問它,並享受免費額度、99.99% 的正常運行時間,且無需 OpenAI 組織驗證。
Google最強大的創意模型現已在Atlas Cloud上全面可用。Veo 3.1提供電影等級的影片生成,Nano Banana 2支援高保真圖像建立,而Gemini為每個工作流程帶來多模態智慧。透過單一API key即可存取完整的Google模型套件,提供Day-0可用性和隨用隨付(pay-as-you-go)定價。
Seedance 2.0 Mini
Seedance 2.0 Mini 將 ByteDance 的多模態影片生成技術引入到對速度和成本要求極高的工作流程中。它以更輕量的佔用空間提供 Seedance 2.0 的核心能力——更快的生成速度、更低的單支影片成本,並且使用您現有的同款 API 整合。對於運行高吞吐量流水線或進行大規模原型設計的團隊來說,Mini 是最實用的預設選擇。
ByteDance
從電影級影片生成到高保真影像建立,ByteDance 最強大的模型現已在 Atlas Cloud 上線。以最低的推論定價和零基礎設施開銷,大規模執行 Seedance 和 Seedream。
Alibaba
Atlas Cloud 將 Alibaba 的全系模型陣容整合至同一個 API 中:Qwen 適用於語言和圖像任務,Wan 適用於高達 1080p 的影片生成。所有模型均採用按需付費模式,無需訂閱。您可以使用現有的 OpenAI 兼容客戶端,透過單一的 base URL 存取 Alibaba API。
OpenAI
Atlas Cloud 為您提供存取完整 OpenAI API 產品線的權限,從用於圖像生成的 GPT Image 2 到用於影片的 Sora 2。每個模型均採用按需付費模式,無月度消費限制。使用相容 OpenAI 的 API,只需簡單替換基礎 URL 即可輕鬆接入。
xAI
在 Atlas Cloud 上使用 xAI API 建構完整的影像與影片處理管線。以 2K 解析度生成、使用參考影像進行編輯,並將影像動畫化為音訊同步的影片片段。
Kwaivgi
Kwaivgi API 價格低於標準定價 15%。Atlas Cloud 提供對最新 Kling 版本的零日(Day-0)存取權限,採用按需付費定價且無席位限制。一個帳戶,一個金鑰,暢享從標準版到大師版的所有 Kling 模型。
Seedream 5.0 Pro
Seedream 5.0 Pro API 為開發者在 Atlas Cloud 上提供了字節跳動的可控圖像編輯模型。它透過錨點和座標精確定位編輯,將圖像分離為可編輯圖層,融合多個參考,並精準匹配顏色和材質,支援 2K 和 3K 解析度的多語言文本。在 Atlas Cloud 上,您只需一個金鑰即可存取!


