RSpqXx0wq8Q
2026年5月19日,在 Google I/O 大会上,DeepMind 发布了 Gemini Omni。当天,Gemini Omni 提示词指南便在 DeepMind 文档网站上线,位置夹在 Omni Flash 模型卡片和 API 说明之间。大多数人只关注了主题演讲演示,而这份文档几乎被忽略了。
先说重点。Gemini Omni 是 DeepMind 新推出的多模态生成模型。其首个产品 Gemini Omni Flash 支持通过文本、图像、音频或视频的任意组合生成长达 10 秒的视频。所有输出内容均带有 SynthID 水印。AI Plus、AI Pro 和 AI Ultra 订阅用户可立即使用;据 Gagadget 报道,YouTube Shorts 和 YouTube Create 应用用户在本发布周内即可获得免费使用权限。据 Google 称,API 访问权限将在“未来几周内”开放。
回到提示词指南。Google DeepMind 在“世界理解(World understanding)”部分直接点明了范式转变:
使用 Veo 时,你需要提供精确的指令才能获得最佳结果。但在 Gemini Omni 中,你不必如此拘泥于特定的提示词。只需告诉 Omni 你想创作的内容,然后看着模型凭借其推理能力和世界知识将细节变为现实。
翻译过来就是:少写点。
将此与字节跳动和快手为其视频模型发布的提示词指南对比来看,尽管框架不同,但指向是一致的。
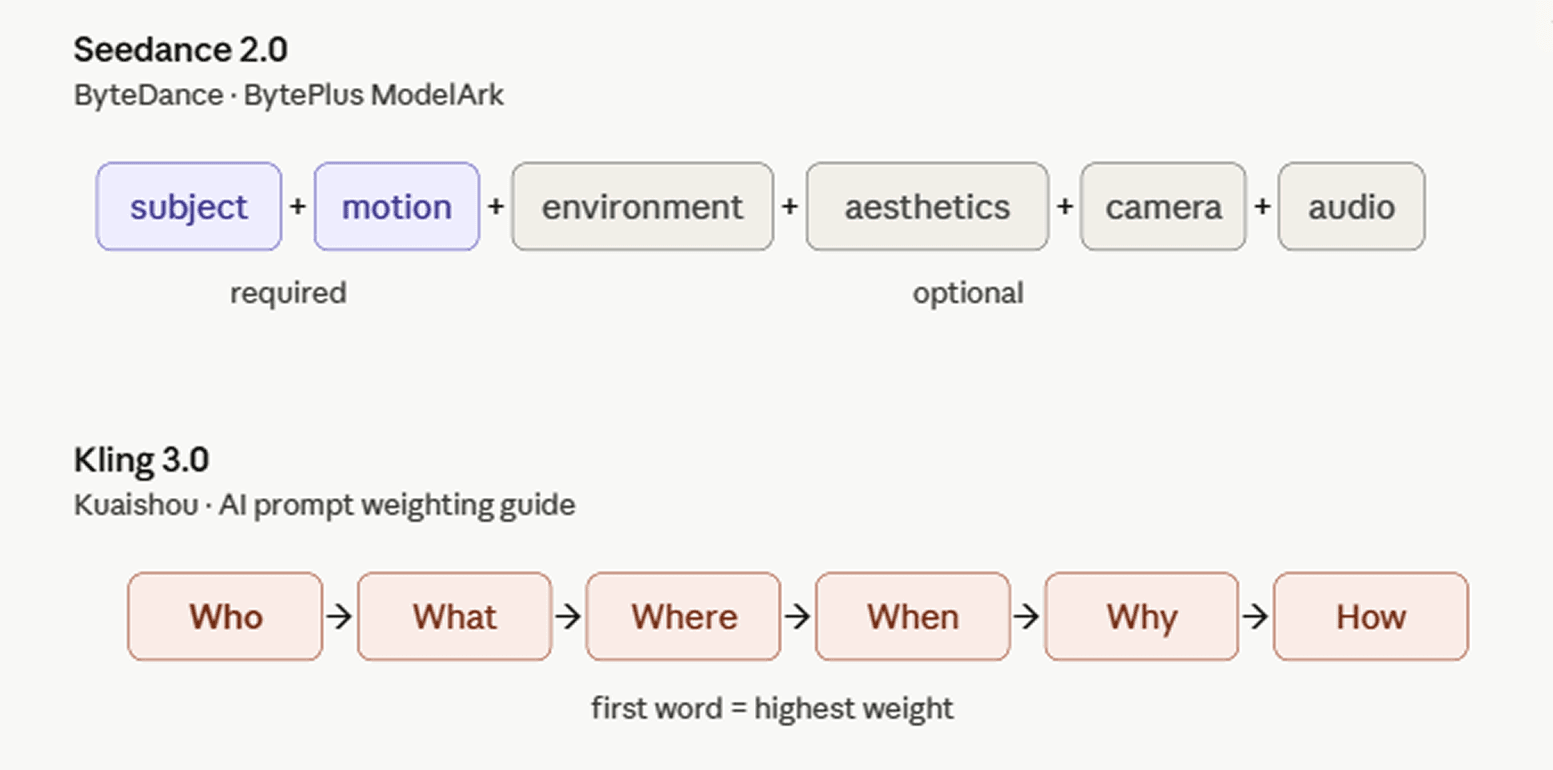
字节跳动在其国际开发者平台通过 BytePlus ModelArk 提示词指南介绍了 Seedance 2.0。推荐结构为:主体 + 动作(+ 环境 + 美学 + 摄像机移动/切镜 + 音频)。并非每个组件都必须具备,你可以根据镜头需求进行选择。
快手的 AI 提示词加权指南通过 5W1H 公式来构建:Who(谁)+ What(什么)+ Where(地点)+ When(时间)+ Why(原因)+ How(如何)。Who(主体)通常权重最高且放在提示词开头,因为在 Kling 3.0 中,词序决定权重:排在越前面的词,获得的算力关注度越高。像媒介或视角这类风格化选择最好放在末尾,作为对既定场景的润色。指南提醒不要盲目堆砌元素;过多冲突的关键词会降低质量。
三家公司独立得出了类似的建议,这表明它们的模型在同一时期达到了相近的能力水平。Google 建议少写,字节跳动将大多数组件设为可选,而快手则强调词序而非字数。虽然具体表述有所差异,但三家实验室都引导创作者采用更宽松、更自然的提示词。
现在来看看 Gemini Omni 提示词指南在实际应用中的表现。
Gemini Omni 提示词结构:Google DeepMind 使用的 5 个维度
指南以一个完整的示例开场:
一个广角跟踪镜头平滑掠过宁静的湖面,显现出一个巨大的、反光的、铬合金质感的豆状物体在空中轻松悬浮,缓慢旋转,露出其扭曲倒映出的雄伟悬崖和下方清澈蔚蓝水中部分淹没的类似小物体,一道灿烂的阳光在悬浮异常体后升起,将整个场景笼罩在清澈、空灵的日光中,呈现出鲜艳的蓝绿色调,营造出一种电影般令人敬畏的氛围,背景是雄伟且超凡脱俗的管弦乐,强调了外星景观的广阔与神秘,悬浮物体散发出微弱而深沉的嗡嗡声。
_SpuwEI0tIU
超过 90 个字。拆解开来,包含 5 个维度。
- 镜头构图与运动。广角、中景还是特写?镜头应该平滑滑行还是突然快速移动?这两个动词会产生截然不同的输出,因此在追求合适的运动感时,多尝试几次是值得的。
- 风格。写实、电影感、空灵、雄伟?这一维度不需要细节。告诉模型情感基调就足够了。
- 光影。光从哪里来?太阳、路灯、在镜头内还是画面外?感觉是清冽、温暖还是空灵?
- 场景。指南中有一行值得强调:“你不需要描述每一个细节,Omni 会根据你的整体意图进行创作。”这与 Seedance 和 Kling 在官方文档中的说法相吻合。
- 动作与交互。场景中有什么人或物,他们如何运动,如何交互。
Gemini Omni 对话式编辑 vs Veo 提示词重写
Omni 和 Veo 的生成质量旗鼓相当,真正的差距在于视频生成后的操作能力。
以前,修改一个细节意味着要重写整个提示词、重新生成,并祈祷帧间连贯性保持不变。Omni 用对话取代了这一步。
官方指南给出了一些示例。
一段小男孩的定格动画视频。第一次编辑:“把蝴蝶换成蜜蜂。” 下一次:“把蜜蜂换成一群小萤火虫。” 每次对话只改变一个元素;其他帧会自动保留。
5zDLZZccPTY
摄像机操作也是如此。一段小提琴手的视频依次接收了三个指令:“将小提琴手移动到图片环境”、“让小提琴隐形”、“将摄像机角度改为小提琴手肩后”。环境置换、物体移除、摄像机重定位,全都可以通过自然语言完成。
jXnbo0gBMHQ
有一个需要注意的坑。第三方测评指出,如果你的编辑指令过于模糊,Omni 往往会过度编辑,导致改变了你希望保留的元素。Google 的建议:每次只改变一个变量,并明确说明哪些内容应该保持不变。
跨模态同步示例更有趣。拿一段公寓楼的夜景视频,加入指令“公寓的灯光随着音乐同步亮起”。模型会分析配乐的节拍,并将窗户灯光与之对齐。在 After Effects 中做这件事需要时间轴、节拍器和逐帧手动打关键帧。
93oo4Yvghl8
Gemini Omni 的 4 项高级能力:世界知识、文本渲染、动作参考、多输入
指南的后半部分拆解了 4 项能力。
应用级世界知识
提示词示例:解释常规计算与量子计算的区别。使用一种当代扁平化媒体风格可视化这句话,将极简主义矢量形状与丰富的有机纹理融合。审美由高对比度的“电子”色调定义,霓虹粉、青色和青柠色置于深蓝色背景上。这种风格的标志是使用点画阴影和颗粒感渐变,为原本简单的几何形状增添了触感和类印刷品的质感。通过将锐利的边缘与柔和、斑驳的过渡结合,插画营造出一种俏皮、编辑风的感觉。
模型已经知道什么是量子叠加,以及如何通过一组对比镜头来传达它。用户不需要解释量子力学,只需要描述视觉基调。
3b29A-7qHvE
这之所以有效,是因为 Omni 运行在顶尖的推理模型之上,这是纯生成式视频模型无法比拟的。Demis Hassabis 在 I/O 大会后接受 Semafor 采访时,将 Omni 描述为构建能更好地理解现实世界的 AI 计划的一步。他指出,Alphabet 的自动驾驶部门 Waymo 已经在测试类似的“世界模型”,赋予自动驾驶汽车一种处理不可预测情况的“想象力”。视频生成只是该架构最直观的应用。
文本渲染
提示词示例:逐字显示,屏幕一次显示一个词,每个词有不同的动画风格,节奏完美契合韵律,制作一段精彩剪辑。
_NV7lrxo6Ik
复杂动作参考
提示词示例:在保持一切不变的情况下编辑,添加滑板发出的动画运动特效。
b94aat8s22c
多输入参考
提示词示例:视频中的鸟儿根据图像松散地形成鸟的形状。它们随着音频的音乐移动,并在飞行时消散。
3jdeP-az3oQ
风格迁移
提示词示例:创建视频参考的四部分风格渐变,以鲜艳的蜡笔美学开始,特色是丰富、蜡质、有纹理的笔触和俏皮的手绘角色设计,背景是颗粒感极强的纸张。无缝过渡到纹理纸上的石墨铅笔素描,使用交叉阴影、不同的线条粗细和 12fps 的“线条抖动”效果来强调手绘感。接着,变形为超写实 3D 半透明玻璃风格,特征是复杂的折射、焦散图案和极简主义工作室场景内的柔和内部发光。以触感印刷品外观结束序列,应用有限的三色调色板、颗粒状半色调纹理和刻意的套色叠加,打造复古机械感。
n9TesZsfVNw
分镜参考
提示词:在视频中展示这个故事。从左上角开始,完全按顺序执行故事。整个故事在 10 秒内完成。电影感。
uT937Ptk9fg
跨镜头一致性
RSpqXx0wq8Q
为什么 Gemini Omni、字节跳动 Seedance、快手 Kling 的提示词建议趋于一致?
回到最初的观察。Seedance、Kling 和 Omni 在提示词建议上的相似性并非互抄的结果。更合理的解释是,这一代模型凭借自身能力达到了相近的水平。
一旦模型能够在场景层面处理自然语言、用世界知识补充细节并推断用户的真实意图,过度编写反而会成为瓶颈。这三家实验室对于需要增加多少结构意见不一,但都同意答案不是写得越多越好。
这是扩散模型与大型语言模型联合训练两年的结果。Omni 将这一结果推向了相对完善的状态。
通过 Atlas Cloud 调用 Gemini Omni:Seedance、Kling、Veo 的统一 API
Gemini Omni 即将登陆 Atlas Cloud。Atlas Cloud 整合了文本、图像、视频、音频领域的 300 多种 AI 模型。主要的视频模型已在该平台运行:Seedance 2.0、Kling 3.0、Wan 2.7、Veo 等。如需进行并排对比,请查看 Atlas Cloud 的 Wan 2.7 vs Seedance 2.0 vs Kling 3.0 深度解析。
一个账号即可运行整个工作流。无需在多个区域平台注册、付费和维护 API 密钥。Playground 支持交互式调试。兼容 OpenAI 的统一 API 可直接接入现有工作流。
Atlas Cloud 的提示词库拥有二十多种类别的现成提示词,涵盖动漫、科幻、悬疑、美食、Vlog 等格式。每个提示词都附有示例视频和参数说明。复制、替换几个词,即可运行。
生产级视频生成的统一 API
虽然 Google 正在向 Gemini 应用和 Google Flow 的最终用户推广 Gemini Omni Flash,但想要将相同的多模态视频引擎嵌入自身工作流的开发者和产品团队,需要一个稳定、可预测的 API 层。
Atlas Cloud 通过一个兼容 OpenAI 的统一 API 提供 Gemini Omni Flash,以及其他 300 多种图像、视频和 LLM 模型——让你无需在多个供应商账户、计费门户或 SDK 之间切换,即可集成 Google 的原生多模态模型。
Gemini Omni Flash 的两个版本现已上线 Atlas Cloud:
| 版本 | 最佳用途 | 输入 | 分辨率 | 时长 | 起步价 |
|---|---|---|---|---|---|
| Gemini Omni Flash 文本转视频 (开发者) | 纯提示词驱动的电影级生成 | 文本(最多 20,000 字符) | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | $0.2 + $0.1/秒 |
| Gemini Omni Flash 图像转视频 (开发者) | 基于真实参考的主体一致性视频 | 文本 + 最多 7 张参考图 | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | $0.2 + $0.1/秒 |
快速开始 — 5 行代码生成 Gemini Omni Flash 视频:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
API 会立即返回一个预测 ID —— 通过轮询 /api/v1/model/prediction/{id} 获取渲染完成的 MP4 URL。上述模型页面提供了完整架构、7 种语言的代码示例以及无需代码的 Playground。






