
Grok Imagine Video Generation 是 xAI 推出的前沿多模态 AI 视频系统,它已经重新定义了创作者对单次 API 调用产出效果的期待。该模型构建于 xAI Aurora 引擎之上,使用自回归专家混合(MoE)网络,能够同时处理文本、图像、视频和音频 token。这种方法彻底取代了 Sora 和 Veo 等系统所采用的扩散 Transformer 方法。
其核心优势在于:在单次生成过程中即可创建自然的音视频同步效果,无需后续额外使用配音工具。
概览:关键规格
| 功能 | 详情 |
| 时长 | 1–15 秒 |
| 帧率 | 24 FPS |
| 分辨率 | 480p / 720p |
| 音频 | 原生口型同步、音效(SFX)、对话、环境音乐 |
| 排行榜 | Artificial Analysis Video Arena 第 1 名 (Elo 1404 ±6) |
Grok imagine video generation 于 2026 年 5 月底发布,甫一亮相便登顶 Artificial Analysis Video Arena 的“图生视频”排行榜,取代了字节跳动的 Seedance 2.0。对于任何需要快速产出带有内置音轨、达到生产级质量视频的现代数字工作流而言,这是目前业界公认的新标杆。
深入了解 xAI Grok Imagine Video Generation 的架构
为了充分利用 Grok 的特性,我们首先需要剖析其底层逻辑。与那些在事后将声音和画面拼接在一起的传统视频模型不同,Grok 将音画视为一个统一的实体。理解这一核心转变,就能明白为什么它的提示词响应和渲染速度与市面上的其他方案存在如此巨大的差异。
什么是 Grok Imagine 及其工作原理?
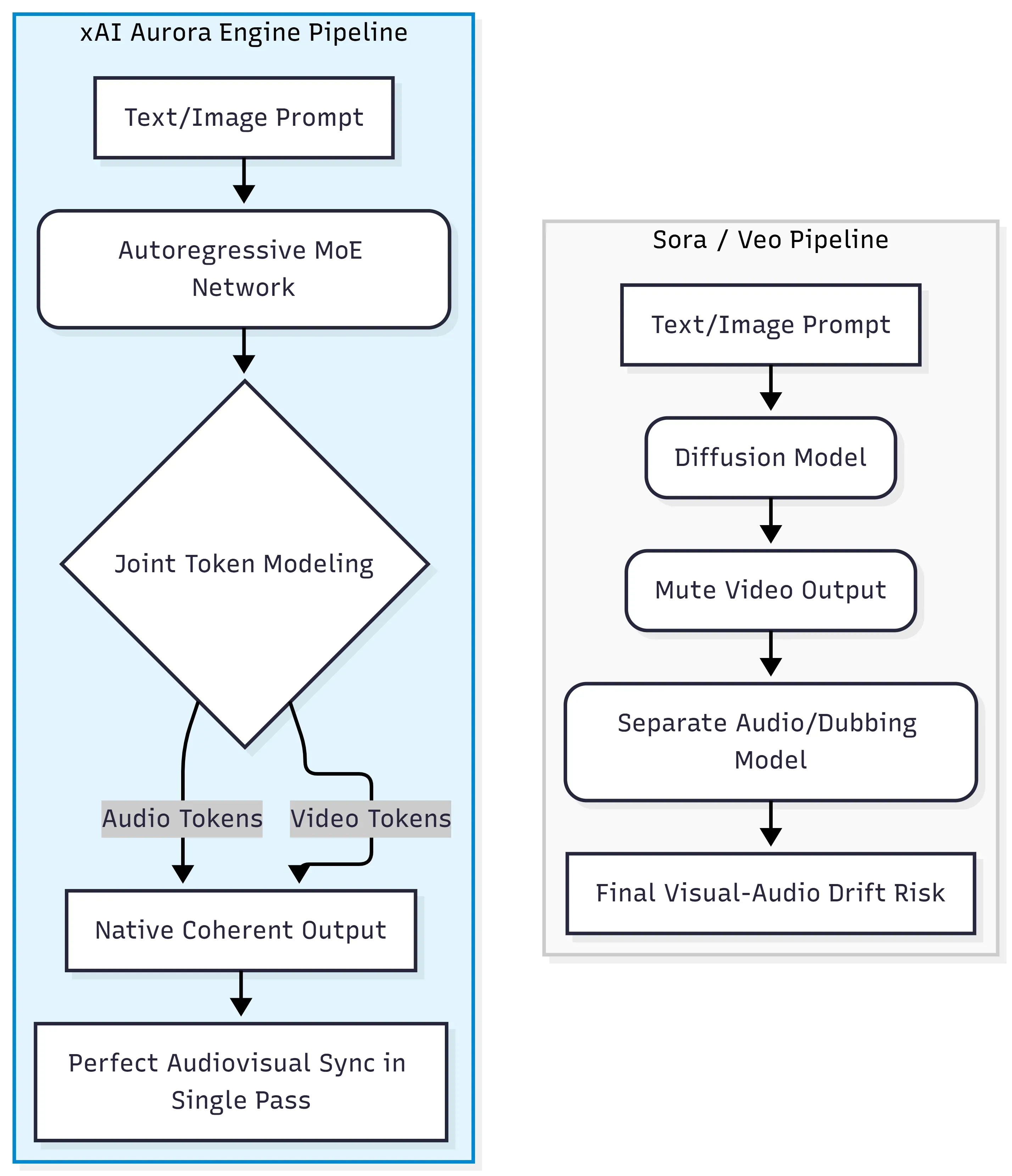
Grok Imagine Video Generation 的核心是 xAI Aurora 引擎,这是一个自回归专家混合网络(MoE 网络),能够跨文本、图像、视频和音频数据组成的统一流中预测下一个 token。这与 OpenAI 的 Sora 和 Google 的 Veo 所使用的扩散 Transformer 范式(视频和音频通常在不同阶段生成或对齐)在架构上有本质区别。
告别扩散 Transformer
传统的扩散模型通过将随机噪声逐渐去噪为连贯帧来工作。它们在视觉质量上表现出色,但将音频视为“次要事项”,通常需要外部工具或后期流水线来添加声音。Aurora 则走了一条完全不同的道路。
| 方法 | 架构 | 音频处理方式 |
| Sora / Veo | 扩散 Transformer | 后期制作 / 独立模型 |
| Grok Imagine Video | 自回归 MoE | 原生单步生成 |
交错式多模态 Token 处理
Aurora 不会按顺序处理不同模态,而是处理交错式多模态数据——这意味着视听 token(对话、音效、环境音乐)是在同一个前向传播过程中与视频帧同时生成的。正是这种联合 token 建模能力,使得口型同步和与事件对齐的音效能够直接由模型生成,而无需额外的对齐系统。
该演示样本展示了 Aurora 的单步执行能力,引擎产生的引擎轰鸣声频率与视觉上的加速感及轮胎摩擦力物理反馈达到了完美的相位同步。
大规模训练:Colossus
该模型是在 xAI 的 Colossus 超级计算机上训练的。该站点使用了约 55.5 万个 NVIDIA GPU,功耗约为 2 吉瓦,是目前全球最大的单点 AI 训练集群。这种超大规模的设施是 Aurora 能够混合四种不同媒体类型且不降低质量的秘密所在。
关键能力:图生视频、格式设置与质量模式
虽然 Grok 支持文生视频,但其真正的企业级应用价值体现在图生视频(I2V)工作流中。通过向模型输入静态参考图,你可以瞬间锁定角色特征,从而将繁琐的描述性文字负担转化为精确的机械控制。在深入了解样式模式之前,你需要先配置核心流水线约束。
Grok Imagine 的视频时长限制、宽高比和分辨率是多少?
将图像转换为视频是 Grok Imagine 最实用的功能之一。只需上传一张静态照片并输入简单的提示词描述动作,模型即可在生成视频的同时添加匹配的音频。你可以通过时长、帧率、分辨率和形状这四项设置完全控制最终格式。
时长和帧率
精细的时长控制允许你请求 1 到 15 秒之间的任意整数时长。这在保持更长窗口期内的时间一致性的同时,将之前的 10 秒上限提升了 50%。所有输出均以 24 FPS 的固定帧率渲染。
分辨率选项
| 分辨率 | 质量 | 处理速度 |
| 480p | 标准清晰度 | 更快(默认) |
| 720p | 高清 (HD) | 较慢 |
对于最终交付或社交媒体分发,720p 是实用的选择;480p 则适用于快速迭代和提示词测试。
宽高比变化
支持七种宽高比变化:
| 比例 | 最佳用例 |
| 16:09 | 宽屏 / YouTube(默认) |
| 9:16 | TikTok / Instagram Reels / Stories |
| 1:01 | 社交媒体缩略图 |
| 4:3 / 3:4 | 演示文稿 / 人像 |
| 3:2 / 2:3 | 摄影格式 |
在图生视频生成中,输出默认为输入图像的原始宽高比,除非手动进行覆盖。
电影级动态与零样本身份一致性的提示词工程指南
由于 xAI Aurora 引擎依赖于联合 token 建模,你的提示词策略必须做出相应调整。你不再需要花费 token 去描述角色的外貌——输入图像通过零样本身份保留(zero-shot identity preservation)直接解决了这个问题。相反,你的提示词应严格聚焦于方向性动作、摄像机行为,以及至关重要的:你希望引擎同步生成的声学环境。
如何编写提示词以获得最佳 Grok Imagine 视频效果?
最核心的原则:由于 Grok Imagine 支持零样本身份保留,模型会直接从输入图像中获取主体外观。你无需重复描述发色、服装或面部特征,应将每一字一句都用于描述运动动态、环境和摄像机运动。
最佳提示词语法
组合使用以下优化过的 token 模块,构建高可控性的电影场景:
| 动作与运动 | 摄像机动态 | 声学与环境 |
| ...自信大步向前,大衣飘动 | 推拉变焦(Dolly zoom)缓慢后移 | ...霓虹倒影在湿滑路面起涟漪。SFX:暴雨拍打在沥青路面 |
| ...在人群中疾驰,回头张望 | 低角度追踪镜头,快速节奏 | ...在闪烁的荧光灯下。SFX:人群嘈杂的窃窃私语声和喘息声 |
| ...缓慢转身,睁开双眼 | 微距镜头从左向右平移 | ...浅景深,漂浮的尘埃。SFX:深沉的电影重低音 |
场景 A:赛博朋克追逐序列(高动态、强音频同步)
提示词:
动作与主体: 一名男子在霓虹灯照亮的湿滑巷子里飞奔。
摄像机动态: 摄像机保持低位紧跟其后。背景模糊掠过,明亮的灯光在屏幕上划过。
音效(SFX): 快节奏电子音乐混杂着踩水坑的声音和远处的警笛声。节拍与闪烁的霓虹灯完美同步。
测试目标: 验证 Aurora 引擎在高速运动中对物体形态的控制能力,并评估引擎将音频与视觉同步(如合成器节拍与闪烁霓虹灯对齐)的精确度。
亮点(Grok 的成功之处):
- 零样本身份保留: 与静态种子图的衔接天衣无缝。风衣的皱褶皮革纹理和角色凌乱的深色头发保持高度稳定,没有任何身份形变。
- 物理连贯性: Grok 在处理高速疾驰时,肢体没有出现残影,衣服也没有发生穿模,这通常是扩散模型竞品的常见故障点。
- 动态光影物理: 湿滑路面上粉色和蓝色的霓虹反射随着摄像机的向前追踪角度进行了准确的平移与变换。
瑕疵(瓶颈所在):
- 音频 Token 偏差: 虽然原生单步音频同步令人印象深刻,但引擎过度强化了“synthwave music”(合成波音乐)token,导致“puddle splashes”(踩水坑)的局部环境音效被完全掩盖。
- 运动压缩: 在 720p 分辨率下,快速的摄像机运动导致远处的背景文字(如“MIDNIGHT DINER”)边缘出现轻微模糊和数字伪影。
场景 B:电影对话与情感迸发
提示词:
动作与主体: 她发表一段紧张的电影演讲,坚定地低语:“一切今晚结束。”
摄像机动态: 当一阵强风吹乱她的头发时,摄像机缓慢推向她的脸部。
音效(SFX): 她低沉的声音与嘴唇动作完美匹配,混杂着突如其来的强风吹入麦克风并摩擦衣物的声音。
测试目标: 这是对 xAI Aurora 引擎多 token 集成能力的终极压力测试。模型必须在单次推理过程中执行无懈可击的原生口型同步和复杂的面部肌肉运动,同时计算头发/衣物运动的物理交互,并匹配逼真的环境音效。
亮点(Grok 的成功之处):
- 无懈可击的原生口型同步: “It ends tonight”这句话的口型与角色唇部和下颚的动作完全匹配,无需任何后期编辑。
- 微表情保持: 面部雀斑、轻微的眨眼和锐利的眼神都保持原位,证明引擎在特写镜头下依然能稳住角色身份。
- 风力物理模拟: 在她说话结束时,一阵突如其来的微风吹过她的黑发,发丝移动自然,保持了真实的质感与体积感。
瑕疵(瓶颈所在):
- 音频伪影: 生成的人声虽然时间点准确,但音色略显压缩、机械感较强,缺失了提示词中要求的原始、带呼吸感的质感。
- 时间微形变: 在头发随风飘动时,耳朵和发际线周围出现了轻微的纹理混合,引擎在区分移动发丝与静态背景皮肤时略显吃力。
避坑指南:反例矩阵
由于目前的公共 API 端点不支持专门的负面提示词(negative prompt)参数,流水线工程师必须转变传统的基于扩散模型的提示词启发式方法:
- ❌ 错误做法(扩散思维): “一名男子在奔跑,高度细节,4k,无模糊,无失真,电影级灯光。”
- 编辑分析: 这会在上下文窗口中填入大量冗余 token,并引入“无模糊”、“无失真”等负面短语。像 Aurora 这样的自回归 MoE 网络可能会误将这些词理解为语义锚点,从而意外生成你想要避免的失真效果。
- ✅ 正确做法(Aurora 原生思维): “充满活力地大步向前。全程锐利对焦,纯净的电影质感,体积光穿透尘埃。”
- 编辑分析: 将排除项替换为肯定性的、决定论的空间和物理描述,从而清晰地引导引擎向高锐度渲染的 token 预测路径发展。
专业提示:
当提示词引入冲突的空间指令(如同时命令放大画面和向右平移)时,时间连贯性会下降。请保持摄像机移动的单一性和方向性。对于超过 8 秒的片段,请围绕一个连续的运动弧线来设计提示词,而不是进行多次场景剪辑。
Grok Imagine Video Generation API 集成:Python 与 REST 快速入门
从创意概念过渡到生产级规模,需要通过官方 xAI API 网关来驱动这些参数。根据你当前的架构,以及你偏好自动化后台管理还是轻量级自定义循环,xAI 提供了两条不同的实现路径。
如何调用 Grok Imagine API 生成视频?
调用 Grok Imagine API 支持两条路径:原生的 xai_sdk Client(自动处理轮询)以及通过 https://api.x.ai/v1 进行的 OpenAI 兼容 base_url REST 调用方式。两者均需将 API Key 设置为环境变量进行身份验证。
前置条件
在编写代码前,请完成以下步骤:
- 在 console.x.ai 生成 API Key。
- 在 shell 中导出:
export XAI_API_KEY="your-key-here" - 安装 SDK:
pip install xai-sdk
路径 1:原生 xai_sdk(推荐)
xai_sdk Client 在内部封装了完整的异步轮询循环,因此你只需调用 video.generate 接口即可获得完整的视频对象:
python1import os 2import xai_sdk 3 4client = xai_sdk.Client(api_key=os.getenv("XAI_API_KEY")) 5 6# 确保在图生视频工作流中传入参考图 7response = client.video.generate( 8 model="grok-imagine-video", 9 image="your image", # 所需的 URL 或 base64 10 prompt="your prompt", 11 duration=5, 12 aspect_ratio="16:9", 13 resolution="720p", 14) 15 16# 已修复:符合标准 xai_sdk 响应模式 17print(f"生成成功。视频 URL: {response.video.url}")
无需手动轮询。SDK 会提交请求、等待完成并返回 URL。
路径 2:标准 REST API(自定义异步循环)
对于无法使用原生 SDK 的环境,请使用底层的 HTTP 端点。由于视频生成是异步的,你必须手动实现一个轮询序列来跟踪执行状态:
python1import os 2import time 3import requests 4 5headers = { 6 "Authorization": f"Bearer {os.environ['XAI_API_KEY']}", 7 "Content-Type": "application/json", 8} 9 10payload = { 11 "model": "grok-imagine-video", 12 "image": "your image", 13 "prompt": "prompt", 14 "duration": 5, 15 "aspect_ratio": "16:9", 16 "resolution": "720p" 17} 18 19# 1. 提交视频生成请求 20res = requests.post("https://api.x.ai/v1/videos/generations", headers=headers, json=payload) 21res.raise_for_status() 22request_id = res.json()["request_id"] 23 24# 2. 轮询状态接口直至完成 25while True: 26 poll = requests.get(f"https://api.x.ai/v1/videos/{request_id}", headers=headers) 27 data = poll.json() 28 29 if data["status"] == "done": 30 # 已修复:符合官方 xAI JSON 模式返回值 31 print(f"成功!资源地址: {data['video']['url']}") 32 break 33 elif data["status"] in ["expired", "failed"]: 34 print(f"生成失败,状态: {data['status']}") 35 break 36 37 time.sleep(5) # 安全的速率限制间隔
轮询状态参考
生成过程中 API 返回以下四种状态值之一:
| 状态 | 含义 |
| pending | 处理中 |
| done | 视频就绪,URL 可用 |
| expired | 请求超时 |
| failed | 生成错误 |
建议每 5 秒轮询一次以保持在合理的速率限制内。SDK 默认采用 100ms 间隔,但 5 秒对于生产工作流来说是切实可行的。
生产替代方案:通过 Atlas Cloud API 网关进行简化
对于需要高级并发、统一结算或高可用路由的企业级流水线,通过诸如 Atlas Cloud 等第三方管理网关进行集成是一种可行的生产方案。Atlas Cloud 的统一包装器可自动处理服务器端的队列和状态持久化,无需你在本地管理复杂的异步轮询循环。
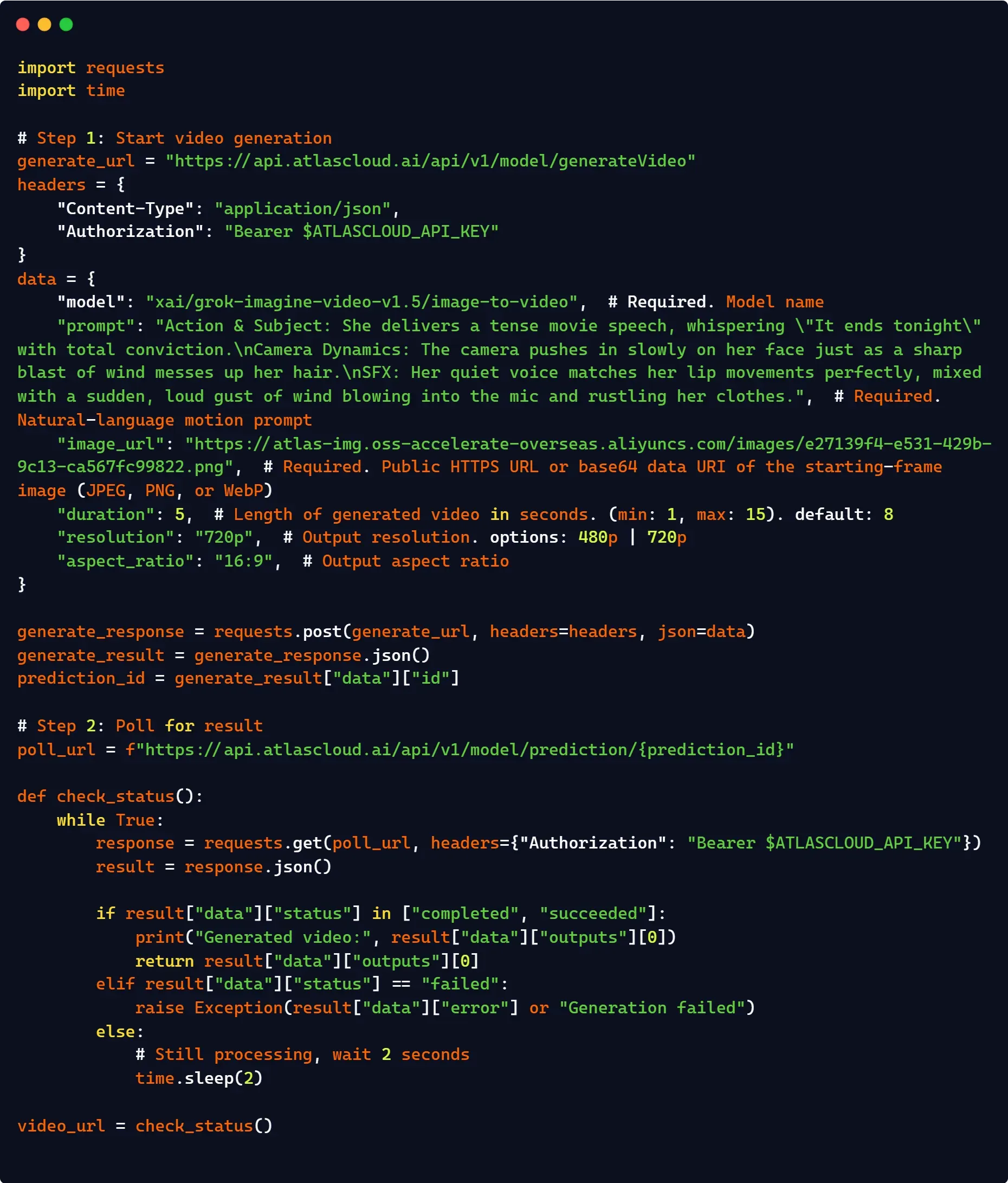
此外,它通过统一的 base URL 路由请求,实现了无缝替代,在最大限度减少代码变更的同时,解锁了通常超过标准 xAI 公共层阈值的企业级速率限制。
基准测试表现:成本、延迟与竞品对比
高保真视听输出只有在符合严格的计算预算和延迟要求时,才具备商业应用价值。为了了解 Grok 在市场中的地位,第三方压力测试将其生成速度和每秒成本与行业巨头进行了直接对比。
Grok Imagine Video 是否比其他 AI 视频工具更快、更省钱?
在独立基准测试中,答案基本是肯定的。Grok Imagine Video 在 Artificial Analysis Video Arena 的“图生视频”排行榜上首次亮相即位居第一,Elo 评分达到 1404 ±6,将字节跳动的 Seedance 2.0 挤出了榜首位置。
对标竞品对比
| 模型 | 开发者 | 最大时长 | 最大分辨率 | 原生音频 |
| Grok Imagine V1.5 | xAI | 15s | 720p | 是 |
| Seedance 2.0 对比 | 字节跳动 | 4–12s | 720p | 是 |
| Veo 3.1 | 8s | 1080p | 是 | |
| Sora 2 | OpenAI | 20s | 1080p | 是 |
| Runway Gen-4 | Runway | 10s | 1080p | 部分 |
推理速度与延迟
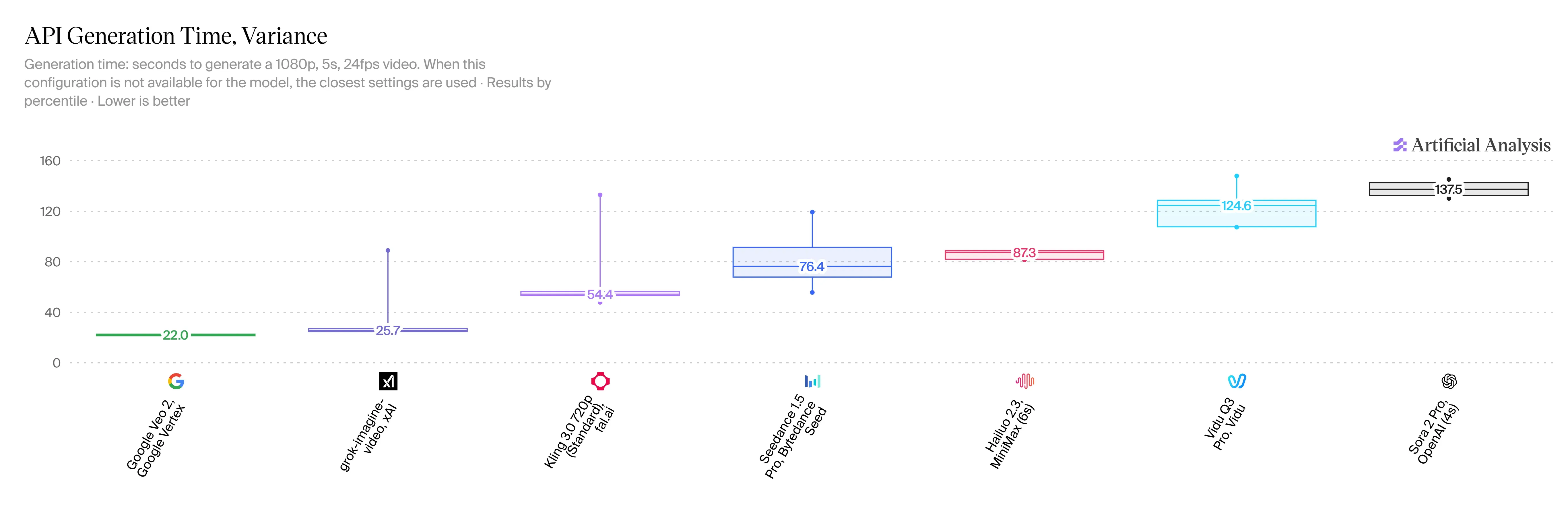
V1.5 的速度极其惊人,这对用户来说是一个巨大的利好。生成一个 5 秒的 720p 短片仅需 20 到 30 秒。与 HappyHorse 2.3 相比,等待时间缩短了 2 到 3 倍。虽然目前没有 Veo 3.1 的官方速度统计,但在线测试显示,类似片段的生成耗时超过一分钟。
定价结构
通过诸如 Atlas Cloud 等第三方 API 网关的按秒计费结构,生成视频的费用大约为每秒 USD0.096。以此计算,10 秒的短片成本约为 USD0.96,这使得独立创作者和小团队能够在进行最终成品制作前,低成本地试验多个提示词版本。
企业安全、数据隐私与内容合规
将专有媒体资产或面向客户的内容部署到任何基于云的 AI 系统都会引发必要的法律问题。对于商业制作公司而言,了解生成输入数据的流向及其隔离方式,与最终输出质量同样重要。
xAI 是否会使用我的 API 数据或生成的视频来训练其模型?
这是企业采用者最常问的问题之一,必须直接回答。根据 xAI 的开发者条款,通过平台处理的 API 输入和输出需接受内容政策审查以进行安全过滤,但均在**“默认隐私(Data Privacy by Design)”**原则下处理,将推理数据与公共训练流水线进行了隔离。
合规框架概览
提供 Grok Imagine 访问权限的第三方 API 网关提供商(如 Atlas Cloud)发布了其独立的合规认证:
| 合规标准 | 状态 |
| SOC 2 Type II 合规 | 已认证 |
| GDPR 数据驻留 | 已对齐 |
| HIPAA | 合格 |
专业用户的关键隐私边界
评估 Grok Imagine 用于商业工作流的专业人员应注意以下几点:
- 生成的视频输出以临时托管 URL 的形式返回,默认情况下不会永久存储。
- 内容政策审查会在交付前过滤输出以防止安全违规,但不会保留内容以供重复使用。
- 模型训练排除适用于 API 用户:你的提示词和生成的媒体内容不会被回填到公共模型的训练循环中。
- GDPR 数据驻留对齐意味着数据处理实践符合欧洲跨司法管辖区工作的团队的加工标准。
对于需要正式数据处理协议(DPA)或自定义保留策略的企业级部署,通过 x.ai 与 xAI 企业团队直接对接是后续的正确步骤。






