
أعادت Kling 3.0 تعريف صناعة الأفلام بالذكاء الاصطناعي بهدوء منذ لحظة إطلاقها في فبراير 2026. والخلاصة بسيطة: الحركة المطابقة للفيزياء الواقعية وهوية الشخصيات الثابتة لم تعد استثناءً، بل أصبحت هي المعيار الأساسي. وباعتبارها أحدث سلسلة نماذج ذكاء اصطناعي متعددة الوسائط من Kuaishou، تسد Kling 3.0 فجوة "الوادي غير المألوف" التي كانت تتطلب سابقاً فرق مؤثرات بصرية باهظة الثمن لإصلاحها في مرحلة ما بعد الإنتاج.
ما الذي يجعل Kling 3.0 تغير قواعد اللعبة في 2026؟
- بنية Omni One: نظام موحد يتعامل مع الفيديو والصورة والصوت معاً.
- مزامنة الشفاه الأصلية: محاذاة طبيعية للحوار بلغات متعددة دون الحاجة إلى دمج في مرحلة ما بعد الإنتاج.
- صفر انحراف بصري: استمرارية مثالية للقطات المتعددة مع الحفاظ على سلامة الوجوه والملابس والتناسب.
يضع هذا Kling 3.0 في منافسة مباشرة مع Seedance 2.0 و Veo 3.1 من Google كمعيار جديد لفيديو الذكاء الاصطناعي فائق الواقعية. من استمرارية اللقطات المتعددة إلى مزامنة الصوت الأصلية، يستعرض هذا الدليل "خطة اللعب" الدقيقة للحصول على نتائج بجودة سينمائية مع حركة شخصيات انسيابية في جيل مولدات الفيديو بالذكاء الاصطناعي الحالي.
ما هي Kling 3.0؟ تحليل محرك Omni One القائم على الفيزياء
في جوهرها، يعمل مولد الفيديو Kling AI على بنية Omni One الخاصة بـ Kuaishou، وهو نظام موحد يتعامل مع التوليد والفهم والتحرير في تمريرة واحدة بدلاً من معالجة الإطارات بشكل تسلسلي. فهو يصمم كيفية تحرك الأشياء في الفضاء، وكيف يتغير الضوء بمرور الوقت، وكيف تتفاعل العناصر المختلفة فيزيائياً، وهو ما يمثل الأساس لـ محاكاة الفيزياء الواقعية.
كيف يعمل الانتباه المشترك للزمكان ثلاثي الأبعاد على إصلاح الحركة "المتطايرة"
يعمل الانتباه المشترك للزمكان ثلاثي الأبعاد (3D Spacetime Joint Attention) والاستدلال بسلسلة الأفكار (Chain-of-Thought) على استخراج ونقل الحركة مع بقاء فيزياء العالم الحقيقي سليمة، مما يحافظ على الجاذبية والتوازن والتشوه والقصور الذاتي. يعني مكون "سلسلة الأفكار" أن النموذج يفكر فعلياً قبل أن يقوم بالريدر (Rendering)، حيث يقوم بتفكيك المطالبة (Prompt) إلى عناصر مشهد ومسارات حركة أولاً، ولهذا السبب يُشار إلى Kling الآن كبديل موثوق لـ Sora.
الفرق بين Kling V3 و Kling O3
يعتمد الاختيار بين Kling V3 و Kling O3 على المكان الذي يبدأ فيه سير عملك الإبداعي. تعمل Kling V3 كقوة دافعة تعتمد على المطالبات لإنشاء فيديوهات فائقة الواقعية من الصفر، بينما تعمل Kling O3 كإطار عمل يعتمد على المراجع، ومصمم للتحرير الدقيق، واستنساخ الشخصيات، والتحكم القائم على الأصول.
| الميزة / القدرة | Kling V3 (Video 3.0) | Kling O3 (Omni 3.0) |
| هدف سير العمل الأساسي | التركيز على المطالبة: الأفضل للتحويل من نص إلى فيديو وإنشاء لقطات سينمائية من الصفر. | التركيز على التحكم: الأفضل للتحرير المستند إلى مراجع، ونقل الأنماط، وإعادة مزج الأصول الموجودة. |
| أنماط الإدخال المدعومة | مطالبات نصية مكثفة، صور ثابتة فردية (I2V) | مراجع صور متعددة (تصل إلى 4)، مقاطع فيديو مرجعية، نص، وفيديو موجود. |
| المرجع إلى فيديو (R2V) | لا يوجد مسار مخصص (يعتمد كلياً على مطالبات النص/الصورة) | نعم (دعم كامل): يربط مظهر الشخصية/المنتج عبر المقاطع باستخدام مراجع صور متعددة. |
| تحرير فيديو إلى فيديو (V2V) | غير مدعوم | نعم: يتضمن نقل الأنماط، وتغيير الخلفية، والاستبدال السلس للكائنات/الشخصيات. |
| المرجعية المشتركة لعدة شخصيات | متقدم: يتعامل مع مشاهد المجموعات المعقدة بـ 3 شخصيات أو أكثر مع التزام دقيق بالنصوص. | جيد (يحافظ على الاستقرار، ولكنه مُحسَّن أساساً لاتساق الأصول الفردية). |
| الصوت ومزامنة الشفاه الأصلية | نعم (ينشئ حواراً متزامناً، وتعليقاً صوتياً، ومؤثرات صوتية محلياً) | نعم (يتشارك نفس ميزات محاذاة الصوت الأصلية وربط الأصوات متعددة اللغات). |
| أقصى مدة للمقطع | تصل إلى 15 ثانية لكل توليد فردي | تصل إلى 15 ثانية (تمتد فترات التوليد إلى 30 ثانية في أوضاع توجيه فيديو محددة). |
| التكلفة وسرعة التكرار | تكلفة رصيد أقل؛ مثالية لاختبار المسودات السريع وتكرار المطالبات عالي السرعة. | تكلفة رصيد أعلى؛ مصممة للريدر الإنتاجي النهائي وفحوصات الاتساق عالية المخاطر. |
يتشارك كلا النموذجين في بنية محرك Omni One الموحدة الرائدة، مما يعني أن Kling AI Lip Sync وألوان HDR بدقة 16-بت تأتي كمعيار قياسي، مما يعزز كل مقطع سينمائي من Kling AI بغض النظر عن مسار النموذج الذي تختاره.
إتقان مراجع العناصر للحصول على شخصيات ذكاء اصطناعي متسقة بنسبة 100%
لطالما كان الانحراف البصري، وهو تحول وجه الشخصية أو ملابسها أو نسبها بين اللقطات، هو الخلل الأكثر إحباطاً في فيديوهات الذكاء الاصطناعي. تُعد طريقة مرجعية العناصر في Kling أقرب شيء إلى "قاتل الانحراف البصري" الحقيقي المتاح حالياً، لأنها تتوقف عن معاملة كل إطار كخمن جديد، وبدلاً من ذلك تربط الشخصية بملف هوية ثابت.

خطوة بخطوة: تثبيت شخصية على نموذج محدد
- قم ببناء عنصر من حوالي أربع زوايا لنفس الشخص، مما يمنح النموذج إحساساً ثلاثي الأبعاد بالهوية.
- أو تخطَّ الصور الثابتة تماماً: قم بإنشاء أو تسجيل عينة صوتية مدتها 3 إلى 8 ثوانٍ ليقوم Kling باستخراج السمات الصوتية للشخصية والحفاظ على اتساق الهوية عبر كل لقطة.
- في وضع "صورة إلى فيديو"، قم بتشغيل ميزة "Bind Subject" لتثبيت الوجه والملابس، ثم قم بطبقة أداة القصص المصورة متعددة اللقطات للحفاظ على هذا المظهر طوال مدة المقطع البالغة 15 ثانية.
- أعد استخدام العنصر المحفوظ عبر توليدات منفصلة، وليس مجرد مقطع واحد، للحصول على نتائج اتساق شخصيات حقيقية في فيديوهات الذكاء الاصطناعي بمرور الوقت.
الحفاظ على استقامة الشخصيات المتعددة
المرجعية المشتركة لعدة شخصيات هي ما يمنع شخصين أو ثلاثة في نفس المشهد من الاندماج في وجه واحد. من خلال تحديد الحوار بوضوح لكل شخصية في مطالبتك، يقوم النموذج تلقائياً بمطابقة كل شخصية بخطوطها المقابلة، حتى عبر التبادلات ثنائية اللغة في لقطة واحدة.
| سير العمل | الأفضل لـ |
| عنصر متعدد الصور (2-4 صور) | شخصية رئيسية متكررة عبر الحلقات |
| مرجع شخصية فيديو | المشاهد المعتمدة على الأداء، تمثيل الحركة |
| المرجعية المشتركة لعدة شخصيات (3+) | حوارات المجموعات، طاقم عمل جماعي |
هندسة المطالبات المتقدمة للواقعية السينمائية بدقة 4K والفيزياء الواقعية
تتعامل هندسة مطالبات Kling AI الجيدة مع النموذج كـ "مصور سينمائي"، وليس كقائمة أمنيات. يستجيب النظام بقوة للغة الكاميرا المحددة، نظراً لأنها تحدد الإحساس البصري الكامل للمخرجات، لذا فإن التعليمات حول كيفية التقاط اللقطة تهم أكثر من قائمة طويلة بما يوجد في الإطار.
مطالبة قصيرة مقابل مطالبة طويلة: مقارنة واقعية
| نمط المطالبة | مثال | النتيجة |
| قصيرة | "امرأة تمشي تحت مطر نيون" | إعدادات ذكاء اصطناعي عشوائية، فيزياء تتبع مسطحة، وتأثيرات إضاءة نيون مبالغ فيها تتعارض مع البيئة. |
| طويلة | لقطة سينمائية بالحركة البطيئة، امرأة بمعطف واقٍ من المطر ثقيل تمشي تحت مطر ليلي مظلم، إضاءة جوية واقعية، وزن نسيج طبيعي، تدرج ألوان بارد، HDR 16-بت، أسلوب صناعة أفلام احترافي. | استقرار هيكلي مثالي، فيزياء مواد طبيعية، وجو سينمائي غامر للغاية |
دعنا نشاهد نتائج الفيديو الفعلية. المقطع الموجود على اليسار (المطالبة الطويلة) يبدو أفضل بكثير وأكثر تماسكاً من المقطع الموجود على اليمين. دعنا نلقي نظرة فاحصة على اللقطات لنرى بالضبط لماذا يتفوق الجانب الأيسر على الأيمن:
إذا قمت بتحليل هذه الرندرات الخام بدقة، فسترى كيف أن الحفاظ على نظافة الأمور يؤدي فعلياً إلى تمريرة رندرة أكثر انضباطاً وسينمائية. يعود الأمر إلى ثلاث تفاصيل بصرية حاسمة:
- التركيز السردي النقي: الفيديو الأيسر يثبت عين المشاهد تماماً على الشخصية. عمق الخلفية وعناصر المطر لا تسرق الأضواء، والتكوين النظيف يترك مساحة فنية كافية للتحرير في مرحلة ما بعد الإنتاج.
- الحركة الفيزيائية الطبيعية: راقب كيف يتحرك معطف المطر. القماش على اليسار يتدلى، وينطوي، ويتأرجح بفعل الجاذبية الحقيقية أثناء مشيها. ولا يحتوي على اهتزاز الحواف الغريب الذي يحدث عندما يرتبك نموذج الذكاء الاصطناعي بسبب كثرة التفاصيل.
- إضاءة سينمائية بسيطة: الجانب الأيمن يحتوي على انعكاسات نيون براقة، لكن الألوان المظلمة والباردة للمطر الليلي على اليسار تخلق مزاجاً أفضل بكثير. إنه يبدو كفيلم حقيقي بدلاً من مؤثر رخيص.
قبل أن تحرق أرصدتك المميزة في رندرة عالية المخاطر من فئة Pro، قاوم الرغبة في تكديس عبارات وصفية طويلة دون تفكير. المزيد من الكلمات لا يعني تلقائياً جودة أفضل. عندما يتم حشر الكثير من حركات الكاميرا المعقدة والإشارات البيئية معاً، يمكن أن يعقد الأمر الأمور لمحرك الاستدلال الفيزيائي، مما يسبب تشوهات موضعية. استخدم دائماً "وضع المسودة" (Draft Mode) أولاً لاختبار استقرار الموضوع بمطالبة أساسية بسيطة، ثم أضف تدريجياً معدلات الإضاءة والملمس بمجرد التأكد من أن اللقطة مضبوطة.
نصيحة إنتاجية سريعة: إذا قمت بتشغيل دفعات Pro Mode ثقيلة من خلال متصفح الويب القياسي، فستواجه غالباً اختناقات في قائمة الانتظار أو فترات توقف للرندرة أثناء ساعات الذروة. لتخطي الانتظار تماماً، قمنا بإنشاء مقاطع المقارنة هذه جنباً إلى جنب مباشرة من خلال واجهة برمجة تطبيقات Atlas Cloud Kling Text-to-Video API. إنها تعمل كخط أنابيب مستقر وعالي الأداء يقوم بتشغيل توليداتك بسلاسة في الخلفية، مما يجعلها حلاً ممتازاً لسير العمل إذا كنت تختبر دفعات من مطالبات متعددة أو تشغل سكربتات برمجية دون تأخير في الواجهة.
توجيه ميكانيكا الكاميرا
من أجل التحكم السينمائي في الكاميرا، اذكر حركة واحدة لكل مطالبة بدلاً من تكديس التأثيرات، لأن دمج حركات مثل "تقريب دولي مع الدوران لليسار" يميل إلى إنتاج حركة كاميرا لا تتطابق مع الوصف:
- زووم دولي: "تأثير تقريب دولي، تحول الإضاءة إلى الأزرق، بينما يتحول تعبير الرجل من القلق إلى الرعب"
- لقطة التتبع: "تتبع الكاميرا بجانبه على مستوى العين، ثم تندفع برفق إلى لقطة قريبة"
- تركيز الرف (Rack focus): "ينتقل التركيز من المحارب في المقدمة إلى الوحش الواقف خلفه"
إشارات فيزيائية تبيع الواقعية
تفاصيل الملمس الملموسة مثل الحبيبات، وتوهج العدسة، والانعكاسات، وبريق القماش، والتكثف، والدخان، والعرق تجعل المخرجات تبدو واقعية فيزيائياً، وتسمية مصادر الضوء الحقيقية مثل لافتات النيون، أو ضوء الشموع، أو الساعة الذهبية تنتج نتائج أفضل من مصطلحات غامضة مثل "إضاءة درامية".
التثبيت على دقة 4K، وHDR، وطول المقطع
من أجل إنشاء أفلام سينمائية بدقة 4K بالذكاء الاصطناعي، حدد وضع Pro؛ تصل المخرجات الأصلية إلى 3840×2160 مع ألوان HDR بدقة 16-بت، جاهزة للبث دون الحاجة إلى تكبير إضافي، مما يجعل هذا الفيديو بتقنية HDR 16-بت بالذكاء الاصطناعي حقاً. يبلغ أقصى طول للمقطع في Kling AI 3.0 لعام 2026 15 ثانية لكل توليد فردي، مع وضع اللقطات المتعددة الذي يربط عدة مقاطع في تسلسل أطول.
كيفية استخدام سير عمل المخرج بالذكاء الاصطناعي والقصص المصورة متعددة اللقطات
يسمح سير عمل المخرج بالذكاء الاصطناعي للمبدعين ببناء مشهد منظم دون لمس محرر الخط الزمني. فبدلاً من توليد مقاطع منفصلة وربطها معاً في مرحلة ما بعد الإنتاج، يقوم تخطيط القصص المصورة متعدد اللقطات بأسلوب Kling بحزم ما يصل إلى ست لقطات كاميرا في توليد واحد.
بناء مشهد دون تحرير من طرف ثالث
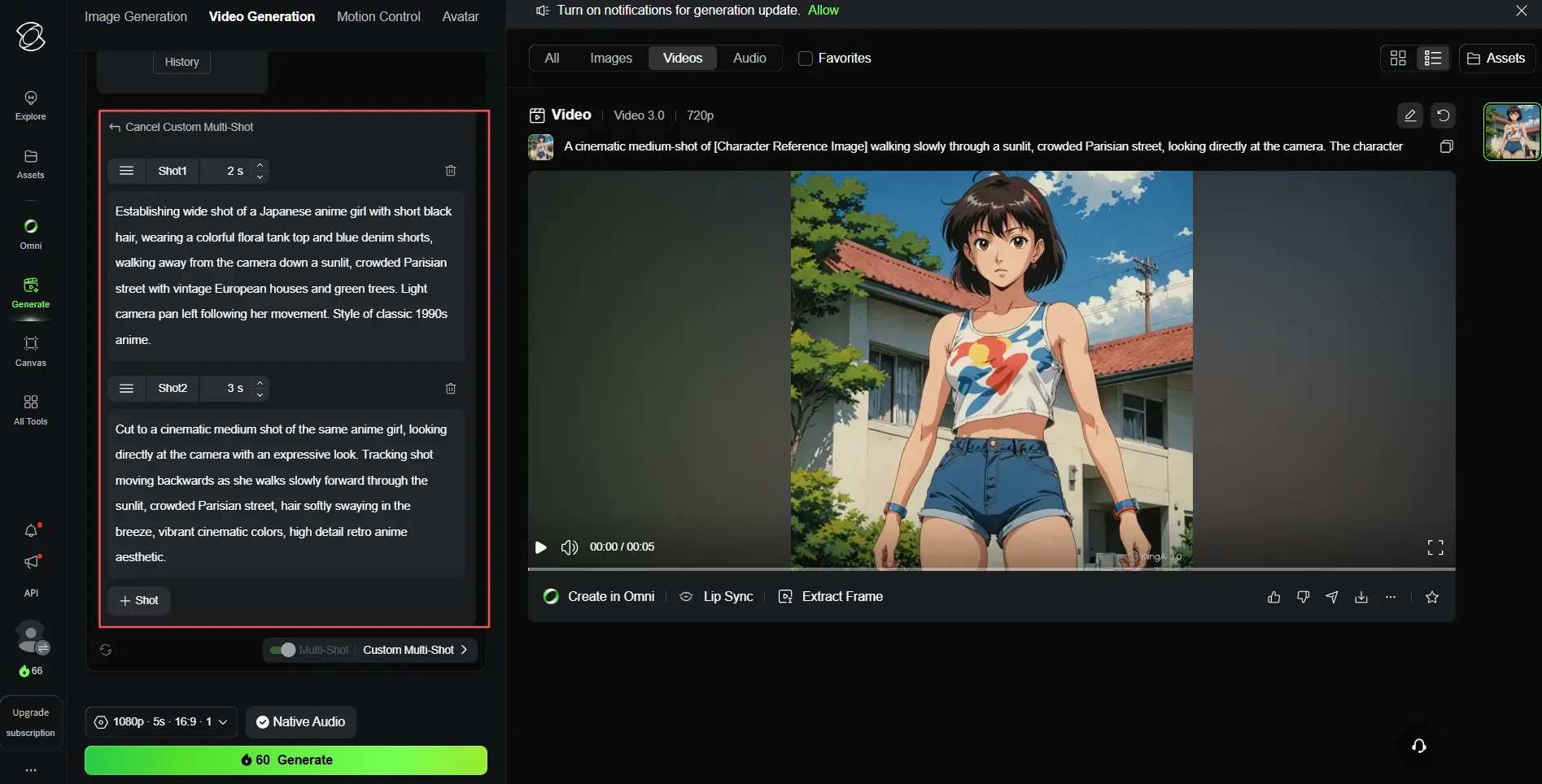
يستخدم وضع "لوحة القصص الذكية" الذكاء الاصطناعي لتقسيم قصتك إلى لقطات مختلفة بأفضل زوايا الكاميرا والانتقالات تلقائياً. أما وضع "لوحة القصص المخصصة" فيتيح لك ضبط الوقت وحركة الكاميرا والتخطيط لكل لقطة بنفسك، وهو أمر رائع للمحادثات أو التوقيت الدقيق. كلاهما يبقي كل شيء داخل مقطع فيديو واحد بالذكاء الاصطناعي مدته 15 ثانية، لذا تبدو شخصياتك وإضاءتك متطابقة عبر كل قص دون عمل إضافي. قد تبدو الانتقالات جامدة قليلاً مقارنة بمحرر بشري، لذا استخدم هذه الميزة كمسودة أولية رائعة بدلاً من فيديو نهائي للمشاريع الكبيرة.
Kling Standard مقابل مستوى Pro: أيهما تختار للرندرة
| الوضع | السرعة | الأفضل لـ |
| وضع المسودة (Draft) | أسرع بـ 5 إلى 20 مرة، وغالباً ما يقدم معاينات في ثوانٍ | اختبار المطالبات وزوايا الكاميرا قبل إنفاق الأرصدة |
| قياسي (Standard) | حوالي 1 إلى 3 دقائق لمقطع مدته 10 ثوانٍ | التسليمات السريعة حيث تكون دقة 1080p كافية |
| مستوى Pro | حوالي 3 إلى 8 دقائق | مخرجات نهائية بجودة سينمائية مع محاكاة فيزيائية كاملة ودقة 4K |
إذن كم تستغرق Kling Pro في الرندرة؟ عادةً من 3 إلى 8 دقائق لكل مقطع، على الرغم من أن أوقات المعالجة تختلف بناءً على حمل الخادم ومستوى أولوية خطتك. كما يستهلك مستوى Pro أرصدة أكثر بشكل ملحوظ من Standard، لذا احتفظ به للقطات التي سيتم إطلاقها فعلياً.
سير عمل عملي
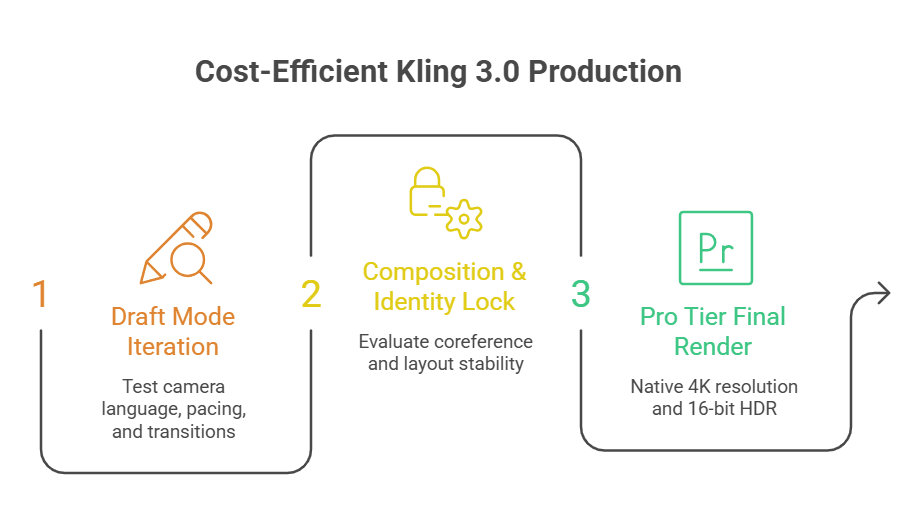
لتحقيق أقصى استفادة من ميزانيتك دون التضحية بالجودة، لا تقفز مباشرة إلى الرندرة من فئة Pro. بدلاً من ذلك، طبق دورة "Draft-to-Pro" القياسية في الصناعة لتوفير ما يصل إلى 80% من أرصدة Kling الخاصة بك.
-
التكرار والتحسين في وضع المسودة: 5-20 ثانية لكل رندرة
قم بتوليد 5 إلى 10 تكرارات باستخدام وضع المسودة. ركز كلياً على اختبار لغة الكاميرا، والسرعة، والانتقالات متعددة اللقطات. يمنحك وضع المسودة تمريرة معاينة فورية تقريباً مقابل جزء بسيط من التكلفة.
-
تثبيت التكوين والهوية: مرحلة المراجعة
قم بتقييم مقاطع المسودة الخاصة بك. تحقق من استقرار المرجعية المشتركة للشخصيات المتعددة وتأكد من أن لقطات الكاميرا تبدو طبيعية. بمجرد تثبيت التأطير ومسارات الحركة، توقف عن التكرار.
-
التبديل إلى مستوى Pro للرندرة النهائية: 3-8 دقائق لكل رندرة
قم بتبديل إعداداتك إلى وضع Pro. احتفظ برقم البذرة (Seed) والمطالبة الدقيقين، ثم قم بتشغيل الرندرة النهائية لفتح دقة 4K الأصلية، وألوان HDR بدقة 16-بت، ومحاكاة فيزيائية كاملة دقيقة.
ملاحظة: فكر في وضع المسودة كرسوماتك بالقلم الرصاص ومستوى Pro كلوحتك الزيتية النهائية. لا تنفق أبداً أرصدة مميزة على مطالبة أو حركة كاميرا لم تتحقق منها في وضع المسودة أولاً.
مزامنة الصوت الأصلية وتحرير فيديو إلى فيديو: كتاب الإنتاج
يتصرف Kling 3.0 كمحرك متعدد الوسائط واحد بدلاً من نموذج فيديو مضاف إليه أداة صوت منفصلة. مزامنة الصوت الأصلية في Kling 3.0 تولد تعليقات صوتية متزامنة، وحواراً مع مزامنة الشفاه، ومؤثرات صوتية، وموسيقى، كل ذلك في تمريرة واحدة، وليس كخطوة منفصلة في مرحلة ما بعد الإنتاج.
درس سريع حول مزامنة الشفاه في Kling AI
| الخطوة | أداة الإجراء | سير عمل الإنتاج (ماذا تنقر بالضبط) |
| 01. استخراج الصوت | إدخال المرجع الصوتي | قم بتحميل أو تسجيل عينة صوتية واضحة مدتها 3 إلى 8 ثوانٍ إلى النظام. سيقوم Kling تلقائياً باستخراج السمات الصوتية الأساسية والجرس. |
| 02. ربط الشخصية | مرجعية العناصر | اربط عينة الصوت تلك مباشرة بعنصر هوية الشخصية المحفوظ داخل لوحة التوليد. |
| 03. حوار المطالبة | مربع الشخصيات المتعددة | حدد السطور المنطوقة مباشرة ضمن نص مطالبتك. للمشاهد ثنائية اللغة، اكتب سطور الحوار بالضبط بالإنجليزية، أو الصينية، أو اليابانية. |
| 04. المخرجات النهائية | رندرة موحدة | اضغط على التوليد. يقوم محرك Omni One بمحاذاة حركة الشفاه بدقة الإطار مع المسار الصوتي أصلياً في تمريرة واحدة. |
نصيحة احترافية للحملات الدولية: نظراً لأن المزامنة تتم عبر بنية واحدة، تظل مزامنة الشفاه في Kling AI دقيقة تماماً حتى لو تبدلت الشخصية بين اللغات في منتصف الفيديو—تتشكل هندسة الشفاه تلقائياً لتتطابق مع الصوتيات الإقليمية المتغيرة.
نشر توليد الصوت الأصلي ثنائي اللغة
يدعم النموذج أصلياً الإنجليزية، والصينية، واليابانية، والكورية، والإسبانية، ويتعامل مع اللهجات الإقليمية، ويسمح للشخصيات بالتبديل بين اللغات في منتصف الفيديو مع حركات شفاه متزامنة طوال الوقت. هذه هي الآلية الكامنة وراء ما يتم تسويقه كـ ذكاء اصطناعي لمزامنة الشفاه بدقة الإطار: حدد سطر كل شخصية مباشرة في المطالبة، ويقوم النظام بمطابقة الحوار مع الوجه الصحيح تلقائياً، حتى عبر التبادلات ثنائية اللغة.
التحكم في الحركة ووضع التحرير في Kling 3.0
للعمل على تحرير فيديو إلى فيديو بالذكاء الاصطناعي، قم بتحميل صورة مرجعية لمظهر الشخصية وفيديو مرجعياً للحركة التي تريدها أن تتبعها. يشكل وضعان للتوجيه النتيجة: يحافظ اتجاه الصورة على مواجهة الشخصية لنفس اتجاه الصورة للمقاطع التي تصل مدتها إلى 10 ثوانٍ، بينما يطابق اتجاه الفيديو اتجاه الشخصية في الفيديو المرجعي للتسلسلات التي تصل مدتها إلى 30 ثانية.
يُعد التحكم في حركة Kling 3.0 ووضع التحرير الخاص به مفيداً حقاً في:
| نوع التحرير | ماذا يفعل |
| نقل الأنماط | يطبق جمالية فيديو واحد على آخر باستخدام وضع مرجع الميزات |
| تغيير الخلفية | يغير البيئات مع الحفاظ على الشخصيات في المقدمة سليمة |
| استبدال الكائن/الشخصية | يحول الشخصيات والإعدادات مع بقاء حركة الكاميرا الأصلية والحركة سليمة |
نظراً لأن الصوت والحركة والتحرير تعمل من خلال بنية واحدة، تصل المخرجات إلى جودة فيديو ذكاء اصطناعي جاهز تجارياً دون الحاجة إلى الذهاب والعودة عبر مجموعة VFX منفصلة.
هل Kling 3.0 مناسب لسير عملك وميزانيتك؟
عبر مراجعة Kling 3.0 هذه، يظل هناك حكم واحد واضح. بعد اختباره بشدة لمدة 48 ساعة، يصفه المراجعون بأنه ربما يكون نموذج الفيديو العام الأكثر قدرة المتاح حالياً، على قدم المساواة مع Veo 3.1 وربما يتفوق عليه في بعض الجوانب.
أين يقصر؟
هناك تحذيران صادقان يهمان سير عمل إنتاج الفيديو بالذكاء الاصطناعي:
- إنه يعاني قليلاً مع العناصر المرئية التي تعتمد أكثر على التصميم أو التوضيح، لذلك يظل Grok الخيار الأفضل للمحتوى التجريدي أو القائم على الرسوم.
- استغرقت Kling 3 Pro أكثر من 3 دقائق لرندرة بعض المقاطع، مقارنة بـ Grok الذي قد يفعل ذلك في 30 ثانية، وتتصاعد تكاليف الأرصدة بسرعة عندما تحتاج إلى عدة تكرارات للحصول على لقطة قابلة للاستخدام.
إذن، هل Kling AI يستحق ذلك؟
تأتي Kling 3.0 مع واحدة من أكثر الخطط المجانية سخاءً في هذه الفئة، حوالي 66 رصيداً شهرياً بدون الحاجة إلى بطاقة ائتمان.
| اختر Kling 3.0 عندما | اختر منافساً عندما |
| تحتاج إلى حركة دقيقة فيزيائياً، ولوحات قصص متعددة اللقطات، وصوت أصلي متعدد اللغات | تعمل مع رسوم توضيحية أو مرئيات تجريدية (Grok)، أو تحتاج إلى أسرع وقت تسليم |
| الميزانية وسرعة التكرار هما الأهم | تحتاج إلى نظام Google البيئي (Veo 3.1) أو استمرارية أطول للقطة الواحدة |
بالنسبة للمسوقين، والمبدعين المنفردين، وصانعي الأفلام الذين يقومون بمعاينة المشاهد، تستحق Kling 3.0 مكانتها كـ أفضل نموذج فيديو ذكاء اصطناعي للأغراض العامة من حيث الواقعية والسعر. بالنسبة للرسومات القائمة على التصميم، قم بإقرانها بأداة أسرع وصديقة للتوضيح بدلاً من ذلك.
الخاتمة: كيفية التعامل مع Kling 3.0 اليوم
تعد Kling 3.0 أكثر بكثير من مجرد ترقية بسيطة. إنها تغير قواعد اللعبة تماماً باستخدام نظام ذكي مدفوع بالفيزياء الحقيقية والأصول المباشرة. من خلال حزم الفيديو، وأدلة الحركة، والصوت متعدد اللغات في إعداد Omni One واحد، فإنها تتخلص من التبديل الفوضوي بين الأدوات المختلفة التي كانت تبطئ المبدعين المنفردين دائماً.
لتوفير أرصدتك المميزة والحصول على أفضل النتائج من المنصة، استخدم قائمة التحقق الإنتاجية السريعة هذه:
- تصرف كمخرج: التزم بحركات كاميرا واضحة وأنماط إضاءة محددة بدلاً من تكديس كلمات وصفية عديمة الفائدة.
- قم بتشغيل دورة "Draft-to-Pro": لا تلتزم أبداً بأرصدة فئة Pro لمطالبة غير محققة. قم ببناء وضبط وتثبيت وتيرة سردك في وضع المسودة أولاً.
- ثبّت استمرارك: استفد من مرجعية العناصر والمرجعية المشتركة لعدة شخصيات في وقت مبكر من النص الخاص بك ليكون بمثابة قاتل نهائي للانحراف البصري.
- بسّط خط الإنتاج: إذا كنت تشغل سكربتات مطالبات معقدة أو دفعات توليد ثقيلة متعددة اللقطات، فتجاوز واجهة الويب تماماً واستخدم قناة Atlas Cloud Kling Text-to-Video API المستقرة لتخطي طوابير الانتظار.
لم يكن من السهل أبداً صنع فيديوهات ذكاء اصطناعي بجودة سينمائية. ابدأ صغيراً، واختبر حركات الكاميرا أولاً، ودع إعداد الفيزياء يقوم بالعمل الشاق لمشروعك القادم.






