العائق الحقيقي في فيديوهات الذكاء الاصطناعي ليس أن المخرجات تبدو خاطئة. العائق هو أنها تبدو بطيئة.
1. لماذا تفشل مقاطع الذكاء الاصطناعي التي تستغرق 15 ثانية في إثارة الإعجاب؟
أي شخص أمضى وقتاً حقيقياً مع Seedance 2.0 سيصطدم بنفس السقف: عندما تطلب مقطعاً مدته 15 ثانية، يمنحك النموذج ثلاث أو أربع لقطات - وهذا كل شيء.
أنت تغذيه بمشهد قتال، وما يعود إليك هو "مقاتل يدخل ← يرفع سلاحه ← يتجمد". إعداد، حركة، نهاية. ثم تظهر شارة النهاية.
لكن هذه ليست الطريقة التي يُقرأ بها القتال على الشاشة. قبل أن تهبط اللكمة، يستدير الكتف. وبعد المراوغة، يكون الهجوم المضاد قيد التحضير بالفعل. المطاردة الواسعة تنتقل إلى لقطة قريبة جداً، والتي تنتقل إلى تأثير الحركة البطيئة. التوتر يأتي من كثافة التقطيع، وليس من جعل أي لقطة فردية تبدو أجمل.
والنموذج لن يمنحك ست عشرة لقطة من تلقاء نفسه، بغض النظر عن الطريقة التي تكتب بها الـ prompt.
تلك هي المشكلة. وإليك كيف قمنا بحلها.
2. ثلاثة محاور غيرت سير العمل
بعد تشغيل عرض توضيحي كامل لحركة شخصية واحدة من البداية إلى النهاية، توصلنا إلى ثلاثة أمور مهمة:
① توتر الحركة يأتي من كثافة التقطيع، لا من جودة اللقطة الواحدة. توقف عن محاولة جعل لقطة واحدة مثالية. قسّم الـ 15 ثانية إلى لوحة قصص (storyboard) مكونة من 16 خلية أولاً، ثم قدمها لنموذج الفيديو.
② القوة الحقيقية لـ GPT Image 2 تكمن في فهم السيناريو وتخطيط اللقطات، وليس في ثبات الأسلوب. أردنا في البداية أن يقوم GPT Image 2 بتثبيت أسلوب واحد عبر السلسلة بأكملها. بعد الاختبار، تقبلنا أن المرجع إلى الفيديو يميل طبيعياً نحو الرسوم الحاسوبية (CG) - ولا توجد طريقة نظيفة لفرض ذلك. لكن ما يمكن لـ GPT Image 2 فعله — قراءة السيناريو، وتخطيط اللقطات، وتصميم لوحة قصص من 16 خلية — هو أمر لا يقوم به أي نموذج آخر في مجموعتنا بنفس الكفاءة.
③ خط العمليات بالكامل يعمل بمفتاح API واحد من AtlasCloud. حيث تعيش كل من GPT Image 2، وNano Banana 2، وSeedance 2.0 في نفس مجموعة النماذج على AtlasCloud. مفتاح واحد. نقطة نهاية واحدة. فاتورة واحدة. حصة واحدة. لا حاجة للتعامل مع موردين متعددين.
3. اختبار الإجهاد لشخصية واحدة
لاختبار GPT Image 2 بشكل حقيقي، اخترنا أصعب شخصية يمكن أن نفكر فيها.
تعرفوا على Ranx — مشغلة تكتيكية سيبرانية. تتميز بضفيرتين بلون الذهب الرملي. وأربع قطع من المعدات غير المتماثلة تماماً:
- جورب أسود يصل للفخذ على الساق اليمنى فقط
- جراب صلب أحمر على الفخذ الأيمن فقط
- خطوط زرقاء سماوية (Cyan) على الركبة اليمنى فقط
- سلك أسود سميك يمتد من الجهة الخلفية اليمنى لحزامها وصولاً إلى ساقها اليسرى
الصورة المرجعية الوحيدة التي قدمناها للنموذج كانت لقطة خلفية بثلاثة أرباع. كان على النموذج استنتاج الواجهة، والجوانب، والتعبيرات، وتفاصيل السلاح — وعدم عكس أي من هذه الاختلافات الأربعة.
النتيجة: توليد واحد. ست لقطات دوران، أربع دراسات للرأس، أربع تعبيرات، لوحة السلاح، اليدين، القدمين — كلها في صفحة واحدة. تم تثبيت الاختلافات الأربعة جميعاً. صفر أخطاء في الانعكاس.


البيئة التي تعاملنا معها كمرجع تصميم نهائي (زقاق خلفي مبلل بطابع السايبربانك، جماليات لعبة Stray):

4. اختبار A/B الذي يثبت صحة الطريقة
هذه هي التجربة التي يستند إليها سير العمل بأكمله. نفس السيناريو. نفس ورقة الشخصية. نفس مرجع المشهد. المتغير الوحيد هو وجود لوحة قصص (storyboard) من عدمه.
التحكم: الـ prompt بالنص فقط، بدون لوحة قصص
المدخلات لـ Seedance 2.0 في خاصية المرجع إلى الفيديو:
- 1× ورقة شخصية
- 1× مرجع مشهد
- نص مفصل مدته 15 ثانية يصف أربعة تقطيعات حادة
اللقطات مقروءة والحرفة جيدة. لكن المقطع بالكامل يُعرض كـ ثلاث نبضات بطيئة — المشي إلى الزقاق، رفع السلاح، التجمد. يبدو كعرض تجريبي للشخصية، وليس قتالاً.
الاختبار: مع لوحة قصص من 16 خلية
طلبنا من GPT Image 2 تقسيم نفس السيناريو إلى لوحة قصص 4×4 = 16 خلية، مع تصنيف كل خلية بـ:
- رقم اللقطة (① ② ③ … ⑯)
- حجم اللقطة (WIDE / MS / CU / ECU)
- سهم حركة الكاميرا (→ ↘ ↙ ↑ ↓ ↗)
- ملاحظة إيقاعية ("ارتفاع ثابت" / "تقطيع حاد" / "تأثير" / "لقطة قتل" / "خاتمة")
- ملاحظة قصيرة للمخرج بالصينية المكتوبة يدوياً — قرار يعتمد على الكثافة، حيث أن الصينية تسمح بتضمين المزيد من النوايا الإخراجية في خلية صغيرة (كلا النموذجين GPT Image 2 وSeedance 2.0 يقرآن كلتا اللغتين بنفس الكفاءة)
ثم سطر واحد كـ prompt لـ Seedance 2.0 في خاصية المرجع إلى الفيديو:
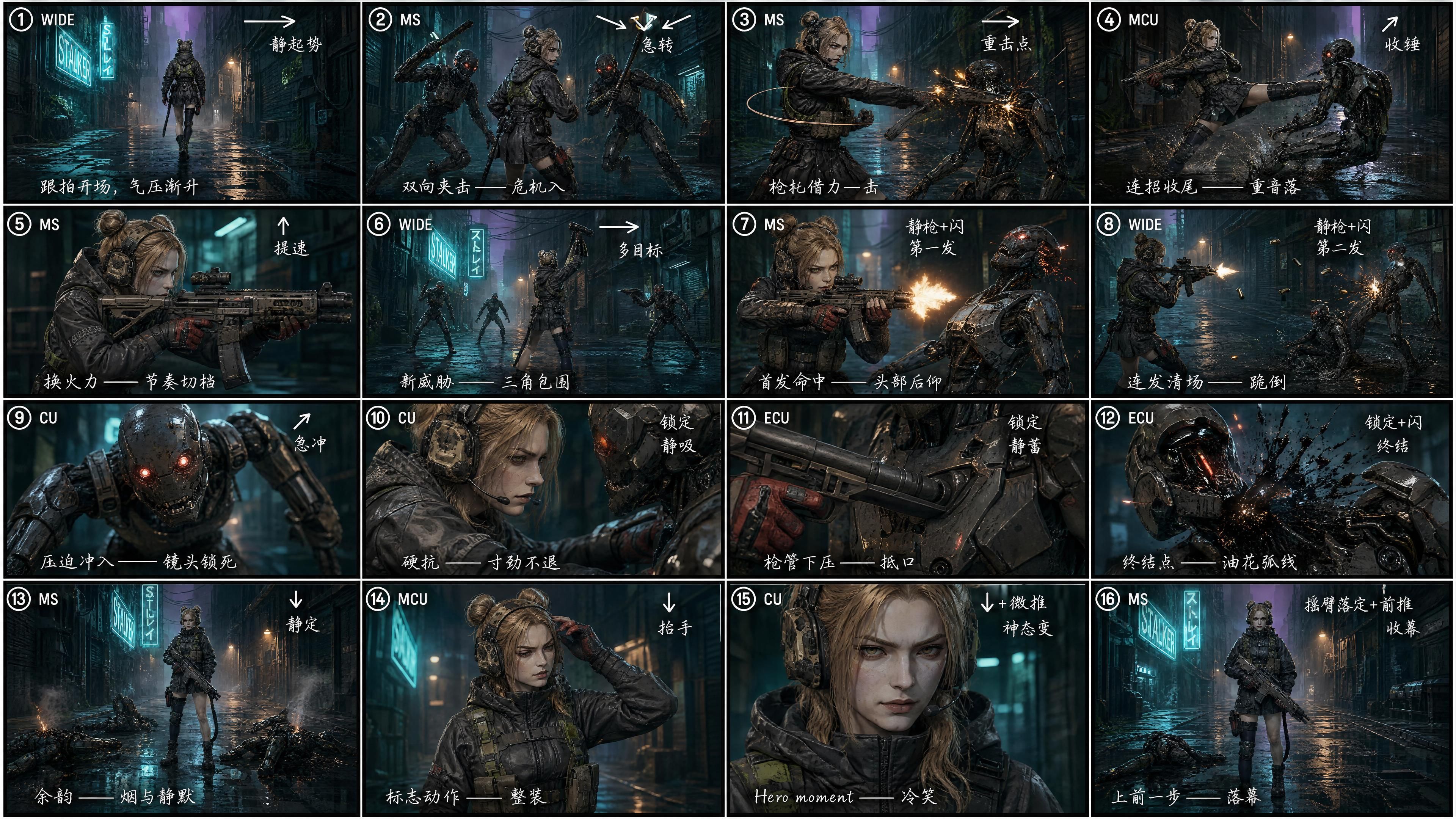
"أنشئ فيديو يتبع بدقة الصورة المرجعية 3 كلوحة قصص. شعور سينمائي قوي ولغة لقطات، ديناميكيات مبالغ فيها، وحركة ذات تأثير قوي."
الفرق واضح دون الحاجة للقياس. كثافة التقطيع تقفز بمقدار 4 أضعاف تقريباً. مطاردة واسعة إلى لقطة متوسطة على الكتف إلى لقطة قريبة جداً من الفوهة وصولاً إلى إنهاء بوضعية البطل — خمس عشرة ثانية، ممتلئة بالكامل. نفس السيناريو، إيقاع مختلف. الإصدار الأول يبدو كعرض تجريبي. الثاني يبدو كإعلان ترويجي.
هذه هي الفكرة الأساسية لسير العمل هذا: GPT Image 2 ليس لتثبيت الأسلوب. بل هو لتقسيم السيناريو إلى سلسلة لقطات مكثفة.
5. التوسع: مبارزة بين مقاتلين
بمجرد أن أصبح إصدار الشخصية الواحدة نظيفاً، توسعنا إلى مبارزة. الجزء الأصعب في قتال شخصين هو تثبيت أربعة أشياء في وقت واحد — الشخصية أ، الشخصية ب، البيئة، وإيقاع الحركة.
بدلاً من إنشاء أربع صور منفصلة ومحاولة ربطها، طلبنا من GPT Image 2 التعامل مع الأربعة في صورة واحدة:
- الشخصية أ (A-27): نسخة معدلة من Ranx — مشغلة تكتيكية بشعر ذهبي رملي مربوط ومعطف قتالي قصير
- الشخصية ب: تصميم مرتزق ذكر أصلي — معطف طويل أسود وأحمر، شعر مربوط للخلف، سيف عريض على الخصر
- البيئة: حصن صناعي في أرض قاحلة يسمى Ash City — ضوء عنبري وقت الغسق، توهج الفرن في المسافة، دخان في كل مكان
- عشر نبضات حركة مرسومة يدوياً: جسّ نبض ← اندفاع ← صد ← مراوغة ← خطاف ← هجوم مضاد ← تثبيت ← ركبة ← اقتراب ← سقوط

من المهم الإشارة إلى أن: الشخصية أ فقط هي التي استخدمت صورة مرجعية (Ranx من قبل). الشخصية ب، والبيئة بأكملها، وجميع نبضات الحركة العشر — صممها GPT Image 2 بنفسه. وصفنا الأجواء؛ وهو قام بالبقية.
الأسلوب، والهويتان، والبيئة، وعشر نبضات — كلها مثبتة في توليد واحد. لا شيء يتغير بين الصور. لا يتغير زي أحد في منتصف الطريق.
ثم مباشرة إلى Seedance 2.0 في خاصية المرجع إلى الفيديو:
مواجهة على السطح ترتكز على شعارين للفصائل على أرضية المنصة، اشتباك في المنتصف، ورمية نهائية — خمس عشرة ثانية من تصميم رقصات لشخصين في تمريرة واحدة.
6. لماذا يعمل هذا المسار على مفتاح API واحد
السلسلة — الشخصية ← المشهد ← لوحة القصص ← الفيديو — كانت تعني في السابق التلاعب بمفاتيح API، وSDKs، ووثائق، وفواتير، وحدود استخدام عبر موردين متعددين. أنت تعرف ذلك جيداً.
على AtlasCloud، كل شيء يقع خلف نقطة نهاية واحدة:
| الخطوة | النموذج | المنصة |
|---|---|---|
| ورقة الشخصية | GPT Image 2 | AtlasCloud |
| مفهوم المشهد | Nano Banana 2 | AtlasCloud |
| لوحة القصص | GPT Image 2 | AtlasCloud |
| الفيديو | Seedance 2.0 | AtlasCloud |
مفتاح واحد. نقطة نهاية واحدة. حصة واحدة. فاتورة واحدة. تنخفض تكاليف التكامل والعمليات إلى ما يقرب من الصفر.
7. الخلاصة: توقف عن القتال من أجل توحيد الأسلوب عبر النماذج، وابدأ بالاستفادة من قوة كل نموذج
بذلنا جهداً حقيقياً لمحاولة تثبيت أسلوب واحد في كل خطوة من السلسلة. في وضع المرجع إلى الفيديو، تلك معركة خاسرة — فكلما زاد إصرارك في الـ prompt على ذلك، ساءت المخرجات.
بمجرد أن تخلينا عن هذا الهدف، انفتح أمامنا سير العمل. دع كل نموذج يقوم بما يجيده فعلاً.
- GPT Image 2 — تقسيم السيناريو، وتخطيط اللقطات.
- Seedance 2.0 — فرد الزمن، ورسم الحركة.
- AtlasCloud — مفتاح واحد، سلسلة واحدة.
إذا كنت تصنع أفلاماً قصيرة للحركة، أو مشاهد قتال، أو تصميم رقصات مبارزة باستخدام الذكاء الاصطناعي، فهذا هو سير العمل الذي ننصح به.
جربها بنفسك
كلا النموذجين يعيشان في نفس مجموعة النماذج على AtlasCloud — مفتاح API واحد يشغل السلسلة بأكملها:
- Seedance 2.0 (المرجع إلى الفيديو) → atlascloud.ai/collections/seedance2
- GPT Image 2 (ورقة الشخصية + لوحة القصص) → atlascloud.ai/collections/gpt-image-2
- Nano Banana 2 (مفهوم المشهد) → atlascloud.ai/collections/nanobanana-2
تم نشر الخطوات التفصيلية وكل prompt تم استخدامه في هذه المقالة جنباً إلى جنب مع جولة الفيديو التوضيحية على YouTube.
انطلق واصنع شيئاً مميزاً.






