Gemini Omni is a major shift from traditional AI systems. It works as an all-in-one AI model that processes information naturally from the start. Instead of gluing different tools together for different types of media, it runs entirely on a single, universal neural engine. By processing text, image, audio, and video inside a singular cross-modal vector space, it completely eliminates legacy data silos and communication bottlenecks.
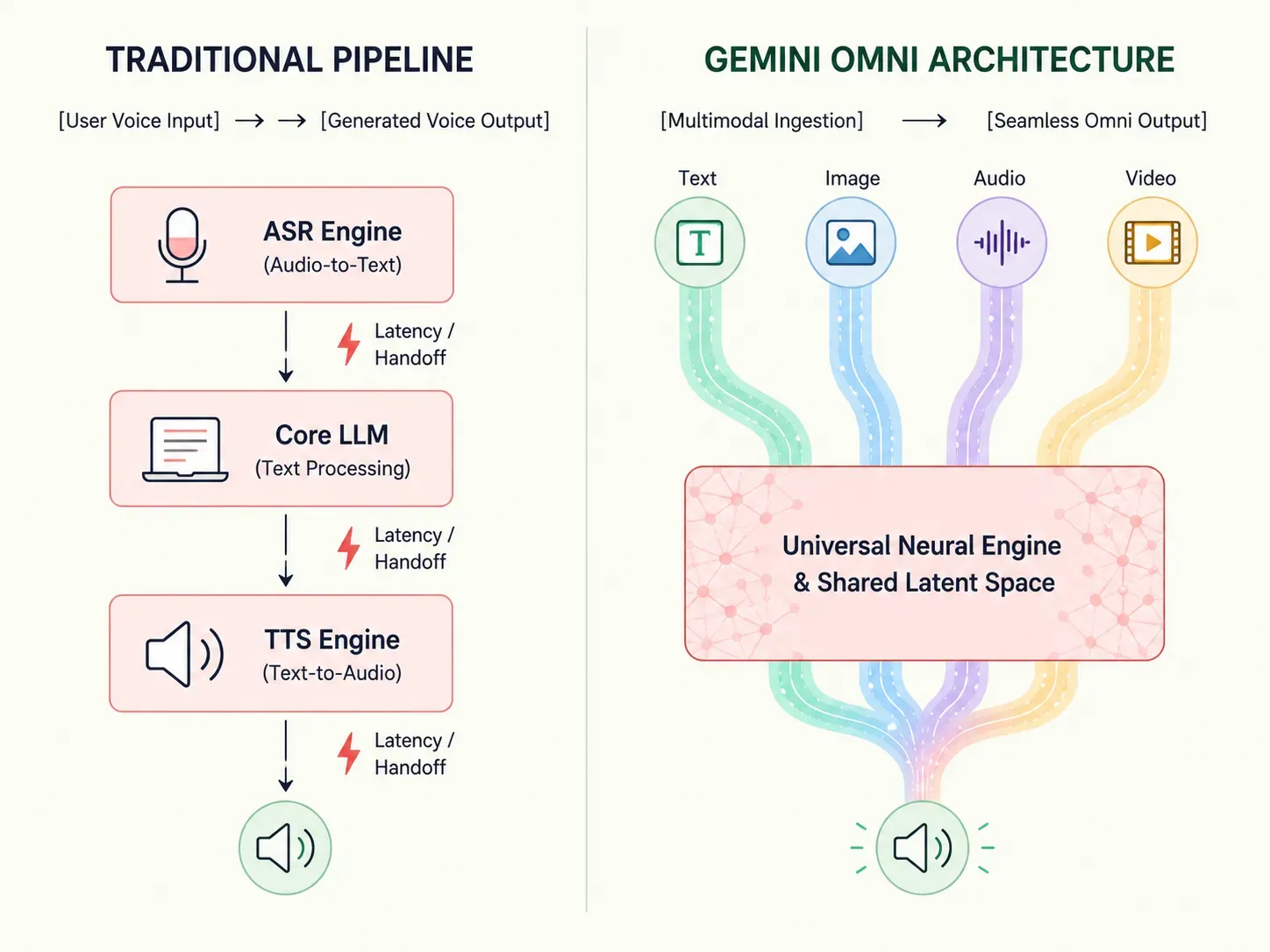
Traditional artificial intelligence relies on staggered pipelines—converting voice to text before a language model can even begin processing an answer. Gemini Omni fundamentally redefines this workflow.
- Native Ingestion: The system processes text tokens, image pixels, audio frequencies, and video frames all at the exact same time.
- Context Preservation: End-to-end data processing keeps subtle emotions, visual cues, and small details from getting lost between different layers.
This structural shift boosts processing efficiency and cuts delays down to near-human response times. Developers and businesses can now skip complex multi-model setups and rely on one solid system built for true multi-sensory computing.
How One Model Computes Four Modalities Simultaneously
To understand how Gemini Omni features processes text, images, audio, and video at the exact same time, we have to look directly at its core data layer. Traditional systems route different file types through separate, isolated sub-models. Gemini Omni completely bypasses this fragmented method. It implements a unified tokenization framework that natively translates all inputs into a singular language the AI core understands.
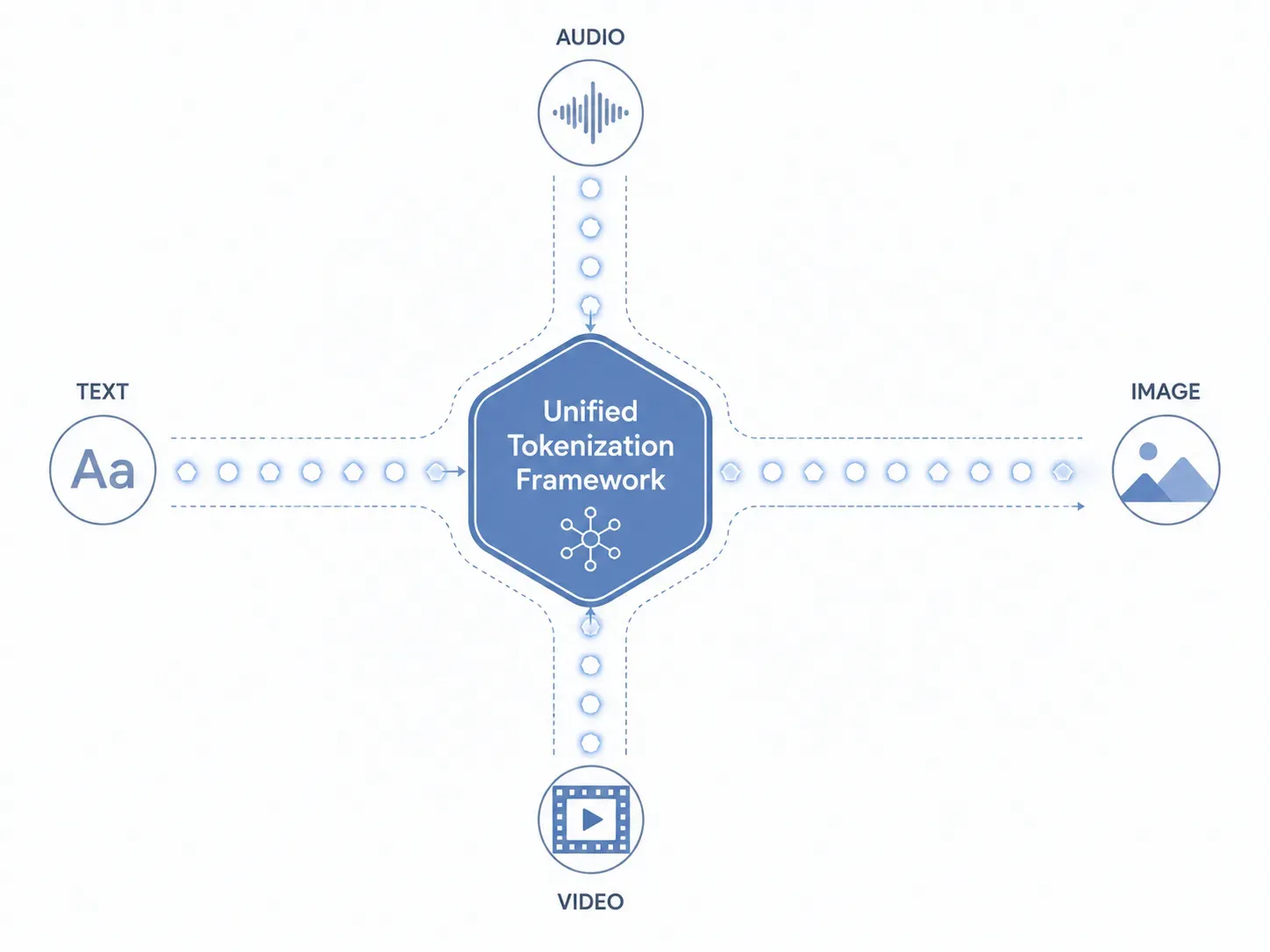
The Mechanics of Unified Tokenization
How does Gemini Omni handle different file types without separate sub-models? The answer lies in how the data is ingested and broken down before inference begins:
- Text: Alphanumeric characters are converted into standard semantic text tokens.
- Images: Visual elements are sliced into small patches of pixels and mapped as visual tokens.
- Audio: Continuous sound waves are sampled, capturing frequency and tone, and transformed into acoustic tokens.
- Video: Moving images are treated as a continuous sequence of temporal frames, establishing spatial-temporal tokens.
Shared Weights and Native Tensor Processing
Once this diverse multimodal data ingestion is complete, all data types enter a shared weight architecture. Instead of using individual specialized encoders that pass data back and forth over latency-inducing bridges, a single core neural network processes all tokens uniformly.
Using native tensor processing, the model executes mathematical computations on text, audio, and visual tokens within the same matrix layers. Because everything shares the same computational space, the network directly understands the relationship between a spoken word, a written sentence, an image pixel, and a video frame without a single translation step.
To see these engineering principles and native tokenization deployed at scale in real-world scenarios, watch the MIT Media Lab Research Vision Presentation. This presentation outlines the long-term industry shift toward connecting AI models directly with a rich spectrum of physical and multi-sensory world signals:
The Core Modality Pillars: Cross-Media Processing Map
To truly grasp the power of Gemini Omni, you have to look beyond simple data ingestion. The model utilizes a unified architecture where text, images, audio, and video exist within a shared latent space mapping. When an input changes in one modality, it doesn't just trigger an isolated reaction—it dynamically shifts the mathematical parameters of the other three formats at the exact same time.
The Multimodal Inter-Dependency Matrix
This real-time cross-media inference relies on inter-dependent data streams. Instead of processing data in sequential blocks, the model continuously synchronizes all four pillars to achieve a flawless multimodal alignment.
The processing map below outlines exactly how these live inputs influence each other within the universal neural network:
| Primary Media Input | Co-Processed Modalities | System Operation | Deep Technical Intent |
| Acoustic Waveforms | Text + Video Frames | Tracks voice cadence to index temporal video sequences | Real-time sensory alignment |
| Static Images | Raw Audio + Text | Translates visual color spectrums into matching contextual acoustics | Cross-modal synthesis |
| Alphanumeric Code | Video Arrays + Text | Modifies structural video variables directly via programming logic | Generative code execution |
| Temporal Video Sequences | Audio Tracks + Code | Computes spatial-temporal updates across multi-layered data tracks | Unified video-audio parsing |
Real-Time Parameter Synchronization in Action
When Gemini Omni processes a live video feed, it does not separate the visuals from the background track. If the audio input registers a sudden spike in frequency—such as a person shouting—the model instantly updates its visual token expectations. It anticipates rapid physical movement or a shift in the video frames before they even occur.
This deep cross-influence prevents context drift. Because the entire network balances these variables simultaneously, the output remains perfectly coherent, whether the model is generating a synchronized video summary or translating a live multi-sensory stream on the fly.
Eliminating Latency and Context Drift: The Advantage of Unified Weights
To appreciate the speed of Gemini Omni, it helps to look at the mathematical inefficiencies of traditional "stitched" AI pipelines. Historically, building a voice- or video-capable assistant required daisy-chaining separate, single-purpose software layers.
plaintext1[User Voice Input] 2 │ 3 ▼ 4 1. ASR Engine (Audio-to-Text Transcription) 5 │ 6 ▼ 7 2. Core LLM Layer (Text Generation Processing) 8 │ 9 ▼ 10 3. TTS Engine (Text-to-Audio Synthesis) 11 │ 12 ▼ 13[Generated Voice Output]
This multi-step orchestration forces data to travel across continuous software bridges, compounding execution delays. The separate text-to-speech engine cannot hear the original audio recording. This causes a huge loss of data across different media types. Important vocal cues, like a user's sarcastic tone, hesitations, or emotional distress, disappear completely when everything is flattened into plain text.
Realizing True Pipeline Latency Reduction
Gemini Omni bypasses these boundaries by operating on unified neural weights. Because a single neural network natively evaluates text, audio, and pixels under one mathematical roof, it scales execution speeds dramatically. This layout yields a profound pipeline latency reduction.
According to benchmarking reports from Google DeepMind, native multi-modal architectures running live audio streams drop end-to-end response times to under 150 milliseconds. This shift effectively matches the natural tempo of real-time human conversation.
Context Retention Optimization
Beyond sheer speed, unified execution ensures a high level of context retention optimization. When you speak to the model, the weights process your audio frequencies alongside your textual definitions simultaneously.
- Intonation Processing: The network captures vocal modulations directly, responding with appropriate empathy or urgency.
- Visual Synchronization: Subtle facial micro-expressions or spatial motions within a video frame translate directly into the conversational output without parsing errors.
By removing middle translation steps, Gemini Omni keeps small details from fading away. This builds a strong foundation for smooth, natural interactions across different senses between humans and machines.
Building Enterprise Workflows with Omni-Channel AI Systems
This shift toward native multimodality changes how companies build and scale digital tools. By using a single, all-in-one AI setup, businesses can replace messy, separate software pieces with unified workflows. This lets them run interactive, mixed-media systems easily on a large scale.
The Single API Architecture
Developers no longer need to coordinate disparate cloud functions for speech recognition, text analysis, and image processing. Instead, a single, unified API integration connects the application layer directly to the core network, like Atlas Cloud AI model API. This streamlined path allows teams to construct advanced cross-media pipelines with a single request framework.
plaintext1 ┌─────────────────────────────────┐ 2 │ Unified Gemini API │ 3 └────────────────┬────────────────┘ 4 │ 5 ┌─────────────────────────┼─────────────────────────┐ 6 ▼ ▼ ▼ 7┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ 8│ Real-Time Code │ │ Mixed-Media Data │ │ Multi-Sensory Ed │ 9│ & Asset Sync │ │ Automation Layer │ │ Dashboards │ 10└──────────────────┘ └──────────────────┘ └──────────────────┘
For instance, an enterprise training platform can process a live video stream, track a speaker’s audio cadence, translate the dialogue, and dynamically update a visual data dashboard simultaneously—all driven by one backend system.
Strategic Deployment Advantages
What are the deployment advantages of switching to an all-in-one model architecture?
Switching from old multi-model setups to a single neural network gives immediate, solid benefits for company IT systems:
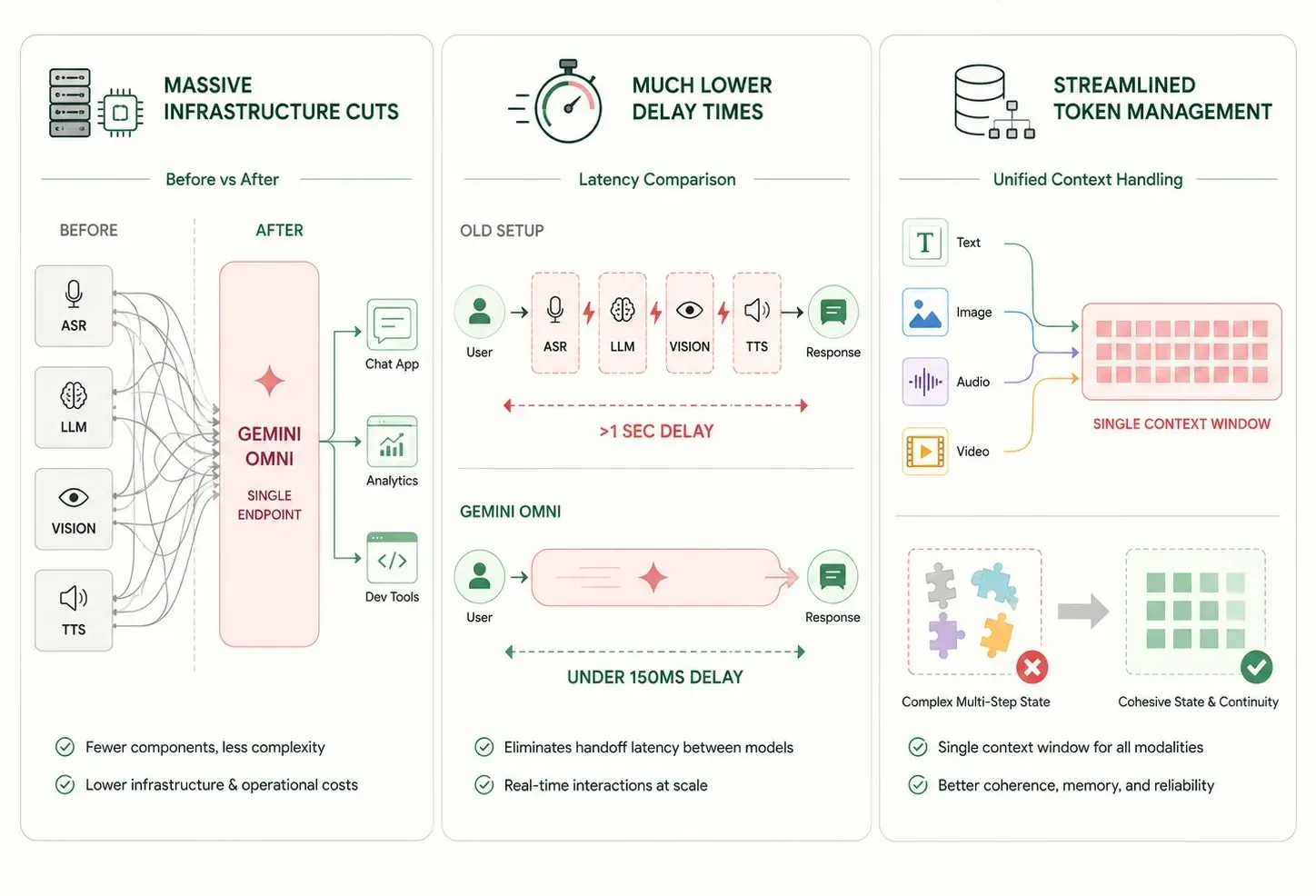
- Massive Infrastructure Cuts: Putting text, vision, and sound tasks into one model reduces the number of separate software endpoints. This makes long-term maintenance much easier.
- Much Lower Delay Times: Skipping extra network steps between small, specialized tools drops response times to under a second. This allows for truly real-time user experiences.
- Streamlined Token Management: A single context window tracking all modalities uniformally reduces complex state-management issues across multi-step processes.
Achieving Scalable Multimodal Deployment
Operating through frameworks like the Gemini Enterprise Agent Platform, businesses can seamlessly coordinate networks of autonomous sub-agents. This single system makes it easy to run large-scale multimedia projects. It uses managed setups that keep track of background context and user identity across workflows that last for days. By keeping different inputs in one secure space, companies can automate tasks across different media from start to finish without losing data or losing track of the main topic.
Computational Constraints and Hardware Optimization for Global AI Inference
While processing four separate data streams under a unified network architecture unlocks seamless cross-media workflows, it also introduces unprecedented demands on modern hardware infrastructure. Navigating this environment requires meticulous compute resource management to overcome the extreme physical penalties associated with simultaneous, multi-sensory processing at a global scale.
The Overhead of Multimodal Tokenization
The foremost engineering challenge stems from multimodal token overhead. Unlike standard alphanumeric text datasets, high-definition images, raw audio frequencies, and sequential video files generate massive amounts of numerical data.
- Text Processing: A single page of writing turns into roughly 1,000 dense meaningful tokens.
- Visual Processing: One minute of raw video footage, when cut into steady frame steps and pixel blocks, breaks apart into hundreds of thousands of visual tokens.
When a single model core processes these media types together, it causes an exponential surge in context window density. The system’s Attention mechanism must evaluate how every single token relates to every other token, threatening to overwhelm on-chip High Bandwidth Memory (HBM) and saturate processing layers.
Accelerating Workloads via TPU Cluster Scaling
To counter this bottleneck, enterprise infrastructures rely on specialized hardware platforms designed specifically for multi-sensory computing. Google’s latest architecture utilizes TPU cluster scaling to distribute these intensive unified token workloads across multi-layered data center environments.
plaintext1 ┌─────────────────────────┐ 2 │ Unified Gemini Tokens │ 3 └────────────┬────────────┘ 4 │ 5 ┌───────────────────────┴───────────────────────┐ 6 ▼ ▼ 7┌─────────────────────────────────┐ ┌─────────────────────────────────┐ 8│ TensorCore Array │ │ TensorCore Array │ 9│ (Parallel Matrix Arithmetic) │ │ (Parallel Matrix Arithmetic) │ 10└────────────────┬────────────────┘ └────────────────┬────────────────┘ 11 │ │ 12 └───────────────┬───────────────────────┘ 13 ▼ 14 ┌─────────────────────────┐ 15 │ Optical Interconnect │ 16 │ (Ultra-Low Latency ICI) │ 17 └─────────────────────────┘
Hardware setups like the Trillium TPU v6e platform deliver an impressive 4.7x increase in peak compute performance per chip compared to older hardware generations. This specialized architecture handles these massive demands by combining optimized matrix execution units with deep physical infrastructure layouts:
| Hardware Engine Layer | Architectural Specifications | Core System Function |
| Expanded TensorCore Arrays | Double the Matrix Multiply Unit (MXU) area | Executes intensive parallel arithmetic on dense video tensors. |
| High-Bandwidth HBM | Up to 32 GB HBM per chip | Houses massive token arrays entirely on silicon to prevent memory bottlenecks. |
| Next-Gen Inter-Chip Interconnect | 800 GBps bidirectional bandwidth | Syncs parameter variables across tens of thousands of chips without lag. |
By utilizing custom optical networking fabric alongside these deep memory configurations, cloud infrastructures can scale dynamically to handle multi-million token input parameters. This allows enterprises to deploy advanced, real-time AI agents globally without risking memory stalls or system runtime failures.
One Unified API for Production Video Generation
While Google rolls out Gemini Omni Flash inside the Gemini app and Google Flow for end-users, developers and product teams who want to embed the same multimodal video engine into their own workflows need a stable, predictable API layer.
Atlas Cloud serves Gemini Omni Flash through a unified, OpenAI-compatible API, alongside 300+ other image, video, and LLM models — so you can integrate Google's native multimodal model without juggling separate vendor accounts, billing portals, or SDKs.
Both Gemini Omni Flash variants are live on Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variant | Best For | Inputs | Resolution | Duration | Starting Price |
| Gemini Omni Flash Text-to-Video (Developer) | Pure prompt-driven cinematic generation | Text (up to 20,000 chars) | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/sec |
| Gemini Omni Flash Image-to-Video (Developer) | Subject-consistent video from real references | Text + up to 7 reference images | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/sec |
Quick Start — Generate a Gemini Omni Flash video in 5 lines:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
The API returns a prediction ID immediately — poll /api/v1/model/prediction/{id} for the rendered MP4 URL. Full schema, code samples in 7 languages, and a no-code Playground are available on the model pages linked above.
Conclusion: Future-Proofing for Unified Machine Intelligence
The arrival of Gemini Omni fundamentally alters developer design paradigms, shifting the industry from stringing together separate tools to deploying unified, single-layer solutions. Instead of managing complex integration bridges between isolated APIs, engineers can now rely on next-generation machine learning frameworks that naturally process inter-dependent data streams under one mathematical roof.
plaintext1[Legacy Software Pipeline] 2Separate Text API ──┐ 3Separate Audio API ─┼──► Manual Pipeline Bricks ──► Fragile Production 4Separate Video API ──┘ 5 6[Unified Omni Architecture] 7Universal Tokens ──► Native Single-Layer Model ──► Seamless Automation
This structural shift requires a complete overhaul of how we build digital products. To stay competitive, technical teams must transition away from static data silos and prepare standard software ecosystems for native multi-sensory systems.
Operating directly on a highly optimized cloud backbone like the Google Cloud AI infrastructure, enterprises can scale these intensive token workloads without risking systemic context drift or latency penalties. Ultimately, future-proofing your development pipeline means designing solutions around a singular, cohesive engine built to understand the physical world holistically.






