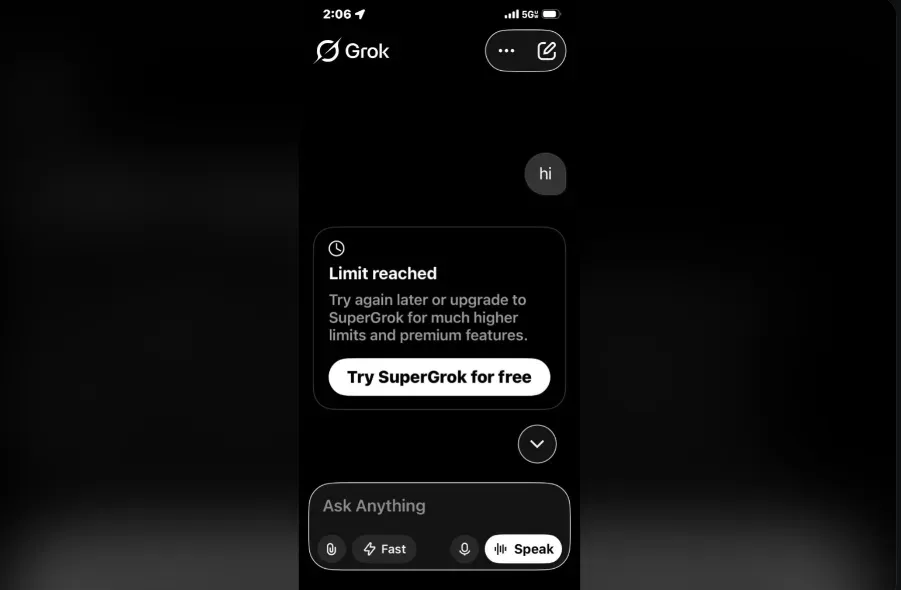
Die Zeit bis zum Reset des Grok-Bildgenerierungslimits folgt einem rollierenden 2-Stunden-Fenster und nicht einem festen täglichen Reset um Mitternacht. Sobald Sie Ihr Limit erreichen, laufen Ihre ältesten Anfragen innerhalb dieses Zeitraums zuerst ab. Das bedeutet, dass Ihre Kapazität nach und nach zurückkehrt, anstatt auf einmal.
Hier ist ein kurzer Überblick darüber, wie es nach Tarif funktioniert:
| Plan / Stufe | Geschätztes Bildkontingent (pro Fenster) | Beobachteter Reset-Mechanismus |
|---|---|---|
| X Premium+ / SuperGrok | 70 – 150+ Bilder (stark abhängig vom Geschwindigkeits- vs. Qualitätsmodus) | Dynamisches rollierendes Fenster (typischerweise 4 bis 12 Stunden; bis zu 24 Stunden bei hoher Serverlast) |
| X Premium (Standard) | 20 – 50+ Bilder (variiert je nach Region und Serverkapazität) | Dynamisches rollierendes Fenster (meist näher an einem 12- oder 24-Stunden-Zyklus) |
| X Premium (Basic) | Sehr begrenzter Zugang (nur Chat-Generierung) | Rollierendes Fenster / tägliches Limit |
⚠️Da xAI keine offiziellen Echtzeit-Daten zu Ratenlimits veröffentlicht und häufig serverseitige A/B-Tests durchführt, basieren diese Zahlen auf den neuesten aggregierten Nutzerdaten aus der Grok-Reddit-Community. Ihre individuelle Erfahrung kann je nach Serverauslastung und regionalen Einschränkungen variieren.
Dieses rollierende System ist die Hauptursache für die Verwirrung rund um das Grok-Ratenlimit. Im Gegensatz zu einfachen Tageskontingenten verschieben sich Ihre verfügbaren Generierungen kontinuierlich basierend auf Ihrer letzten Aktivität.
Dieser Leitfaden behandelt:
- Wie das rollierende Fenster Ihr verbleibendes Kontingent tatsächlich berechnet
- Stufenspezifische Aufschlüsselungen der SuperGrok-Nutzungslimits und des X Premium-Bildkontingents
- Praktische Strategien zur Verteilung der Nutzung und zur Vermeidung unerwarteter Sperren
Wenn Ihre Generierungen nicht wie erwartet aktualisiert werden, liegt das fast sicher an diesem rollierenden Mechanismus.
Was ist die Zeit bis zum Reset des Grok-Bildgenerierungslimits?
Die Zeit bis zum Reset des Grok-Bildgenerierungslimits ist nicht an eine feste Uhrzeit gebunden. Es gibt keinen Stichtag um Mitternacht oder einen täglichen Kalender-Reset. Stattdessen hat xAI die Grok Imagine-Ratenlimits um ein dynamisches, rollierendes Fenster herum aufgebaut, das sich an Ihrem eigenen Nutzungsverhalten orientiert.
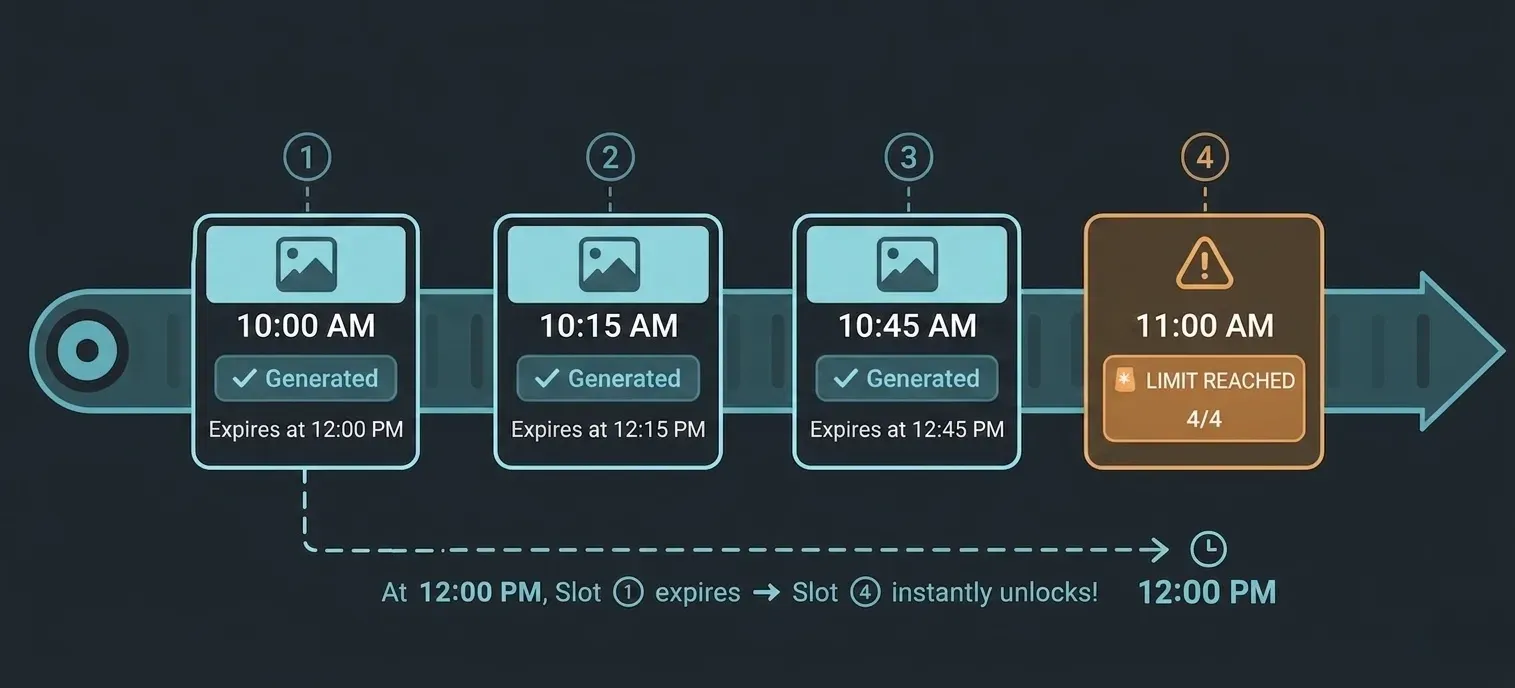
So funktioniert das rollierende Fenster
Der Timer startet in dem Moment, in dem Sie Ihre erste Bildgenerierungsanfrage in einer Sitzung senden. Ab diesem Zeitpunkt läuft Ihr Kontingentfenster für etwa zwei Stunden vorwärts. Wenn jede Anfrage das 2-Stunden-Limit überschreitet, wird der Platz, den sie belegt hat, wieder frei.
Stellen Sie es sich weniger wie einen Eimer vor, der sich einmal am Tag füllt, sondern eher wie ein Fließband: Alte Anfragen fallen am Ende herunter, während die Zeit vergeht, und schaffen kontinuierlich Platz für neue.
Schlüsselfaktoren, die Ihren Reset-Timer beeinflussen
Mehrere Variablen können dazu führen, dass sich Ihre Reset-Zeit inkonsistent anfühlt:
- xAI-Serverkapazität: In Zeiten hoher Auslastung können Einschränkungen der xAI-Serverkapazität die verfügbaren Plätze vorübergehend verknappen, wodurch sich die Limits auch innerhalb derselben Stufe restriktiver anfühlen.
- A/B-Tests: xAI testet aktiv verschiedene Kontingentkonfigurationen bei verschiedenen Nutzergruppen, was bedeutet, dass zwei Nutzer mit identischen Plänen gleichzeitig leicht unterschiedliche Grenzwerte erleben können.
- Warteschlangen für Anfragen: Fehlgeschlagene oder in der Warteschlange befindliche Generierungen können je nach serverseitiger Protokollierung dennoch auf Ihr Fenster angerechnet werden.
Was das praktisch bedeutet
| Situation | Erwartetes Verhalten |
|---|---|
| Limit um 15:00 Uhr erreicht | Erste Plätze werden gegen 17:00 Uhr frei |
| Server unter hoher Last | Reset kann sich um 10-20 Minuten verzögern |
| A/B-Test auf dem Account | Kontingentobergrenze kann von veröffentlichten Limits abweichen |
Da sich der rollierende Fenster-Reset mit Ihrem Verhalten verschiebt und nicht nach der Uhr, gibt Ihnen das Prüfen einer festen Zeit pro Tag keine verlässliche Auskunft darüber, wann Ihre Grok Imagine-Ratenlimits aufgehoben sind.
Wie viele Bilder können Sie generieren, bevor das Limit erreicht ist?
Bildgenerierungskontingente variieren erheblich je nach Abonnementstufe und der verwendeten Generierungsmethode. Beide Dimensionen zu verstehen hilft Ihnen, Ihren Workflow zu planen und unerwartete Sperren während einer Sitzung zu vermeiden.
![]()
Chat-Generierung vs. der dedizierte Imagine-Tab
Es gibt einen kritischen technischen Unterschied zwischen der Generierung von Bildern innerhalb eines Standard-Grok-Chat-Threads und der Nutzung des dedizierten Grok Imagine-Layouts:
- Chat-Generierung: Nutzt normalerweise das Basis-Modell Flux 1. Anfragen, die hier gestellt werden, laufen über eine separate, historisch gesehen engere Pipeline. Wenn Sie Ihre chatbasierten visuellen Anfragen aufbrauchen, schränkt dies Ihre Fähigkeit ein, Inline-Bilder zu generieren, sperrt Sie jedoch möglicherweise nicht vollständig von anderen Kreativ-Suiten aus.
- Der Imagine-Tab: Angetrieben von xAIs Flaggschiff-Modellfamilie Aurora. Dieser Arbeitsbereich schaltet leistungsstarke Kreativfunktionen wie Leinwanderweiterung und Image-to-Image-Stilüberblendung frei. Er schöpft aus Ihrem primären Kontingent-Pool für Premium+ oder SuperGrok und passt sich dynamisch daran an, ob Sie Geschwindigkeit oder reine Wiedergabetreue wählen.
Verbrauchen Grok-Bildbearbeitungen und Inpainting Ihr Kontingent?
Die Verwendung fortgeschrittener Funktionen im Grok Imagine-Tab – wie pinselbasiertes Inpainting, das Erweitern der Leinwand (Outpainting) oder Stil-Überblendungen – zählt nicht als eine einzelne Transaktion, wenn Sie mehrere Iterationen durchführen. Jedes Mal, wenn Sie einen Änderungs-Prompt auf ein bestehendes Bild anwenden, behandelt xAIs Aurora-Modell dies als eine neue Generierungsanfrage.
Wenn Sie beispielsweise ein Bild als Basis generieren, aber innerhalb von 5 Minuten 5 aufeinanderfolgende Pinselbearbeitungen vornehmen, um eine Hand oder ein Hintergrunddetail zu korrigieren, haben Sie tatsächlich 6 Plätze Ihres gesamten rollierenden Kontingents verbraucht. Um Ihr Kontingent bei intensiven Bearbeitungssitzungen zu schonen, legen Sie Ihre Komposition zuerst im Geschwindigkeitsmodus fest und führen Sie detailliertes Inpainting erst durch, nachdem Sie wieder in den Qualitätsmodus gewechselt haben.
Chat-Generierung vs. der Imagine-Tab
Es gibt einen wichtigen Unterschied zwischen der Generierung von Bildern innerhalb eines Standard-Grok-Chats und der Nutzung des dedizierten Grok Imagine-Tabs:
- Chat-Generierung verwendet das Modell Flux 1 und schöpft aus einem separaten, typischerweise kleineren Kontingent-Pool.
- Grok Imagine-Tab verwendet das Aurora-Modell von xAI und unterstützt SuperGrok-Bildbearbeitungsfunktionen wie Inpainting und Stilsteuerung.
Diese beiden Pools werden separat nachverfolgt, sodass das Aufbrauchen Ihrer chatbasierten Generierungen nicht unbedingt Ihre Grok Imagine-Token erschöpft.
Zählen fehlgeschlagene oder moderierte Generierungen?
Dies ist eine häufige Quelle für Frustration. Basierend auf Community-Berichten gilt:
- Moderierte Inhalte (Prompts, die vor der Verarbeitung blockiert werden) verbrauchen im Allgemeinen kein Kontingent.
- Fehlgeschlagene Generierungen, die mit der Verarbeitung beginnen, bevor ein Fehler auftritt, zählen normalerweise doch gegen Ihr Limit.
- Anfragen in der Warteschlange, bei denen ein Timeout auftritt, befinden sich in einer Grauzone und werden möglicherweise je nach serverseitigem Verhalten als Abzug für ein Ratenlimit bei fehlgeschlagenen Generierungen registriert.
Gehen Sie im Zweifelsfall davon aus, dass eine während der Verarbeitung fehlgeschlagene Generierung einen Platz verbraucht hat.
So überprüfen und verfolgen Sie Ihren Grok-Reset-Timer
Zu wissen, wo Sie Ihren Grok-Limit-Countdown-Timer finden, erspart viel Rätselraten. Die Benutzeroberfläche zeigt Informationen zum verbleibenden Kontingent an, aber die Sichtbarkeit hängt davon ab, welche Plattform Sie verwenden und ob Ihr Limit tatsächlich erreicht wurde.
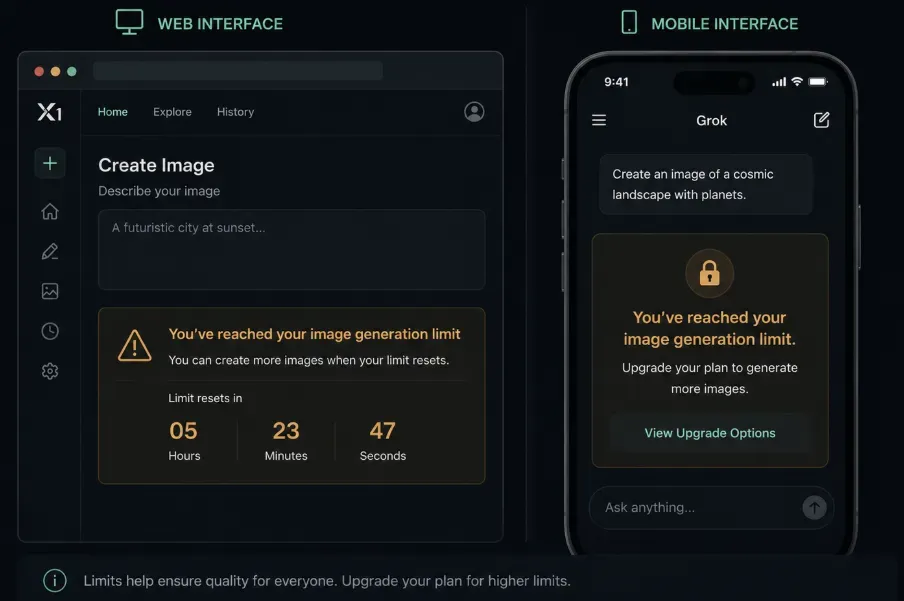
Timer im Web finden
Wenn Sie auf der Browserversion von Grok Ihr Limit für die Bildgenerierung erreichen, erscheint normalerweise eine Benachrichtigung direkt in der Chat- oder Imagine-Tab-Oberfläche. Diese Nachricht enthält einen ungefähren Grok-Limit-Countdown-Timer, der anzeigt, wie lange es dauert, bis Ihr nächster Platz frei wird.
Um den Grok-Ratenlimit-Status im Web zu überprüfen:
- Navigieren Sie zu grok.com und öffnen Sie den Imagine-Tab.
- Versuchen Sie eine Generierung, nachdem Sie Ihr Limit erreicht haben.
- Achten Sie auf die Reset-Zeit, die direkt bei der Fehlermeldung angezeigt wird.
- Notieren Sie den Zeitstempel und rechnen Sie basierend auf Ihrer ersten Generierungszeit vorwärts.
Timer auf Mobilgeräten finden
Die X-App für Mobilgeräte handhabt die Kontingentanzeige anders. Der Countdown wird weniger konsistent angezeigt und zeigt möglicherweise nur eine generische "Limit erreicht"-Meldung ohne spezifischen Timer an. In diesem Fall ist die manuelle Nachverfolgung Ihrer ersten Generierungszeit die zuverlässigste Lösung.
Warum der Timer fehlerhaft ist oder verschwindet
Mehrere Faktoren beeinflussen die Zuverlässigkeit der Anzeige des Grok AI-Nutzungskontingents 2026:
| Ursache | Auswirkung auf die Timer-Anzeige |
|---|---|
| Wechsel zwischen App und Browser | Diskrepanz im Sitzungsstatus kann den Countdown verbergen |
| Serverseitige A/B-Tests | Timer-Benutzeroberfläche wird möglicherweise nicht für alle Nutzersegmente gerendert |
| Zwischengespeicherte Sitzungsdaten | Alter Kontingentstatus wird möglicherweise anstelle von Live-Daten angezeigt |
| Konto-Synchronisierung während der Sitzung | Timer wird zurückgesetzt oder verschwindet vorübergehend |
Wenn Ihr Timer nach dem Wechsel der Plattform verschwindet, stellt ein Hard-Refresh oder ein vollständiges Ab- und Anmelden normalerweise die korrekte Sichtbarkeit des Kontingents wieder her. Verlassen Sie sich nicht nur auf den angezeigten Timer; die Nachverfolgung Ihres eigenen Zeitstempels der ersten Generierung bleibt die verlässlichste Methode, um den Grok-Ratenlimit-Status zu überprüfen.
Intelligente Strategien zur Verwaltung Ihres Grok-Bildgenerierungskontingents
Wenn Ihnen mitten im Projekt die Generierungen ausgehen, ist das frustrierend, aber mehrere praktische Strategien können Ihnen helfen, Ihr Kontingent besser auszunutzen, ohne auf den Reset des rollierenden Fensters warten zu müssen. Keine dieser Methoden kann technisch gesehen Grok-Ratenlimits umgehen, aber sie helfen Ihnen, innerhalb des Systems intelligenter zu arbeiten.
Wechseln Sie vom Qualitätsmodus in den Geschwindigkeitsmodus
Das Aurora-Modell bietet zwei Generierungsmodi, und Ihre Wahl wirkt sich direkt darauf aus, wie stark jede Anfrage Ihr Gleichgewicht zwischen Grok-Bildqualität vs. Geschwindigkeits-Token belastet:
| Modus | Token-Kosten | Am besten für |
|---|---|---|
| Qualität (Aurora) | Höher pro Anfrage | Finale Renderings, detaillierte Ausgaben |
| Geschwindigkeit | Niedriger pro Anfrage | Entwürfe, Konzeptentwicklung, Iteration |
Der grundlegende Grund, warum der Geschwindigkeitsmodus Ihr Kontingent schont, liegt in der Reduzierung der Inferenzschritte. Unter der Haube führt der Qualitätsmodus (Aurora High-Fidelity) mehr Denoising-Schritte durch, um Artefakte zu beseitigen, strenge Texttypografie abzubilden und Mikrodetails zu maximieren. Dies verbraucht deutlich mehr GPU-Rechenleistung des Servers, was den xAI-Ratenbegrenzer dazu veranlasst, Ihr rollierendes Fenster stark zu bestrafen – manchmal sinkt Ihr maximaler Schwellenwert von 150 Bildern auf nur 40.
Zusätzlich führt die Erstellung ungewöhnlicher Formate, wie ultra-breite 16:9-Seitenverhältnisse oder komplexe vertikale Formate, zusammen mit langen Beschreibungen dazu, dass das Modell stärker arbeiten muss. Dieser zusätzliche Arbeitsaufwand erhöht die Wahrscheinlichkeit eines Timeouts erheblich. Infolgedessen kann die Anfrage als fehlgeschlagene Generierung registriert werden, während sie dennoch Ihr Kontingent verbraucht.
Für Workflows mit hohem Volumen kann das Entwerfen im Geschwindigkeitsmodus und das Reservieren des Qualitätsmodus für die endgültigen Ausgaben die Reichweite Ihres Kontingents innerhalb eines 2-Stunden-Fensters sinnvoll erweitern.
Pro-Tipp: Erstellen Sie Ihre Prompts immer in einem standardmäßigen 1:1-Quadrat-Seitenverhältnis im Geschwindigkeitsmodus. Sobald Sie die ideale stilistische Ästhetik erreicht haben, aktivieren Sie den Qualitätsmodus und passen Sie die Leinwandgröße für Ihren endgültigen Produktionslauf an.
Wechseln Sie zwischen Web- und Mobil-Schnittstellen
Einige Nutzer berichten, dass der Wechsel zwischen der Browserversion und der X-App für Mobilgeräte gelegentlich zusätzliche verfügbare Plätze anzeigen kann, wenn eine Schnittstelle einen "Limit erreicht"-Status anzeigt. Dies ist keine garantierte Lösung und spiegelt wahrscheinlich Unterschiede im Sitzungsstatus wider und nicht separate Kontingent-Pools. Es ist einen Versuch wert, aber bauen Sie darauf keine Workflow-Abhängigkeit auf.
Upgrade auf xAI API-Zugang für Power-User
Wenn konstante Verfügbarkeit und Volumen wichtiger sind als Abonnement-Limits, bietet der Übergang von Web-Frontends zu einem API-Ökosystem einen nahtlosen Weg.
Für automatisierte Content-Pipelines nutzen Power-User häufig Plattformen wie Atlas Cloud, um auf die offizielle Grok-Imagine-Models-API zuzugreifen. Anstatt sich mit den starren rollierenden Fenstern von X auseinanderzusetzen, bietet Atlas Cloud stabile, serverlose REST-Endpunkte für die Grok Imagine Image API, die bis zu 2K Text-zu-Bild- und Bild-zu-Bild-Generierungen unterstützen. Durch die programmgesteuerte Weiterleitung Ihrer Anfragen skaliert die Kapazität dynamisch basierend auf einem vorhersehbaren Abrechnungsmodell pro Bild, wodurch Sitzungssperren vollständig eliminiert werden.
Entdecken Sie Alternativen zur unbegrenzten Bildgenerierung
Für Kreative, die es sich absolut nicht leisten können, während der Grok-Reset-Fenster Ausfallzeiten zu haben, bieten mehrere alternative Plattformen andere Abonnement- oder Infrastrukturmodelle an, um Ihren Workflow in Bewegung zu halten:
- Midjourney: Eine abonnementbasierte Plattform für Renderings mit hohem Volumen, die über Discord- und Web-Schnittstellen betrieben wird.
- Adobe Firefly: Eine unternehmenssichere Option mit monatlichen generativen Credits, die vollständig in die Creative Cloud integriert ist.
- Stable Diffusion: Ein selbstgehostetes Open-Source-Setup, das effektiv unbegrenzt ist, wenn Sie über die lokale GPU-Hardware verfügen.
- Ideogram: Eine exzellente Alternative, bekannt für präzises Rendering von Typografie mit flexiblen kostenlosen und Premium-Stufen.
- Atlas Cloud: Eine API-first-Plattform, die auf Entwickler zugeschnitten ist, die es vorziehen, Front-End-Schnittstellen vollständig zu umgehen, um Bildmodelle (wie Flux oder Ideogram v2) auf einer serverlosen, Pay-per-Picture-Infrastruktur abzufragen.
Diese Plattformen arbeiten auf unterschiedlichen operativen Rahmenbedingungen und können sicherstellen, dass Ihre kreative Produktion niemals zum Stillstand kommt.
Fazit
Die Zeit bis zum Reset des Grok-Bildgenerierungslimits arbeitet mit einem rollierenden 2-Stunden-Fenster, das an Ihre eigene Nutzungshistorie gebunden ist, nicht an eine feste tägliche Uhrzeit. Diese eine Unterscheidung ändert die Art und Weise, wie Sie an jede Sitzung herangehen sollten.
Der effektivste Weg, das Grok AI-Kontingent zu verwalten, ist einfach: Lassen Sie es ruhig angehen. Das "Abfeuern" von 20 Generierungen innerhalb von 15 Minuten sperrt Ihre ältesten Plätze viel schneller, als wenn Sie dasselbe Volumen über ein oder zwei Stunden verteilen. Langsame, bewusste Nutzung hält das Fließband zu Ihren Gunsten am Laufen.
Hier ist eine kurze Checkliste für Ihre nächste Sitzung:
- Notieren Sie den Zeitstempel Ihrer ersten Generierung
- Verwenden Sie den Geschwindigkeitsmodus für Entwürfe, den Qualitätsmodus für finale Ausgaben
- Verfolgen Sie Ihren eigenen Timer, anstatt sich nur auf die Anzeige in der App zu verlassen
- Betrachten Sie die 2-Stunden-Marke als weichen Planungshorizont, nicht als harte Sperrzeit
Letztendlich hängt der Wert des SuperGrok-Abonnements stark davon ab, wie gut Sie diese Mechanismen verstehen. Nutzer, die das Kontingent als starre Tagesobergrenze behandeln, fühlen sich konsequent benachteiligt, während diejenigen, die mit dem rollierenden Fenster arbeiten, selten auf Reibung stoßen. Das System belohnt Geduld und Tempo gegenüber der massenhaften Generierung.






