Zusammenfassung: GLM-5-Turbo, entwickelt von Zhipu AI (Z.ai), ist ein großes Sprachmodell, das speziell für OpenClaw-Anwendungsfälle konzipiert wurde. Es ist das erste Closed-Source-Release des Unternehmens (zuvor unter dem Codenamen Pony-Alpha-2 getestet) und wird in Kürze auf Atlas Cloud verfügbar sein.
Das Modell bietet signifikante Verbesserungen bei der Tool-Nutzung, der Ausführung von Anweisungen, mehrstufigen Workflows sowie der Bewältigung langfristiger Aufgaben und unterstützt ein Kontextfenster von bis zu 200.000 Token. Seine Datenanalysefähigkeiten sind mit Claude Opus 4.6 vergleichbar, und es übertrifft GLM-5 bei Automatisierungs- und Informationsverarbeitungsaufgaben. Durch die Nutzung der einheitlichen API und des Multi-Modell-Ökosystems von Atlas Cloud ermöglicht GLM-5-Turbo eine effiziente Bereitstellung in komplexen Geschäftsprozessen, bei der Analyse langer Dokumente und in der Softwareentwicklung – eine kosteneffiziente und einfach zu integrierende KI-Lösung für Entwickler und Unternehmen.
Wir freuen uns, ankündigen zu können, dass GLM-5-Turbo bald auf Atlas Cloud verfügbar ist!
- Was ist GLM-5-Turbo: GLM-5-Turbo wurde von Zhipu AI (Z.ai) entwickelt und ist ein auf OpenClaw-Anwendungsfälle zugeschnittenes großes Sprachmodell. Es ist das erste Closed-Source-Release des Teams und bietet eine höhere Laufzeiteffizienz als GLM-5 bei geringeren Kosten pro Aufruf. Zuvor hatte Zhipu AI das Modell der nächsten Generation informell unter dem Codenamen Pony-Alpha-2 getestet.
- Kernfunktionen: GLM-5-Turbo bietet wesentliche Verbesserungen bei der Tool-Nutzung, beim Befolgen von Anweisungen, bei mehrstufigen Workflows und bei der dauerhaften Ausführung von Aufgaben. Es unterstützt dynamische Reasoning-Modi für verschiedene Szenarien, Echtzeit-Streaming-Ausgabe, verbesserte Tool-Integration und die Verarbeitung langer Kontexte mit bis zu 200.000 Token.
- Veröffentlichungsdatum: 24.03.2026.
GLM-5 erregte zuvor Aufmerksamkeit als das leistungsstärkste Open-Source-Modell im Artificial Analysis Intelligence Index und übertraf dabei Gemini 3 Pro. Als Nachfolger führt GLM-5-Turbo eine Reihe iterativer Upgrades ein, die im Folgenden detailliert beschrieben werden.
Kernpositionierung: Ein auf ClawBench optimiertes Modell
Starke Benchmark-Leistung
Optimiert für OpenClaw-Szenarien, verbessert GLM-5-Turbo die Fähigkeiten bei Tool-Aufrufen, der Befehlsausführung und der Orchestrierung komplexer Aufgaben erheblich. Die Datenanalyse-Performance liegt auf Augenhöhe mit Claude Opus 4.6 und übertrifft GLM-5 in den Bereichen Automatisierung, Informationsabruf, Büroproduktivität und Analyseaufgaben.
Bildquelle: Offizielle Website von Zhipu AI (Z.ai).
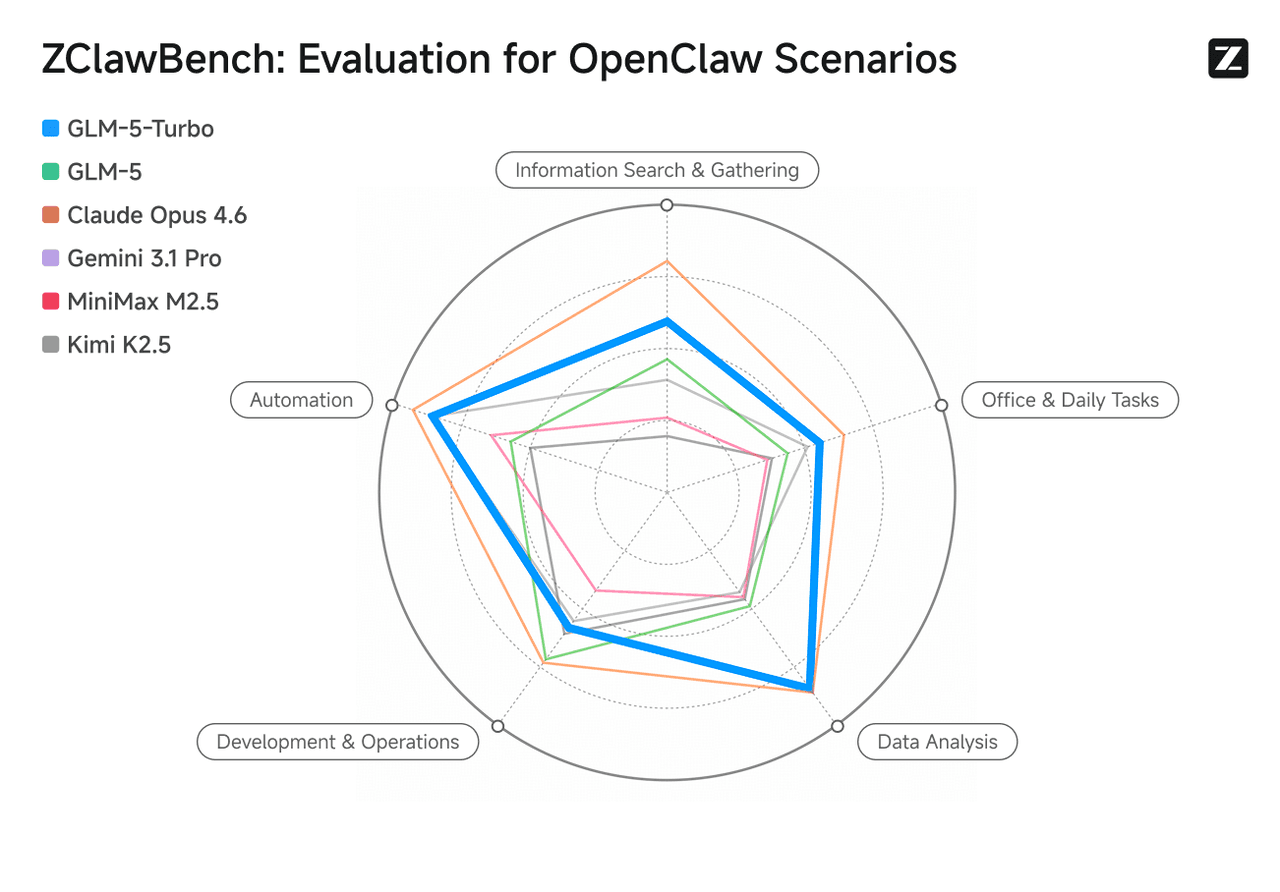
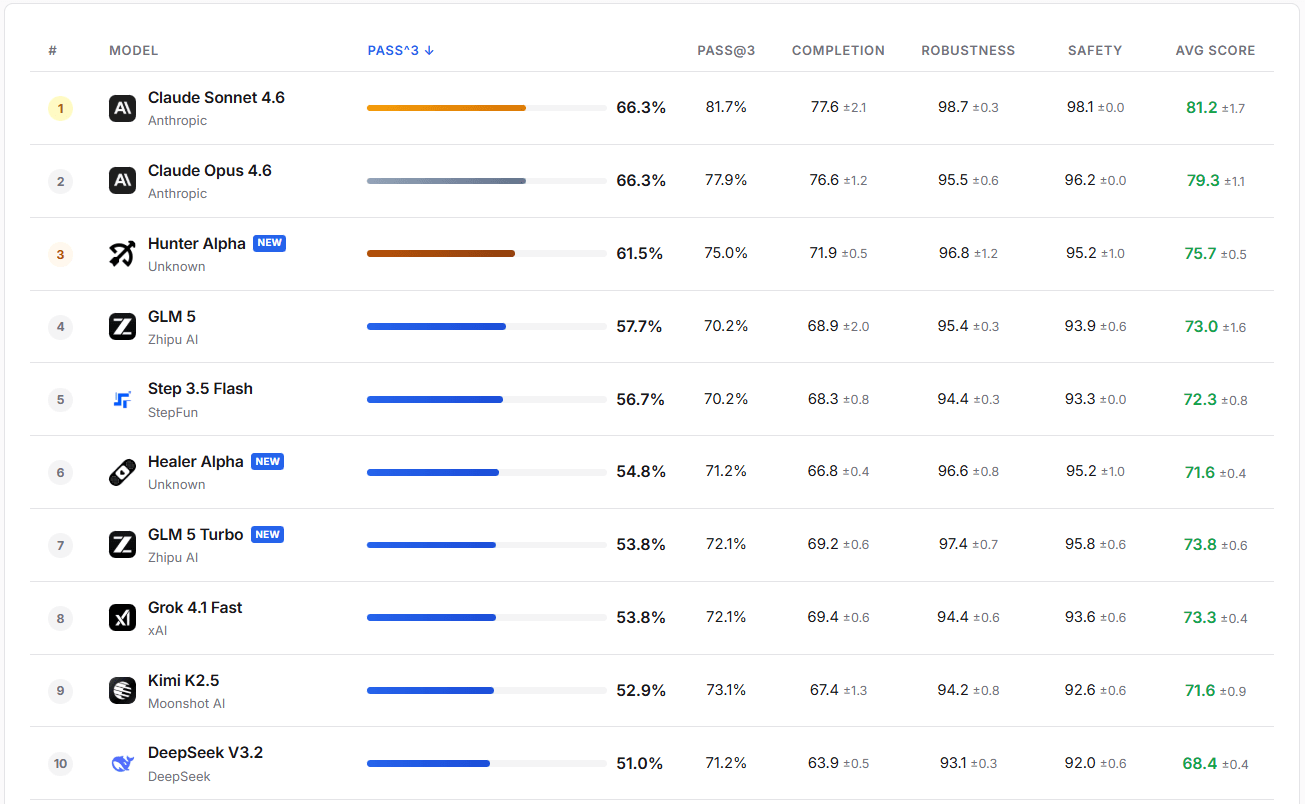
In praktischen Bewertungen zeigt GLM-5-Turbo eine hohe Robustheit und Sicherheit. Die PASS@3-Erfolgsrate übertrifft die von GLM-5, Step 3.5 Flash und Kimi K2.5.
Bildquelle: https://claw-eval.github.io/
Verbesserte Tool-Nutzung und externe Integration
Z.ai hat die agentischen Fähigkeiten von GLM-5-Turbo während des Trainings gestärkt, was eine nahtlose Interaktion mit externen Tools ermöglicht. Diese ausführungsorientierte Ausrichtung bringt jedoch Kompromisse mit sich: Einige Nutzer berichten, dass der Tonfall in Rollenspielszenarien im Vergleich zu GLM-5 etwas mechanischer wirkt.
Um den unterschiedlichen Stärken der Modelle gerecht zu werden, bietet Atlas Cloud eine einheitliche Schnittstelle, über die Nutzer mehrere Modelle gleichzeitig abfragen und so direkte Vergleiche anstellen können.
Zusätzlich können Nutzer eigene Skills definieren oder GLM-5-Turbo erlauben, diese autonom zu entdecken und zu installieren.
Bildquelle: Atlas Cloud

Autonome Ausführung bei langfristigen Aufgaben
GLM-5-Turbo ist für Aufgaben optimiert, die geplante Trigger oder längere Laufzeiten erfordern. Es bewältigt persistente, mehrstufige und zeitübergreifende Workflows mit hoher Aufgabenkontinuität.
Das Modell schlägt proaktiv Ausführungsstrategien basierend auf der Komplexität der Aufgabe vor. Bei Vergleichstests zur Code-Optimierung lieferte GLM-5-Turbo in etwa 10 % der Fälle Empfehlungen, die konkurrierende Modelle übertrafen.
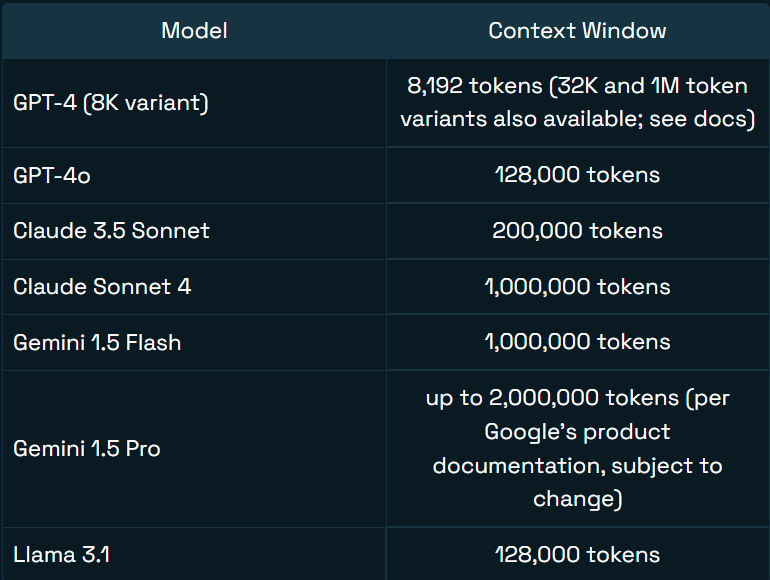
200.000 Token Kontextfenster
Mit der Unterstützung von bis zu 200.000 Token (ca. 133.000 englische Wörter) kann GLM-5-Turbo umfangreiche Kontextinformationen innerhalb einer einzigen Sitzung beibehalten und nutzen. Dies ermöglicht den präzisen Abruf früherer Informationen, selbst in späteren Stadien eines Gesprächs.
Bildquelle: Jim Allen Wallace (Redis)
Anwendungsfälle
Automatisierung komplexer Workflows
Mit seinen erweiterten OpenClaw-Fähigkeiten kann GLM-5-Turbo komplexe Geschäftsprozesse dekonstruieren, die zugrunde liegende Logik identifizieren und autonom die erforderlichen Skills suchen oder generieren, um Aufgaben auszuführen.
Bei der Produktion von Kurzvideos kann das Modell beispielsweise Schreib-, Bildgenerierungs- und Videoproduktionstools suchen, installieren und orchestrieren – und so den gesamten Workflow von Anfang bis Ende planen und ausführen.
QA für lange Dokumente und Tiefenanalyse
Das Modell behält innerhalb einer Sitzung den vollständigen Kontext über lange Dokumente hinweg bei, was präzise Fragen-Antwort-Zyklen über mehrere Runden hinweg ermöglicht. Seine hohe Token-Effizienz stellt schnelle Antworten bei geringeren Rechenkosten sicher.
In großen Codebasen kann GLM-5-Turbo architektonische Designs analysieren, Abhängigkeiten zwischen Komponenten abbilden und potenzielle Kettenreaktionen durch Änderungen am Low-Level-Code kennzeichnen.
„Vibe Coding“
Innerhalb des Softwareentwicklungs-Lebenszyklus fungiert GLM-5-Turbo eher wie ein Full-Stack-Entwickler, der in komplexe Arbeitsabläufe eingebettet ist. Entwickler können die übergeordnete Logik skizzieren, während das Modell die Anwendungsarchitektur in Echtzeit schrittweise aufbaut.
In Kombination mit multimodalen Skills können Nutzer UI-Bilder, Bildschirmaufnahmen oder Skizzen hochladen, die das Modell direkt in funktionale Frontend-Komponenten umwandeln kann.
Warum GLM-5-Turbo auf Atlas Cloud nutzen?
Als KI-Infrastrukturplattform für alle Modalitäten bietet Atlas Cloud seinen Nutzern eine einheitliche API-Schnittstelle. Nach der Anbindung können Nutzer problemlos auf über 300 fortschrittliche KI-Modelle zugreifen, einschließlich Text-, Bild-, Video- oder multimodaler Modelle.
Zielgruppe
- Unabhängige Entwickler, die nach kostengünstigen, vereinfachten Lösungen für den Aufruf verschiedener KI-Modelle suchen.
- Unternehmen, die eine stabile, sichere und skalierbare Infrastruktur zur Unterstützung ihres Kerngeschäfts benötigen.
- Entwicklungsteams, die mehrere cross-modale Modelle effizient in Projekte integrieren müssen.
- Workflow-Nutzer, die Wert auf Toolchain-Kompatibilität legen und ComfyUI oder n8n verwenden.
Produktmerkmale
- Stark vereinfachte Integration: Die Plattform bietet eine OpenAI-kompatible API, die die Arbeitslast für Entwickler sofort reduziert. Kein Jonglieren mit mehreren Anbieterschlüsseln oder Sorgen um Wartungskosten über verschiedene Plattformen hinweg mehr.
- Kostenvorteil: Im Vergleich zu Wettbewerbern bietet Atlas Cloud niedrigere Bereitstellungskosten. Nano Banana 2 kostet 0,056 USD/Bild (Konkurrenz: 0,07 USD/Bild); Veo 3.1 ist für 0,09 USD/Sekunde verfügbar (Konkurrenz: 0,1 USD/Sekunde). Zudem bietet das Playground-Interface volle Preistransparenz, wobei der „Run“-Button den Abzugsbetrag pro Bild oder pro Sekunde Video direkt anzeigt.
- Stabilität & Support auf Enterprise-Niveau: Atlas Cloud stellt sicher, dass der Datenschutz strenge Standards erfüllt und auch sensible Informationen verarbeitet werden können.
- Plug-and-Play-freundlich: Entwickelt, um mühelos mit Tools wie ComfyUI und n8n zusammenzuarbeiten, was Unternehmen hilft, Wechselkosten zu senken und sofort produktiv zu sein.
Vergleich mit ähnlichen Produkten
- Fal.ai: Während sie einige Modelle anbieten, stellt Atlas Cloud eine größere Auswahl (300+) und wettbewerbsfähigere Preise bereit. Neue registrierte Nutzer erhalten zudem ein Startguthaben von 1 USD.
- Wavespeed: Die Preise sind deutlich höher. Atlas Cloud bietet zusätzlichen Support für Unternehmens-Compliance und fachkundige technische Beratung, die bei Wavespeed nicht im Vordergrund stehen.
- Kie.ai: Verwendet ein undurchsichtiges Guthabensystem. Atlas Cloud zeigt die genauen Kosten für jeden Durchlauf direkt auf der Oberfläche an. Die Anzahl der Modelle ist zudem höher als bei Kie.ai.
- Replicate: Konzentriert sich auf das Modell-Hosting. Die Vorteile von Atlas Cloud liegen in der API-Vereinheitlichung, der Geschwindigkeit der Modellbereitstellung und entwicklerfreundlicheren Support-Richtlinien.
- OpenAI oder Google: Diese Anbieter stellen nur ihre eigenen Modelle zur Verfügung. Nutzer mit cross-modalen Anforderungen müssen in der Regel mehrere Dienste integrieren. Atlas Cloud integriert proprietäre und Open-Source-Modelle unter einer einzigen API, was die Systemkomplexität reduziert.
Wie nutzt man GLM-5-Turbo auf Atlas Cloud?
Methode 1: Direkte Nutzung auf der Plattform
Methode 2: Nutzung über API-Integration
Schritt 1: API-Schlüssel abrufen. Erstellen Sie Ihren API-Schlüssel und fügen Sie ihn in der Konsole ein:


Schritt 2: Lesen Sie die API-Dokumentation. Prüfen Sie Anfrageparameter, Authentifizierungsmethoden usw.
Schritt 3: Führen Sie Ihre erste Anfrage aus (Python-Beispiel)
Beispiel mit GLM-5.
plaintext1{ 2 "model": "zai-org/glm-5", 3 "messages": [ 4 { 5 "role": "user", 6 "content": "Hello" 7 } 8 ], 9 "max_tokens": 1024, 10 "temperature": 0.7, 11 "stream": false 12}
FAQ
Was ist der Unterschied zwischen GLM-5-Turbo und GLM-5? GLM-5-Turbo ist schneller und kosteneffizienter, mit einer deutlich verbesserten Token-Effizienz – Berichten zufolge bis zu dreimal so hoch wie bei GLM-5. Es ist zudem speziell für OpenClaw-Szenarien optimiert.
Wie schneidet GLM-5-Turbo im Vergleich zu MiniMax M2.7** ab?** Beide Modelle sind für die agentische Tool-Nutzung optimiert und bieten eine höhere Token-Effizienz als GLM-5. Beide unterstützen Kontextfenster von etwa 200.000 Token (MiniMax M2.7 unterstützt 196.608 Token). Wir bereiten derzeit einen Blogbeitrag für eine weiterführende vergleichende Bewertung vor. Bleiben Sie dran!
Welches GLM-Modell wird für die OpenClaw-Bereitstellung empfohlen? GLM-5-Turbo, da es speziell für OpenClaw-Szenarien optimiert ist und eine Datenanalyse-Performance erreicht, die mit Claude Opus 4.6 vergleichbar ist.






