Das eigentliche Problem bei KI-Videos ist nicht, dass das Ergebnis „falsch“ aussieht. Es ist, dass es sich langsam anfühlt.
1. Warum 15 Sekunden KI-Action oft nicht überzeugen
Wer sich intensiv mit Seedance 2.0 beschäftigt hat, stößt immer wieder an dieselbe Grenze: Wenn man einen 15-sekündigen Clip anfordert, liefert das Modell drei oder vier Einstellungen — und das war's.
Du fütterst es mit einer Kampfszene. Zurück kommt: „Kämpfer kommt rein → hebt die Waffe → erstarrt.“ Aufbau, Aktion, Ende. Abspann.
Aber so liest sich ein Kampf auf dem Bildschirm nicht. Bevor der Schlag landet, dreht sich die Schulter. Nach dem Ausweichen wird bereits der Konter eingeleitet. Eine Totale schneidet auf eine extreme Nahaufnahme, gefolgt von einer Zeitlupen-Einstellung des Aufpralls. Spannung entsteht durch Schnittdichte — nicht dadurch, dass man ein einzelnes Bild schöner macht.
Und das Modell wird dir von sich aus keine 16 Einstellungen liefern, egal wie du es steuerst.
Genau das ist das Problem. Hier zeigen wir, wie wir es gelöst haben.
2. Drei Stellschrauben, die den Workflow verändert haben
Nachdem wir die gesamte Demo für eine Action-Sequenz mit einer Figur von Anfang bis Ende durchgespielt haben, sind wir auf drei entscheidende Faktoren gestoßen:
① Action-Spannung entsteht durch Schnittdichte, nicht durch die Qualität einzelner Aufnahmen. Versuche nicht, eine Aufnahme perfekt zu machen. Zerlege die 15 Sekunden zuerst in ein Storyboard mit 16 Feldern und gib dieses dann dem Videomodell.
② Die wahre Stärke von GPT Image 2 liegt im Verständnis von Skripten und Shot-Layouts – nicht in der Stil-Konsistenz. Wir wollten anfangs, dass GPT Image 2 über die gesamte Kette einen einheitlichen Stil beibehält. Nach Tests mussten wir akzeptieren, dass Referenz-zu-Video-Prozesse natürlich in Richtung CG driften – es gibt keinen sauberen Weg, dies zu erzwingen. Aber was GPT Image 2 hervorragend kann – ein Skript lesen, die Einstellungen planen und ein 16-Felder-Storyboard erstellen – macht ihm kein anderes Modell in unserem Pool nach.
③ Die gesamte Pipeline läuft über einen einzigen AtlasCloud API-Key. GPT Image 2, Nano Banana 2 und Seedance 2.0 befinden sich alle im selben Modell-Pool auf AtlasCloud. Ein Key. Ein Endpunkt. Eine Rechnung. Ein Kontingent. Kein technisches Gefrickel mit verschiedenen Anbietern.
3. Der Stresstest mit einer Figur
Um GPT Image 2 wirklich auf die Probe zu stellen, haben wir uns die schwierigste Figur ausgesucht, die uns einfiel.
Lerne Ranx kennen – eine Cyber-Taktik-Operatorin. Sandgoldene Zöpfe. Und vier völlig asymmetrische Ausrüstungsgegenstände:
- Ein schwarzer, oberschenkelhoher Strumpf nur am rechten Bein
- Ein rotes Hartschalen-Holster nur am rechten Oberschenkel
- Cyanfarbene Paspeln nur am rechten Knie
- Eine dicke schwarze Spule, die von der rechten Rückseite ihres Gürtels bis zu ihrer linken Wade verläuft
Das einzige Referenzbild, das wir dem Modell gaben, war eine Dreiviertelansicht von hinten. Das Modell musste die Vorderseite, die Seiten, die Mimik und die Waffendetails ableiten – ohne eine dieser vier Asymmetrien zu spiegeln.
Ergebnis: Eine Generierung. Sechs Drehungen, vier Kopfstudien, vier Mimiken, Waffen-Detail, Hände, Füße – alles auf einer Seite. Alle vier Asymmetrien fixiert. Kein einziges Spiegeln.


Die Umgebung haben wir als fertige Design-Referenz behandelt (Cyberpunk-Regen-Gasse, Ästhetik wie im Spiel Stray):

4. Der A/B-Vergleich beweist die Methode
Dies ist das Experiment, auf dem der gesamte Workflow basiert. Gleiches Skript. Gleiches Charakterblatt. Gleiche Szenenreferenz. Die einzige Variable ist, ob ein Storyboard existiert.
Kontrolle: nur Text-Prompt, kein Storyboard
Inputs für Seedance 2.0 Referenz-zu-Video:
- 1× Charakterblatt
- 1× Szenenreferenz
- Ein detaillierter 15-sekündiger Text-Prompt, der vier harte Schnitte beschreibt
Das Material ist lesbar und handwerklich in Ordnung. Aber der Clip wirkt wie etwa drei langsame Takte – in die Gasse gehen, Waffe heben, erstarren. Es liest sich wie eine Charakter-Demo, nicht wie ein Kampf.
Test: mit einem 16-Felder-Storyboard
Wir baten GPT Image 2, dasselbe Skript in ein 4×4 = 16-Felder Storyboard zu zerlegen, wobei jedes Feld markiert war mit:
- Einstellungsnummer (① ② ③ … ⑯)
- Einstellungsgröße (TOTAL / MS / NAH / EXTREM)
- Kamerapfeil (→ ↘ ↙ ↑ ↓ ↗)
- Rhythmus-Notiz („statischer Anstieg“ / „harter Schnitt“ / „Aufprall“ / „Kill-Shot“ / „Outro“)
- Eine kurze Regieanweisung auf handgeschriebenem Chinesisch – rein eine Entscheidung der Dichte; Chinesisch lässt mehr Regieanweisungen in ein kleines Storyboard-Feld packen (sowohl GPT Image 2 als auch Seedance 2.0 lesen beide Sprachen gleich gut)
Dann ein Ein-Zeilen-Prompt in Seedance 2.0 Referenz-zu-Video:
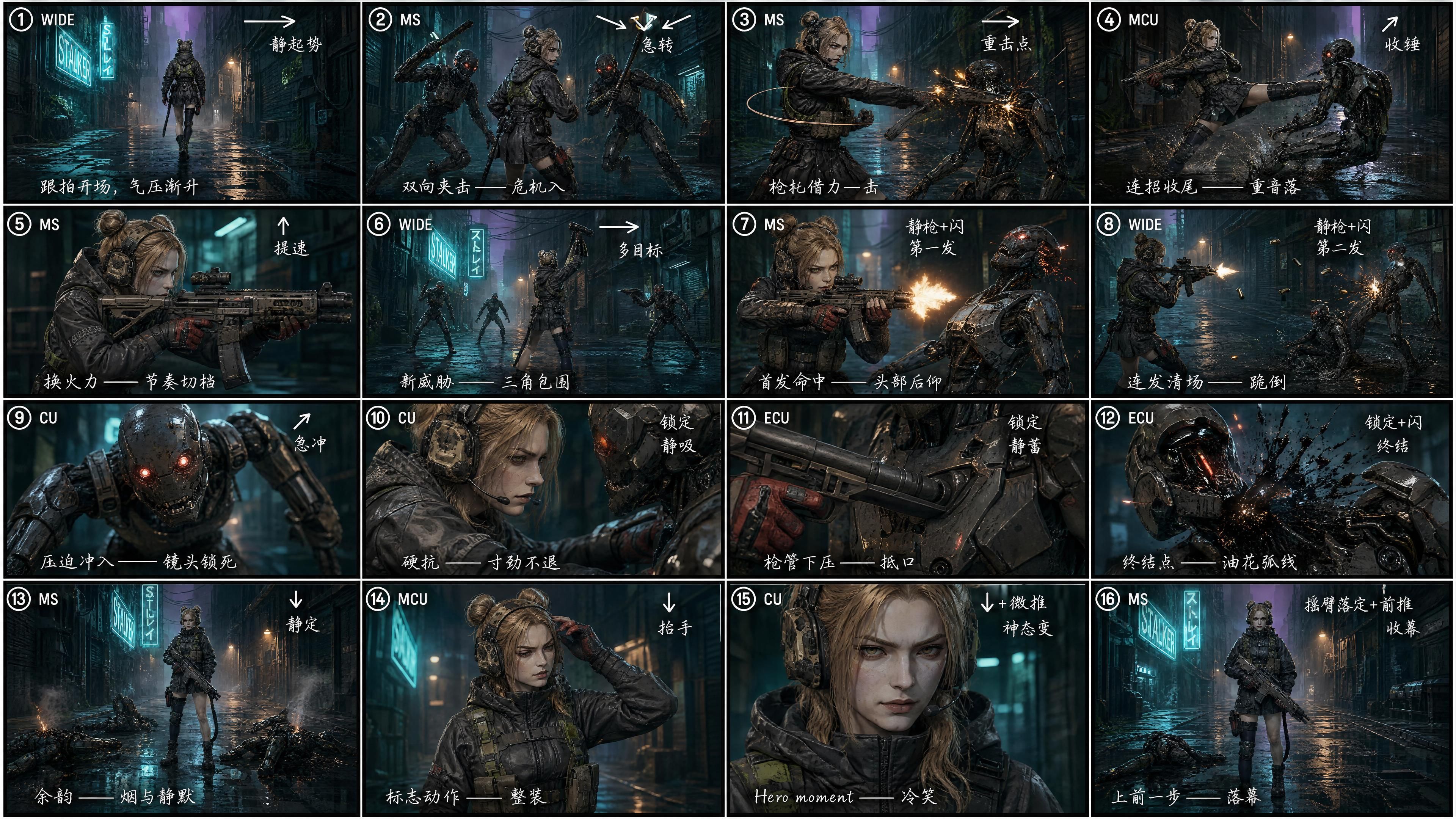
"Generiere ein Video, das streng dem Referenzbild 3 als Storyboard folgt. Starkes filmisches Gefühl und Kameraführung, übertriebene Dynamik, harte Action."
Der Unterschied ist ohne Messung sichtbar. Die Schnittdichte steigt etwa um das Vierfache. Weite Verfolgung zu Schulterkamera-Mittelschnitt zu extremer Nahaufnahme auf den Lauf zu einer Heldenpose als Abschluss – fünfzehn Sekunden, komplett gefüllt. Gleiches Skript, anderes Tempo. Die erste Version fühlt sich wie eine Demo an. Die zweite liest sich wie ein Trailer.
Das ist die gesamte These dieses Workflows: GPT Image 2 ist nicht dafür da, den Stil festzulegen. Es ist dafür da, ein Skript in eine dichte Sequenz von Einstellungen zu zerlegen.
5. Skalierung: ein Duell zwischen zwei Kämpfern
Nachdem die Version mit einer Figur sauber lief, haben wir auf ein Duell skaliert. Das Schwierigste an einem Kampf zwischen zwei Personen ist es, vier Dinge gleichzeitig festzulegen – Figur A, Figur B, die Umgebung und den Action-Rhythmus.
Anstatt vier separate Bilder zu generieren und zu versuchen, sie zu verketten, haben wir GPT Image 2 gebeten, alle vier in einem einzigen Bild zu verarbeiten:
- Figur A (A-27): eine verfeinerte Version von Ranx – sandgoldene Pferdeschwanz-Taktik-Operatorin in kurzem Kampfmantel
- Figur B: ein ursprüngliches Design eines Söldners – schwarz-roter langer Mantel, zurückgebundenes Haar, Breitschwert an der Hüfte
- Die Umgebung: eine industrielle Festung namens Ash City – bernsteinfarbenes Abendlicht, Ofenglut in der Ferne, überall Rauch
- Zehn handgezeichnete Action-Beats: sondieren → stürmen → blocken → ausweichen → Haken → kontern → fixieren → Knie → nah ran → stürzen

Wichtig zu erwähnen: Nur Figur A nutzte ein Referenzbild (Ranx von vorhin). Figur B, die gesamte Umgebung und alle zehn Action-Beats – das hat GPT Image 2 selbst entworfen. Wir haben die Stimmung beschrieben; den Rest hat es geliefert.
Stil, beide Identitäten, die Umgebung und zehn Beats – alles fixiert in einer einzigen Generierung. Nichts drifftet zwischen den Bildern ab. Niemand wechselt mitten im Clip sein Kostüm.
Dann direkt in Seedance 2.0 Referenz-zu-Video:
Ein Stand-off auf einem Dach, verankert durch zwei Fraktionsinsignien auf dem Boden, ein Ringkampf in der Mitte und ein finaler Wurf – fünfzehn Sekunden Choreografie für zwei Personen in einem einzigen Durchlauf.
6. Warum diese Pipeline über einen einzigen API-Key läuft
Die Kette – Figur → Szene → Storyboard → Video – bedeutete früher, API-Keys, SDKs, Dokumentationen, Abrechnungen und Rate-Limits bei verschiedenen Anbietern jonglieren zu müssen. Du kennst das.
Auf AtlasCloud liegt alles hinter einem einzigen Endpunkt:
| Schritt | Modell | Plattform |
|---|---|---|
| Charakterblatt | GPT Image 2 | AtlasCloud |
| Szenenkonzept | Nano Banana 2 | AtlasCloud |
| Storyboard | GPT Image 2 | AtlasCloud |
| Video | Seedance 2.0 | AtlasCloud |
Ein Key. Ein Endpunkt. Ein Kontingent. Eine Rechnung. Der Integrations- und Betriebsaufwand sinkt gegen Null.
7. Das Fazit: Hör auf, für einen einheitlichen Stil über Modelle hinweg zu kämpfen – nutze die Stärken jedes Modells
Wir haben viel Energie darauf verwendet, einen einheitlichen Stil über jeden Schritt der Kette hinweg zu erzwingen. Im Referenz-zu-Video-Modus ist dieser Kampf nicht zu gewinnen – je mehr man darauf drängt, desto schlechter wird das Ergebnis.
Sobald wir dieses Ziel losließen, öffnete sich der Workflow. Lass jedes Modell das tun, wofür es wirklich gut ist.
- GPT Image 2 — das Skript zerlegen, die Einstellungen planen
- Seedance 2.0 — die Zeit entfalten, die Action rendern
- AtlasCloud — ein Key, eine Kette
Wenn du Action-Kurzfilme, Kampfszenen oder Duell-Choreografien mit KI erstellst, ist dies der Workflow, den wir empfehlen würden.
Probiere es selbst aus
Beide Modelle befinden sich im selben AtlasCloud-Modell-Pool – ein API-Key steuert die gesamte Kette:
- Seedance 2.0 (Referenz-zu-Video) → atlascloud.ai/collections/seedance2
- GPT Image 2 (Charakterblatt + Storyboard) → atlascloud.ai/collections/gpt-image-2
- Nano Banana 2 (Szenenkonzept) → atlascloud.ai/collections/nanobanana-2
Die vollständige Schritt-für-Schritt-Anleitung und alle in diesem Artikel verwendeten Prompts sind zusammen mit dem Video-Walkthrough auf YouTube veröffentlicht.
Leg los und erschaffe etwas.






