
ChatGPT API for Frontier GPT 5.6 Reasoning
Die ChatGPT API auf Atlas Cloud bringt OpenAIs neueste GPT 5.6-Familie in eine einzige Integration: Sol für tiefgehendes Frontier Reasoning, Terra für fundierte Produktions-Workloads und Luna für natürliche Konversation und Content-Generierung. Routen Sie jedes Modell über einen einzigen OpenAI-kompatiblen Schlüssel, verlassen Sie sich auf produktionsreife Verfügbarkeit und zahlen Sie transparente nutzungsabhängige Tarife ab $1 per million input tokens. Beginnen Sie noch heute mit der Entwicklung.
Erkunden Sie die Führenden Modelle
Atlas Cloud bietet Ihnen die neuesten branchenführenden kreativen Modelle.
Das richtige ChatGPT API Model wählen: alle Endpoints im Vergleich
Fünf Textgenerierungs-Endpoints von Frontier-Reasoning bis hin zu kostengünstigen Konversationen, alle bereitgestellt über einen einzigen OpenAI-kompatiblen Schlüssel mit transparenter Pay-as-you-go-Preisgestaltung.
| Modalität | Beschreibung |
|---|---|
| GPT 5.6 Sol API (Text to Text) | Entwickelt für Frontier-AI-Workloads: GPT 5.6 Sol verwandelt komplexe Text-Prompts in tiefgehende, mehrstufige Reasoning-Ausgaben für anspruchsvolle Problemlösungen. Der Standardpreis liegt bei 5 $ pro Million Input-Tokens und 30 $ pro Million Output-Tokens, womit es die Flaggschiff-Wahl ist, wenn Antwortqualität wichtiger ist als Kosten. |
| GPT 5.6 Terra API (Text to Text) | Sie benötigen einen verlässlichen Produktionsstandard? GPT 5.6 Terra wandelt Prompts in fundierte, praktische Texte für reale Workflows und Analyse-Pipelines um – für 2,50 $ Input und 15 $ Output pro Million Tokens. Teams setzen es in kundenorientierten Anwendungen ein, bei denen Konsistenz wichtiger ist als experimentelle Tiefe. |
| GPT 5.6 Luna API (Text to Text) | Leiten Sie Konversations- und Kreativ-Traffic an GPT 5.6 Luna weiter, ein Textmodell, das auf natürliche Dialoge, Content-Generierung und personalisierte AI-Erlebnisse abgestimmt ist. Mit 1 $ Input und 6 $ Output pro Million Tokens ist es der wirtschaftlichste Einstiegspunkt in dieses ChatGPT API-Angebot und eignet sich gut für Chat-Produkte und Copy-Generierung mit hohem Volumen. |
| GPT 5.4 API (Text to Text) | GPT 5.4 verarbeitet Textanweisungen zu zuverlässigem Code, Long-Form-Content und strukturierten Problemlösungsausgaben mit hoher Genauigkeit. Als fortschrittliches multimodales Modell konzipiert, liegt es mit 2,50 $ Input und 15 $ Output pro Million Tokens im mittleren Preissegment – eine praktische Wahl für Coding-Assistenten und Content-Plattformen. |
| GPT 5.5 API (Text to Text) | Wenn schwierige Probleme Premium-Ausgaben rechtfertigen, liefert GPT 5.5 fortschrittliches Reasoning, Coding und Content-Generierung über einen einzigen Text-Endpoint. Mit 5 $ Input und 30 $ Output pro Million Tokens richtet es sich an komplexe, zuverlässigkeitskritische Workloads wie Agent-Orchestrierung und technische Analyse. |
Die ChatGPT API: GPT 5.x Tiers und Open Weights
Greifen Sie über eine einzige ChatGPT API auf die gesamte GPT 5.x Modellreihe und das Open-Weight-Modell GPT OSS 120B zu, passen Sie den Reasoning-Aufwand von low bis xhigh an, kombinieren Sie Text, Bilder und Dateien in einem einzigen Aufruf und nutzen Sie native Tools mit Live-Websuche über einen OpenAI-kompatiblen Schlüssel.
Text, Bilder und Dateien in einem einzigen ChatGPT API-Aufruf
Eine einzelne ChatGPT API-Anfrage kann Klartext, Bild-URLs und Dokumentdateien in einer Nachricht kombinieren. Dadurch entfallen separate OCR- oder Vision-Dienste, sodass Sie gescannte Verträge zusammenfassen oder Screenshots in einem Durchgang auslesen können.
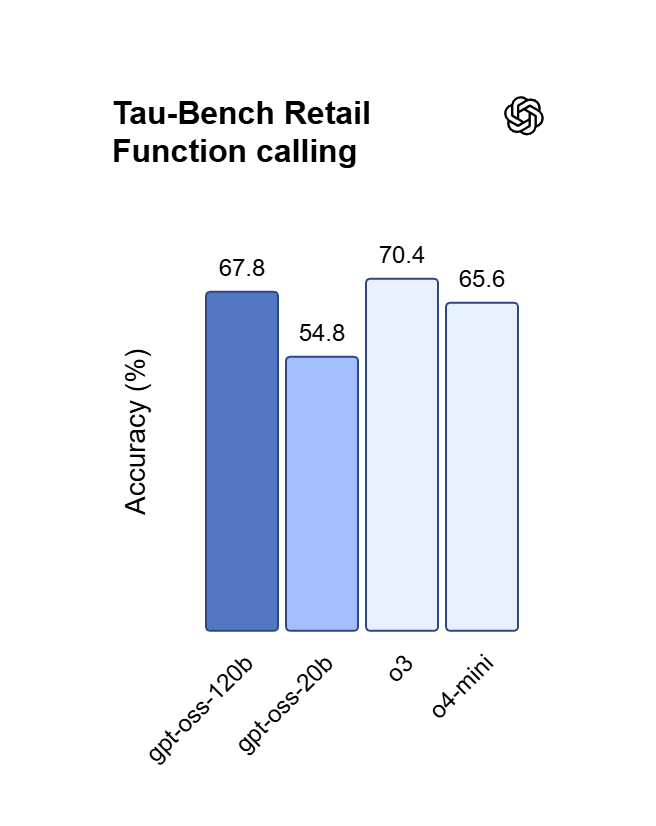
Zuverlässige Befolgung von Anweisungen in der ChatGPT API
GPT OSS 120B hält sich an mehrschichtige System-Prompts und sorgt dafür, dass Formate, Einschränkungen und Ton über Ausgaben hinweg stabil bleiben, ohne abzudriften. Diese Zuverlässigkeit eignet sich für autonome Agents, strukturierte Extraktion und Produktionspipelines, in denen Ausgaben die Regeln einhalten müssen.
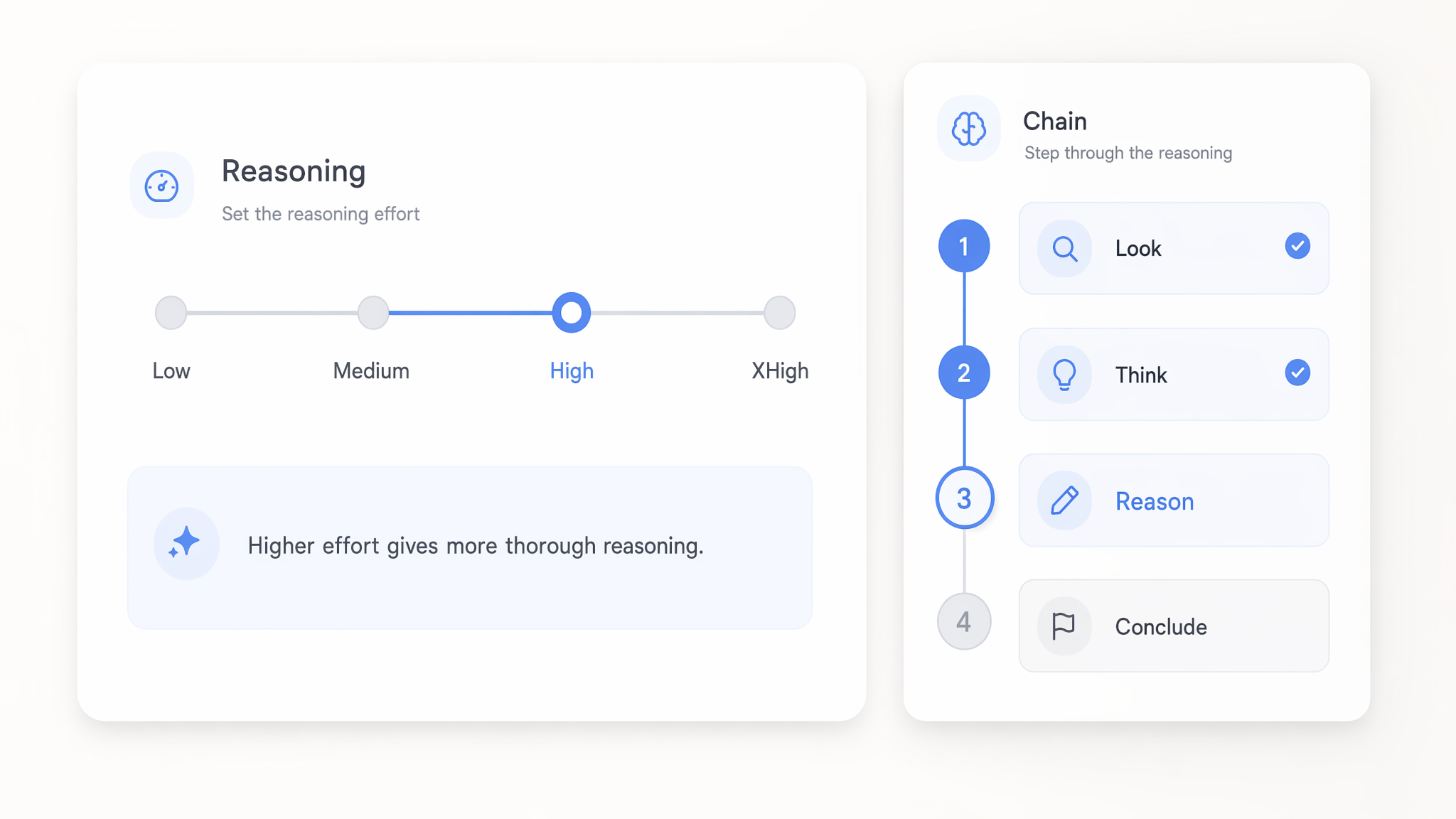
Reasoning-Aufwand von low bis xHigh einstellen
Legen Sie den Reasoning-Aufwand bei GPT 5.x Modellen von low bis xhigh fest, um zu steuern, wie gründlich sie vor der Antwort nachdenken. Niedrige Einstellungen beantworten einfache Aufrufe schnell und kostengünstig, während xhigh mehr Rechenleistung für anspruchsvolle mehrstufige Logik einsetzt.
Apache 2.0 Weights, die Ihnen vollständig gehören
GPT OSS 120B wird unter der Apache 2.0 Lizenz bereitgestellt und erlaubt kommerzielle Nutzung sowie privates Fine-Tuning auf einer einzelnen 80GB GPU. Hosten Sie es On-Premises, um proprietäre Daten im eigenen Haus zu behalten und Gebühren pro Token vollständig zu vermeiden.

Fünf GPT Tiers, eine ChatGPT API
Eine ChatGPT API bedient die gesamte GPT 5.x Modellreihe, mit Preisen von Luna für $1 bis Sol für $5 pro Million Input-Tokens. Ordnen Sie jeden Aufruf dem Tier zu, das zu Kosten- und Intelligenzanforderungen passt, ganz ohne Endpoint-Änderungen.
Für Vibecoding optimiertes Reasoning
Mit nahezu gleicher Leistung wie OpenAI o4-mini bewältigt GPT OSS 120B mehrstufige Code-Synthese und mathematische Beweise. Verwandeln Sie Ideen in Alltagssprache in funktionierende Web-Apps, debuggen Sie verschachtelte Logik und orchestrieren Sie komplexe Task-Scheduling-Abläufe.

Function Calls mit Live-Websuche
GPT 5.x Modelle unterstützen Function Calling mit automatischer Tool-Auswahl sowie eine integrierte Websuche, die aktuelle Ergebnisse abruft. Streamen Sie Antworten als server-sent events, während Prompt-Caching die gecachten Inputs von GPT 5.6 Sol auf $0.5 pro Million Tokens senkt.
Ein Prompt, drei Herausforderer: ChatGPT API im direkten Vergleich
Wir haben exakt dieselbe Build-Anweisung über die ChatGPT API an Modelle und zwei konkurrierende Flaggschiffe gesendet und anschließend jede rohe HTML-Antwort unverändert gerendert, damit du Tiefe des Reasonings, Codequalität und Designgeschmack direkt nebeneinander beurteilen kannst.
Erstelle eine einzelne, vollständig eigenständige HTML-Datei (nur Inline-CSS und JavaScript — absolut keine externen Bibliotheken, CDNs, Frameworks, Fonts oder Bild-URLs), die sich direkt in jedem modernen Browser öffnen lässt und einen lebendigen, selbst wachsenden Glass-Greenhouse-Ecosystem-Simulator ausführt, der komplett als flache Canvas/SVG-Vektorillustration gerendert wird. Die vollflächige Szene zeigt ein kuppelförmiges viktorianisches Gewächshaus: Eine gebogene Glaskuppel spannt sich als rahmendes Element über den oberen Bereich, ihre Scheiben sind als durchscheinende jadegrüne Polygone mit weichen Glanzlichtern und feinen Sprossenlinien gezeichnet, und am unteren Rand verläuft ein Streifen dunkler Kulturerde. Die Art Direction ist eine klare Vektorillustration — Blätter und Stängel mit präzisen Aderlinien und halbtransparenten, geschichteten Füllungen, eine Palette aus nebligem Salbeigrün und moosigem Braun mit bernsteinfarbenem Sonnenlicht und Jadeglas-Akzenten; kein Fotorealismus, keine Verläufe als Texturen, sondern grafisch und handillustriert im Eindruck. Kerninteraktion: Ein Klick irgendwo auf die Erde pflanzt an dieser Stelle einen Samen, und die Pflanze wächst in Echtzeit mithilfe eines echten L-Systems — implementiere eine rekursive Rewrite-Grammatik (Axiom plus Produktionsregeln mit Verzweigungsklammern und randomisiertem Winkel-/Längen-Jitter pro Instanz, sodass keine zwei Pflanzen identisch sind) und animiere die Ableitung so, dass Äste über einige Sekunden hinweg wachsen, sich verzweigen und Blätter entfalten, statt vollständig ausgeformt aufzutauchen. Tropische Farne und Kletterranken sollen sich phototrop zum ziehbaren Sonnenpunkt biegen und winden: Rendere eine leuchtende bernsteinfarbene Sonnenscheibe, die der Nutzer greifen und beliebig im Himmel ziehen kann, und jede wachsende Spitze muss ihre Wachstumsrichtung kontinuierlich an der aktuellen Position der Sonne ausrichten, sodass das Ziehen der Sonne sichtbar steuert, wie sich der gesamte Garten neigt und emporrankt. Keimlinge entfalten sich mit einer Easing-Animation, und Kondensationstropfen bilden sich auf dem Glas und gleiten langsam in einer Schleife nach unten. Steuere alles über einen Tag-Nacht-Zyklus, der an die Position der Sonne gekoppelt ist: Das Umgebungslicht und die Himmelsfärbung gleiten sanft entlang eines Verlaufs von warmem Gold zu kühlem Blau, die Position der Sonne bestimmt Richtung und Länge weicher Pflanzenschatten auf dem Boden sowie die wandernden Lichtflecken auf dem Glas, und in der Dämmerung blenden sich Glühwürmchen als kleine pulsierende Lichtpunkte ein, die zwischen dem Blattwerk treiben. Die Komposition lässt das Pflanzenwachstum von der Basis nach oben zur Mitte ausstrahlen, begrenzt durch den Bogen der Kuppel. Verwende requestAnimationFrame für eine kontinuierliche, leise atmende Animationsschleife; halte die Performance auch mit vielen Pflanzen gleichzeitig auf dem Bildschirm flüssig. Füge subtile, unaufdringliche Steuerelemente hinzu (z. B. einen Slider oder einen automatisch fortschreitenden Schalter für die Tageszeit sowie einen Reset-/Clear-Button), passend zum illustrierten Stil gestaltet, plus einen einzeiligen Hinweis, dass der Nutzer auf die Erde klicken soll, um zu pflanzen, und die Sonne ziehen soll, um das Wachstum zu lenken. Mache die Darstellung für jede Fenstergröße responsiv, und gestalte die emotionale Tonalität ruhig, still und lebendig — erstes Morgenlicht fällt schräg herein, während zarte Triebe gemeinsam aufgehen. Dies ist eine generative Simulation, kein Spiel und kein Dashboard: Priorisiere den echten rekursiven Wachstumsalgorithmus, die Animationsschleife sowie Licht-/Schatten- und Phototropismus-Physik.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Erstelle eine vollständige Single-File-HTML-Seite mit einem interaktiven globalen Startup-Funding-Dashboard mit fiktiven, aber in sich konsistenten Daten für 8 Branchen über 5 Jahre. Sämtliches CSS und JavaScript muss inline sein, ohne externe Abhängigkeiten, ohne Chart-Bibliotheken, ohne CDNs, ohne Bilder. Rendere drei handcodierte Visualisierungen auf Canvas oder SVG: ein animiertes Balkendiagramm, das sich mit Easing neu sortiert, wenn der Nutzer über einen Slider ein Jahr auswählt, ein Liniendiagramm mit Hover-Tooltips, die exakte Werte anzeigen, plus vertikaler Tracking-Hilfslinie, und ein Donut-Diagramm, dessen Segmente sich beim Hover mit einer Spring-Animation ausdehnen. Verwende eine dunkle moderne UI mit einer Akzentpalette von Violett bis Türkis, animierte Zahlenzähler in vier KPI-Stat-Cards, eine Sektorfilter-Zeile mit Toggle-Chips, die alle Diagramme sofort aktualisiert, sowie einen Hell-/Dunkel-Theme-Schalter mit sanften Farbübergängen. Das Layout muss responsiv sein, unterhalb von 768px auf eine einzelne Spalte umbrechen, und jede Interaktion muss in Echtzeit ohne Neuladen der Seite reagieren.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
Jede Workload, die die ChatGPT API antreiben kann
Von agentischem Coding und strukturierter Extraktion bis hin zu fundiertem Support-Chat und Content in hoher Stückzahl: Die ChatGPT API auf Atlas Cloud leitet jede Aufgabe über einen einzigen OpenAI-kompatiblen Schlüssel an die passende GPT 5.6-Stufe weiter.

Agentische Coding-Tools mit der ChatGPT API ausliefern
Leiten Sie komplexe Refactorings und Multi-File-Code-Synthese an GPT 5.6 Sol weiter, die Deep-Reasoning-Stufe der Familie für anspruchsvolle Engineering-Workloads. Teams, die Coding-Copilots, automatisierte Review-Bots und Testgeneratoren entwickeln, erhalten produktionsreife Logik.

Markengerechte Content-Erstellung im großen Maßstab
GPT 5.6 Luna, die kreative Stufe der Familie, erstellt Blogbeiträge, Produktbeschreibungen und lokalisierte Texte mit natürlichem Ton und personalisierter Ausgabe. Content-Teams und E-Commerce-Plattformen produzieren große Mengen an Text, ohne die Markenstimme zu opfern.

Support-Assistenten mit der ChatGPT API betreiben
Sie brauchen einen Chatbot, der sich an das Skript hält? GPT 5.6 Terra liefert verlässliche, fundierte Antworten für produktive Konversationen, damit Support-Teams und SaaS-Produkte Tickets automatisieren und wiederkehrende Anfragen zuverlässig abfangen können.

Retrieval-Augmented Knowledge Systems
Speisen Sie ganze Richtlinienhandbücher oder Forschungsarchive in ein Long-Context-Modell ein und erhalten Sie fundierte Antworten mit Quellentreue. Rechts-, Medizin- und interne Suchteams gewinnen eine zuverlässige Engine für retrieval-augmented Question Answering.

Strukturierte Datenextraktion über die ChatGPT API
Unübersichtliche Rechnungen, E-Mails und PDFs werden in sauberes JSON umgewandelt, dem nachgelagerte Systeme vertrauen können. Zuverlässiges Befolgen von Anweisungen hält Schemas intakt und unterstützt Datenpipelines, CRM-Automatisierung und Analytics-Workflows, die keine Abweichungen tolerieren.

Jede Aufgabe der richtigen Model Tier zuordnen
Wenn Budget und Latenz zählen, wechseln Sie über einen einzigen OpenAI-kompatiblen Schlüssel zwischen Sol, Terra und Luna. Startups und Indie-Entwickler prototypisieren schnell mit Pay-as-you-go-Preisen und skalieren anschließend dieselbe Integration für die Produktion.
| Modell | Kontext | Max. Ausgabe | Eingabe | Positionierung |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Text | Hocheffizientes Reasoning-LLM |
| GLM-5 | 202.75K | 202.75K | Text | Flaggschiff-Foundation-Model |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Allgemeines Flaggschiffmodell |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA für agentisches Coding |
So verwenden Sie ChatGPT auf Atlas Cloud
In wenigen Minuten startklar — folgen Sie diesen einfachen Schritten, um Modelle über die Plattform von Atlas Cloud zu integrieren und bereitzustellen.
Atlas Cloud-Konto erstellen
Registrieren Sie sich auf atlascloud.ai und schließen Sie die Verifizierung ab. Neue Nutzer erhalten kostenlose Credits zum Erkunden der Plattform und Testen von Modellen.
Warum ChatGPT auf Atlas Cloud Verwenden
Die Kombination der fortschrittlichen ChatGPT-Modelle mit der GPU-beschleunigten Plattform von Atlas Cloud bietet unübertroffene Leistung, Skalierbarkeit und Entwicklererfahrung.
Leistung & Flexibilität
Niedrige Latenz:
GPU-optimierte Inferenz für Echtzeit-Reasoning.
Einheitliche API:
Führen Sie ChatGPT, GPT, Gemini und DeepSeek mit einer Integration aus.
Transparente Preisgestaltung:
Vorhersehbare Token-basierte Abrechnung mit serverlosen Optionen.
Unternehmen & Skalierung
Entwicklererfahrung:
SDKs, Analysen, Fine-Tuning-Tools und Vorlagen.
Zuverlässigkeit:
99,99% Verfügbarkeit, RBAC und compliance-bereite Protokollierung.
Sicherheit & Compliance:
SOC 2 Type II, HIPAA-Ausrichtung, Datensouveränität in den USA.
ChatGPT API: Entwicklerfragen beantwortet
Mit der ChatGPT API können Entwickler Prompts an die GPT-Modelle von OpenAI senden und programmatisch Completions erhalten, statt die Chat-Oberfläche zu nutzen. Auf Atlas Cloud erreichst du die vollständige GPT 5.6-Reihe zusammen mit GPT 5.4 und GPT 5.5 über einen einzigen OpenAI-kompatiblen Endpoint. Jeder Aufruf wird pro Token mit transparenter Pay-as-you-go-Preisgestaltung abgerechnet, sodass du nur für das zahlst, was du generierst.
Fünf Modelle decken das Spektrum von tiefgehendem Reasoning bis hin zu alltäglichem Chat ab. GPT 5.6 Sol ist auf anspruchsvolle Problemlösung und Frontier-Workloads ausgelegt, GPT 5.6 Terra übernimmt zuverlässige Produktions-Workflows, und GPT 5.6 Luna ist für natürliche Konversation und Content-Erstellung optimiert. GPT 5.4 und GPT 5.5 ergänzen multimodales Reasoning und Coding für Teams, die bewährte Allzweckleistung wünschen.
Erzeuge einen API Key, setze deine Base URL auf https://api.atlascloud.ai/v1 und wähle eine Model ID wie openai/gpt-5.6-terra. Da die ChatGPT API hier vollständig OpenAI-kompatibel ist, läuft vorhandener OpenAI SDK-Code nach lediglich einer Änderung von Base URL und Key. Es gibt keine Warteliste und kein Abonnement, und neue Releases sind mit Day-0-Zugriff verfügbar, sodass du noch am selben Tag deine erste Anfrage senden kannst.
Die Preise skalieren mit dem Modell, das du auswählst. GPT 5.6 Luna ist mit $1 pro Million Input Tokens und $6 pro Million Output Tokens am günstigsten, GPT 5.6 Terra liegt bei $2.5 und $15, und GPT 5.6 Sol bei $5 und $30. Prompt Caching senkt die Kosten für wiederholten Input, und die Abrechnung bleibt Pay-as-you-go, sodass dir nur die Tokens berechnet werden, die du tatsächlich nutzt.
Ja. Der Endpoint folgt dem OpenAI Chat Completions-Format, sodass die offiziellen OpenAI SDKs, LangChain und die meisten OpenAI-kompatiblen Bibliotheken funktionieren, sobald du Base URL und Key austauschst. Das bedeutet, dass eine bestehende ChatGPT API-Integration wechseln kann, ohne dass du deine Request-Logik neu schreiben musst.
Streaming und Function Calling funktionieren unverändert wie in der OpenAI-Implementierung: Du setzt stream auf true für eine Token-für-Token-Ausgabe und übergibst ein tools-Array, um Function Calls auszulösen. Strukturierte JSON-Antworten folgen demselben OpenAI-kompatiblen Request-Format, wodurch Agent-Orchestrierung und Datenextraktions-Pipelines vorhersehbar bleiben.
Diese Modelle akzeptieren große Prompts für Workflows mit langen Dokumenten und vollständigen Repositories. Die Preisgestaltung ist ab der Marke von 272,000 Tokens gestaffelt, mit einem Standardtarif für Prompts darunter und einem zweiten Tarif für Prompts, die 272,000 Tokens überschreiten. Du kannst also umfangreichen Kontext in einer einzigen Anfrage übergeben und genau nachvollziehen, wie sich der Tarif mit wachsendem Prompt ändert.
Wähle das Modell passend zur Aufgabe. Nutze GPT 5.6 Sol, wenn du Frontier Reasoning und anspruchsvolle Problemlösung brauchst, wähle GPT 5.6 Terra für fundierte Analysen in Produktionsqualität und verwende GPT 5.6 Luna für konversationelle oder kreative Aufgaben, bei denen die Kosten besonders wichtig sind. GPT 5.4 und GPT 5.5 bleiben starke multimodale Optionen für Coding und allgemeines Reasoning.
Atlas Cloud betreibt die ChatGPT API auf verwalteter Infrastruktur, die mit deinem Traffic skaliert, sodass du GPU-Provisionierung und Node-Orchestrierung beim Self-Hosting vermeidest. Neue Modellversionen sind mit Day-0-Zugriff verfügbar, damit du ohne Migrationsaufwand auf dem neuesten Stand bleibst. Wenn deine Anforderungen wachsen, deckt derselbe OpenAI-kompatible Key jedes Modell der Familie ab, sodass Skalierung nie eine neue Integration bedeutet.
Weitere Familien Erkunden
Seedance 2.0
Die Seedance 2.0 API bietet Ihnen Produktionszugriff auf das multimodale Videomodell von ByteDance – quadmodale Eingaben (Text, Bild, Video, Audio) und ein branchenführendes „Universal Reference“-System, das Bildkomposition, Kamerabewegungen und Charakteraktionen über verschiedene Einstellungen hinweg fixiert. Integrieren Sie Kontrolle auf Regisseur-Niveau mit nur einem API-Aufruf, einem Pauschalpreis von 0,09 $/s, sofortigem Key und ohne Warteliste – unterstützt durch branchenübliche Verfügbarkeit und Compliance für Unternehmen. Seedance 2.0 Native 4K ist ab sofort live!
Grok Imagine
Die Grok Imagine API bietet Entwicklern die Bild-, Video- und Audiogenerierung von xAI in einer einzigen Suite. Sie erzeugt Bilder mit bis zu 2K Auflösung und mehrsprachigem Text-Rendering sowie bis zu 15 Sekunden lange Videos mit nativem, synchronisiertem Audio und referenzbasierter Bearbeitung. Auf Atlas Cloud führt ein einziger Schlüssel jeden Grok Imagine-Modus aus, sodass Sie ohne separate Einrichtung zwischen Bild, Video und Audio wechseln können, ab 0,02 $ pro Bild und 0,05 $ pro Sekunde.
Gemini Omni Flash
Die Gemini Omni API bringt das multimodale Videogenerierungs- und Bearbeitungsmodell von Google DeepMind, vorgestellt auf der Google I/O 2026, in Ihren Stack. Gemini Omni verbindet die Reasoning-Engine von Gemini mit generativen Medien und akzeptiert beliebige Kombinationen aus Text, Bildern, Video und Audio, um konsistente, wissensbasierte Ergebnisse zu erzeugen. Verfeinern Sie die Resultate im natürlichen Dialog – tauschen Sie Objekte aus, schreiben Sie Szenen um und wechseln Sie den Stil, während Physik, Figuren und Kontinuität erhalten bleiben. Atlas Cloud stellt das komplette Gemini-Omni-Flash-Lineup bereit – Text-to-Video, Image-to-Video mit bis zu 7 Referenzbildern und Reference-to-Video – über eine einheitliche API mit transparenter sekundengenauer Abrechnung ab $0.112 und ohne Abo. Legen Sie noch heute los.
GPT Image 2
Die GPT Image 2 API bietet Entwicklern Zugang zum neuesten Bildmodell von OpenAI, dem Nachfolger von GPT Image 1.5. Es generiert und bearbeitet Bilder mit präziser Textdarstellung über lateinische und CJK-Schriften hinweg sowie mit starker Komposition für Poster, Mockups und Infografiken. Auf Atlas Cloud erreichen Sie es über eine einzige vereinheitlichte API zusammen mit über 300 Modellen, mit kostenlosen Credits, 99,99 % Verfügbarkeit und ohne erforderliche OpenAI-Organisationsverifizierung.
Die leistungsstärksten kreativen Modelle von Google sind alle auf Atlas Cloud verfügbar. Veo 3.1 liefert kinoreife Videogenerierung, Nano Banana 2 ermöglicht die Erstellung von High-Fidelity-Bildern und Gemini bringt multimodale Intelligenz in jeden Workflow. Greifen Sie über einen einzigen API key mit Day-0-Verfügbarkeit und Pay-as-you-go-Preisen auf die vollständige Google-Modellsuite zu.
Seedance 2.0 Mini
Seedance 2.0 Mini bringt die multimodale Videogenerierung von ByteDance in Workflows, bei denen Geschwindigkeit und Kosten am wichtigsten sind. Es bietet die Kernfunktionen von Seedance 2.0 bei geringerem Ressourcenverbrauch – schnellere Generierung, niedrigere Kosten pro Video und dieselbe API-Integration, die Sie bereits nutzen. Für Teams, die hochvolumige Pipelines betreiben oder Prototyping in großem Maßstab durchführen, ist Mini der praktische Standard.
ByteDance
Von der Generierung kinoreifer Videos bis zur Erstellung von High-Fidelity-Bildern sind die leistungsstärksten Modelle von ByteDance jetzt auf der Atlas Cloud verfügbar. Führen Sie Seedance und Seedream in großem Maßstab zu den niedrigsten Inferenzpreisen und ohne Infrastruktur-Overhead aus.
Alibaba
Atlas Cloud vereint das gesamte Modell-Lineup von Alibaba unter einer einzigen API: Qwen für Sprach- und Bildaufgaben sowie Wan für die Videogenerierung mit bis zu 1080p. Greifen Sie auf jedes Modell im Pay-as-you-go-Verfahren ohne Abonnements zu. Die Alibaba API ist über eine einzige Base-URL mit Ihrem bestehenden OpenAI-kompatiblen Client verfügbar.
OpenAI
Atlas Cloud bietet Ihnen Zugriff auf das gesamte Lineup der OpenAI API, von GPT Image 2 für die Bildgenerierung bis hin zu Sora 2 für Videos. Jedes Modell ist als Pay-as-you-go-Service ohne monatliche Verpflichtung verfügbar. Die Integration erfolgt durch den einfachen Austausch einer einzigen Basis-URL über die OpenAI-kompatible API.
xAI
Erstellen Sie vollständige Bild- und Videopipelines unter Verwendung der xAI API auf Atlas Cloud. Generieren Sie in 2K, bearbeiten Sie mit Referenzbildern und animieren Sie Bilder zu audiosynchronen Clips.
Kwaivgi
Die Kwaivgi API 15 % unter dem Standardpreis. Atlas Cloud bietet Day-0-Zugriff auf neue Kling-Releases mit nutzungsbasierter Preisgestaltung (Pay-as-you-go) und ohne Platzbeschränkungen. Ein Konto, ein Schlüssel, jedes Kling-Modell von der Standard- bis zur Master-Stufe.
Seedream 5.0 Pro
Die Seedream 5.0 Pro API bietet Entwicklern das steuerbare Bildbearbeitungsmodell von ByteDance auf Atlas Cloud. Sie platziert Bearbeitungen präzise mit Ankern und Koordinaten, trennt Bilder in bearbeitbare Ebenen, verschmilzt mehrere Referenzen und passt exakte Farben und Materialien an, mit mehrsprachigem Text in 2K und 3K. Auf Atlas Cloud erreichen Sie es über einen einzigen Schlüssel!


