Gemini Omni Flash API for Conversational Video Editing
Die Gemini Omni API bringt das multimodale Videogenerierungs- und Bearbeitungsmodell von Google DeepMind, vorgestellt auf der Google I/O 2026, in Ihren Stack. Gemini Omni verbindet die Reasoning-Engine von Gemini mit generativen Medien und akzeptiert beliebige Kombinationen aus Text, Bildern, Video und Audio, um konsistente, wissensbasierte Ergebnisse zu erzeugen. Verfeinern Sie die Resultate im natürlichen Dialog – tauschen Sie Objekte aus, schreiben Sie Szenen um und wechseln Sie den Stil, während Physik, Figuren und Kontinuität erhalten bleiben. Atlas Cloud stellt das komplette Gemini-Omni-Flash-Lineup bereit – Text-to-Video, Image-to-Video mit bis zu 7 Referenzbildern und Reference-to-Video – über eine einheitliche API mit transparenter sekundengenauer Abrechnung ab $0.112 und ohne Abo. Legen Sie noch heute los.
Erkunden Sie die Führenden Modelle
Atlas Cloud bietet Ihnen die neuesten branchenführenden kreativen Modelle.







Vier Möglichkeiten zur Generierung mit der Gemini Omni Flash API
Wählen Sie den für Ihre Aufgabe passenden Gemini Omni Flash API-Endpunkt, von Text-zu-Video und Bild-zu-Video bis hin zu referenzgesteuerter Generierung und konversationeller Bearbeitung.
| Modalität | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | Sie haben nur einen Text-Prompt? Die Gemini Omni Flash Text-to-Video API verwandelt diesen in einem einzigen Durchgang in einen 720p-Clip mit synchronisierter Audiowiedergabe und folgt dabei einer durch logisches Denken gesteuerten Regie für Szene, Bewegung und Kamera für Clips von bis zu 10 Sekunden Länge. |
| Gemini Omni Flash Image-to-Video API (I2V) | Die Gemini Omni Flash Image-to-Video API animiert ein statisches Bild in Bewegung und verankert die Quelle als Startframe. Mit natürlichen Bewegungen und synchronisiertem Audio erweckt sie Produktaufnahmen, Porträts und Konzepte in 720p zum Leben. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Steuern Sie eine Generierung mit bis zu sieben Referenzbildern und drei kurzen Videoclips mithilfe der Gemini Omni Flash Reference-to-Video API. Sie sorgt für durchgehende Konsistenz von Charakteren, Stil und Szene im gesamten Clip und ist ideal für Marken- und Serieninhalte. |
| Gemini Omni Flash Video Edit API | Wenn ein Clip geändert werden muss, wendet die Gemini Omni Flash Video Edit API Anweisungen in natürlicher Sprache über eine zustandsbehaftete Interactions API an. Sie tauscht Elemente aus, passt die Beleuchtung an und gestaltet Szenen neu, während der Rest des Filmmaterials über mehrere Interaktionsrunden hinweg intakt bleibt. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
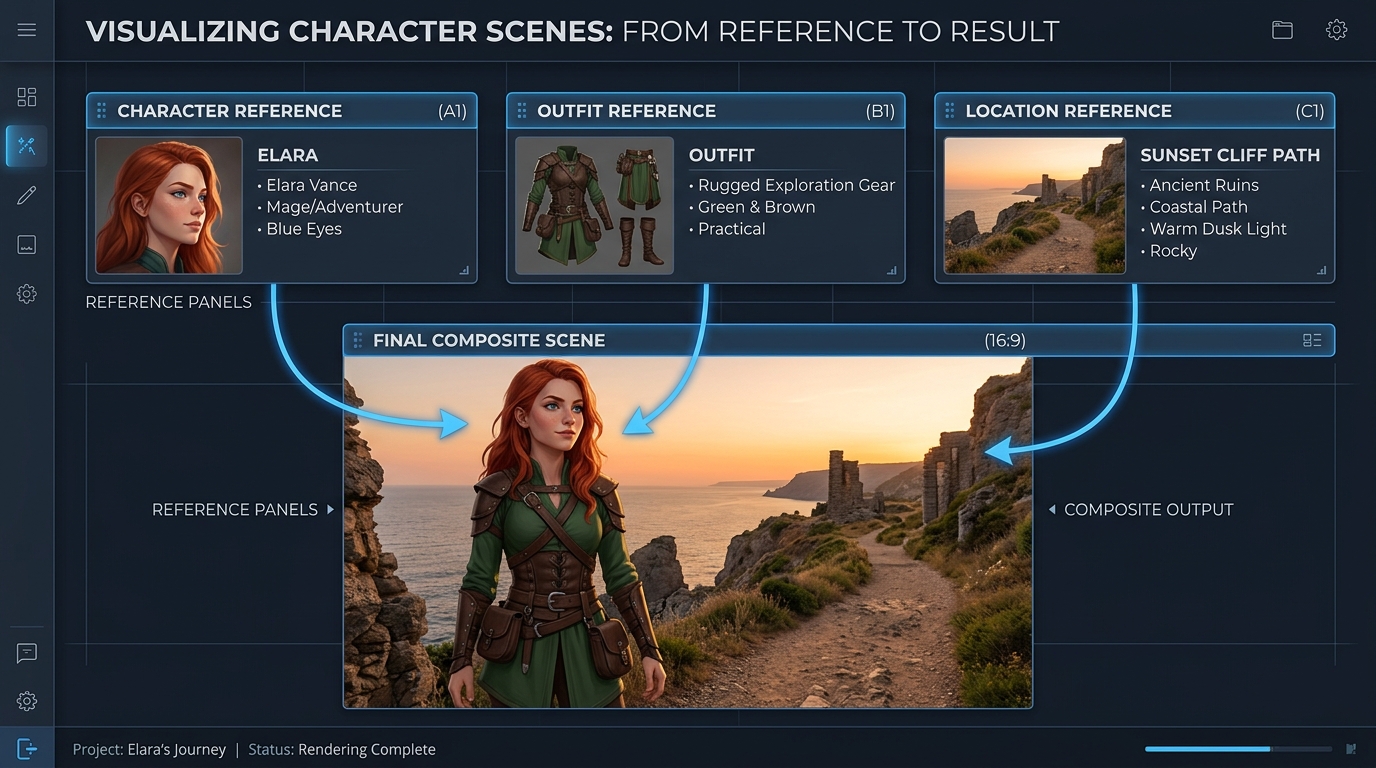
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Wie die Gemini Omni Flash API im Vergleich abschneidet
Sehen Sie, wie sich Modelle verschiedener Anbieter vergleichen — Leistung, Preise und einzigartige Stärken für eine fundierte Entscheidung.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | Bearbeitung fertiger Videos durch Konversation | Yes | Ja, zustandsbehaftet | Text, Bild, Video, Audio |
| Veo 3.1 | Cinematische Clips mit Szenenerweiterung | Yes | No | Text, Bild, Referenz |
| Seedance 2.0 | Referenzgesteuertes Video in Spitzenqualität | Yes | No | Text, Bild, Video, Audio |
| Kling 3.0 | Multi-Shot-Storytelling durch KI-Regie | Yes | No | Text, Bild, Referenz |
So verwenden Sie Gemini Omni Flash auf Atlas Cloud
In wenigen Minuten startklar — folgen Sie diesen einfachen Schritten, um Modelle über die Plattform von Atlas Cloud zu integrieren und bereitzustellen.
Atlas Cloud-Konto erstellen
Registrieren Sie sich auf atlascloud.ai und schließen Sie die Verifizierung ab. Neue Nutzer erhalten kostenlose Credits zum Erkunden der Plattform und Testen von Modellen.
Warum Gemini Omni Flash auf Atlas Cloud Verwenden
Die Kombination der fortschrittlichen Gemini Omni Flash-Modelle mit der GPU-beschleunigten Plattform von Atlas Cloud bietet unübertroffene Leistung, Skalierbarkeit und Entwicklererfahrung.
Leistung & Flexibilität
Niedrige Latenz:
GPU-optimierte Inferenz für Echtzeit-Reasoning.
Einheitliche API:
Führen Sie Gemini Omni Flash, GPT, Gemini und DeepSeek mit einer Integration aus.
Transparente Preisgestaltung:
Vorhersehbare Token-basierte Abrechnung mit serverlosen Optionen.
Unternehmen & Skalierung
Entwicklererfahrung:
SDKs, Analysen, Fine-Tuning-Tools und Vorlagen.
Zuverlässigkeit:
99,99% Verfügbarkeit, RBAC und compliance-bereite Protokollierung.
Sicherheit & Compliance:
SOC 2 Type II, HIPAA-Ausrichtung, Datensouveränität in den USA.
FAQ zu Google Gemini Omni Flash API
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
Weitere Familien Erkunden
Seedance 2.0
Die Seedance 2.0 API bietet Ihnen Produktionszugriff auf das multimodale Videomodell von ByteDance – quadmodale Eingaben (Text, Bild, Video, Audio) und ein branchenführendes „Universal Reference“-System, das Bildkomposition, Kamerabewegungen und Charakteraktionen über verschiedene Einstellungen hinweg fixiert. Integrieren Sie Kontrolle auf Regisseur-Niveau mit nur einem API-Aufruf, einem Pauschalpreis von 0,09 $/s, sofortigem Key und ohne Warteliste – unterstützt durch branchenübliche Verfügbarkeit und Compliance für Unternehmen. Seedance 2.0 Native 4K ist ab sofort live!
Grok Imagine
Die Grok Imagine API bietet Entwicklern die Bild-, Video- und Audiogenerierung von xAI in einer einzigen Suite. Sie erzeugt Bilder mit bis zu 2K Auflösung und mehrsprachigem Text-Rendering sowie bis zu 15 Sekunden lange Videos mit nativem, synchronisiertem Audio und referenzbasierter Bearbeitung. Auf Atlas Cloud führt ein einziger Schlüssel jeden Grok Imagine-Modus aus, sodass Sie ohne separate Einrichtung zwischen Bild, Video und Audio wechseln können, ab 0,02 $ pro Bild und 0,05 $ pro Sekunde.
Gemini Omni Flash
Die Gemini Omni API bringt das multimodale Videogenerierungs- und Bearbeitungsmodell von Google DeepMind, vorgestellt auf der Google I/O 2026, in Ihren Stack. Gemini Omni verbindet die Reasoning-Engine von Gemini mit generativen Medien und akzeptiert beliebige Kombinationen aus Text, Bildern, Video und Audio, um konsistente, wissensbasierte Ergebnisse zu erzeugen. Verfeinern Sie die Resultate im natürlichen Dialog – tauschen Sie Objekte aus, schreiben Sie Szenen um und wechseln Sie den Stil, während Physik, Figuren und Kontinuität erhalten bleiben. Atlas Cloud stellt das komplette Gemini-Omni-Flash-Lineup bereit – Text-to-Video, Image-to-Video mit bis zu 7 Referenzbildern und Reference-to-Video – über eine einheitliche API mit transparenter sekundengenauer Abrechnung ab $0.112 und ohne Abo. Legen Sie noch heute los.
GPT Image 2
Die GPT Image 2 API bietet Entwicklern Zugang zum neuesten Bildmodell von OpenAI, dem Nachfolger von GPT Image 1.5. Es generiert und bearbeitet Bilder mit präziser Textdarstellung über lateinische und CJK-Schriften hinweg sowie mit starker Komposition für Poster, Mockups und Infografiken. Auf Atlas Cloud erreichen Sie es über eine einzige vereinheitlichte API zusammen mit über 300 Modellen, mit kostenlosen Credits, 99,99 % Verfügbarkeit und ohne erforderliche OpenAI-Organisationsverifizierung.
Die leistungsstärksten kreativen Modelle von Google sind alle auf Atlas Cloud verfügbar. Veo 3.1 liefert kinoreife Videogenerierung, Nano Banana 2 ermöglicht die Erstellung von High-Fidelity-Bildern und Gemini bringt multimodale Intelligenz in jeden Workflow. Greifen Sie über einen einzigen API key mit Day-0-Verfügbarkeit und Pay-as-you-go-Preisen auf die vollständige Google-Modellsuite zu.
Seedance 2.0 Mini
Seedance 2.0 Mini bringt die multimodale Videogenerierung von ByteDance in Workflows, bei denen Geschwindigkeit und Kosten am wichtigsten sind. Es bietet die Kernfunktionen von Seedance 2.0 bei geringerem Ressourcenverbrauch – schnellere Generierung, niedrigere Kosten pro Video und dieselbe API-Integration, die Sie bereits nutzen. Für Teams, die hochvolumige Pipelines betreiben oder Prototyping in großem Maßstab durchführen, ist Mini der praktische Standard.
ByteDance
Von der Generierung kinoreifer Videos bis zur Erstellung von High-Fidelity-Bildern sind die leistungsstärksten Modelle von ByteDance jetzt auf der Atlas Cloud verfügbar. Führen Sie Seedance und Seedream in großem Maßstab zu den niedrigsten Inferenzpreisen und ohne Infrastruktur-Overhead aus.
Alibaba
Atlas Cloud vereint das gesamte Modell-Lineup von Alibaba unter einer einzigen API: Qwen für Sprach- und Bildaufgaben sowie Wan für die Videogenerierung mit bis zu 1080p. Greifen Sie auf jedes Modell im Pay-as-you-go-Verfahren ohne Abonnements zu. Die Alibaba API ist über eine einzige Base-URL mit Ihrem bestehenden OpenAI-kompatiblen Client verfügbar.
OpenAI
Atlas Cloud bietet Ihnen Zugriff auf das gesamte Lineup der OpenAI API, von GPT Image 2 für die Bildgenerierung bis hin zu Sora 2 für Videos. Jedes Modell ist als Pay-as-you-go-Service ohne monatliche Verpflichtung verfügbar. Die Integration erfolgt durch den einfachen Austausch einer einzigen Basis-URL über die OpenAI-kompatible API.
xAI
Erstellen Sie vollständige Bild- und Videopipelines unter Verwendung der xAI API auf Atlas Cloud. Generieren Sie in 2K, bearbeiten Sie mit Referenzbildern und animieren Sie Bilder zu audiosynchronen Clips.
Kwaivgi
Die Kwaivgi API 15 % unter dem Standardpreis. Atlas Cloud bietet Day-0-Zugriff auf neue Kling-Releases mit nutzungsbasierter Preisgestaltung (Pay-as-you-go) und ohne Platzbeschränkungen. Ein Konto, ein Schlüssel, jedes Kling-Modell von der Standard- bis zur Master-Stufe.
Seedream 5.0 Pro
Die Seedream 5.0 Pro API bietet Entwicklern das steuerbare Bildbearbeitungsmodell von ByteDance auf Atlas Cloud. Sie platziert Bearbeitungen präzise mit Ankern und Koordinaten, trennt Bilder in bearbeitbare Ebenen, verschmilzt mehrere Referenzen und passt exakte Farben und Materialien an, mit mehrsprachigem Text in 2K und 3K. Auf Atlas Cloud erreichen Sie es über einen einzigen Schlüssel!


