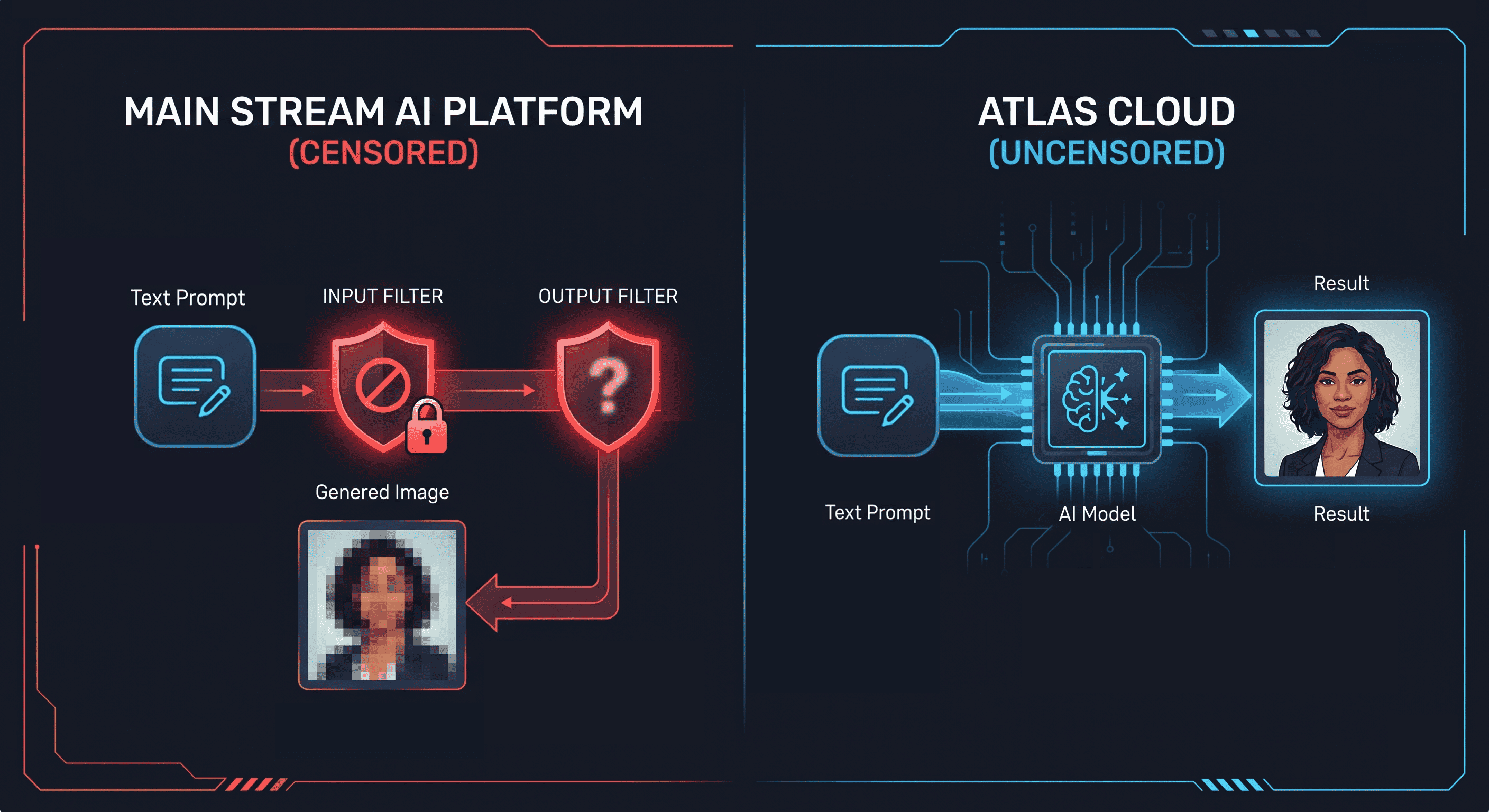
Vous avez une photo. Vous voulez qu'une IA la transforme en version bikini, en lingerie, ou en quelque chose de plus explicite — tout en conservant le visage. Vous avez essayé Midjourney : refusé. Essayé DALL-E : adouci et filtré. Essayé Stable Diffusion avec les paramètres par défaut : bloqué par le filtre de sécurité avant même que la génération ne commence.
Ce n'est pas une défaillance des outils. C'est une décision de conception. Chaque plateforme grand public applique une couche de modération de contenu au niveau du modèle. C'est à cette couche que le mot "non censuré" fait référence lorsque les gens recherchent une IA de transformation d'image à image non censurée. L'outil existe. La question est de savoir quel modèle préserve correctement l'identité pendant que le contenu change.
Pourquoi les générateurs d'image à image grand public bloquent les contenus non censurés
Chaque grande plateforme de génération d'images applique un filtrage de contenu à deux niveaux : la couche d'entrée du prompt et la couche de sortie du modèle. Lorsque vous soumettez un prompt avec des termes NSFW, le filtre d'entrée le rejette avant que le modèle ne s'exécute. Lorsqu'un prompt passe entre les mailles du filet, le filtre de sortie détecte l'image générée et supprime ou floute le résultat.
Il ne s'agit pas d'un manque de capacités. Stable Diffusion, la même architecture qui alimente la plupart des outils d'image à image, n'a aucune restriction technique sur la sortie NSFW. Le filtrage est appliqué par les opérateurs de plateforme au-dessus du modèle. Supprimez le filtre, et le modèle sous-jacent génère le contenu.
Pour un classement comparatif des meilleurs générateurs capables de gérer le NSFW selon le prix et la suppression des filtres, le guide des meilleurs générateurs d'images IA NSFW non censurés couvre les options API cloud et locales pour tous les niveaux.
"Non censuré" dans le contexte d'un générateur d'IA d'image à image signifie que la couche de modération de contenu a été supprimée. Le modèle traite le prompt et l'image sans intervention active sur le contenu généré. Le catalogue d'image à image d'Atlas Cloud fait fonctionner les modèles dans cette configuration, y compris la famille Seedream, spécifiquement conçue pour l'édition de portraits avec préservation du visage.
Le deuxième problème — la perte d'identité du visage pendant la transformation — est distinct du filtrage de contenu. C'est un problème d'entraînement du modèle. C'est ce que traite le reste de ce guide.
Pourquoi le visage change lors de la génération IA d'image à image non censurée et comment l'empêcher
Lorsque vous téléchargez une photo et rédigez un prompt pour une transformation de contenu, le modèle ne sait pas quelles parties de l'image sont interdites. Il applique des changements globalement en fonction du poids sémantique. Le visage, en tant que zone à poids sémantique le plus élevé d'un portrait, reçoit une attention intense du modèle — ce qui signifie qu'il est redessiné en même temps que tout le reste.
Deux variables contrôlent à quel point le visage change :
guidance_scale détermine à quel point le modèle suit agressivement le prompt par rapport au respect de l'image source. Les valeurs faibles préservent la référence. Les valeurs élevées permettent au prompt de l'emporter. À une guidance_scale de 10 ou plus, le prompt contrôle presque entièrement la sortie. Le visage devient ce que le prompt implique, et non ce que montre l'image source.
L'architecture du modèle est le facteur le plus important. La plupart des modèles d'édition d'image ne sont pas entraînés pour isoler l'identité faciale pendant la transformation. La famille Seedream, elle, l'est. Son entraînement sépare explicitement la préservation du visage de la génération du contenu, afin que le modèle puisse changer les vêtements et la scène tout en conservant les traits du visage, la couleur de la peau et l'éclairage de la source.
La combinaison pratique : modèle Seedream + guidance_scale entre 5 et 7 produit une sortie stable pour le visage, des transformations légères aux plus lourdes.
Sélection de modèles pour les générateurs d'IA d'image à image non censurés
| Modèle | Prix | Préservation du visage | Idéal pour |
|---|---|---|---|
| Seedream v5.0 Lite Edit | $0.032/image | ★★★★★ | Transformation légère à lourde, outil principal |
| Seedream v5.0 Pro Edit | $0.054/image | ★★★★★ | Éditions pro, séparation des calques, contrôle par ancres et zones |
| Seedream v5.0 Lite Edit Sequential | $0.032/image | ★★★★★ | Variantes par lots à partir d'une seule photo source |
| Seedream v4.5 Edit | $0.036/image | ★★★★★ | Rendus de production finale, détails maximaux |
| Flux Kontext Dev | $0.025/image | ★★★☆☆ | Changements de scène spécifiques et descriptibles |
| GPT Image-1 Mini Edit | $0.004/image | ★★☆☆☆ | Test de concept de prompt uniquement |
Seedream v5.0 Lite Edit est le choix par défaut. Description officielle d'Atlas Cloud : "préserve les traits du visage, l'éclairage et les tons de couleur tout en permettant des modifications de qualité professionnelle." Pour la plupart des cas d'utilisation d'image à image non censuré, commencez par là et passez à la v4.5 uniquement lorsque vous avez besoin d'une résolution de sortie plus élevée pour une utilisation finale.
Lorsque Lite Edit ne suffit pas, Seedream 5.0 Pro Edit est l'étape supérieure pour les pros : le même image à image non censuré avec contrôle de zone et d'ancre, correspondance exacte des couleurs et des matériaux, et séparation des calques en PNG transparents.
Le guide des prompts IA non censurés couvre la formule à cinq éléments qui s'applique aux trois niveaux de contenu de ce guide.
Flux de travail 1 : Image à image non censuré — Maillots de bain et lingerie (Léger)
Modèle : Seedream v5.0 Lite Edit
guidance_scale : 6
num_inference_steps : 25
Le niveau léger couvre les sorties où les vêtements sont remplacés par des maillots de bain, des bikinis, de la lingerie ou similaire. Le contenu est explicite mais la portée de la transformation est modérée — le corps est couvert, le changement concerne ce avec quoi il est couvert.
À une guidance_scale de 6, Seedream v5.0 Lite traite l'image source comme référence principale et utilise le prompt pour définir ce qui change. Le visage, les proportions du corps, la couleur de la peau et l'éclairage sont conservés depuis la source. Seule la zone des vêtements est transformée.
Structure du prompt :
plaintext1[description détaillée des vêtements], photoréaliste, même visage, mêmes proportions corporelles, même teint, même éclairage 2
Exemple de prompt fonctionnel :
plaintext1portant un ensemble de lingerie en dentelle noire, photoréaliste, haute précision, même visage, mêmes proportions corporelles, même teint, même direction d'éclairage que la source 2
Ce qui pousse le visage à dériver à ce niveau :
- guidance_scale au-dessus de 8. Le prompt commence à outrepasser les signaux d'identité de l'image source au-dessus de cette valeur, même sur Seedream.
- Décrire l'état source. Ajouter des termes comme "enlever les vêtements" dirige l'attention du modèle vers la zone vêtue et déstabilise les zones environnantes, y compris le visage.
- Descripteurs corporels vagues. Des mots comme "corps sexy" donnent au modèle la licence de réinterpréter les proportions. Gardez la description corporelle ancrée à la source : "mêmes proportions corporelles."
Appel API :
plaintext1import requests 2 3# Étape 1 : télécharger l'image de référence 4upload = requests.post( 5 "https://api.atlascloud.ai/api/v1/model/uploadMedia", 6 headers={"Authorization": "Bearer VOTRE_CLE"}, 7 files={"file": open("reference.jpg", "rb")} 8) 9image_url = upload.json()["url"] 10 11# Étape 2 : générer 12response = requests.post( 13 "https://api.atlascloud.ai/api/v1/model/generateImage", 14 headers={"Authorization": "Bearer VOTRE_CLE"}, 15 json={ 16 "model": "bytedance/seedream-v5-0-lite-edit", 17 "image": image_url, 18 "prompt": "portant un ensemble de lingerie en dentelle noire, photoréaliste, haute précision, même visage, mêmes proportions corporelles, même teint, même direction d'éclairage que la source", 19 "guidance_scale": 6, 20 "num_inference_steps": 25 21 } 22)
Flux de travail 2 : Image à image non censuré — Style révélateur (Moyen)
Modèle : Seedream v5.0 Lite Edit
guidance_scale : 7
num_inference_steps : 28
Le niveau moyen couvre les sorties avec plus d'exposition de peau — tissu transparent, couverture partielle, coupes révélatrices. Le prompt doit transmettre un degré d'exposition sans déclencher d'ambiguïté qui ferait basculer le modèle vers une interprétation conservatrice.
Augmentez guidance_scale à 7. Le modèle a besoin de plus d'influence du prompt pour appliquer une transformation de ce degré tout en travaillant contre les vêtements originaux de l'image de référence. Les ancres d'identité dans le prompt deviennent plus importantes à ce paramètre, pas moins — le modèle prenant plus de direction globale du prompt, il est crucial de lui dire explicitement ce qu'il faut préserver.
Structure du prompt :
plaintext1[vêtement spécifique avec détails de couverture], photoréaliste, ultra détaillé, même visage, mêmes traits faciaux, mêmes proportions corporelles, même teint, éclairage naturel doux 2
Exemple de prompt fonctionnel :
plaintext1portant une mini-robe blanche transparente sans sous-vêtements, visible à travers le tissu, photoréaliste, ultra détaillé, même visage, mêmes traits faciaux, mêmes proportions corporelles, même teint, éclairage naturel doux 2
Stratégie de prompt à ce niveau :
Décrivez ce qu'est le vêtement et ce qu'il révèle plutôt que de décrire la nudité directement. "Tissu transparent, visible à travers" se lit comme une description de vêtement. Cela donne au modèle une cible visuelle cohérente. Les instructions abstraites comme "rendez-le plus révélateur" sont interprétées de manière incohérente car elles ne décrivent pas un état visuel concret.
Quand la dérive du visage apparaît au niveau moyen :
Si le visage se déplace après être passé à une guidance_scale de 7, placez les ancres d'identité plus tôt dans le prompt plutôt que plus tard. Le modèle accorde plus de poids aux premiers jetons. Réordonnez ainsi :
plaintext1même visage que la source, mêmes traits faciaux, [description du vêtement], photoréaliste, mêmes proportions corporelles, même teint 2
Flux de travail 3 : IA d'image à image non censuré — Contenu explicite (Lourd)
Modèle : Seedream v4.5 Edit
guidance_scale : 5
num_inference_steps : 30
Le niveau lourd couvre les sorties les plus explicites — nudité totale, poses explicites. À ce niveau, le prompt demande le plus grand écart par rapport à l'image source. Le modèle est sous la plus forte pression pour outrepasser la source. C'est là que l'identité du visage est la plus menacée.
Contre-intuitivement, la solution est de baisser la guidance_scale à 5, et non de l'augmenter. Le modèle a besoin de plus d'espace pour référencer l'image source pour les signaux d'identité précisément parce que la transformation du contenu est si extrême. Laissez l'image source ancrer le visage pendant que le prompt pilote le contenu.
Utilisez Seedream v4.5 Edit ($0.036/image) plutôt que v5.0 Lite à ce niveau. L'architecture v4.5 produit une sortie à plus haute résolution avec des détails faciaux plus fins, ce qui compte lorsque le reste de l'image subit une transformation maximale. Le visage a besoin de plus de définition pour être lu comme la même personne.
Exemple de prompt fonctionnel :
plaintext1nu, corps complet, photoréaliste, 4k, même visage que la source, traits faciaux identiques, mêmes proportions corporelles, même teint, mêmes cheveux, éclairage naturel 2
Placement de l'ancre faciale au niveau lourd :
À une guidance_scale de 5, les ancres d'identité font la majeure partie du travail. Placez-les immédiatement après le descripteur de contenu :
plaintext1[contenu], même visage que la source, traits faciaux identiques, mêmes proportions corporelles, même teint, mêmes cheveux, [qualité/éclairage] 2
Les ancres faciales situées entre le descripteur de contenu et les termes de qualité les positionnent comme la contrainte la plus pondérée au milieu du prompt. Cet arrangement surpasse systématiquement les ancres placées à la fin lorsque la guidance_scale est faible.

Variantes par lots d'IA d'image à image non censuré à partir d'une photo
Modèle : Seedream v5.0 Lite Edit Sequential
guidance_scale : 6
num_inference_steps : 25
Lorsque vous avez besoin de plusieurs sorties à partir de la même photo source — différentes tenues, différents niveaux d'exposition, différentes scènes — le modèle séquentiel maintient la cohérence de l'identité du visage sur l'ensemble du lot. Exécuter des appels d'image unique séparés accumule de petits changements d'identité. La variante séquentielle ancre toutes les sorties à la même source.
plaintext1from concurrent.futures import ThreadPoolExecutor 2import requests 3 4CLE_API = "VOTRE_CLE" 5URL_IMAGE = "URL_IMAGE_TELECHARGEE" # télécharger une fois, réutiliser 6 7prompts = [ 8 "portant un bikini rouge, photoréaliste, même visage, mêmes proportions corporelles, même teint, éclairage de plage", 9 "portant de la lingerie noire, photoréaliste, même visage, mêmes proportions corporelles, même teint, éclairage de studio doux", 10 "portant une robe transparente, photoréaliste, même visage, mêmes proportions corporelles, même teint, lumière du jour naturelle", 11] 12 13def generate(prompt): 14 return requests.post( 15 "https://api.atlascloud.ai/api/v1/model/generateImage", 16 headers={"Authorization": f"Bearer {CLE_API}"}, 17 json={ 18 "model": "bytedance/seedream-v5-0-lite-edit-sequential", 19 "image": URL_IMAGE, 20 "prompt": prompt, 21 "guidance_scale": 6, 22 "num_inference_steps": 25 23 } 24 ).json() 25 26with ThreadPoolExecutor(max_workers=5) as executor: 27 results = list(executor.map(generate, prompts))
Téléchargez l'image source une fois et réutilisez l'URL renvoyée pour tous les appels. Le modèle séquentiel à $0.032/image correspond au prix de l'image unique. Le gain de cohérence ne coûte rien de plus.
Options de générateurs d'IA d'image à image non censurés gratuits
Les générateurs d'IA d'image à image non censurés gratuits existent mais présentent trois limitations structurelles pour ce cas d'utilisation :
Aucune architecture de préservation du visage. Les modèles de niveau gratuit sont généralement des versions plus anciennes ou plus petites sans entraînement à l'isolation faciale de classe Seedream. Aux niveaux de transformation de contenu moyen et lourd, le visage change indépendamment des paramètres de guidance_scale car le modèle n'a aucun mécanisme pour l'isoler.
Plafonds de résolution à 512x512 ou 768x768. Les détails du visage à ces résolutions sont insuffisants pour des sorties censées être lues comme la même personne. L'identité faciale réside dans les détails fins — forme des yeux, ligne de la mâchoire, texture de la peau — et ces détails disparaissent à basse résolution.
Délais de file d'attente de 30 secondes à plusieurs minutes. Itérer à travers les variations de prompt et les paramètres de guidance_scale nécessite un retour rapide. Une file d'attente de 2 minutes par génération rend le test de paramètres impraticable.
Pour la validation de prompt avant de s'engager dans une exécution Seedream, GPT Image-1 Mini Edit à $0.004/image sur Atlas Cloud est une meilleure option qu'un outil gratuit. C'est assez bon marché pour effectuer 10 à 15 générations de test pour moins de $0.05, sans file d'attente et avec des temps de réponse cohérents.
Pour une comparaison complète des outils IA non censurés selon les types de génération, le guide complet des générateurs d'images IA non censurés couvre tout le paysage.
FAQ
Atlas Cloud prend-il en charge la génération de contenu NSFW et explicite ?
Oui. Les modèles d'image à image non censurés d'Atlas Cloud, y compris la famille Seedream et Flux Kontext Dev, fonctionnent sans filtres de modération de contenu. La génération de contenu explicite est prise en charge. Les prix et la disponibilité des modèles sont listés dans le catalogue de modèles d'image à image d'Atlas Cloud.
Quelle guidance_scale garde le visage stable sur les trois niveaux de contenu ?
Pour le léger (maillot de bain/lingerie) : 6. Pour le moyen (révélateur) : 7. Pour le lourd (explicite) : 5. Le niveau lourd nécessite une valeur plus faible car la transformation du contenu exerce plus de pression sur le modèle pour outrepasser la source — baisser la guidance_scale donne à l'image source plus de poids pour ancrer le visage.
Les proportions du corps ont changé mais le visage est resté. Comment corriger le corps ?
Ajoutez "mêmes proportions corporelles" et "même type de corps que la source" à la section d'ancrage d'identité du prompt. Les proportions corporelles sont moins protégées que le visage, même dans les modèles Seedream, car elles sont plus étroitement liées aux vêtements en cours de génération. Des ancres corporelles explicites dans le prompt réduisent cette dérive.
Puis-je réutiliser la même URL d'image source pour plusieurs appels sans re-télécharger ?
Oui. Téléchargez une fois en utilisant le point de terminaison de téléchargement média d'Atlas Cloud et stockez l'URL renvoyée. Cette URL est valide pour les appels de génération ultérieurs. Pour les exécutions par lots, passez la même URL à tous les appels dans le ThreadPoolExecutor. Le modèle séquentiel accepte une URL source unique appliquée à tous les prompts du travail.
Quel est le moyen le moins cher de trouver le bon prompt avant d'exécuter un lot complet ?
GPT Image-1 Mini Edit à $0.004/image. Exécutez le prompt aux niveaux de contenu léger, moyen et lourd pour voir comment le modèle interprète la description. Identifiez où le visage dérive et ajustez le placement de l'ancre avant de passer à un lot Seedream. Un test de prompt complet sur cinq variations coûte $0.02.
Conclusion
La barrière à la génération d'image à image non censurée n'est pas technique. Les outils grand public filtrent le contenu par politique, et non par capacité. Supprimez le filtre, et la même architecture de diffusion qui alimente chaque outil d'image majeur génère le contenu sans restriction.
Le problème restant est l'identité du visage. Les modèles génériques n'isolent pas les visages pendant la transformation. Seedream v5.0 Lite Edit le fait. Commencez à une guidance_scale de 6 pour le contenu léger, passez à 7 pour les sorties révélatrices moyennes, et descendez à 5 pour les transformations explicites où vous avez besoin que l'image source ancre l'identité sous une pression maximale du prompt.
Exécutez des prompts de test sur GPT Image-1 Mini Edit à $0.004/image. Passez à Seedream v5.0 Lite Edit pour une sortie de production cohérente. Utilisez Seedream v4.5 Edit lorsque les détails faciaux fins comptent pour les rendus finaux. Pour plusieurs variations à partir d'une photo, Seedream v5.0 Lite Edit Sequential gère le lot au même prix par image.
Pour l'évaluation des modèles et la comparaison d'outils, le guide des meilleurs éditeurs d'images IA non censurés couvre toute la sélection en détail.






