Résumé : GLM-5-Turbo, développé par Zhipu AI (Z.ai), est un modèle de langage étendu conçu pour les cas d'utilisation OpenClaw et constitue la première version propriétaire de l'entreprise (précédemment testée sous le nom de code Pony-Alpha-2). Son lancement sur Atlas Cloud est imminent.
Le modèle offre des améliorations significatives en matière d'utilisation d'outils, d'exécution d'instructions, de flux de travail multi-étapes et de gestion de tâches à long terme, tout en prenant en charge une fenêtre de contexte allant jusqu'à 200 000 jetons. Ses capacités d'analyse de données sont comparables à celles de Claude Opus 4.6, et il surpasse GLM-5 dans les tâches d'automatisation et de traitement de l'information. En tirant parti de l'API unifiée et de l'écosystème multi-modèles d'Atlas Cloud, GLM-5-Turbo permet un déploiement efficace dans les domaines de l'automatisation commerciale complexe, de l'analyse de documents longs et du développement logiciel, offrant une solution IA rentable et facilement intégrable pour les développeurs et les entreprises.
Nous sommes ravis d'annoncer que GLM-5-Turbo arrive sur Atlas Cloud !
- Qu'est-ce que GLM-5-Turbo : Développé par Zhipu AI (Z.ai), GLM-5-Turbo est un modèle de langage étendu conçu pour les cas d'utilisation OpenClaw. Il s'agit de la première version propriétaire de l'équipe, offrant une meilleure efficacité d'exécution que GLM-5 à un coût par appel réduit. Auparavant, Zhipu AI avait testé son modèle de nouvelle génération sous le nom de code Pony-Alpha-2.
- Fonctionnalités principales : GLM-5-Turbo apporte des améliorations substantielles en matière d'utilisation d'outils, de suivi des instructions, de flux de travail multi-étapes et d'exécution persistante des tâches. Il prend en charge des modes de raisonnement dynamiques adaptés à divers scénarios, une sortie en streaming en temps réel, une intégration renforcée des outils et une gestion de contexte long jusqu'à 200 000 jetons.
- Date de lancement : 24/03/2026.
GLM-5 avait précédemment attiré l'attention en tant que modèle open-source le plus performant sur l'Artificial Analysis Intelligence Index, surpassant Gemini 3 Pro. En tant que successeur, GLM-5-Turbo introduit une série d'améliorations itératives, détaillées ci-dessous.
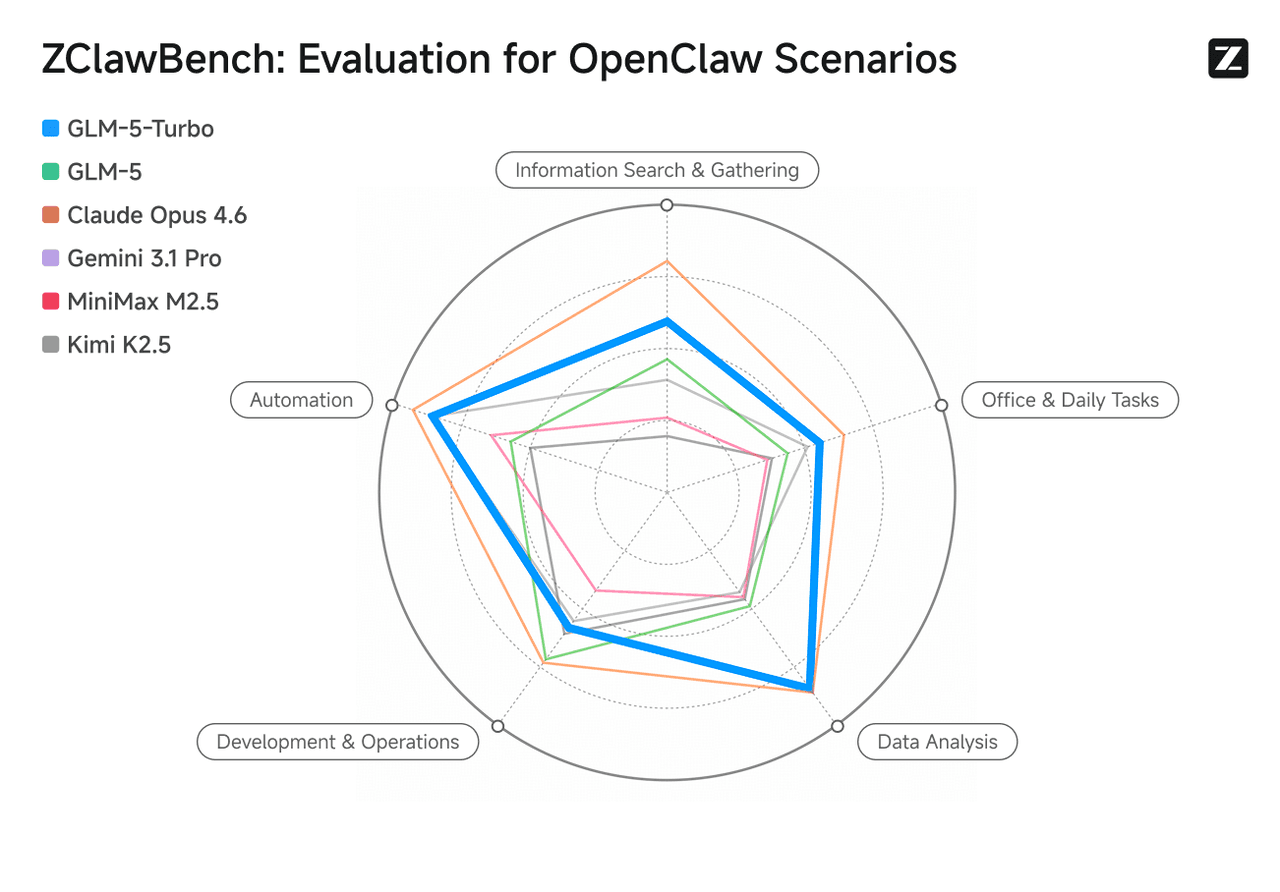
Positionnement clé : Un modèle optimisé pour ClawBench
Performances de référence solides
Optimisé pour les scénarios OpenClaw, GLM-5-Turbo améliore considérablement les capacités en matière d'appel d'outils, d'exécution d'instructions et d'orchestration de tâches complexes. Ses performances en analyse de données sont à égalité avec Claude Opus 4.6, tout en surpassant GLM-5 dans l'automatisation, la recherche d'informations, la productivité bureautique et les tâches analytiques.
Source de l'image : Site officiel de Zhipu AI (Z.ai).
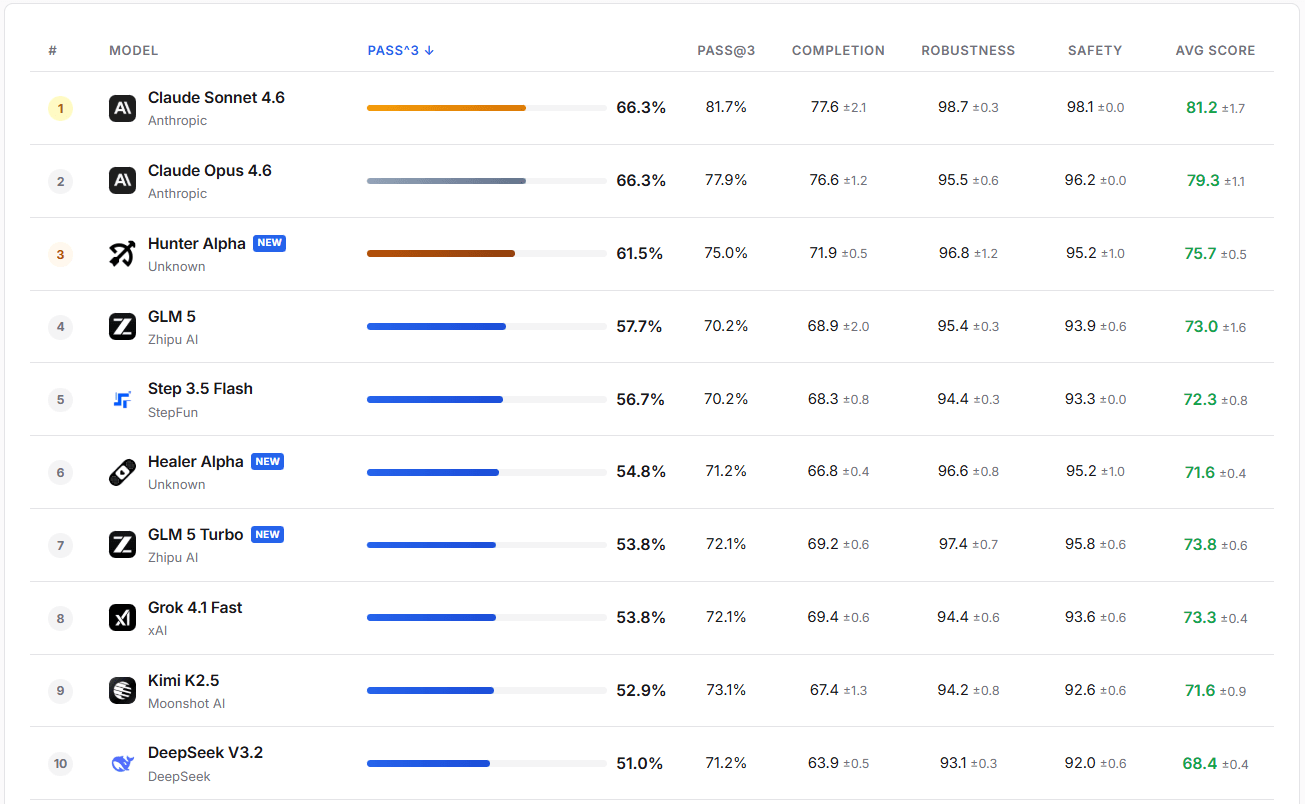
Dans les évaluations pratiques, GLM-5-Turbo fait preuve d'une grande robustesse et sécurité. Son taux de réussite PASS@3 dépasse celui de GLM-5, Step 3.5 Flash et Kimi K2.5.
Source de l'image : https://claw-eval.github.io/
Utilisation améliorée des outils et intégration externe
Z.ai a renforcé les capacités agentiques de GLM-5-Turbo au cours de l'entraînement, permettant une interaction fluide avec des outils externes. Cette orientation axée sur l'exécution comporte des compromis : certains utilisateurs signalent un ton légèrement plus mécanique par rapport à GLM-5 dans les scénarios de jeu de rôle.
Pour s'adapter aux forces de chaque modèle, Atlas Cloud fournit une interface unifiée qui permet aux utilisateurs d'interroger plusieurs modèles simultanément, facilitant ainsi la comparaison et la sélection.
De plus, les utilisateurs peuvent définir des compétences personnalisées ou permettre à GLM-5-Turbo de les découvrir et de les installer de manière autonome.
Source de l'image : Atlas Cloud

Exécution autonome à long terme
GLM-5-Turbo est optimisé pour les tâches nécessitant des déclenchements programmés ou des temps d'exécution étendus. Il gère des flux de travail persistants, multi-étapes et transversaux avec une forte continuité des tâches.
Le modèle suggère de manière proactive des stratégies d'exécution basées sur la complexité de la tâche. Dans des tests comparatifs sur l'optimisation du code, GLM-5-Turbo a produit des recommandations qui ont surpassé les modèles concurrents dans environ 10 % des cas.
Fenêtre de contexte de 200 000 jetons
Prenant en charge jusqu'à 200 000 jetons (environ 133 000 mots en anglais), GLM-5-Turbo peut conserver et utiliser un contexte étendu au cours d'une seule session. Cela permet une récupération précise des informations antérieures, même à des stades avancés de la conversation.
Source de l'image : Jim Allen Wallace (Redis)
Cas d'utilisation
Automatisation de flux de travail complexes
Grâce à ses capacités OpenClaw améliorées, GLM-5-Turbo peut décomposer des processus métier complexes, identifier la logique sous-jacente et localiser ou générer de manière autonome les compétences nécessaires à l'exécution des tâches.
Par exemple, dans la production de vidéos courtes, le modèle peut rechercher, installer et orchestrer des outils d'écriture, de génération d'images et de production vidéo, planifiant et exécutant l'intégralité du flux de travail de bout en bout.
Questions-réponses sur documents longs et analyse approfondie
Le modèle conserve tout le contexte sur de longs documents au sein d'une seule session, permettant des réponses précises aux questions multi-tours. Sa grande efficacité en matière de jetons garantit des réponses rapides avec un coût de calcul inférieur.
Sur des bases de code à grande échelle, GLM-5-Turbo peut analyser la conception architecturale, cartographier les dépendances entre les composants et signaler les effets en cascade potentiels résultant de changements de code de bas niveau.
« Vibe Coding »
Dans le cycle de vie du développement logiciel, GLM-5-Turbo fonctionne davantage comme un ingénieur full-stack intégré dans des flux de travail complexes. Les développeurs peuvent définir la logique de haut niveau tandis que le modèle construit progressivement l'architecture de l'application en temps réel.
Combiné avec des compétences multimodales, les utilisateurs peuvent télécharger des images d'interface utilisateur, des enregistrements d'écran ou des croquis, que le modèle peut directement convertir en composants frontend fonctionnels.
Pourquoi utiliser GLM-5-Turbo sur Atlas Cloud ?
En tant que plateforme d'infrastructure IA tout-en-un, Atlas Cloud fournit aux utilisateurs une interface API unifiée. Une fois connectés, les utilisateurs peuvent facilement débloquer plus de 300 modèles d'IA avancés, incluant la génération de texte, d'images, de vidéo ou des modèles multimodaux.
Public cible
- Développeurs indépendants cherchant des solutions simplifiées et à faible coût pour appeler divers modèles d'IA.
- Entreprises ayant besoin d'une infrastructure stable, sécurisée et évolutive pour soutenir leur cœur de métier.
- Équipes de développement ayant besoin d'intégrer efficacement plusieurs modèles cross-modaux dans leurs projets.
- Utilisateurs de flux de travail qui privilégient la compatibilité des chaînes d'outils et utilisent ComfyUI ou n8n.
Caractéristiques du produit
- Intégration grandement simplifiée : La plateforme fournit une API compatible avec OpenAI, simplifiant instantanément la charge de travail du développeur. Plus besoin de jongler avec plusieurs clés de fournisseurs ou de se soucier des coûts de maintenance entre les plateformes.
- Avantage coût : Par rapport à ses concurrents, Atlas Cloud offre des coûts de déploiement inférieurs. Nano Banana 2 coûte $0.056/image (concurrent : $0.07/image) ; Veo 3.1 est tarifé à $0.09/seconde (concurrent : $0.1/seconde). De plus, l'interface Playground offre une transparence totale des prix, le bouton « Exécuter » indiquant directement le montant de la déduction par image ou par seconde de vidéo.
- Stabilité et support de niveau entreprise : Atlas Cloud garantit que la protection des données répond à des normes de confidentialité strictes et peut traiter des informations sensibles.
- Prêt à l'emploi (Plug-and-Play) : Conçu pour fonctionner sans effort avec des outils comme ComfyUI et n8n, aidant les entreprises à réduire les coûts de transition et à être opérationnelles rapidement.
Comparaison avec des produits similaires
- Fal.ai : Bien qu'ils proposent certains modèles, Atlas Cloud offre une sélection plus large (300+), des prix plus compétitifs, et les nouveaux utilisateurs enregistrés reçoivent un crédit d'essai de $1.
- Wavespeed : La tarification est nettement plus élevée. Atlas Cloud offre un support de conformité d'entreprise supplémentaire et des conseils techniques d'experts que Wavespeed ne met pas en avant.
- Kie.ai : Utilise un système de crédit opaque. Atlas Cloud affiche le coût exact pour chaque exécution directement sur l'interface. Le nombre de modèles est également plus élevé que chez Kie.ai.
- Replicate : Se concentre sur l'hébergement de modèles. Les avantages d'Atlas Cloud résident dans l'unification de l'API, la rapidité de déploiement des modèles et des politiques de support plus adaptées aux développeurs.
- OpenAI ou Google : Ces fournisseurs ne proposent que leurs propres modèles. Les utilisateurs ayant des besoins cross-modaux doivent généralement intégrer plusieurs services. Atlas Cloud intègre des modèles propriétaires et open-source sous une seule API, réduisant la complexité du système.
Comment utiliser GLM-5-Turbo sur Atlas Cloud ?
Méthode 1 : Utilisation directe sur la plateforme
Méthode 2 : Utilisation via intégration API
Étape 1 : Obtenez votre clé API. Créez et collez votre clé API dans la console :


Étape 2 : Consultez la documentation de l'API. Vérifiez les paramètres de requête, les méthodes d'authentification, etc.
Étape 3 : Faites votre première requête (Exemple en Python)
GLM-5 à titre d'exemple.
plaintext1{ 2 "model": "zai-org/glm-5", 3 "messages": [ 4 { 5 "role": "user", 6 "content": "Hello" 7 } 8 ], 9 "max_tokens": 1024, 10 "temperature": 0.7, 11 "stream": false 12}
FAQ
Quelle est la différence entre GLM-5-Turbo et GLM-5** ?** GLM-5-Turbo est plus rapide et plus rentable, avec une efficacité de jetons considérablement améliorée — jusqu'à trois fois celle de GLM-5. Il est également spécifiquement optimisé pour les scénarios OpenClaw.
Comment GLM-5-Turbo se compare-t-il à MiniMax M2.7** ?** Les deux modèles sont optimisés pour l'utilisation d'outils agentiques et bénéficient d'une efficacité de jetons supérieure à celle de GLM-5. Chacun prend en charge des fenêtres de contexte d'environ 200 000 jetons (MiniMax M2.7 prend en charge 196 608 jetons). Nous préparons un article de blog pour une évaluation comparative plus approfondie. Restez à l'écoute !
Quel modèle GLM est recommandé pour le déploiement OpenClaw ? GLM-5-Turbo, car il est spécifiquement optimisé pour les scénarios OpenClaw et atteint des performances en analyse de données comparables à Claude Opus 4.6.






