
ChatGPT API for Frontier GPT 5.6 Reasoning
L’API ChatGPT sur Atlas Cloud réunit la toute nouvelle famille GPT 5.6 d’OpenAI dans une seule intégration, couvrant Sol pour le raisonnement frontier approfondi, Terra pour les charges de travail de production ancrées, et Luna pour la conversation naturelle et la génération de contenu. Acheminez chaque modèle via une clé unique compatible OpenAI, bénéficiez d’une disponibilité de niveau production et profitez de tarifs transparents à l’usage, à partir de 1 $ par million de tokens d’entrée. Commencez à développer dès aujourd’hui.
Explorez les Modèles Leaders
Atlas Cloud vous offre les derniers modèles créatifs de pointe de l'industrie.
Choisir le bon modèle d’API ChatGPT : comparaison de tous les endpoints
Cinq endpoints de génération de texte, du raisonnement de pointe à la conversation économique, tous accessibles avec une seule clé compatible OpenAI et une tarification transparente à l’usage.
| Modalité | Description |
|---|---|
| GPT 5.6 Sol API (Text to Text) | Conçu pour les charges de travail d’IA de pointe, GPT 5.6 Sol transforme des prompts textuels complexes en sorties de raisonnement approfondies et multi-étapes pour résoudre des problèmes ambitieux. La tarification standard est de 5 $ par million de tokens d’entrée et de 30 $ par million de tokens de sortie, ce qui en fait le choix phare lorsque la qualité des réponses prime sur le coût. |
| GPT 5.6 Terra API (Text to Text) | Besoin d’un choix par défaut fiable pour la production ? GPT 5.6 Terra convertit les prompts en textes ancrés et pratiques pour les workflows réels et les pipelines d’analyse, à 2,50 $ par million de tokens d’entrée et 15 $ par million de tokens de sortie. Les équipes le déploient dans des applications destinées aux clients, lorsque la cohérence compte davantage que la profondeur expérimentale. |
| GPT 5.6 Luna API (Text to Text) | Orientez le trafic conversationnel et créatif vers GPT 5.6 Luna, un modèle de texte optimisé pour le dialogue naturel, la génération de contenu et les expériences d’IA personnalisées. À 1 $ par million de tokens d’entrée et 6 $ par million de tokens de sortie, c’est le point d’entrée le plus économique de cette gamme d’API ChatGPT, parfaitement adapté aux produits de chat et à la génération de textes à grand volume. |
| GPT 5.4 API (Text to Text) | GPT 5.4 transforme des instructions textuelles en code fiable, en contenus longs et en sorties structurées de résolution de problèmes, avec une grande précision. Conçu comme un modèle multimodal avancé, il se situe sur une tarification intermédiaire de 2,50 $ par million de tokens d’entrée et 15 $ par million de tokens de sortie, un choix pratique pour les assistants de codage et les plateformes de contenu. |
| GPT 5.5 API (Text to Text) | Lorsque des problèmes difficiles justifient un budget premium, GPT 5.5 fournit du raisonnement avancé, du codage et de la génération de contenu depuis un endpoint texte unique. Tarifé à 5 $ par million de tokens d’entrée et 30 $ par million de tokens de sortie, il cible les charges de travail complexes et critiques en matière de fiabilité, comme l’orchestration d’agents et l’analyse technique. |
L’API ChatGPT : niveaux GPT 5.x et poids ouverts
Accédez à toute la gamme GPT 5.x et au modèle à poids ouverts GPT OSS 120B via une seule API ChatGPT, ajustez l’effort de raisonnement de low à xhigh, combinez texte, images et fichiers dans un seul appel, et invoquez des outils natifs avec recherche web en direct à partir d’une clé compatible OpenAI.
Texte, images et fichiers dans un seul appel à l’API ChatGPT
Une seule requête à l’API ChatGPT peut combiner du texte brut, des URL d’images et des fichiers de documents dans un même message. Cela évite les services OCR ou de vision séparés : vous pouvez résumer des contrats scannés ou lire des captures d’écran en une seule passe.
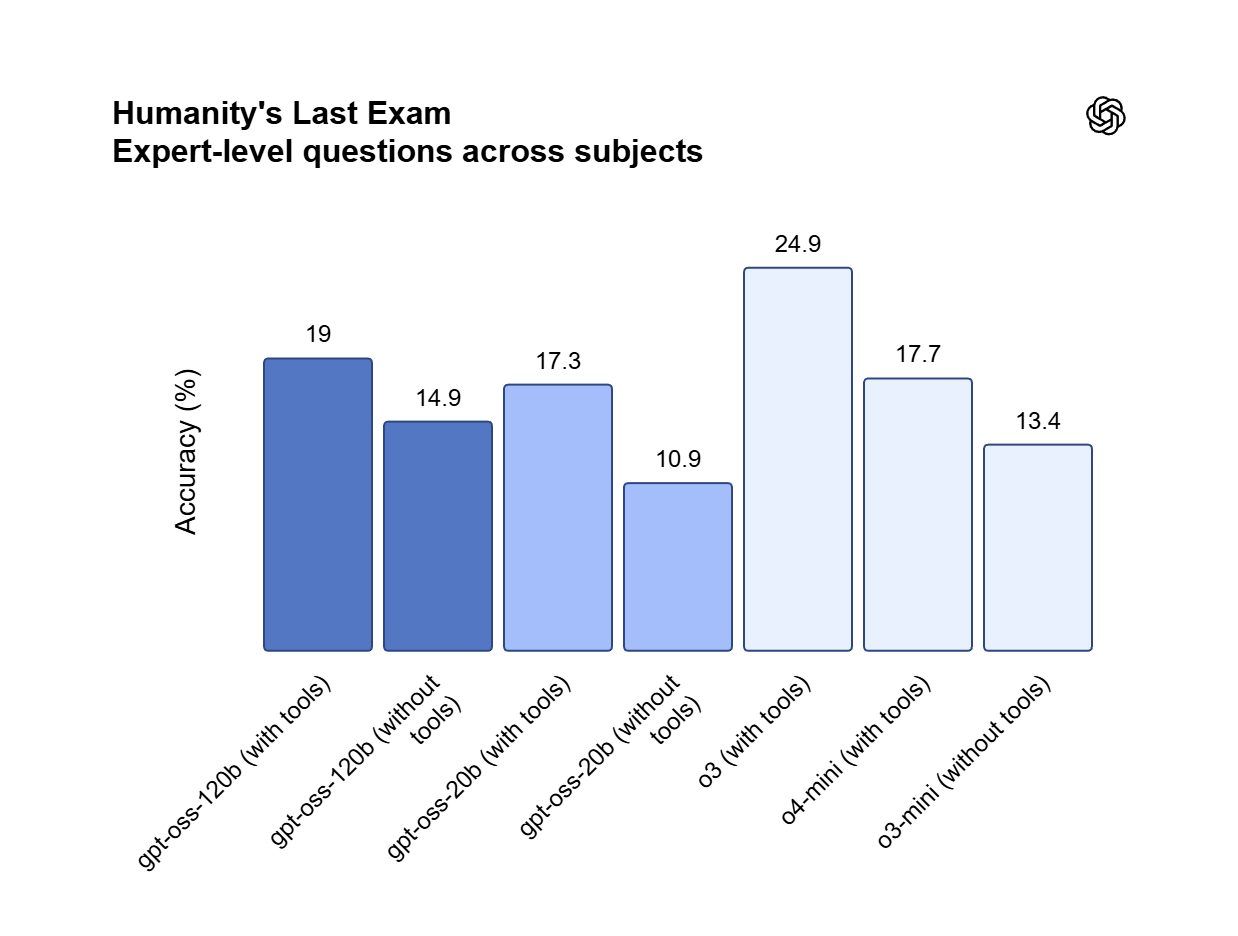
Fidélité aux instructions sur l’API ChatGPT
GPT OSS 120B respecte les prompts système en couches, en maintenant des formats, des contraintes et un ton stables dans les sorties, sans dérive. Cette fiabilité convient aux agents autonomes, à l’extraction structurée et aux pipelines de production où la sortie doit suivre les règles.
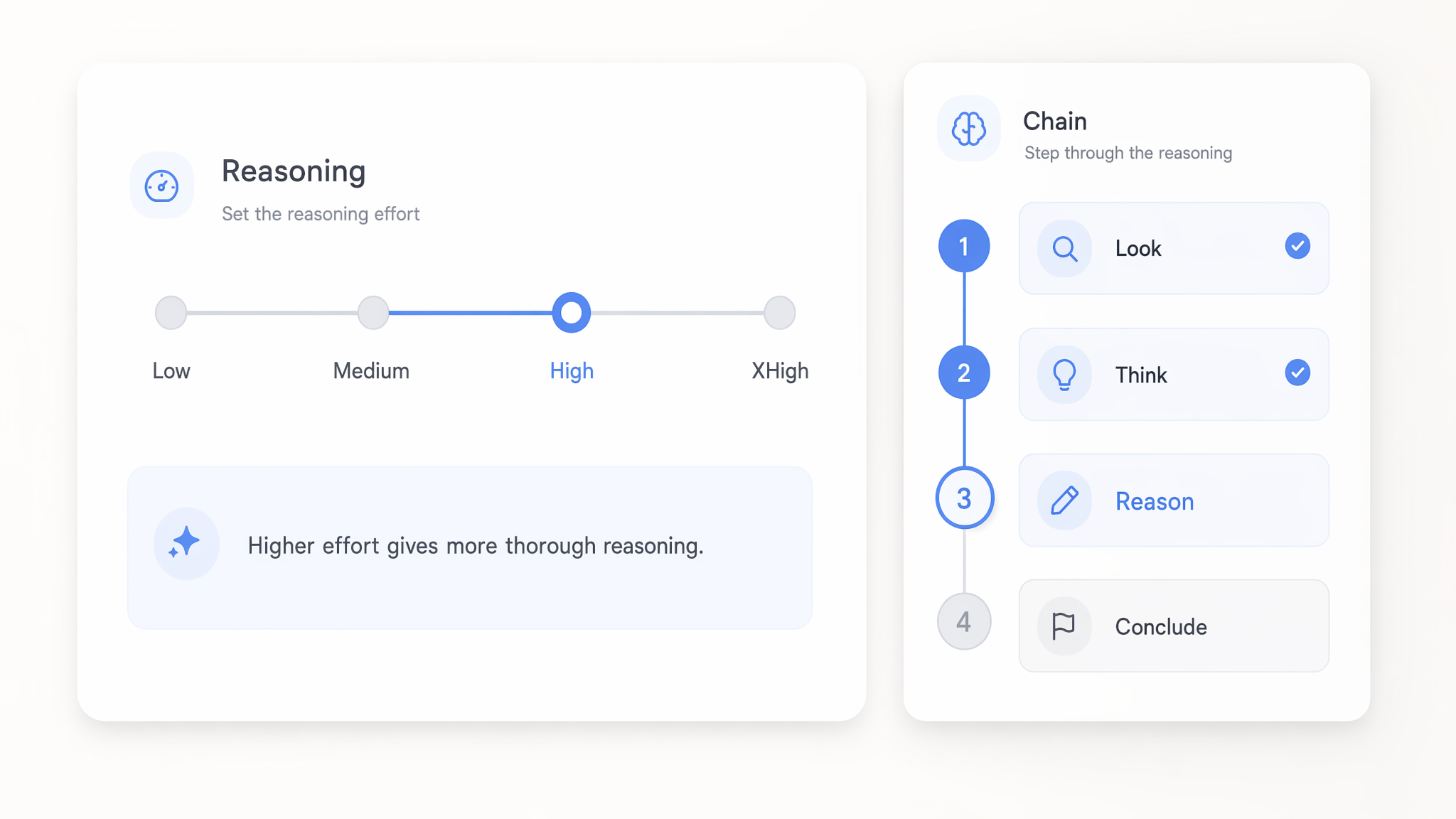
Réglez l’effort de raisonnement de low à xHigh
Définissez l’effort de raisonnement des modèles GPT 5.x de low jusqu’à xhigh afin de contrôler la profondeur de réflexion avant la réponse. Les réglages low répondent aux appels simples rapidement et à moindre coût, tandis que xhigh consacre davantage de calcul aux raisonnements complexes en plusieurs étapes.
Des poids Apache 2.0 qui vous appartiennent pleinement
Distribué sous licence Apache 2.0, GPT OSS 120B autorise l’usage commercial et le fine-tuning privé sur un seul GPU 80GB. Hébergez-le on-premises pour conserver les données propriétaires en interne et éviter totalement les frais par token.

Cinq niveaux GPT, une seule API ChatGPT
Une seule API ChatGPT donne accès à toute la gamme GPT 5.x, avec des prix allant de Luna à 1 $ à Sol à 5 $ par million de tokens d’entrée. Associez chaque appel au niveau correspondant à ses besoins de coût et d’intelligence, sans changer d’endpoint.
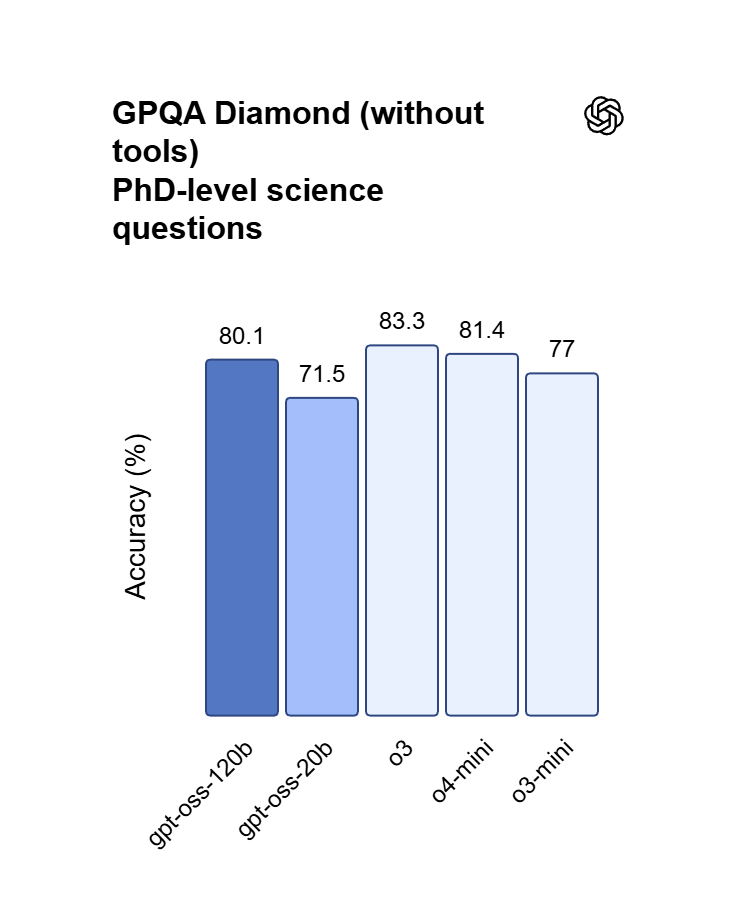
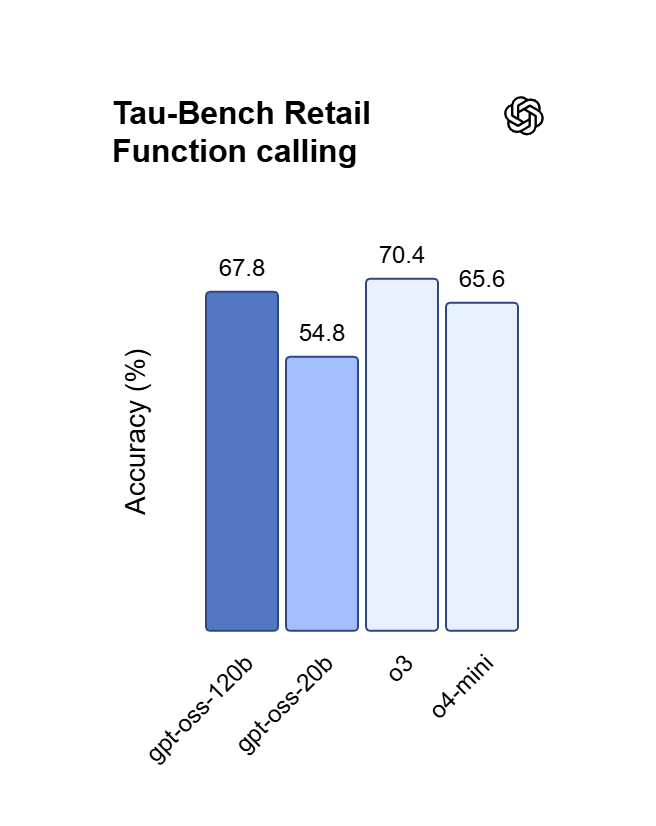
Un raisonnement optimisé pour le vibecoding
Avec des performances proches d’OpenAI o4-mini, GPT OSS 120B prend en charge la synthèse de code en plusieurs étapes et les preuves mathématiques. Transformez des idées en langage naturel en applications web fonctionnelles, déboguez une logique imbriquée et orchestrez des flux complexes de planification de tâches.

Appels de fonctions avec recherche web en direct
Les modèles GPT 5.x prennent en charge les appels de fonctions avec sélection automatique des outils, ainsi qu’une recherche web intégrée qui récupère des résultats à jour. Diffusez les réponses sous forme de server-sent events, tandis que la mise en cache des prompts ramène l’entrée mise en cache de GPT 5.6 Sol à 0,5 $ par million de tokens.
Une seule consigne, trois concurrents : duel via l’API ChatGPT
Nous avons transmis exactement la même instruction de développement à des modèles via l’API ChatGPT et à deux fleurons concurrents, puis nous avons rendu chaque réponse HTML brute sans modification afin que vous puissiez comparer côte à côte la profondeur du raisonnement, la qualité du code et le sens du design.
Crée un fichier HTML unique et autonome (CSS et JavaScript inline uniquement — absolument aucune bibliothèque externe, CDN, framework, police ou URL d’image) qui s’ouvre directement dans n’importe quel navigateur moderne et exécute un simulateur d’écosystème de serre en verre vivant et auto-croissant, rendu entièrement sous forme d’illustration vectorielle plate en Canvas/SVG. La scène en plein écran est une serre victorienne à dôme : une coupole de verre incurvée traverse le haut comme élément de cadrage, avec des panneaux dessinés en polygones translucides vert jade, de doux reflets spéculaires et de fines baguettes de vitrage, tandis qu’une bande de terre de culture sombre longe le bas. La direction artistique est une illustration vectorielle épurée — feuilles et tiges dessinées avec des nervures nettes et des aplats semi-transparents superposés, une palette ancrée dans le vert sauge brumeux et le brun mousse, avec une lumière ambrée et des accents de verre jade ; pas de photoréalisme, pas de dégradés utilisés comme textures, garder un rendu graphique avec une sensation d’illustration à la main. Interaction principale : cliquer n’importe où sur la terre plante une graine à cet endroit, et la plante pousse en temps réel à l’aide d’un véritable L-system — implémente une grammaire de réécriture récursive (axiome plus règles de production avec crochets de branchement et variations aléatoires d’angle/de longueur par instance afin qu’aucune plante ne soit identique) et anime la dérivation pour que les branches s’allongent, bifurquent et déploient leurs feuilles progressivement sur quelques secondes au lieu d’apparaître entièrement formées. Les fougères tropicales et les lianes grimpantes doivent se courber et s’enrouler par phototropisme vers un soleil déplaçable : affiche un disque solaire ambré lumineux que l’utilisateur peut saisir et faire glisser n’importe où dans le ciel, et chaque pointe en croissance doit réorienter continuellement sa direction de croissance vers la position actuelle du soleil afin que déplacer le soleil infléchisse visiblement l’inclinaison et l’ascension de tout le jardin. Les jeunes pousses se déploient avec une animation d’easing, et des gouttelettes de condensation se forment sur le verre puis glissent lentement vers le bas en boucle. Pilote l’ensemble avec un cycle jour-nuit lié à la position du soleil : la lumière ambiante et le voile du ciel évoluent en douceur le long d’un dégradé allant de l’or chaud au bleu frais, la position du soleil définit la direction et la longueur des ombres douces des plantes projetées au sol ainsi que des taches de lumière flottant sur le verre, et au crépuscule des lucioles apparaissent progressivement sous forme de petits points lumineux pulsants dérivant parmi le feuillage. La composition fait rayonner la croissance des plantes depuis la base vers le centre, contenue par l’arc du dôme. Utilise requestAnimationFrame pour une boucle d’animation continue, calme et respirante ; conserve des performances fluides avec de nombreuses plantes affichées simultanément. Inclue des contrôles subtils et discrets (par exemple un slider ou un interrupteur d’avance automatique pour l’heure de la journée, ainsi qu’un bouton de réinitialisation/effacement) stylisés pour correspondre à l’esthétique illustrée, plus une indication en une ligne disant à l’utilisateur de cliquer sur la terre pour planter et de faire glisser le soleil pour guider la croissance. Rends le tout responsive à toutes les tailles de fenêtre, avec une tonalité émotionnelle calme, immobile et vivante — les premiers rayons du matin entrant en biais tandis que de tendres pousses s’ouvrent ensemble. Il s’agit d’une simulation générative, pas d’un jeu ni d’un dashboard : privilégie le véritable algorithme de croissance récursive, la boucle d’animation et la physique de la lumière/des ombres/du phototropisme.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Crée une page HTML complète en un seul fichier contenant un dashboard interactif de financement mondial des startups, avec des données fictives mais cohérentes en interne pour 8 secteurs industriels sur 5 ans. Tout le CSS et le JavaScript doivent être inline, sans aucune dépendance externe, sans bibliothèques de graphiques, sans CDN et sans images. Rends trois visualisations codées à la main en canvas ou SVG : un graphique en barres animé qui se retrie avec easing lorsque l’utilisateur choisit une année via un slider, un graphique en lignes avec tooltips au survol affichant les valeurs exactes et un guide de suivi vertical, ainsi qu’un graphique en donut dont les segments s’agrandissent au survol avec une animation à ressort. Inclue une UI moderne sombre avec une palette d’accents violet-vers-turquoise, des compteurs numériques animés dans quatre cartes KPI, une rangée de filtres par secteur sous forme de chips activables qui met instantanément à jour tous les graphiques, et un commutateur de thème clair/sombre avec des transitions de couleur fluides. La mise en page doit être responsive, se replier en une seule colonne sous 768px, et chaque interaction doit répondre en temps réel sans rechargement de page.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
Tous les workloads que la ChatGPT API peut alimenter
Du codage agentique et de l’extraction structurée au chat d’assistance ancré et au contenu à grand volume, la ChatGPT API sur Atlas Cloud achemine chaque tâche vers le bon niveau GPT 5.6 via une clé compatible OpenAI.

Lancez des outils de codage agentique avec la ChatGPT API
Acheminez les refactorisations complexes et la synthèse de code multi-fichiers vers GPT 5.6 Sol, le niveau de raisonnement approfondi de la famille, conçu pour les workloads d’ingénierie de pointe. Les équipes qui créent des copilotes de codage, des bots de revue automatisée et des générateurs de tests bénéficient d’une logique prête pour la production.

Génération de contenu à grande échelle, fidèle à votre marque
GPT 5.6 Luna, le niveau créatif de la famille, rédige des articles de blog, des descriptions de produits et des contenus localisés avec un ton naturel et des sorties personnalisées. Les équipes contenu et les plateformes ecommerce produisent de grands volumes de textes sans sacrifier la voix de marque.

Alimentez des assistants de support avec la ChatGPT API
Besoin d’un chatbot qui respecte le script ? GPT 5.6 Terra fournit des réponses fiables et ancrées, conçues pour les conversations en production, afin que les équipes de support et les produits SaaS puissent automatiser les tickets et détourner efficacement les demandes répétitives.

Systèmes de connaissances augmentés par la récupération
Injectez des manuels de politiques complets ou des archives de recherche dans un modèle à long contexte et obtenez des réponses ancrées avec fidélité aux sources. Les équipes juridiques, médicales et de recherche interne disposent d’un moteur fiable pour les réponses aux questions augmentées par la récupération.

Extraction de données structurées via la ChatGPT API
Les factures, emails et PDF désordonnés sont convertis en JSON propre auquel les systèmes en aval peuvent faire confiance. Le suivi fiable des instructions préserve l’intégrité des schémas, au service des pipelines de données, de l’automatisation CRM et des workflows d’analytics qui ne peuvent tolérer aucune dérive.

Associez chaque tâche au bon niveau de modèle
Lorsque le budget et la latence comptent, basculez entre Sol, Terra et Luna via une seule clé compatible OpenAI. Les startups et les développeurs indépendants prototypent rapidement avec une tarification à l’usage, puis font évoluer la même intégration vers la production.
| Modèle | Contexte | Sortie max. | Entrée | Positionnement |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Texte | LLM de raisonnement à haute efficacité |
| GLM-5 | 202.75K | 202.75K | Texte | Modèle fondation phare |
| DeepSeek V3.2 | 163.84K | 163.84K | Texte | Modèle généraliste phare |
| MiniMax-M2.5 | 204.8K | 196.6K | Texte | Codage agentique SOTA |
Comment utiliser ChatGPT sur Atlas Cloud
Soyez opérationnel en quelques minutes — suivez ces étapes simples pour intégrer et déployer des modèles via la plateforme Atlas Cloud.
Créer un compte Atlas Cloud
Inscrivez-vous sur atlascloud.ai et complétez la vérification. Les nouveaux utilisateurs reçoivent des crédits gratuits pour explorer la plateforme et tester les modèles.
Pourquoi Utiliser ChatGPT sur Atlas Cloud
Combiner les modèles ChatGPT avancés avec la plateforme accélérée par GPU d'Atlas Cloud offre des performances, une évolutivité et une expérience développeur inégalées.
Performance et Flexibilité
Faible Latence :
Inférence optimisée par GPU pour un raisonnement en temps réel.
API Unifiée :
Exécutez ChatGPT, GPT, Gemini et DeepSeek avec une seule intégration.
Tarification Transparente :
Facturation prévisible par token avec options serverless.
Entreprise et Échelle
Expérience Développeur :
SDK, analytiques, outils de fine-tuning et modèles.
Fiabilité :
99,99% de disponibilité, RBAC et journalisation conforme.
Sécurité et Conformité :
SOC 2 Type II, alignement HIPAA, souveraineté des données aux États-Unis.
ChatGPT API : réponses aux questions des développeurs
La ChatGPT API permet aux développeurs d’envoyer des prompts aux modèles GPT d’OpenAI et de recevoir des complétions par programmation, plutôt que via l’interface de chat. Sur Atlas Cloud, vous accédez à toute la gamme GPT 5.6, ainsi qu’à GPT 5.4 et GPT 5.5, via un endpoint unique compatible avec OpenAI. Chaque appel est facturé au token avec une tarification transparente à l’usage : vous ne payez donc que ce que vous générez.
Cinq modèles couvrent tout l’éventail, du raisonnement approfondi au chat quotidien. GPT 5.6 Sol cible la résolution de problèmes ambitieuse et les charges de travail de pointe, GPT 5.6 Terra prend en charge les workflows de production fiables, et GPT 5.6 Luna est optimisé pour la conversation naturelle et la génération de contenu. GPT 5.4 et GPT 5.5 ajoutent le raisonnement multimodal et le codage pour les équipes qui recherchent des performances polyvalentes éprouvées.
Générez une clé API, définissez votre URL de base sur https://api.atlascloud.ai/v1, puis indiquez l’ID du modèle, par exemple openai/gpt-5.6-terra. Comme la ChatGPT API proposée ici est entièrement compatible avec OpenAI, le code existant basé sur les SDK OpenAI fonctionne après un simple changement d’URL de base et de clé. Il n’y a ni liste d’attente ni abonnement, et les nouvelles versions sont disponibles avec un accès Day-0 : vous pouvez donc envoyer votre première requête le jour même.
La tarification varie selon le modèle choisi. GPT 5.6 Luna est le plus économique, à $1 par million de tokens en entrée et $6 par million de tokens en sortie ; GPT 5.6 Terra coûte $2.5 et $15 ; GPT 5.6 Sol est à $5 et $30. La mise en cache des prompts réduit le coût des entrées répétées, et la facturation reste à l’usage : seuls les tokens que vous utilisez vous sont facturés.
Oui. L’endpoint suit le format OpenAI Chat Completions : les SDK OpenAI officiels, LangChain et la plupart des bibliothèques compatibles avec OpenAI fonctionnent dès que vous remplacez l’URL de base et la clé. Cela signifie qu’une intégration ChatGPT API existante peut être migrée sans réécrire votre logique de requête.
Le streaming et l’appel de fonctions fonctionnent exactement comme dans l’implémentation d’OpenAI : définissez stream sur true pour obtenir une sortie token par token et transmettez un tableau tools pour déclencher des appels de fonctions. Les réponses JSON structurées suivent le même format de requête compatible avec OpenAI, ce qui rend l’orchestration d’agents et les pipelines d’extraction de données prévisibles.
Ces modèles acceptent de grands prompts pour les workflows sur documents longs et dépôts complets. La tarification est échelonnée au seuil de 272,000 tokens, avec un tarif standard pour les prompts en dessous de ce seuil et un second tarif pour ceux qui dépassent 272,000 tokens. Vous pouvez donc fournir un contexte étendu dans une seule requête et savoir précisément comment le tarif évolue à mesure que le prompt grandit.
Faites correspondre le modèle à la tâche. Optez pour GPT 5.6 Sol lorsque vous avez besoin d’un raisonnement de pointe et d’une résolution de problèmes ambitieuse, choisissez GPT 5.6 Terra pour des analyses solides et prêtes pour la production, et utilisez GPT 5.6 Luna pour les usages conversationnels ou créatifs où le coût est prioritaire. GPT 5.4 et GPT 5.5 restent de solides options multimodales pour le codage et le raisonnement général.
Atlas Cloud exécute la ChatGPT API sur une infrastructure managée qui s’adapte à votre trafic, ce qui vous évite le provisionnement de GPU et l’orchestration de nœuds liés à l’auto-hébergement. Les nouvelles versions de modèles arrivent avec un accès Day-0, vous permettant de rester à jour sans travail de migration. Si vos besoins augmentent, la même clé compatible avec OpenAI couvre tous les modèles de la famille : passer à l’échelle ne signifie donc jamais créer une nouvelle intégration.
Explorer Plus de Familles
Seedance 2.0
L'API Seedance 2.0 vous donne un accès en production au modèle vidéo multimodal de ByteDance — des entrées quadrimodales (texte, image, vidéo, audio) et un système « Universal Reference » leader du secteur qui verrouille la composition, les mouvements de caméra et les actions des personnages à travers les plans. Intégrez un contrôle de niveau réalisateur avec un seul appel d'API, un tarif fixe de 0,09 $/s, une clé instantanée et aucune liste d'attente — le tout soutenu par une disponibilité et une conformité de niveau entreprise. Seedance 2.0 Native 4K est désormais disponible !
Grok Imagine
La Grok Imagine API offre aux développeurs la génération d'images, de vidéos et d'audio de xAI dans une seule suite. Elle produit des images jusqu'à 2K avec un rendu de texte multilingue, ainsi que des vidéos allant jusqu'à 15 secondes avec un audio natif synchronisé et une édition basée sur des références. Sur Atlas Cloud, une seule clé exécute chaque mode Grok Imagine, ce qui vous permet de passer d'une image, d'une vidéo et d'un audio à l'autre sans configuration distincte, à partir de 0,02 $ par image et 0,05 $ par seconde.
Gemini Omni Flash
La Gemini Omni API apporte à votre stack le modèle multimodal de génération et d'édition vidéo de Google DeepMind, présenté à Google I/O 2026. Gemini Omni fusionne le moteur de raisonnement de Gemini avec les médias génératifs : il accepte n'importe quelle combinaison de texte, d'images, de vidéo et d'audio pour produire des résultats cohérents et ancrés dans la connaissance. Affinez vos résultats par simple conversation — remplacez des objets, réécrivez des scènes, changez de style — tandis que la physique, les personnages et la continuité restent intacts. Atlas Cloud propose toute la gamme Gemini Omni Flash — texte vers vidéo, image vers vidéo avec jusqu'à 7 images de référence, et référence vers vidéo — via une API unifiée, avec une tarification transparente à la seconde à partir de $0.112 et sans abonnement. Commencez à développer dès aujourd'hui.
GPT Image 2
L'API GPT Image 2 offre aux développeurs un accès au dernier modèle d'image d'OpenAI, le successeur de GPT Image 1.5. Elle génère et modifie des images avec un rendu de texte précis pour les caractères latins et CJK, ainsi qu'une composition solide pour les affiches, les maquettes et les infographies. Sur Atlas Cloud, vous y accédez via une API unifiée aux côtés de plus de 300 modèles, avec des crédits gratuits, une disponibilité de 99,99 % et sans aucune vérification d'organisation OpenAI requise.
Les modèles créatifs les plus puissants de Google sont tous disponibles sur Atlas Cloud. Veo 3.1 offre une génération de vidéos cinématographiques, Nano Banana 2 permet de créer des images haute fidélité, et Gemini apporte une intelligence multimodale à chaque flux de travail. Accédez à la suite complète de modèles Google via une seule API key avec une disponibilité Day-0 et une tarification à l'usage (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini apporte la génération de vidéos multimodale de ByteDance aux flux de travail où la vitesse et les coûts sont primordiaux. Il offre les capacités de base de Seedance 2.0 avec une empreinte plus légère — une génération plus rapide, un coût par vidéo réduit et la même intégration API que celle que vous utilisez déjà. Pour les équipes qui gèrent des pipelines à haut volume ou du prototypage à grande échelle, Mini est le choix par défaut pratique.
ByteDance
De la génération de vidéos cinématiques à la création d'images haute fidélité, les modèles les plus puissants de ByteDance sont disponibles sur Atlas Cloud. Exécutez Seedance et Seedream à grande échelle avec les prix d'inférence les plus bas et aucune surcharge d'infrastructure.
Alibaba
Atlas Cloud rassemble l'ensemble de la gamme de modèles d'Alibaba sous une seule API : Qwen pour les tâches linguistiques et d'imagerie, et Wan pour la génération de vidéos jusqu'en 1080p. Accédez à chaque modèle avec une tarification à l'usage (pay-as-you-go) sans abonnement. L'API Alibaba est disponible via une URL de base unique en utilisant votre client existant compatible avec OpenAI.
OpenAI
Atlas Cloud vous donne accès à l'ensemble de la gamme de l'API OpenAI, de GPT Image 2 pour la génération d'images à Sora 2 pour la vidéo. Chaque modèle est disponible en paiement à l'usage sans engagement mensuel. Intégrez-le en remplaçant simplement l'URL de base à l'aide de l'API compatible OpenAI.
xAI
Créez des pipelines complets d'images et de vidéos en utilisant la xAI API sur Atlas Cloud. Générez en 2K, éditez avec des images de référence et animez des images en clips synchronisés avec l'audio.
Kwaivgi
L'API Kwaivgi à 15 % en dessous du tarif standard. Atlas Cloud offre un accès Day-0 aux nouvelles versions de Kling avec une tarification à l'usage et sans limite de postes. Un seul compte, une seule clé, tous les modèles Kling du niveau standard au niveau master.
Seedream 5.0 Pro
L'API Seedream 5.0 Pro offre aux développeurs le modèle d'édition d'images contrôlable de ByteDance sur Atlas Cloud. Elle positionne les modifications avec précision à l'aide d'ancrages et de coordonnées, sépare les images en calques modifiables, fusionne de multiples références et fait correspondre les couleurs et matériaux exacts, avec du texte multilingue en 2K et 3K. Sur Atlas Cloud, vous y accédez via une seule clé !


