Gemini Omni Flash API for Conversational Video Editing
La Gemini Omni API apporte à votre stack le modèle multimodal de génération et d'édition vidéo de Google DeepMind, présenté à Google I/O 2026. Gemini Omni fusionne le moteur de raisonnement de Gemini avec les médias génératifs : il accepte n'importe quelle combinaison de texte, d'images, de vidéo et d'audio pour produire des résultats cohérents et ancrés dans la connaissance. Affinez vos résultats par simple conversation — remplacez des objets, réécrivez des scènes, changez de style — tandis que la physique, les personnages et la continuité restent intacts. Atlas Cloud propose toute la gamme Gemini Omni Flash — texte vers vidéo, image vers vidéo avec jusqu'à 7 images de référence, et référence vers vidéo — via une API unifiée, avec une tarification transparente à la seconde à partir de $0.112 et sans abonnement. Commencez à développer dès aujourd'hui.
Explorez les Modèles Leaders
Atlas Cloud vous offre les derniers modèles créatifs de pointe de l'industrie.







Quatre façons de générer avec la Gemini Omni Flash API
Choisissez le point de terminaison de l'API Gemini Omni Flash adapté à votre tâche, de la génération de texte vers vidéo et d'image vers vidéo, jusqu'à la génération basée sur des références et l'édition conversationnelle.
| Modalité | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | Vous n'avez qu'un prompt textuel ? L'API Gemini Omni Flash Text-to-Video le transforme en un clip 720p avec audio synchronisé en une seule passe, en suivant une direction guidée par le raisonnement sur la scène, le mouvement et la caméra pour des clips allant jusqu'à 10 secondes. |
| Gemini Omni Flash Image-to-Video API (I2V) | L'API Image-to-Video de Gemini Omni Flash anime une image fixe pour lui donner du mouvement, en fixant la source originale comme image d'ouverture. Avec des mouvements naturels et un son synchronisé, elle donne vie aux photos de produits, aux portraits et aux concepts en 720p. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Guidez une génération avec jusqu'à sept images de référence et trois courts clips vidéo à l'aide de la Gemini Omni Flash Reference-to-Video API. Elle maintient la cohérence des personnages, du style et des scènes tout au long du clip, idéale pour les contenus de marque et de séries. |
| Gemini Omni Flash Video Edit API | Lorsqu'un clip nécessite des modifications, la Gemini Omni Flash Video Edit API applique des instructions en langage naturel via une Interactions API avec état (stateful). Elle échange des éléments, ajuste l'éclairage et redéfinit le style des scènes tout en gardant le reste de la séquence intact au fil des tours d'interaction. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
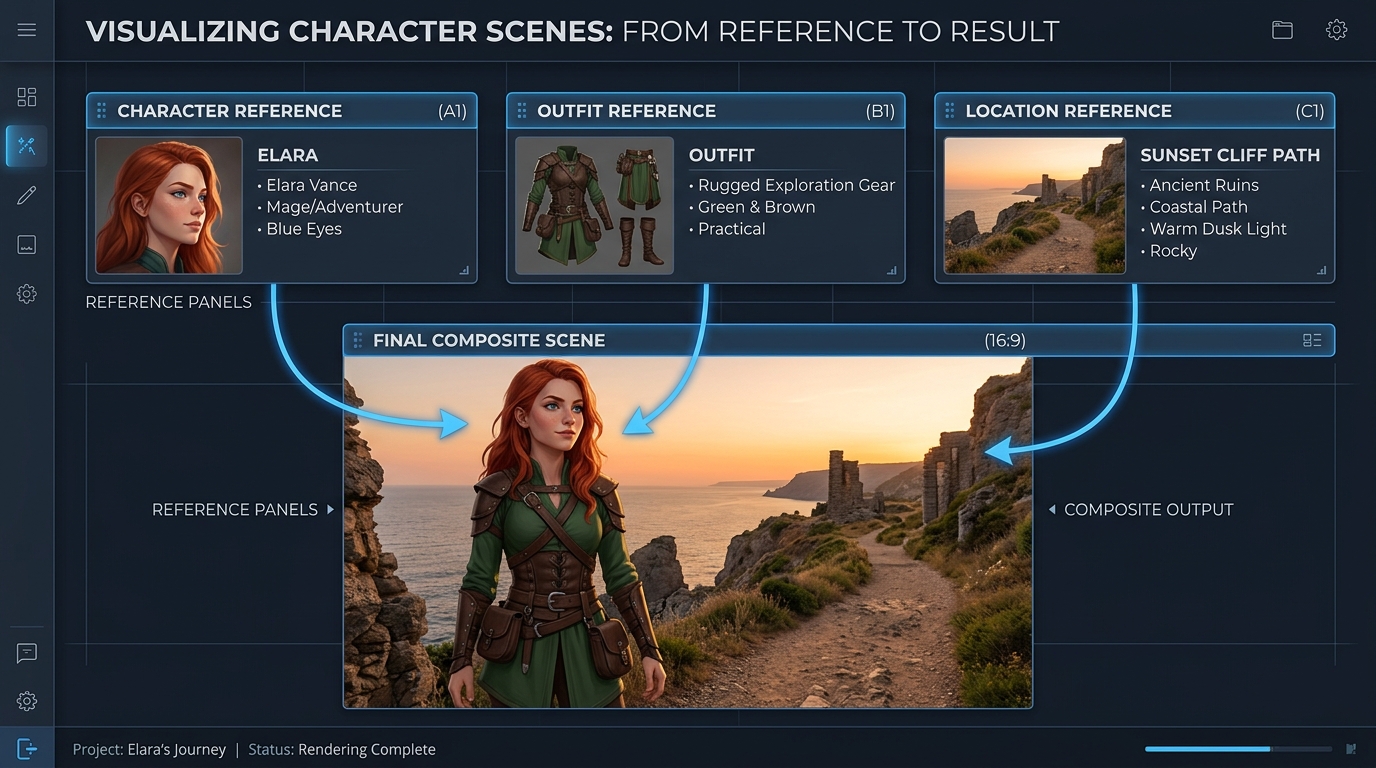
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Comment l'API Gemini Omni Flash se compare
Découvrez comment les modèles de différents fournisseurs se comparent — performance, tarification et atouts uniques pour une décision éclairée.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | Édition de vidéo finalisée par conversation | Yes | Oui, avec état | Texte, image, vidéo, audio |
| Veo 3.1 | Clips cinématographiques avec extension de scène | Yes | No | Texte, image, référence |
| Seedance 2.0 | Vidéo contrôlée par référence de qualité exceptionnelle | Yes | No | Texte, image, vidéo, audio |
| Kling 3.0 | Narration multi-plans dirigée par l'IA | Yes | No | Texte, image, référence |
Comment utiliser Gemini Omni Flash sur Atlas Cloud
Soyez opérationnel en quelques minutes — suivez ces étapes simples pour intégrer et déployer des modèles via la plateforme Atlas Cloud.
Créer un compte Atlas Cloud
Inscrivez-vous sur atlascloud.ai et complétez la vérification. Les nouveaux utilisateurs reçoivent des crédits gratuits pour explorer la plateforme et tester les modèles.
Pourquoi Utiliser Gemini Omni Flash sur Atlas Cloud
Combiner les modèles Gemini Omni Flash avancés avec la plateforme accélérée par GPU d'Atlas Cloud offre des performances, une évolutivité et une expérience développeur inégalées.
Performance et Flexibilité
Faible Latence :
Inférence optimisée par GPU pour un raisonnement en temps réel.
API Unifiée :
Exécutez Gemini Omni Flash, GPT, Gemini et DeepSeek avec une seule intégration.
Tarification Transparente :
Facturation prévisible par token avec options serverless.
Entreprise et Échelle
Expérience Développeur :
SDK, analytiques, outils de fine-tuning et modèles.
Fiabilité :
99,99% de disponibilité, RBAC et journalisation conforme.
Sécurité et Conformité :
SOC 2 Type II, alignement HIPAA, souveraineté des données aux États-Unis.
FAQ sur Google Gemini Omni Flash API
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
Explorer Plus de Familles
Seedance 2.0
L'API Seedance 2.0 vous donne un accès en production au modèle vidéo multimodal de ByteDance — des entrées quadrimodales (texte, image, vidéo, audio) et un système « Universal Reference » leader du secteur qui verrouille la composition, les mouvements de caméra et les actions des personnages à travers les plans. Intégrez un contrôle de niveau réalisateur avec un seul appel d'API, un tarif fixe de 0,09 $/s, une clé instantanée et aucune liste d'attente — le tout soutenu par une disponibilité et une conformité de niveau entreprise. Seedance 2.0 Native 4K est désormais disponible !
Grok Imagine
La Grok Imagine API offre aux développeurs la génération d'images, de vidéos et d'audio de xAI dans une seule suite. Elle produit des images jusqu'à 2K avec un rendu de texte multilingue, ainsi que des vidéos allant jusqu'à 15 secondes avec un audio natif synchronisé et une édition basée sur des références. Sur Atlas Cloud, une seule clé exécute chaque mode Grok Imagine, ce qui vous permet de passer d'une image, d'une vidéo et d'un audio à l'autre sans configuration distincte, à partir de 0,02 $ par image et 0,05 $ par seconde.
Gemini Omni Flash
La Gemini Omni API apporte à votre stack le modèle multimodal de génération et d'édition vidéo de Google DeepMind, présenté à Google I/O 2026. Gemini Omni fusionne le moteur de raisonnement de Gemini avec les médias génératifs : il accepte n'importe quelle combinaison de texte, d'images, de vidéo et d'audio pour produire des résultats cohérents et ancrés dans la connaissance. Affinez vos résultats par simple conversation — remplacez des objets, réécrivez des scènes, changez de style — tandis que la physique, les personnages et la continuité restent intacts. Atlas Cloud propose toute la gamme Gemini Omni Flash — texte vers vidéo, image vers vidéo avec jusqu'à 7 images de référence, et référence vers vidéo — via une API unifiée, avec une tarification transparente à la seconde à partir de $0.112 et sans abonnement. Commencez à développer dès aujourd'hui.
GPT Image 2
L'API GPT Image 2 offre aux développeurs un accès au dernier modèle d'image d'OpenAI, le successeur de GPT Image 1.5. Elle génère et modifie des images avec un rendu de texte précis pour les caractères latins et CJK, ainsi qu'une composition solide pour les affiches, les maquettes et les infographies. Sur Atlas Cloud, vous y accédez via une API unifiée aux côtés de plus de 300 modèles, avec des crédits gratuits, une disponibilité de 99,99 % et sans aucune vérification d'organisation OpenAI requise.
Les modèles créatifs les plus puissants de Google sont tous disponibles sur Atlas Cloud. Veo 3.1 offre une génération de vidéos cinématographiques, Nano Banana 2 permet de créer des images haute fidélité, et Gemini apporte une intelligence multimodale à chaque flux de travail. Accédez à la suite complète de modèles Google via une seule API key avec une disponibilité Day-0 et une tarification à l'usage (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini apporte la génération de vidéos multimodale de ByteDance aux flux de travail où la vitesse et les coûts sont primordiaux. Il offre les capacités de base de Seedance 2.0 avec une empreinte plus légère — une génération plus rapide, un coût par vidéo réduit et la même intégration API que celle que vous utilisez déjà. Pour les équipes qui gèrent des pipelines à haut volume ou du prototypage à grande échelle, Mini est le choix par défaut pratique.
ByteDance
De la génération de vidéos cinématiques à la création d'images haute fidélité, les modèles les plus puissants de ByteDance sont disponibles sur Atlas Cloud. Exécutez Seedance et Seedream à grande échelle avec les prix d'inférence les plus bas et aucune surcharge d'infrastructure.
Alibaba
Atlas Cloud rassemble l'ensemble de la gamme de modèles d'Alibaba sous une seule API : Qwen pour les tâches linguistiques et d'imagerie, et Wan pour la génération de vidéos jusqu'en 1080p. Accédez à chaque modèle avec une tarification à l'usage (pay-as-you-go) sans abonnement. L'API Alibaba est disponible via une URL de base unique en utilisant votre client existant compatible avec OpenAI.
OpenAI
Atlas Cloud vous donne accès à l'ensemble de la gamme de l'API OpenAI, de GPT Image 2 pour la génération d'images à Sora 2 pour la vidéo. Chaque modèle est disponible en paiement à l'usage sans engagement mensuel. Intégrez-le en remplaçant simplement l'URL de base à l'aide de l'API compatible OpenAI.
xAI
Créez des pipelines complets d'images et de vidéos en utilisant la xAI API sur Atlas Cloud. Générez en 2K, éditez avec des images de référence et animez des images en clips synchronisés avec l'audio.
Kwaivgi
L'API Kwaivgi à 15 % en dessous du tarif standard. Atlas Cloud offre un accès Day-0 aux nouvelles versions de Kling avec une tarification à l'usage et sans limite de postes. Un seul compte, une seule clé, tous les modèles Kling du niveau standard au niveau master.
Seedream 5.0 Pro
L'API Seedream 5.0 Pro offre aux développeurs le modèle d'édition d'images contrôlable de ByteDance sur Atlas Cloud. Elle positionne les modifications avec précision à l'aide d'ancrages et de coordonnées, sépare les images en calques modifiables, fusionne de multiples références et fait correspondre les couleurs et matériaux exacts, avec du texte multilingue en 2K et 3K. Sur Atlas Cloud, vous y accédez via une seule clé !


