
ChatGPT API for Frontier GPT 5.6 Reasoning
Atlas Cloud पर ChatGPT API OpenAI के नवीनतम GPT 5.6 परिवार को एक ही इंटीग्रेशन में लाता है, जिसमें गहन फ्रंटियर रीजनिंग के लिए Sol, स्थिर प्रोडक्शन वर्कलोड के लिए Terra, और स्वाभाविक बातचीत व कंटेंट जनरेशन के लिए Luna शामिल हैं। हर मॉडल को एक ही OpenAI-compatible key के ज़रिए रूट करें, production-grade uptime पर भरोसा करें, और पारदर्शी pay-as-you-go दरों पर भुगतान करें, जो प्रति मिलियन input tokens $1 से शुरू होती हैं। आज ही बनाना शुरू करें।
अग्रणी मॉडल एक्सप्लोर करें
Atlas Cloud आपको उद्योग में अग्रणी नवीनतम रचनात्मक मॉडल प्रदान करता है।
सही ChatGPT API मॉडल चुनें: हर एंडपॉइंट की तुलना
Frontier reasoning से लेकर budget-friendly conversation तक फैले पाँच text generation endpoints, सभी एक OpenAI-compatible key के ज़रिए पारदर्शी pay-as-you-go pricing के साथ उपलब्ध।
| मोडैलिटी | विवरण |
|---|---|
| GPT 5.6 Sol API (टेक्स्ट से टेक्स्ट) | Frontier AI workloads के लिए बनाया गया, GPT 5.6 Sol जटिल text prompts को महत्वाकांक्षी problem solving के लिए गहरे, multi-step reasoning output में बदलता है। Standard pricing $5 प्रति million input tokens और $30 प्रति million output tokens है, इसलिए जब answer quality लागत से अधिक महत्वपूर्ण हो, तो यह flagship विकल्प बनता है। |
| GPT 5.6 Terra API (टेक्स्ट से टेक्स्ट) | एक भरोसेमंद production default चाहिए? GPT 5.6 Terra prompts को real-world workflows और analysis pipelines के लिए grounded, practical text में बदलता है, जिसकी कीमत $2.50 input और $15 output प्रति million tokens है। Teams इसे customer-facing applications में deploy करती हैं, जहाँ experimental depth से अधिक consistency मायने रखती है। |
| GPT 5.6 Luna API (टेक्स्ट से टेक्स्ट) | Conversational और creative traffic को GPT 5.6 Luna पर route करें, यह एक text model है जिसे natural dialogue, content generation और personalized AI experiences के लिए tune किया गया है। $1 input और $6 output प्रति million tokens पर, यह इस ChatGPT API lineup का सबसे economical entry point है, जो chat products और high-volume copy generation के लिए उपयुक्त है। |
| GPT 5.4 API (टेक्स्ट से टेक्स्ट) | GPT 5.4 text instructions को reliable code, long-form content और structured problem-solving output में मजबूत accuracy के साथ process करता है। Design के हिसाब से एक advanced multimodal model, यह $2.50 input और $15 output प्रति million tokens की mid-tier pricing पर आता है, जो coding assistants और content platforms के लिए practical fit है। |
| GPT 5.5 API (टेक्स्ट से टेक्स्ट) | जब कठिन समस्याएँ premium spend को justify करती हैं, GPT 5.5 एक ही text endpoint से advanced reasoning, coding और content generation देता है। $5 input और $30 output प्रति million tokens की कीमत पर, यह agent orchestration और technical analysis जैसे complex, reliability-critical workloads को target करता है। |
ChatGPT API: GPT 5.x टियर्स और ओपन वेट्स
एक ही ChatGPT API के ज़रिए पूरे GPT 5.x लाइनअप और open-weight GPT OSS 120B तक पहुँचें, reasoning effort को low से xhigh तक ट्यून करें, एक ही कॉल में टेक्स्ट, इमेज और फाइलें मिलाएँ, और एक OpenAI-compatible key पर लाइव वेब सर्च के साथ native tools चलाएँ।
एक ChatGPT API कॉल में टेक्स्ट, इमेज और फाइलें
एक ही ChatGPT API अनुरोध में plain text, image URLs और document files को एक संदेश में जोड़ा जा सकता है। इससे अलग OCR या vision services की ज़रूरत खत्म होती है, ताकि आप scanned contracts को summarize कर सकें या screenshots को एक ही pass में पढ़ सकें।
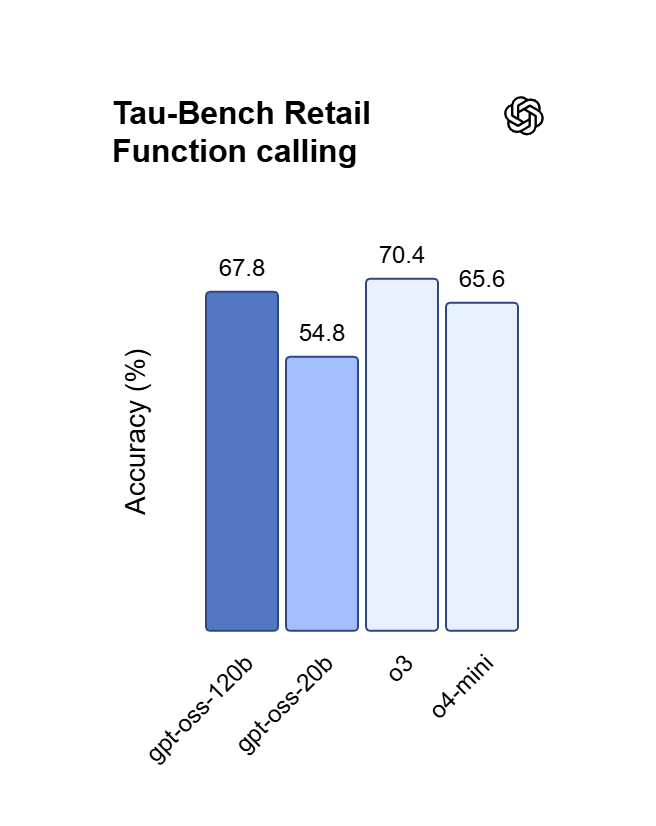
ChatGPT API पर निर्देशों के प्रति निष्ठा
GPT OSS 120B layered system prompts का पालन करता है, जिससे outputs में formats, constraints और tone बिना drift के स्थिर रहते हैं। यह भरोसेमंदी autonomous agents, structured extraction और production pipelines के लिए उपयुक्त है, जहाँ output को नियमों का पालन करना ही होता है।
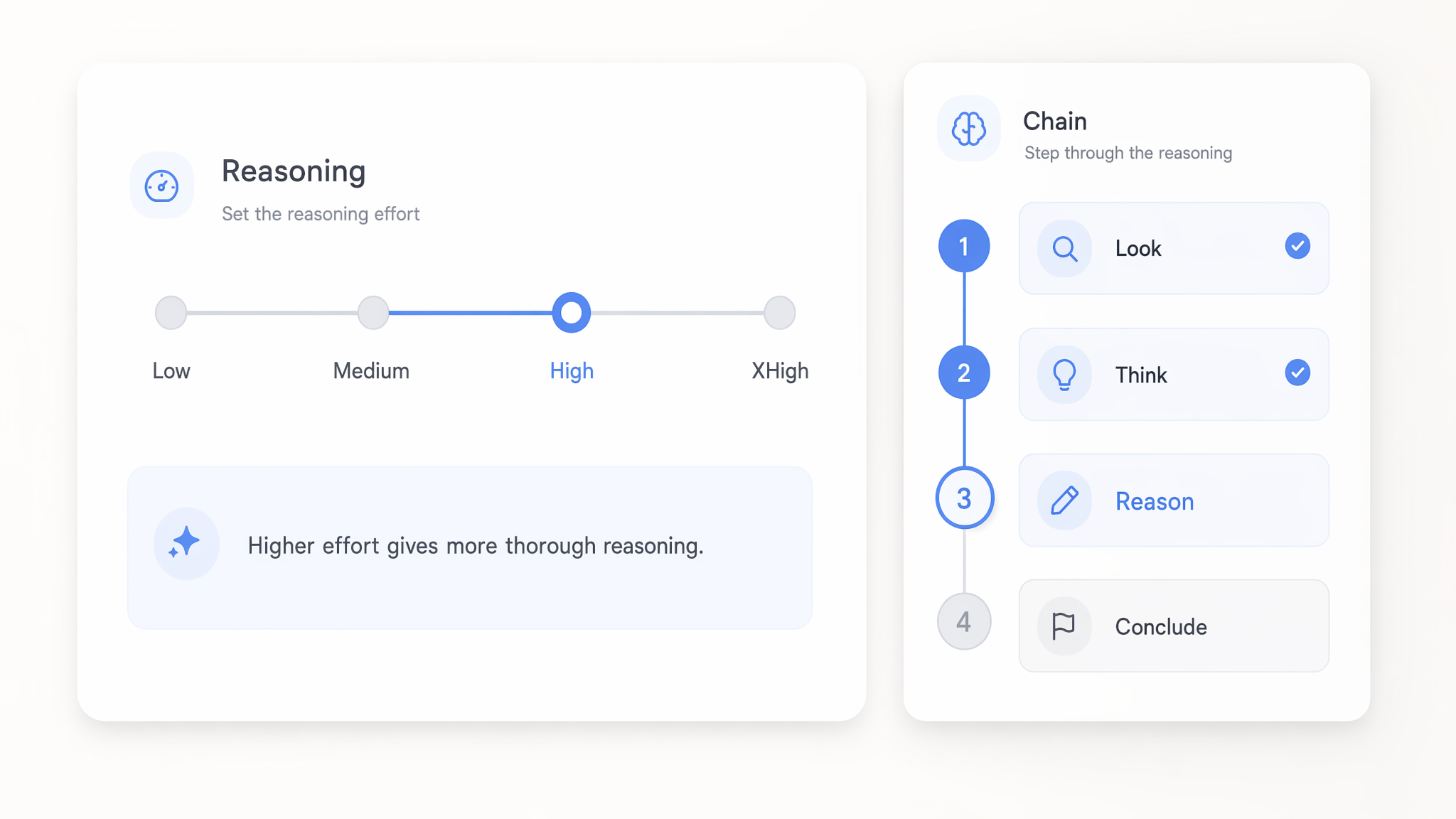
Reasoning Effort को Low से xHigh तक सेट करें
GPT 5.x models पर reasoning effort को low से xhigh तक कहीं भी सेट करें, ताकि नियंत्रित किया जा सके कि वे जवाब देने से पहले कितनी गहराई से सोचें। Low settings सरल calls का जवाब तेज़ और सस्ते में देती हैं, जबकि xhigh कठिन multi-step logic पर ज़्यादा compute खर्च करता है।
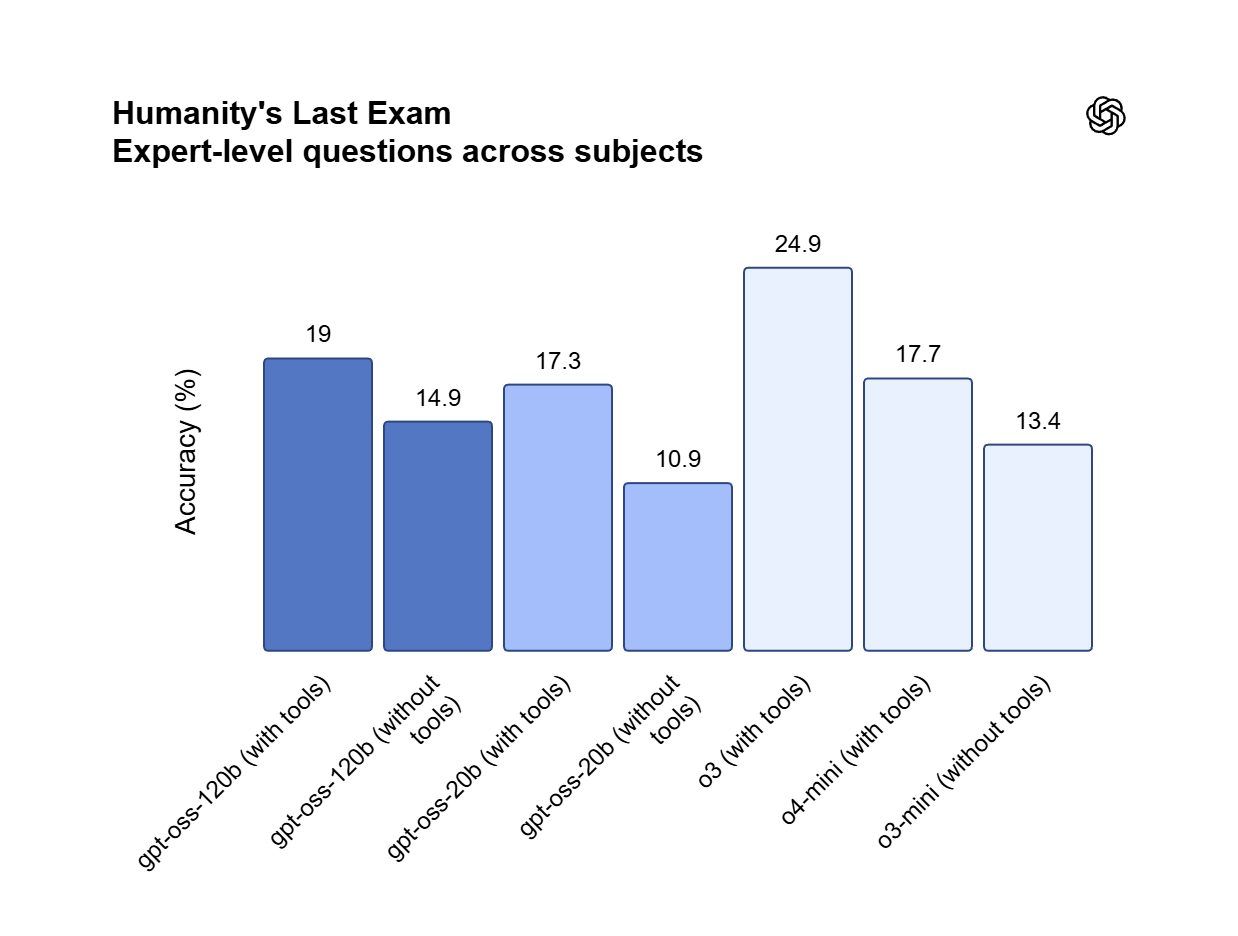
Apache 2.0 Weights जिन पर आपका पूरा नियंत्रण है
Apache 2.0 license के तहत वितरित, GPT OSS 120B commercial use और single 80GB GPU पर private fine-tuning की अनुमति देता है। Proprietary data को अपने ही सिस्टम में रखने और per-token fees से पूरी तरह बचने के लिए इसे on-premises host करें।

पाँच GPT Tiers, एक ChatGPT API
एक ChatGPT API पूरे GPT 5.x lineup को सेवा देता है, जिसकी कीमत Luna पर $1 से Sol पर $5 प्रति million input tokens तक है। हर call को उसकी cost और intelligence demand के अनुसार सही tier से match करें, बिना endpoint बदले।
Vibecoding के लिए ट्यून की गई Reasoning
OpenAI o4-mini के लगभग बराबर क्षमता के साथ GPT OSS 120B multi-step code synthesis और mathematical proofs संभाल सकता है। Plain-language ideas को working web apps में बदलें, nested logic debug करें और complex task-scheduling flows orchestrate करें।

Live Web Search के साथ Function Calls
GPT 5.x models automatic tool selection के साथ function calling और current results fetch करने वाली built-in web search को support करते हैं। Replies को server-sent events के रूप में stream करें, जबकि prompt caching GPT 5.6 Sol cached input की लागत घटाकर $0.5 प्रति million tokens कर देती है।
एक Prompt, तीन दावेदार: ChatGPT API आमने-सामने
हमने ChatGPT API और दो प्रतिद्वंद्वी फ्लैगशिप्स के ज़रिए models को बिल्कुल वही build instruction दिया, फिर हर raw HTML response को बिना छुए render किया ताकि आप reasoning depth, code quality और design taste को साथ-साथ परख सकें।
एक single self-contained HTML file बनाएं (सिर्फ inline CSS और JavaScript — बिल्कुल कोई external libraries, CDNs, frameworks, fonts या image URLs नहीं) जो किसी भी आधुनिक browser में सीधे खुले और एक जीवंत, अपने-आप बढ़ने वाला glass greenhouse ecosystem simulator चलाए, जिसे पूरी तरह flat Canvas/SVG vector illustration के रूप में render किया गया हो। full-viewport scene एक domed Victorian greenhouse है: ऊपर की ओर framing element की तरह एक curved glass cupola arc बनाता है, इसके panes translucent jade-green polygons के रूप में soft specular highlights और पतली muntin outlines के साथ बने हों, और नीचे की ओर dark cultivation soil की एक strip हो। Art direction clean vector illustration हो — leaves और stems crisp vein-line outlining और semi-transparent layered fills के साथ बने हों, palette misty sage green और mossy brown पर आधारित हो, amber sunlight और jade-glass accents के साथ; कोई photorealism नहीं, gradients-as-textures नहीं, इसे graphic और hand-illustrated feel में रखें। Core interaction: soil पर कहीं भी click करने से उसी spot पर seed planted हो, और plant real time में एक actual L-system का उपयोग करके grow करे — recursive rewriting grammar implement करें (axiom plus production rules with branching brackets और हर instance के लिए randomized angle/length jitter ताकि कोई भी दो plants identical न हों) और derivation को animate करें ताकि branches extend हों, fork करें, और leaves कुछ seconds में progressively unfurl हों, बजाय इसके कि fully formed pop in हो जाएं। Tropical ferns और climbing vines phototropically bend और curl करें एक draggable sun की ओर: glowing amber sun disc render करें जिसे user sky में कहीं भी grab और drag कर सके, और हर growing tip लगातार अपनी growth direction को sun की current position की ओर reorient करे ताकि sun को drag करने पर साफ दिखे कि पूरा garden कैसे lean और climb करता है। Seedlings easing animation के साथ unfurl हों, और condensation droplets glass पर बनें और loop में धीरे-धीरे नीचे slide करें। सब कुछ sun की position से जुड़े day-night cycle से drive करें: ambient light और sky wash warm-gold से cool-blue gradient तक smoothly slide करें, sun की location floor पर पड़ने वाली soft plant shadows की direction और length तथा glass पर drift करते light-spots तय करे, और dusk में fireflies foliage के बीच drift करते छोटे pulsing points of light की तरह fade in हों। Composition plant growth को base से ऊपर center की ओर radiate करे, dome के arc के भीतर contained रहे। continuous, शांत breathing animation loop के लिए requestAnimationFrame का उपयोग करें; screen पर कई plants एक साथ हों तब भी performance smooth रखें। Subtle unobtrusive controls शामिल करें (जैसे time of day के लिए slider या auto-advancing toggle, और reset/clear button) जिन्हें illustrated aesthetic से match करते हुए style किया गया हो, साथ में one-line hint हो जो user को soil पर click करके plant करने और growth guide करने के लिए sun drag करने को बताए। इसे किसी भी window size के लिए responsive बनाएं, और emotional tone calm, still, और alive हो — पहली morning light तिरछी आती हुई, जबकि tender shoots साथ-साथ खुलते हैं। यह एक generative simulation है, game या dashboard नहीं: genuine recursive growth algorithm, animation loop, और light/shadow/phototropism physics को प्राथमिकता दें।
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
एक complete single-file HTML page बनाएं जिसमें fictional लेकिन internally consistent data के साथ 8 industry sectors और 5 years के लिए interactive global startup funding dashboard हो। सभी CSS और JavaScript inline हों, zero external dependencies के साथ, कोई chart libraries नहीं, कोई CDNs नहीं, कोई images नहीं। canvas या SVG पर तीन hand-coded visualizations render करें: एक animated bar chart जो user द्वारा slider से year चुनने पर easing के साथ re-sort हो, एक line chart जिसमें exact values और vertical tracking guide दिखाने वाले hover tooltips हों, और एक donut chart जिसके segments hover पर spring animation के साथ expand हों। violet-to-teal accent palette के साथ dark modern UI शामिल करें, चार KPI stat cards में animated number counters, sector filter row में toggle chips जो सभी charts को तुरंत update करें, और smooth color transitions वाला light/dark theme switch। Layout responsive हो, 768px से नीचे single column में collapse हो, और हर interaction page reload के बिना real time में respond करे।
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
हर वर्कलोड जिसे ChatGPT API पावर कर सकता है
एजेंटिक कोडिंग और स्ट्रक्चर्ड एक्सट्रैक्शन से लेकर ग्राउंडेड सपोर्ट चैट और हाई-वॉल्यूम कंटेंट तक, Atlas Cloud पर ChatGPT API हर जॉब को एक OpenAI-compatible key के जरिए सही GPT 5.6 tier पर रूट करता है।

ChatGPT API के साथ एजेंटिक कोडिंग टूल्स शिप करें
जटिल रिफैक्टर और मल्टी-फाइल कोड सिंथेसिस को GPT 5.6 Sol पर रूट करें, जो फ्रंटियर इंजीनियरिंग वर्कलोड के लिए बना परिवार का डीप-रीजनिंग tier है। कोडिंग copilots, ऑटोमेटेड review bots, और test generators बनाने वाली टीमों को प्रोडक्शन-ग्रेड लॉजिक मिलता है।

स्केल पर ऑन-ब्रांड कंटेंट जनरेशन
GPT 5.6 Luna, परिवार का creative tier, नैचुरल टोन और पर्सनलाइज्ड आउटपुट के साथ blog posts, product descriptions, और localized copy ड्राफ्ट करता है। कंटेंट टीमें और ecommerce platforms ब्रांड वॉइस से समझौता किए बिना हाई-वॉल्यूम copy तैयार करते हैं।

ChatGPT API पर सपोर्ट असिस्टेंट्स पावर करें
ऐसा chatbot चाहिए जो स्क्रिप्ट पर बना रहे? GPT 5.6 Terra प्रोडक्शन बातचीत के लिए बनाए गए भरोसेमंद, ग्राउंडेड responses देता है, ताकि सपोर्ट टीमें और SaaS products tickets को ऑटोमेट कर सकें और repetitive queries को भरोसेमंद तरीके से deflect कर सकें।

Retrieval-Augmented नॉलेज सिस्टम्स
पूरे policy manuals या research archives को long-context model में फीड करें और source fidelity के साथ grounded answers पाएं। Legal, medical, और internal-search टीमों को retrieval-augmented question answering के लिए एक भरोसेमंद इंजन मिलता है।

ChatGPT API के जरिए स्ट्रक्चर्ड डेटा एक्सट्रैक्शन
बिखरे हुए invoices, emails, और PDFs साफ JSON में बदल जाते हैं जिस पर downstream systems भरोसा कर सकते हैं। भरोसेमंद instruction following schemas को intact रखता है, जिससे data pipelines, CRM automation, और analytics workflows को सपोर्ट मिलता है जहां drift बर्दाश्त नहीं किया जा सकता।

हर टास्क को सही Model Tier से मैच करें
जब budget और latency मायने रखते हैं, तो एक OpenAI-compatible key के जरिए Sol, Terra, और Luna के बीच स्विच करें। Startups और indie developers pay-as-you-go pricing पर तेजी से prototype बनाते हैं, फिर उसी integration को production तक scale करते हैं।
| मॉडल | संदर्भ | अधिकतम आउटपुट | इनपुट | पोज़िशनिंग |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | टेक्स्ट | उच्च-दक्षता वाला रीजनिंग LLM |
| GLM-5 | 202.75K | 202.75K | टेक्स्ट | फ़्लैगशिप फ़ाउंडेशन मॉडल |
| DeepSeek V3.2 | 163.84K | 163.84K | टेक्स्ट | फ़्लैगशिप जनरल |
| MiniMax-M2.5 | 204.8K | 196.6K | टेक्स्ट | SOTA एजेंटिक कोडिंग |
Atlas Cloud पर ChatGPT का उपयोग कैसे करें
कुछ ही मिनटों में शुरू करें — इन सरल चरणों का पालन करके Atlas Cloud प्लेटफ़ॉर्म के ज़रिए मॉडल इंटीग्रेट और डिप्लॉय करें।
Atlas Cloud अकाउंट बनाएं
atlascloud.ai पर साइन अप करें और वेरिफिकेशन पूरा करें। नए यूज़र्स को प्लेटफ़ॉर्म एक्सप्लोर करने और मॉडल टेस्ट करने के लिए फ्री क्रेडिट मिलते हैं।
Atlas Cloud पर ChatGPT का उपयोग क्यों करें
बेजोड़ प्रदर्शन, स्केलेबिलिटी और विकास अनुभव के लिए उन्नत ChatGPT मॉडल को Atlas Cloud के GPU त्वरण प्लेटफ़ॉर्म के साथ संयोजित करें।
प्रदर्शन और लचीलापन
कम विलंबता:
रियल-टाइम प्रतिक्रिया के लिए GPU-अनुकूलित इंफरेंसिंग।
एकीकृत API:
ChatGPT, GPT, Gemini और DeepSeek के लिए एक इंटीग्रेशन।
पारदर्शी मूल्य निर्धारण:
प्रति token बिलिंग, Serverless मोड का समर्थन।
एंटरप्राइज और स्केल
डेवलपर अनुभव:
SDK, डेटा एनालिटिक्स, फाइन-ट्यूनिंग टूल और टेम्पलेट पूरी तरह से उपलब्ध हैं।
विश्वसनीयता:
99.99% उपलब्धता, RBAC अनुमति नियंत्रण, अनुपालन लॉगिंग।
सुरक्षा और अनुपालन:
SOC 2 Type II प्रमाणन, HIPAA अनुपालन, US डेटा संप्रभुता।
ChatGPT API: डेवलपर सवालों के जवाब
ChatGPT API डेवलपर्स को चैट इंटरफेस के बजाय प्रोग्रामेटिक रूप से OpenAI के GPT models को prompts भेजने और completions प्राप्त करने देती है। Atlas Cloud पर आपको एक OpenAI-compatible endpoint के जरिए GPT 5.4 और GPT 5.5 के साथ पूरी GPT 5.6 lineup मिलती है। हर call का billing transparent pay-as-you-go pricing के साथ per token होता है, इसलिए आप केवल उसी के लिए भुगतान करते हैं जो आप generate करते हैं।
पाँच models deep reasoning से लेकर everyday chat तक की जरूरतों को cover करते हैं। GPT 5.6 Sol महत्वाकांक्षी problem-solving और frontier workloads के लिए है, GPT 5.6 Terra भरोसेमंद production workflows संभालता है, और GPT 5.6 Luna natural conversation और content generation के लिए tuned है। GPT 5.4 और GPT 5.5 उन teams के लिए multimodal reasoning और coding जोड़ते हैं जो proven general-purpose performance चाहती हैं।
एक API key generate करें, अपना base URL https://api.atlascloud.ai/v1 पर point करें, और model ID सेट करें, जैसे openai/gpt-5.6-terra। क्योंकि यहाँ ChatGPT API पूरी तरह OpenAI-compatible है, existing OpenAI SDK code सिर्फ base URL और key बदलने के बाद चल जाता है। कोई waitlist और कोई subscription नहीं है, और नए releases Day-0 access के साथ आते हैं, इसलिए आप उसी दिन अपना पहला request भेज सकते हैं।
Pricing आपके चुने गए model के अनुसार scale होती है। GPT 5.6 Luna सबसे किफायती है: $1 प्रति million input tokens और $6 प्रति million output tokens; GPT 5.6 Terra $2.5 और $15 पर चलता है; और GPT 5.6 Sol $5 और $30 पर है। Prompt caching repeated input की cost घटाती है, और billing pay-as-you-go रहती है, इसलिए आपसे केवल आपके इस्तेमाल किए गए tokens का charge लिया जाता है।
हाँ। Endpoint OpenAI Chat Completions format को follow करता है, इसलिए official OpenAI SDKs, LangChain, और अधिकांश OpenAI-compatible libraries base URL और key बदलते ही काम करती हैं। इसका मतलब है कि existing ChatGPT API integration आपकी request logic को rewrite किए बिना migrate हो सकती है।
Streaming और function calling दोनों OpenAI के implementation की तरह बिना बदलाव के काम करते हैं, इसलिए token-by-token output के लिए stream को true सेट करें और function calls trigger करने के लिए tools array pass करें। Structured JSON responses वही OpenAI-compatible request format follow करते हैं, जिससे agent orchestration और data-extraction pipelines predictable रहती हैं।
ये models long-document और full-repository workflows के लिए बड़े prompts accept करते हैं। Pricing 272,000-token mark पर tiered है: इसके नीचे के prompts के लिए standard rate और 272,000 tokens से ऊपर के prompts के लिए दूसरा rate। इसलिए आप एक ही request में extensive context दे सकते हैं और prompt बढ़ने पर rate कैसे बदलता है, यह ठीक-ठीक जान सकते हैं।
Model को काम के अनुसार match करें। जब आपको frontier reasoning और महत्वाकांक्षी problem-solving चाहिए हो, तो GPT 5.6 Sol चुनें; grounded, production-grade analysis के लिए GPT 5.6 Terra चुनें; और conversational या creative work के लिए, जहाँ cost सबसे ज्यादा मायने रखती है, GPT 5.6 Luna इस्तेमाल करें। GPT 5.4 और GPT 5.5 coding और general reasoning के लिए मजबूत multimodal options बने रहते हैं।
Atlas Cloud ChatGPT API को managed infrastructure पर चलाता है जो आपके traffic के साथ scale होता है, इसलिए आप self-hosting की GPU provisioning और node orchestration से बचते हैं। नए model versions Day-0 access के साथ उपलब्ध होते हैं, जिससे आप migration work के बिना current रहते हैं। अगर आपकी जरूरतें बढ़ती हैं, तो वही OpenAI-compatible key family के हर model को cover करती है, इसलिए scaling का मतलब कभी नई integration नहीं होता।
अधिक सीरीज़ एक्सप्लोर करें
Seedance 2.0
Seedance 2.0 API आपको ByteDance के मल्टीमॉडल वीडियो मॉडल तक प्रोडक्शन एक्सेस देता है — क्वाड-मॉडल इनपुट्स (टेक्स्ट, इमेज, वीडियो, ऑडियो) और एक उद्योग-अग्रणी "Universal Reference" सिस्टम जो शॉट्स के बीच कंपोजिशन, कैमरा मूवमेंट और कैरेक्टर एक्शन्स को लॉक करता है। एक API कॉल के साथ डायरेक्टर-लेवल कंट्रोल को इंटीग्रेट करें, $0.09/s की फ्लैट दर, इंस्टेंट की और बिना किसी वेटलिस्ट के — जिसे एंटरप्राइज़-ग्रेड अपटाइम और कंप्लायंस का समर्थन प्राप्त है। Seedance 2.0 Native 4K अब लाइव है!
Grok Imagine
Grok Imagine API डेवलपर्स को एक ही सूट में xAI की इमेज, वीडियो और ऑडियो जेनरेशन प्रदान करता है। यह बहुभाषी टेक्स्ट रेंडरिंग के साथ 2K तक की इमेज, और नेटिव, सिंक्रनाइज़ ऑडियो और संदर्भ-आधारित संपादन के साथ 15 सेकंड तक के वीडियो बनाता है। Atlas Cloud पर, एक ही कुंजी (key) हर Grok Imagine मोड को चलाती है, जिससे आप अलग-अलग सेटअप के बिना इमेज, वीडियो और ऑडियो के बीच स्विच कर सकते हैं, जिसकी कीमत $0.02 प्रति इमेज और $0.05 प्रति सेकंड से शुरू होती है।
Gemini Omni Flash
Gemini Omni API, Google I/O 2026 में पेश किए गए Google DeepMind के मल्टीमोडल वीडियो जेनरेशन और एडिटिंग मॉडल को आपके स्टैक तक लाता है। Gemini Omni, Gemini के रीज़निंग इंजन को जेनरेटिव मीडिया के साथ जोड़ता है और टेक्स्ट, इमेज, वीडियो तथा ऑडियो के किसी भी संयोजन को स्वीकार कर सुसंगत, ज्ञान-आधारित आउटपुट तैयार करता है। स्वाभाविक बातचीत के ज़रिए परिणामों को निखारें — ऑब्जेक्ट बदलें, सीन दोबारा लिखें और स्टाइल बदलें, जबकि फ़िज़िक्स, किरदार और निरंतरता ज्यों की त्यों बनी रहती है। Atlas Cloud पूरी Gemini Omni Flash सीरीज़ — टेक्स्ट-टू-वीडियो, 7 रेफ़रेंस इमेज तक के साथ इमेज-टू-वीडियो, और रेफ़रेंस-टू-वीडियो — एक एकीकृत API के माध्यम से उपलब्ध कराता है, जिसमें $0.112 से शुरू होने वाली पारदर्शी प्रति-सेकंड कीमत है और कोई सब्सक्रिप्शन नहीं। आज ही बनाना शुरू करें।
GPT Image 2
GPT Image 2 API डेवलपर्स को OpenAI के नवीनतम इमेज मॉडल तक पहुंच प्रदान करता है, जो GPT Image 1.5 का उत्तराधिकारी है। यह लैटिन और CJK लिपियों में सटीक टेक्स्ट रेंडरिंग के साथ चित्र बनाता और संपादित करता है, साथ ही पोस्टर, मॉकअप और इन्फोग्राफिक्स के लिए मजबूत संयोजन (कंपोजिशन) प्रदान करता है। Atlas Cloud पर आप इसे 300+ मॉडलों के साथ एक एकीकृत API के माध्यम से एक्सेस कर सकते हैं, जिसमें मुफ्त क्रेडिट, 99.99% अपटाइम और OpenAI संगठन सत्यापन की कोई आवश्यकता नहीं है।
Google के सबसे शक्तिशाली क्रिएटिव मॉडल अब Atlas Cloud पर उपलब्ध हैं। Veo 3.1 सिनेमैटिक वीडियो जनरेशन प्रदान करता है, Nano Banana 2 हाई-फिडेलिटी इमेज क्रिएशन को शक्ति देता है, और Gemini हर वर्कफ़्लो में मल्टीमॉडल इंटेलिजेंस लाता है। Day-0 उपलब्धता और पे-एज़-यू-गो (pay-as-you-go) प्राइसिंग के साथ एक ही API key के माध्यम से संपूर्ण Google मॉडल सूट तक पहुंचें।
Seedance 2.0 Mini
Seedance 2.0 Mini, ByteDance के मल्टीमोडल वीडियो जनरेशन को उन वर्कफ़्लो में लाता है जहाँ गति और लागत सबसे अधिक मायने रखते हैं। यह एक हल्के फुटप्रिंट पर Seedance 2.0 की मुख्य क्षमताएँ प्रदान करता है — तेज़ जनरेशन, प्रति वीडियो कम लागत, और वही API एकीकरण जिसका आप पहले से उपयोग करते हैं। उच्च-मात्रा वाले पाइपलाइन चलाने या बड़े पैमाने पर प्रोटोटाइपिंग करने वाली टीमों के लिए, Mini व्यावहारिक डिफ़ॉल्ट विकल्प है।
ByteDance
सिनेमैटिक वीडियो जनरेशन से लेकर हाई-फिडेलिटी इमेज क्रिएशन तक, ByteDance के सबसे शक्तिशाली मॉडल Atlas Cloud पर लाइव हैं। सबसे कम इन्फ्रेंस प्राइसिंग और शून्य इन्फ्रास्ट्रक्चर ओवरहेड के साथ बड़े पैमाने पर Seedance और Seedream को रन करें।
Alibaba
Atlas Cloud एक ही API के तहत Alibaba के पूरे मॉडल लाइनअप को एक साथ लाता है: भाषा और छवि कार्यों के लिए Qwen, और 1080p तक के वीडियो निर्माण के लिए Wan। बिना किसी सब्सक्रिप्शन के पे-एज़-यू-गो (pay-as-you-go) के आधार पर प्रत्येक मॉडल तक पहुँच प्राप्त करें। Alibaba API आपके मौजूदा OpenAI-संगत क्लाइंट का उपयोग करके एकल बेस URL के माध्यम से उपलब्ध है।
OpenAI
Atlas Cloud आपको पूर्ण OpenAI API लाइनअप तक पहुंच प्रदान करता है, छवि निर्माण के लिए GPT Image 2 से लेकर वीडियो के लिए Sora 2 तक। हर मॉडल बिना किसी मासिक प्रतिबद्धता के 'पे-ऐज़-यू-गो' (pay-as-you-go) आधार पर उपलब्ध है। OpenAI-संगत API का उपयोग करके एकल बेस URL स्वैप के साथ प्लग इन करें।
xAI
Atlas Cloud पर xAI API का उपयोग करके संपूर्ण इमेज और वीडियो पाइपलाइन बनाएं। 2K रिज़ॉल्यूशन पर जनरेट करें, संदर्भ छवियों के साथ संपादित करें, और छवियों को ऑडियो-सिंक किए गए क्लिप में एनिमेट करें।
Kwaivgi
Kwaivgi API मानक मूल्य निर्धारण से 15% कम पर। Atlas Cloud नए Kling रिलीज़ के लिए पे-एज़-यू-गो (उपयोग के अनुसार भुगतान) मूल्य निर्धारण और बिना किसी सीट सीमा के डे-0 (Day-0) एक्सेस प्रदान करता है। एक खाता, एक कुंजी, मानक से लेकर मास्टर टियर तक हर Kling मॉडल।
Seedream 5.0 Pro
Seedream 5.0 Pro API डेवलपर्स को Atlas Cloud पर ByteDance का नियंत्रणीय छवि संपादन मॉडल प्रदान करता है। यह एंकर और निर्देशांकों के साथ संपादनों को सटीक रूप से रखता है, छवियों को संपादन योग्य परतों में अलग करता है, कई संदर्भों को मिलाता है, और 2K और 3K पर बहुभाषी पाठ के साथ सटीक रंगों और सामग्रियों का मिलान करता है। Atlas Cloud पर आप एक कुंजी के माध्यम से इस तक पहुँच सकते हैं!


