Gemini Omni Flash API for Conversational Video Editing
Gemini Omni API, Google I/O 2026 में पेश किए गए Google DeepMind के मल्टीमोडल वीडियो जेनरेशन और एडिटिंग मॉडल को आपके स्टैक तक लाता है। Gemini Omni, Gemini के रीज़निंग इंजन को जेनरेटिव मीडिया के साथ जोड़ता है और टेक्स्ट, इमेज, वीडियो तथा ऑडियो के किसी भी संयोजन को स्वीकार कर सुसंगत, ज्ञान-आधारित आउटपुट तैयार करता है। स्वाभाविक बातचीत के ज़रिए परिणामों को निखारें — ऑब्जेक्ट बदलें, सीन दोबारा लिखें और स्टाइल बदलें, जबकि फ़िज़िक्स, किरदार और निरंतरता ज्यों की त्यों बनी रहती है। Atlas Cloud पूरी Gemini Omni Flash सीरीज़ — टेक्स्ट-टू-वीडियो, 7 रेफ़रेंस इमेज तक के साथ इमेज-टू-वीडियो, और रेफ़रेंस-टू-वीडियो — एक एकीकृत API के माध्यम से उपलब्ध कराता है, जिसमें $0.112 से शुरू होने वाली पारदर्शी प्रति-सेकंड कीमत है और कोई सब्सक्रिप्शन नहीं। आज ही बनाना शुरू करें।
अग्रणी मॉडल एक्सप्लोर करें
Atlas Cloud आपको उद्योग में अग्रणी नवीनतम रचनात्मक मॉडल प्रदान करता है।







Gemini Omni Flash API के साथ जनरेट करने के चार तरीके
वह Gemini Omni Flash API एंडपॉइंट चुनें जो आपके काम के अनुकूल हो, जिसमें टेक्स्ट-टू-वीडियो और इमेज-टू-वीडियो से लेकर रेफरेंस-ड्रिवन जनरेशन और कन्वर्सेशनल एडिटिंग तक शामिल हैं।
| मोडालिटी | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | क्या आपके पास केवल एक टेक्स्ट प्रॉम्प्ट है? Gemini Omni Flash Text-to-Video API इसे एक ही बार में सिंक्रोनाइज़्ड ऑडियो के साथ 720p क्लिप में बदल देता है, जो 10 सेकंड तक के क्लिप के लिए दृश्य, गति और कैमरे पर तर्क-संचालित निर्देशन का पालन करता है। |
| Gemini Omni Flash Image-to-Video API (I2V) | Gemini Omni Flash Image-to-Video API एक स्थिर छवि को गति में एनिमेट करता है, और मूल स्रोत को शुरुआती फ़्रेम के रूप में एंकर करता है। प्राकृतिक गति और सिंक्रनाइज़ किए गए ऑडियो के साथ, यह 720p रिज़ॉल्यूशन पर उत्पाद शॉट्स, पोर्ट्रेट और अवधारणाओं को जीवंत बनाता है। |
| Gemini Omni Flash Reference-to-Video API (R2V) | Gemini Omni Flash Reference-to-Video API का उपयोग करके सात संदर्भ छवियों और तीन लघु वीडियो क्लिप तक के साथ जनरेशन को निर्देशित करें। यह पूरे क्लिप में पात्र, शैली और दृश्य को सुसंगत रखता है, जो ब्रांडेड और श्रृंखला सामग्री के लिए आदर्श है। |
| Gemini Omni Flash Video Edit API | जब किसी क्लिप में बदलाव की आवश्यकता होती है, तो Gemini Omni Flash Video Edit API एक स्टेटफुल Interactions API के माध्यम से प्राकृतिक-भाषा के निर्देशों को लागू करता है। यह तत्वों को बदलता है, प्रकाश को समायोजित करता है, और दृश्यों को नया रूप देता है, जबकि कई चरणों (turns) में बाकी फुटेज को ज्यों का त्यों बनाए रखता है। |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
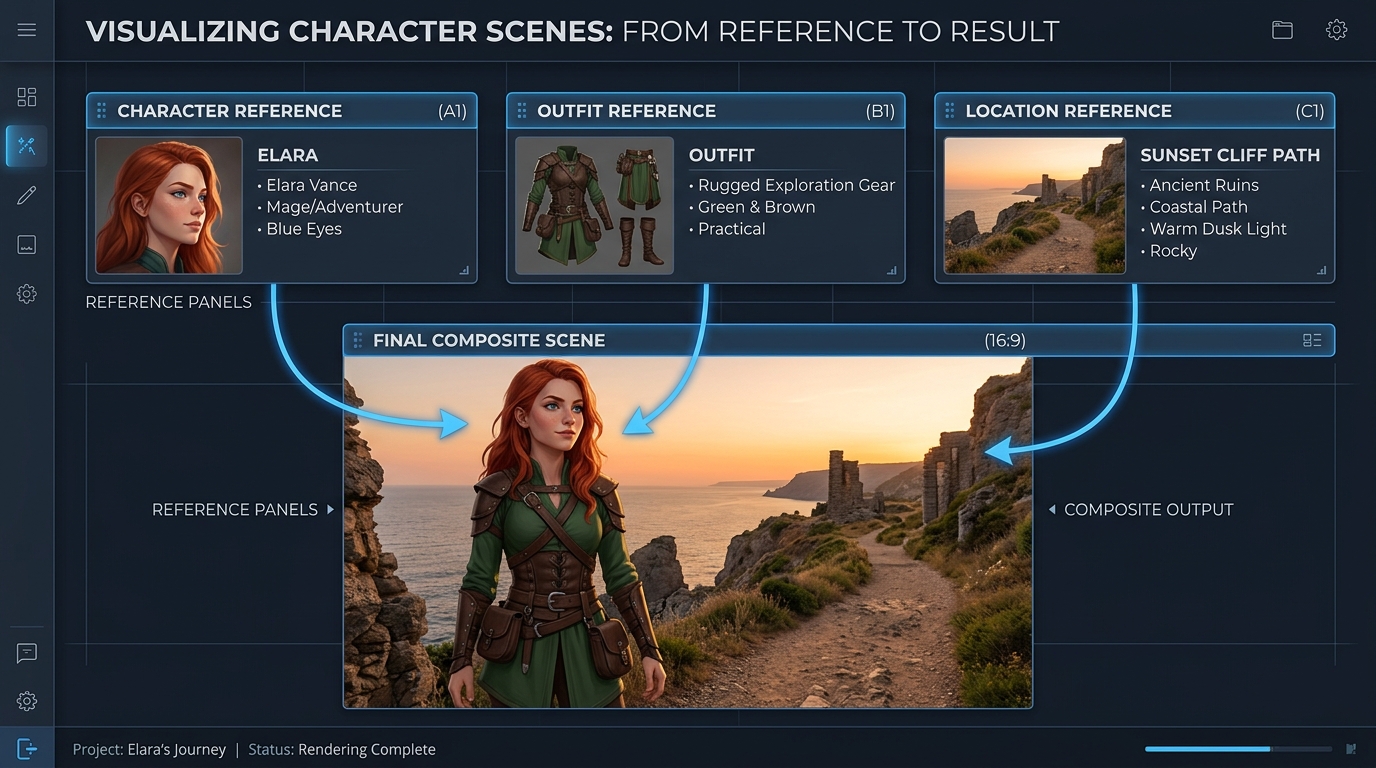
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Gemini Omni Flash API की तुलना
विभिन्न प्रदाताओं के मॉडलों की तुलना देखें — प्रदर्शन, मूल्य निर्धारण और अनूठी ताकतों की तुलना करके सूचित निर्णय लें।
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | बातचीत के माध्यम से तैयार वीडियो का संपादन | Yes | हाँ, स्टेटफुल | टेक्स्ट, छवि, वीडियो, ऑडियो |
| Veo 3.1 | दृश्य विस्तार के साथ सिनेमाई क्लिप | Yes | No | पाठ, छवि, संदर्भ |
| Seedance 2.0 | संदर्भ-नियंत्रित प्रीमियम गुणवत्ता वाला वीडियो | Yes | No | टेक्स्ट, छवि, वीडियो, ऑडियो |
| Kling 3.0 | मल्टी-शॉट AI-निर्देशक कथावाचन | Yes | No | पाठ, छवि, संदर्भ |
Atlas Cloud पर Gemini Omni Flash का उपयोग कैसे करें
कुछ ही मिनटों में शुरू करें — इन सरल चरणों का पालन करके Atlas Cloud प्लेटफ़ॉर्म के ज़रिए मॉडल इंटीग्रेट और डिप्लॉय करें।
Atlas Cloud अकाउंट बनाएं
atlascloud.ai पर साइन अप करें और वेरिफिकेशन पूरा करें। नए यूज़र्स को प्लेटफ़ॉर्म एक्सप्लोर करने और मॉडल टेस्ट करने के लिए फ्री क्रेडिट मिलते हैं।
Atlas Cloud पर Gemini Omni Flash का उपयोग क्यों करें
बेजोड़ प्रदर्शन, स्केलेबिलिटी और विकास अनुभव के लिए उन्नत Gemini Omni Flash मॉडल को Atlas Cloud के GPU त्वरण प्लेटफ़ॉर्म के साथ संयोजित करें।
प्रदर्शन और लचीलापन
कम विलंबता:
रियल-टाइम प्रतिक्रिया के लिए GPU-अनुकूलित इंफरेंसिंग।
एकीकृत API:
Gemini Omni Flash, GPT, Gemini और DeepSeek के लिए एक इंटीग्रेशन।
पारदर्शी मूल्य निर्धारण:
प्रति token बिलिंग, Serverless मोड का समर्थन।
एंटरप्राइज और स्केल
डेवलपर अनुभव:
SDK, डेटा एनालिटिक्स, फाइन-ट्यूनिंग टूल और टेम्पलेट पूरी तरह से उपलब्ध हैं।
विश्वसनीयता:
99.99% उपलब्धता, RBAC अनुमति नियंत्रण, अनुपालन लॉगिंग।
सुरक्षा और अनुपालन:
SOC 2 Type II प्रमाणन, HIPAA अनुपालन, US डेटा संप्रभुता।
Google Gemini Omni Flash API के बारे में अक्सर पूछे जाने वाले प्रश्न
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
अधिक सीरीज़ एक्सप्लोर करें
Seedance 2.0
Seedance 2.0 API आपको ByteDance के मल्टीमॉडल वीडियो मॉडल तक प्रोडक्शन एक्सेस देता है — क्वाड-मॉडल इनपुट्स (टेक्स्ट, इमेज, वीडियो, ऑडियो) और एक उद्योग-अग्रणी "Universal Reference" सिस्टम जो शॉट्स के बीच कंपोजिशन, कैमरा मूवमेंट और कैरेक्टर एक्शन्स को लॉक करता है। एक API कॉल के साथ डायरेक्टर-लेवल कंट्रोल को इंटीग्रेट करें, $0.09/s की फ्लैट दर, इंस्टेंट की और बिना किसी वेटलिस्ट के — जिसे एंटरप्राइज़-ग्रेड अपटाइम और कंप्लायंस का समर्थन प्राप्त है। Seedance 2.0 Native 4K अब लाइव है!
Grok Imagine
Grok Imagine API डेवलपर्स को एक ही सूट में xAI की इमेज, वीडियो और ऑडियो जेनरेशन प्रदान करता है। यह बहुभाषी टेक्स्ट रेंडरिंग के साथ 2K तक की इमेज, और नेटिव, सिंक्रनाइज़ ऑडियो और संदर्भ-आधारित संपादन के साथ 15 सेकंड तक के वीडियो बनाता है। Atlas Cloud पर, एक ही कुंजी (key) हर Grok Imagine मोड को चलाती है, जिससे आप अलग-अलग सेटअप के बिना इमेज, वीडियो और ऑडियो के बीच स्विच कर सकते हैं, जिसकी कीमत $0.02 प्रति इमेज और $0.05 प्रति सेकंड से शुरू होती है।
Gemini Omni Flash
Gemini Omni API, Google I/O 2026 में पेश किए गए Google DeepMind के मल्टीमोडल वीडियो जेनरेशन और एडिटिंग मॉडल को आपके स्टैक तक लाता है। Gemini Omni, Gemini के रीज़निंग इंजन को जेनरेटिव मीडिया के साथ जोड़ता है और टेक्स्ट, इमेज, वीडियो तथा ऑडियो के किसी भी संयोजन को स्वीकार कर सुसंगत, ज्ञान-आधारित आउटपुट तैयार करता है। स्वाभाविक बातचीत के ज़रिए परिणामों को निखारें — ऑब्जेक्ट बदलें, सीन दोबारा लिखें और स्टाइल बदलें, जबकि फ़िज़िक्स, किरदार और निरंतरता ज्यों की त्यों बनी रहती है। Atlas Cloud पूरी Gemini Omni Flash सीरीज़ — टेक्स्ट-टू-वीडियो, 7 रेफ़रेंस इमेज तक के साथ इमेज-टू-वीडियो, और रेफ़रेंस-टू-वीडियो — एक एकीकृत API के माध्यम से उपलब्ध कराता है, जिसमें $0.112 से शुरू होने वाली पारदर्शी प्रति-सेकंड कीमत है और कोई सब्सक्रिप्शन नहीं। आज ही बनाना शुरू करें।
GPT Image 2
GPT Image 2 API डेवलपर्स को OpenAI के नवीनतम इमेज मॉडल तक पहुंच प्रदान करता है, जो GPT Image 1.5 का उत्तराधिकारी है। यह लैटिन और CJK लिपियों में सटीक टेक्स्ट रेंडरिंग के साथ चित्र बनाता और संपादित करता है, साथ ही पोस्टर, मॉकअप और इन्फोग्राफिक्स के लिए मजबूत संयोजन (कंपोजिशन) प्रदान करता है। Atlas Cloud पर आप इसे 300+ मॉडलों के साथ एक एकीकृत API के माध्यम से एक्सेस कर सकते हैं, जिसमें मुफ्त क्रेडिट, 99.99% अपटाइम और OpenAI संगठन सत्यापन की कोई आवश्यकता नहीं है।
Google के सबसे शक्तिशाली क्रिएटिव मॉडल अब Atlas Cloud पर उपलब्ध हैं। Veo 3.1 सिनेमैटिक वीडियो जनरेशन प्रदान करता है, Nano Banana 2 हाई-फिडेलिटी इमेज क्रिएशन को शक्ति देता है, और Gemini हर वर्कफ़्लो में मल्टीमॉडल इंटेलिजेंस लाता है। Day-0 उपलब्धता और पे-एज़-यू-गो (pay-as-you-go) प्राइसिंग के साथ एक ही API key के माध्यम से संपूर्ण Google मॉडल सूट तक पहुंचें।
Seedance 2.0 Mini
Seedance 2.0 Mini, ByteDance के मल्टीमोडल वीडियो जनरेशन को उन वर्कफ़्लो में लाता है जहाँ गति और लागत सबसे अधिक मायने रखते हैं। यह एक हल्के फुटप्रिंट पर Seedance 2.0 की मुख्य क्षमताएँ प्रदान करता है — तेज़ जनरेशन, प्रति वीडियो कम लागत, और वही API एकीकरण जिसका आप पहले से उपयोग करते हैं। उच्च-मात्रा वाले पाइपलाइन चलाने या बड़े पैमाने पर प्रोटोटाइपिंग करने वाली टीमों के लिए, Mini व्यावहारिक डिफ़ॉल्ट विकल्प है।
ByteDance
सिनेमैटिक वीडियो जनरेशन से लेकर हाई-फिडेलिटी इमेज क्रिएशन तक, ByteDance के सबसे शक्तिशाली मॉडल Atlas Cloud पर लाइव हैं। सबसे कम इन्फ्रेंस प्राइसिंग और शून्य इन्फ्रास्ट्रक्चर ओवरहेड के साथ बड़े पैमाने पर Seedance और Seedream को रन करें।
Alibaba
Atlas Cloud एक ही API के तहत Alibaba के पूरे मॉडल लाइनअप को एक साथ लाता है: भाषा और छवि कार्यों के लिए Qwen, और 1080p तक के वीडियो निर्माण के लिए Wan। बिना किसी सब्सक्रिप्शन के पे-एज़-यू-गो (pay-as-you-go) के आधार पर प्रत्येक मॉडल तक पहुँच प्राप्त करें। Alibaba API आपके मौजूदा OpenAI-संगत क्लाइंट का उपयोग करके एकल बेस URL के माध्यम से उपलब्ध है।
OpenAI
Atlas Cloud आपको पूर्ण OpenAI API लाइनअप तक पहुंच प्रदान करता है, छवि निर्माण के लिए GPT Image 2 से लेकर वीडियो के लिए Sora 2 तक। हर मॉडल बिना किसी मासिक प्रतिबद्धता के 'पे-ऐज़-यू-गो' (pay-as-you-go) आधार पर उपलब्ध है। OpenAI-संगत API का उपयोग करके एकल बेस URL स्वैप के साथ प्लग इन करें।
xAI
Atlas Cloud पर xAI API का उपयोग करके संपूर्ण इमेज और वीडियो पाइपलाइन बनाएं। 2K रिज़ॉल्यूशन पर जनरेट करें, संदर्भ छवियों के साथ संपादित करें, और छवियों को ऑडियो-सिंक किए गए क्लिप में एनिमेट करें।
Kwaivgi
Kwaivgi API मानक मूल्य निर्धारण से 15% कम पर। Atlas Cloud नए Kling रिलीज़ के लिए पे-एज़-यू-गो (उपयोग के अनुसार भुगतान) मूल्य निर्धारण और बिना किसी सीट सीमा के डे-0 (Day-0) एक्सेस प्रदान करता है। एक खाता, एक कुंजी, मानक से लेकर मास्टर टियर तक हर Kling मॉडल।
Seedream 5.0 Pro
Seedream 5.0 Pro API डेवलपर्स को Atlas Cloud पर ByteDance का नियंत्रणीय छवि संपादन मॉडल प्रदान करता है। यह एंकर और निर्देशांकों के साथ संपादनों को सटीक रूप से रखता है, छवियों को संपादन योग्य परतों में अलग करता है, कई संदर्भों को मिलाता है, और 2K और 3K पर बहुभाषी पाठ के साथ सटीक रंगों और सामग्रियों का मिलान करता है। Atlas Cloud पर आप एक कुंजी के माध्यम से इस तक पहुँच सकते हैं!


