
ChatGPT API for Frontier GPT 5.6 Reasoning
L’API ChatGPT su Atlas Cloud porta la più recente famiglia GPT 5.6 di OpenAI in un’unica integrazione, che include Sol per il ragionamento avanzato di frontiera, Terra per carichi di lavoro di produzione affidabili e Luna per conversazioni naturali e generazione di contenuti. Instrada ogni modello tramite un’unica chiave compatibile con OpenAI, conta su tempi di attività di livello production-grade e paga tariffe trasparenti pay-as-you-go a partire da 1 $ per milione di token di input. Inizia a sviluppare oggi.
Esplora i Modelli di Punta
Atlas Cloud ti fornisce i più recenti modelli creativi leader del settore.
Scegli il modello API ChatGPT più adatto: confronto di tutti gli endpoint
Cinque endpoint di generazione di testo, dal reasoning di frontiera alla conversazione conveniente, tutti serviti tramite un’unica chiave compatibile con OpenAI e con prezzi pay-as-you-go trasparenti.
| Modalità | Descrizione |
|---|---|
| GPT 5.6 Sol API (Text to Text) | Progettato per carichi di lavoro di AI di frontiera, GPT 5.6 Sol trasforma prompt testuali complessi in output di reasoning profondi e multi-step per risolvere problemi ambiziosi. Il prezzo standard è di $5 per milione di token di input e $30 per milione di token di output, il che lo rende la scelta di punta quando la qualità della risposta conta più del costo. |
| GPT 5.6 Terra API (Text to Text) | Ti serve un default di produzione affidabile? GPT 5.6 Terra converte i prompt in testi concreti e pratici per workflow reali e pipeline di analisi a $2.50 per input e $15 per output per milione di token. I team lo implementano in applicazioni rivolte ai clienti, dove la coerenza conta più della profondità sperimentale. |
| GPT 5.6 Luna API (Text to Text) | Instrada il traffico conversazionale e creativo verso GPT 5.6 Luna, un modello testuale ottimizzato per dialoghi naturali, generazione di contenuti ed esperienze AI personalizzate. A $1 per input e $6 per output per milione di token, è il punto di ingresso più economico in questa gamma di ChatGPT API, ideale per prodotti di chat e generazione di copy ad alto volume. |
| GPT 5.4 API (Text to Text) | GPT 5.4 elabora istruzioni testuali producendo codice affidabile, contenuti long-form e output strutturati di problem solving con elevata accuratezza. Progettato come modello multimodale avanzato, si colloca nella fascia di prezzo intermedia, con $2.50 per input e $15 per output per milione di token: una soluzione pratica per coding assistant e piattaforme di contenuti. |
| GPT 5.5 API (Text to Text) | Quando i problemi difficili giustificano una spesa premium, GPT 5.5 offre reasoning avanzato, coding e generazione di contenuti da un unico endpoint testuale. Con un prezzo di $5 per input e $30 per output per milione di token, è pensato per carichi di lavoro complessi e critici per l’affidabilità, come orchestrazione di agenti e analisi tecnica. |
L'API ChatGPT: livelli GPT 5.x e pesi aperti
Accedi all'intera gamma GPT 5.x e a GPT OSS 120B con pesi aperti tramite un'unica API ChatGPT, regola lo sforzo di ragionamento da low a xhigh, combina testo, immagini e file in una sola chiamata e invoca strumenti nativi con ricerca web live usando una chiave compatibile con OpenAI.
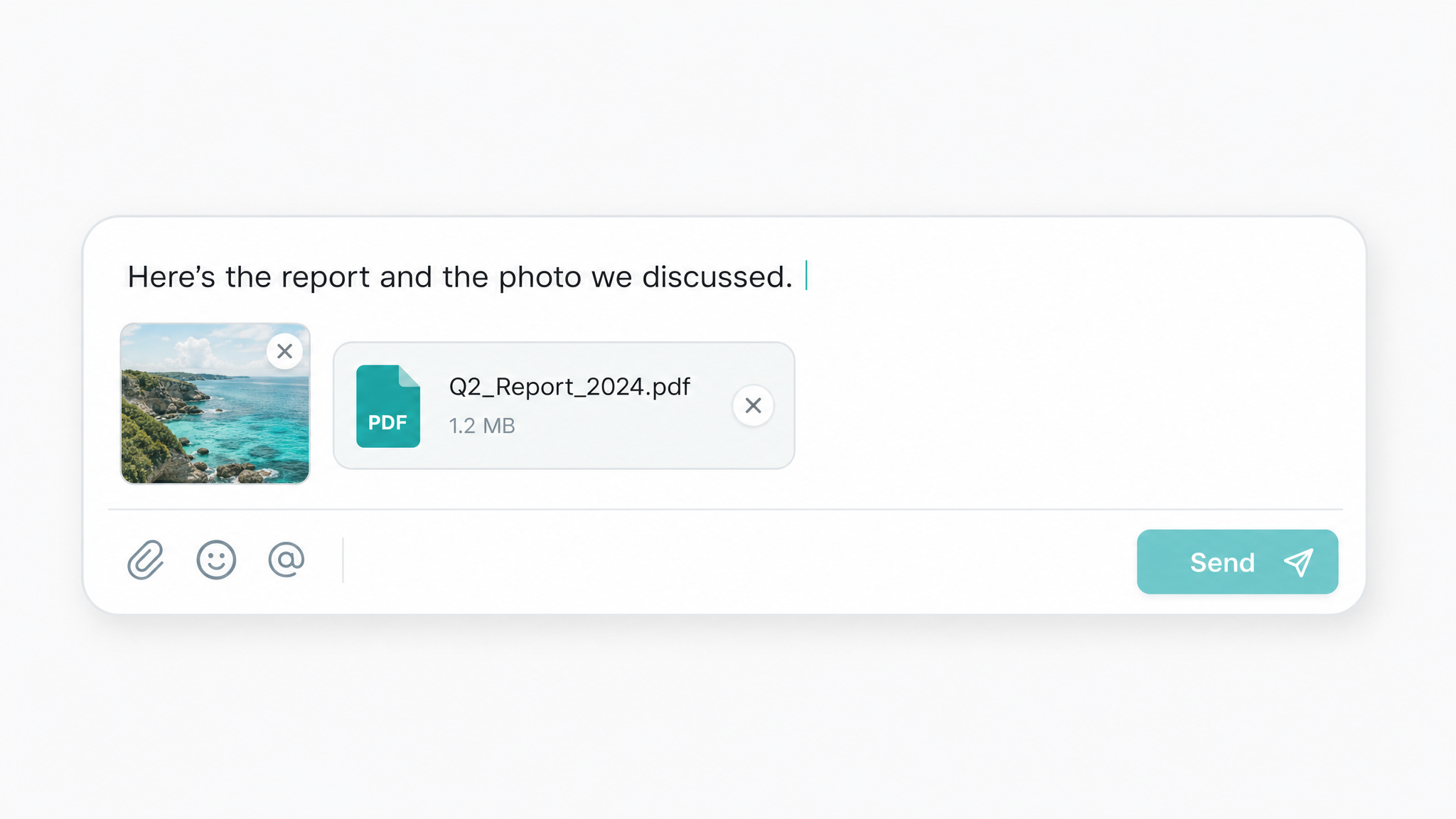
Testo, immagini e file in un'unica chiamata API ChatGPT
Una singola richiesta API ChatGPT può combinare testo semplice, URL di immagini e file di documenti in un unico messaggio. Questo elimina la necessità di servizi OCR o di visione separati, così puoi riassumere contratti scansionati o leggere screenshot in un solo passaggio.
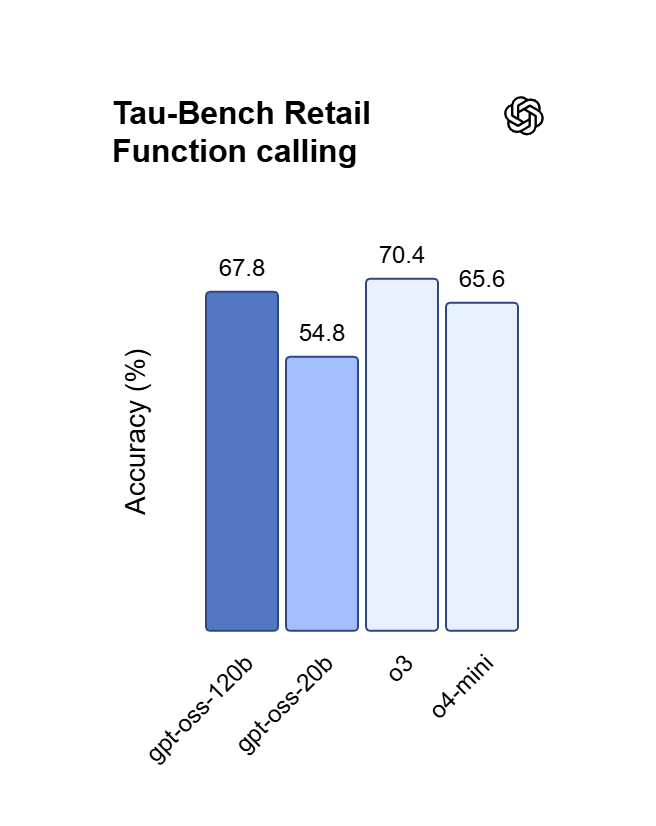
Fedeltà alle istruzioni nell'API ChatGPT
GPT OSS 120B rispetta prompt di sistema stratificati, mantenendo formati, vincoli e tono stabili tra gli output senza deviazioni. Questa affidabilità è ideale per agenti autonomi, estrazione strutturata e pipeline di produzione in cui l'output deve rispettare le regole.
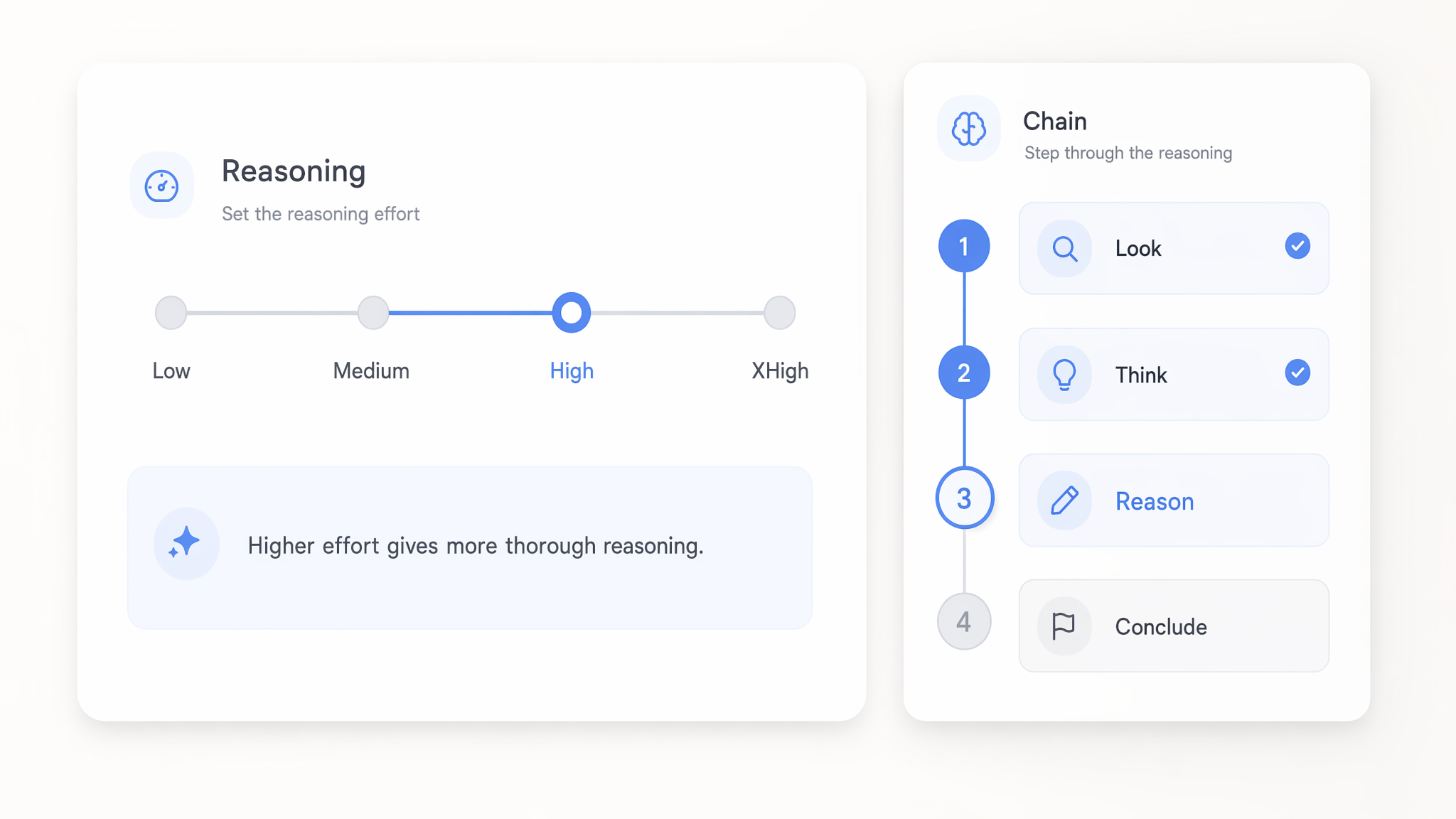
Regola lo sforzo di ragionamento da low a xhigh
Imposta lo sforzo di ragionamento sui modelli GPT 5.x ovunque da low fino a xhigh per controllare quanto approfonditamente ragionano prima di rispondere. Le impostazioni low rispondono alle chiamate semplici in modo rapido ed economico, mentre xhigh usa più calcolo per logiche multi-step complesse.
Pesi Apache 2.0 di cui hai pieno controllo
Distribuito con licenza Apache 2.0, GPT OSS 120B consente l'uso commerciale e il fine-tuning privato su una singola GPU da 80GB. Eseguilo on-premises per mantenere i dati proprietari internamente ed evitare del tutto le tariffe per token.

Cinque livelli GPT, un'unica API ChatGPT
Un'unica API ChatGPT serve l'intera gamma GPT 5.x, con prezzi da Luna a $1 fino a Sol a $5 per milione di token di input. Abbina ogni chiamata al livello richiesto da costo e intelligenza, senza cambiare endpoint.
Ragionamento ottimizzato per il vibecoding
Con prestazioni quasi alla pari di OpenAI o4-mini, GPT OSS 120B gestisce sintesi di codice multi-step e dimostrazioni matematiche. Trasforma idee in linguaggio naturale in web app funzionanti, esegui il debug di logiche annidate e orchestra flussi complessi di pianificazione delle attività.

Function call con ricerca web live
I modelli GPT 5.x supportano le function call con selezione automatica degli strumenti, oltre a una ricerca web integrata che recupera risultati aggiornati. Trasmetti le risposte in streaming come server-sent events, mentre la prompt caching riduce l'input in cache di GPT 5.6 Sol a $0.5 per milione di token.
Un prompt, tre contendenti: confronto diretto con ChatGPT API
Abbiamo inviato la stessa identica istruzione di build ai modelli tramite ChatGPT API e a due flagship concorrenti, poi abbiamo renderizzato ogni risposta HTML grezza senza modificarla, così puoi valutare fianco a fianco profondità del ragionamento, qualità del codice e gusto progettuale.
Crea un singolo file HTML autonomo (solo CSS e JavaScript inline — assolutamente nessuna libreria esterna, CDN, framework, font o URL di immagini) che si apra direttamente in qualsiasi browser moderno ed esegua un simulatore di ecosistema di serra in vetro vivo e auto-espandente, renderizzato interamente come illustrazione vettoriale piatta in Canvas/SVG. La scena a tutto viewport è una serra vittoriana a cupola: una cupola di vetro curva attraversa la parte superiore come elemento di cornice, con lastre disegnate come poligoni traslucidi verde giada, morbidi riflessi speculari e sottili profili dei montanti; lungo il bordo inferiore corre una striscia di scuro terriccio da coltivazione. La direzione artistica è un’illustrazione vettoriale pulita: foglie e steli disegnati con contorni netti delle venature e riempimenti stratificati semi-trasparenti, una palette basata su verde salvia nebbioso e marrone muschio, con luce solare ambrata e accenti di vetro giada; niente fotorealismo, niente gradienti usati come texture, mantieni un aspetto grafico e da illustrazione a mano. Interazione principale: facendo clic in qualsiasi punto del terreno si pianta un seme in quella posizione, e la pianta cresce in tempo reale usando un vero L-system — implementa una grammatica di riscrittura ricorsiva (assioma più regole di produzione con parentesi di ramificazione e variazioni casuali di angolo/lunghezza per ogni istanza, così che non esistano due piante identiche) e anima la derivazione in modo che i rami si estendano, si biforchino e dispieghino progressivamente le foglie nell’arco di alcuni secondi, invece di comparire già completamente formati. Felci tropicali e rampicanti devono piegarsi e arricciarsi fototropicamente verso un sole trascinabile: renderizza un disco solare ambrato e luminoso che l’utente può afferrare e trascinare ovunque nel cielo, e ogni apice in crescita deve riorientare continuamente la propria direzione di crescita verso la posizione attuale del sole, così che trascinando il sole si veda chiaramente come l’intero giardino si inclina e si arrampica. Le piantine si dispiegano con un’animazione easing, e gocce di condensa si formano sul vetro e scivolano lentamente verso il basso in loop. Guida tutto con un ciclo giorno-notte legato alla posizione del sole: la luce ambientale e la velatura del cielo scorrono fluidamente lungo un gradiente da oro caldo a blu freddo, la posizione del sole determina direzione e lunghezza delle morbide ombre delle piante proiettate sul pavimento e delle macchie di luce che scorrono sul vetro, e al crepuscolo le lucciole compaiono gradualmente come piccoli punti luminosi pulsanti che fluttuano tra il fogliame. La composizione irradia la crescita delle piante dalla base verso l’alto e il centro, contenuta dall’arco della cupola. Usa requestAnimationFrame per un ciclo di animazione continuo e quietamente pulsante; mantieni prestazioni fluide anche con molte piante sullo schermo contemporaneamente. Includi controlli discreti e non invasivi (ad esempio uno slider o un toggle di avanzamento automatico per l’ora del giorno, e un pulsante reset/clear) stilizzati in armonia con l’estetica illustrata, più un suggerimento su una riga che dica all’utente di cliccare il terreno per piantare e trascinare il sole per guidare la crescita. Rendilo responsive per qualsiasi dimensione della finestra, e dai un tono emotivo calmo, immobile e vivo — la prima luce del mattino che entra di taglio mentre germogli teneri si aprono insieme. Questa è una simulazione generativa, non un gioco né una dashboard: dai priorità al vero algoritmo di crescita ricorsiva, al ciclo di animazione e alla fisica di luce/ombra/fototropismo.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Crea una pagina HTML completa in un unico file contenente una dashboard interattiva globale sui finanziamenti alle startup, con dati fittizi ma internamente coerenti per 8 settori industriali lungo 5 anni. Tutto il CSS e il JavaScript devono essere inline, senza dipendenze esterne, senza librerie per grafici, senza CDN, senza immagini. Renderizza tre visualizzazioni scritte a mano in canvas o SVG: un grafico a barre animato che si riordina con easing quando l’utente seleziona un anno da uno slider, un grafico a linee con tooltip al passaggio del mouse che mostrano i valori esatti e una guida verticale di tracciamento, e un grafico a ciambella i cui segmenti si espandono al passaggio del mouse con un’animazione a molla. Includi una UI moderna scura con una palette di accenti dal viola al verde acqua, contatori numerici animati in quattro schede KPI, una riga di filtri settore con chip toggle che aggiornano istantaneamente tutti i grafici, e uno switch tema chiaro/scuro con transizioni di colore fluide. Il layout deve essere responsive, collassare in una singola colonna sotto i 768px, e ogni interazione deve rispondere in tempo reale senza ricaricare la pagina.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
Ogni carico di lavoro che la ChatGPT API può alimentare
Dalla programmazione agentica e dall’estrazione strutturata alla chat di supporto con risposte fondate e ai contenuti ad alto volume, la ChatGPT API su Atlas Cloud indirizza ogni attività al livello GPT 5.6 giusto tramite un’unica chiave compatibile con OpenAI.

Lancia strumenti di programmazione agentica con la ChatGPT API
Instrada refactoring complessi e sintesi di codice multi-file verso GPT 5.6 Sol, il livello di ragionamento profondo della famiglia, creato per carichi di lavoro di ingegneria di frontiera. I team che sviluppano copiloti di coding, bot di review automatizzata e generatori di test ottengono logica di livello production-grade.

Generazione di contenuti on-brand su larga scala
GPT 5.6 Luna, il livello creativo della famiglia, crea bozze di post per blog, descrizioni di prodotto e copy localizzato con tono naturale e output personalizzato. I team content e le piattaforme ecommerce producono copy ad alto volume senza sacrificare la voce del brand.

Alimenta gli assistenti di supporto con la ChatGPT API
Ti serve un chatbot che resti aderente allo script? GPT 5.6 Terra offre risposte affidabili e fondate, pensate per conversazioni in produzione, così i team di supporto e i prodotti SaaS possono automatizzare i ticket e deviare in modo affidabile le richieste ripetitive.

Sistemi di conoscenza Retrieval-Augmented
Fornisci interi manuali di policy o archivi di ricerca a un modello a contesto lungo e ottieni risposte fondate con fedeltà alle fonti. I team legali, medici e di ricerca interna dispongono di un motore affidabile per il question answering retrieval-augmented.

Estrazione di dati strutturati tramite la ChatGPT API
Fatture, email e PDF disordinati si trasformano in JSON pulito di cui i sistemi downstream possono fidarsi. L’esecuzione affidabile delle istruzioni mantiene intatti gli schemi, servendo pipeline di dati, automazione CRM e workflow di analytics che non possono tollerare derive.

Associa ogni attività al livello di modello giusto
Quando budget e latenza contano, passa da Sol, Terra e Luna tramite un’unica chiave compatibile con OpenAI. Startup e sviluppatori indie prototipano rapidamente con prezzi pay-as-you-go, poi scalano la stessa integrazione fino alla produzione.
| Modello | Contesto | Output massimo | Input | Posizionamento |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Testo | LLM di ragionamento ad alta efficienza |
| GLM-5 | 202.75K | 202.75K | Testo | Modello foundation di punta |
| DeepSeek V3.2 | 163.84K | 163.84K | Testo | Modello generalista di punta |
| MiniMax-M2.5 | 204.8K | 196.6K | Testo | Coding agentico SOTA |
Come Utilizzare ChatGPT su Atlas Cloud
Inizia in pochi minuti — segui questi semplici passaggi per integrare e distribuire i modelli tramite la piattaforma Atlas Cloud.
Crea un Account Atlas Cloud
Registrati su atlascloud.ai e completa la verifica. I nuovi utenti ricevono crediti gratuiti per esplorare la piattaforma e testare i modelli.
Perché Usare ChatGPT su Atlas Cloud
Combinando i modelli avanzati di ChatGPT con la piattaforma GPU-accelerata di Atlas Cloud, ottieni prestazioni, scalabilità ed esperienza di sviluppo senza pari.
Prestazioni e Flessibilità
Bassa Latenza:
Inferenza ottimizzata su GPU per elaborazione in tempo reale.
API Unificata:
Esegui ChatGPT, GPT, Gemini e DeepSeek con un'unica integrazione.
Prezzi Trasparenti:
Fatturazione prevedibile per token con opzioni Serverless.
Enterprise e Scalabilità
Esperienza Sviluppatore:
SDK, analytics, strumenti di fine-tuning e template.
Affidabilità:
99,99% di uptime, RBAC e logging conforme alle normative.
Sicurezza e Conformità:
SOC 2 Type II, allineamento HIPAA, sovranità dei dati negli USA.
ChatGPT API: risposte alle domande degli sviluppatori
La ChatGPT API consente agli sviluppatori di inviare prompt ai modelli GPT di OpenAI e ricevere completamenti a livello programmatico, invece che tramite l’interfaccia chat. Su Atlas Cloud puoi accedere all’intera lineup GPT 5.6, insieme a GPT 5.4 e GPT 5.5, tramite un unico endpoint compatibile con OpenAI. Ogni chiamata viene fatturata per token con prezzi pay-as-you-go trasparenti, quindi paghi solo ciò che generi.
Cinque modelli coprono l’intero spettro, dal ragionamento approfondito alla chat quotidiana. GPT 5.6 Sol è pensato per la risoluzione di problemi ambiziosi e workload di frontiera, GPT 5.6 Terra gestisce workflow di produzione affidabili e GPT 5.6 Luna è ottimizzato per conversazioni naturali e generazione di contenuti. GPT 5.4 e GPT 5.5 aggiungono ragionamento multimodale e coding per i team che vogliono prestazioni general-purpose già collaudate.
Genera una API key, imposta la base URL su https://api.atlascloud.ai/v1 e specifica il model ID, ad esempio openai/gpt-5.6-terra. Poiché qui la ChatGPT API è completamente compatibile con OpenAI, il codice esistente basato sugli OpenAI SDK funziona modificando solo base URL e key. Non ci sono waitlist né abbonamenti, e le nuove release arrivano con accesso Day-0, così puoi inviare la prima richiesta lo stesso giorno.
I prezzi variano in base al modello scelto. GPT 5.6 Luna è il più economico, a $1 per milione di input token e $6 per milione di output token; GPT 5.6 Terra costa $2.5 e $15, mentre GPT 5.6 Sol costa $5 e $30. Il prompt caching riduce il costo degli input ripetuti e la fatturazione resta pay-as-you-go, quindi ti vengono addebitati solo i token che utilizzi.
Sì. L’endpoint segue il formato OpenAI Chat Completions, quindi gli OpenAI SDK ufficiali, LangChain e la maggior parte delle librerie compatibili con OpenAI funzionano dopo aver sostituito base URL e key. Questo significa che un’integrazione ChatGPT API esistente può essere spostata senza riscrivere la logica delle richieste.
Streaming e function calling funzionano entrambi come nell’implementazione di OpenAI: imposti stream su true per ottenere l’output token per token e passi un array tools per attivare le chiamate di funzione. Le risposte JSON strutturate seguono lo stesso formato di richiesta compatibile con OpenAI, mantenendo prevedibili l’orchestrazione degli agenti e le pipeline di estrazione dati.
Questi modelli accettano prompt di grandi dimensioni per workflow su documenti lunghi e repository completi. I prezzi sono suddivisi in tier alla soglia di 272,000 token, con una tariffa standard per i prompt al di sotto di tale soglia e una seconda tariffa per quelli che superano 272,000 token. Puoi quindi fornire un contesto esteso in un’unica richiesta e sapere esattamente come cambia la tariffa al crescere del prompt.
Abbina il modello al lavoro da svolgere. Scegli GPT 5.6 Sol quando ti servono ragionamento di frontiera e risoluzione di problemi ambiziosi, GPT 5.6 Terra per analisi solide e production-grade, e GPT 5.6 Luna per attività conversazionali o creative in cui il costo è il fattore più importante. GPT 5.4 e GPT 5.5 restano ottime opzioni multimodali per coding e ragionamento generale.
Atlas Cloud esegue la ChatGPT API su un’infrastruttura gestita che scala con il tuo traffico, evitando provisioning di GPU e orchestrazione dei nodi tipici del self-hosting. Le nuove versioni dei modelli arrivano con accesso Day-0, così resti aggiornato senza lavoro di migrazione. Se le tue esigenze crescono, la stessa key compatibile con OpenAI copre ogni modello della famiglia, quindi scalare non richiede mai una nuova integrazione.
Esplora Altre Famiglie
Seedance 2.0
L'API Seedance 2.0 ti offre l'accesso in produzione al modello video multimodale di ByteDance: input quadrimodali (testo, immagine, video, audio) e un sistema "Universal Reference" leader del settore che blocca la composizione, i movimenti di macchina e le azioni dei personaggi tra le diverse inquadrature. Integra un controllo di livello registico con una sola chiamata API, una tariffa fissa di $0,09/s, chiave istantanea e nessuna lista d'attesa, il tutto supportato da uptime e conformità di livello enterprise. Seedance 2.0 Native 4K è ora disponibile!
Grok Imagine
La Grok Imagine API offre agli sviluppatori la generazione di immagini, video e audio di xAI in un'unica suite. Produce immagini fino a 2K con rendering di testi multilingue, oltre a video fino a 15 secondi con audio nativo e sincronizzato ed editing basato su riferimenti. Su Atlas Cloud una singola chiave esegue ogni modalità di Grok Imagine, in modo da poter passare tra immagine, video e audio senza configurazioni separate, a partire da 0,02 $ per immagine e 0,05 $ al secondo.
Gemini Omni Flash
La Gemini Omni API porta nel tuo stack il modello multimodale di generazione ed editing video di Google DeepMind, presentato a Google I/O 2026. Gemini Omni fonde il motore di ragionamento di Gemini con i media generativi, accettando qualsiasi combinazione di testo, immagini, video e audio per produrre output coerenti e fondati sulla conoscenza. Perfeziona i risultati con una conversazione naturale: sostituisci oggetti, riscrivi scene e cambia stile, mentre fisica, personaggi e continuità restano intatti. Atlas Cloud offre l'intera gamma Gemini Omni Flash — text-to-video, image-to-video con fino a 7 immagini di riferimento e reference-to-video — tramite un'unica API unificata, con prezzi trasparenti al secondo a partire da $0.112 e senza abbonamento. Inizia a sviluppare oggi stesso.
GPT Image 2
L'API GPT Image 2 offre agli sviluppatori l'accesso all'ultimo modello di immagini di OpenAI, il successore di GPT Image 1.5. Genera e modifica immagini con un rendering accurato del testo nei caratteri latini e CJK, oltre a una solida composizione per poster, mockup e infografiche. Su Atlas Cloud puoi accedervi tramite un'unica API unificata insieme a oltre 300 modelli, con crediti gratuiti, un tempo di attività del 99,99% e nessuna verifica dell'organizzazione OpenAI richiesta.
I modelli creativi più potenti di Google sono tutti disponibili su Atlas Cloud. Veo 3.1 offre la generazione di video cinematografici, Nano Banana 2 alimenta la creazione di immagini ad alta fedeltà e Gemini porta l'intelligenza multimodale in ogni flusso di lavoro. Accedi alla suite completa di modelli Google tramite una singola API key con disponibilità Day-0 e prezzi a consumo (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini porta la generazione video multimodale di ByteDance nei flussi di lavoro in cui velocità e costi sono fondamentali. Offre le capacità principali di Seedance 2.0 con un impatto minore: generazione più rapida, costi inferiori per video e la stessa integrazione API che utilizzi già. Per i team che gestiscono pipeline ad alto volume o prototipazione su larga scala, Mini è l'opzione predefinita pratica.
ByteDance
Dalla generazione di video cinematografici alla creazione di immagini ad alta fedeltà, i modelli più potenti di ByteDance sono disponibili su Atlas Cloud. Esegui Seedance e Seedream su larga scala con i prezzi di inferenza più bassi e zero costi generali di infrastruttura.
Alibaba
Atlas Cloud riunisce l'intera linea di modelli di Alibaba in un'unica API: Qwen per attività linguistiche e di immagine, Wan per la generazione di video fino a 1080p. Accedi a ogni modello in modalità pay-as-you-go senza abbonamenti. L'API di Alibaba è disponibile tramite una singola base URL utilizzando il tuo attuale client compatibile con OpenAI.
OpenAI
Atlas Cloud ti offre l'accesso all'intera linea di API di OpenAI, da GPT Image 2 per la generazione di immagini a Sora 2 per i video. Ogni modello è disponibile in modalità pay-as-you-go senza alcun impegno mensile. Integralo con una semplice sostituzione dell'URL di base utilizzando l'API compatibile con OpenAI.
xAI
Costruisci pipeline complete di immagini e video utilizzando la xAI API su Atlas Cloud. Genera in 2K, modifica con immagini di riferimento e anima le immagini in clip sincronizzate con l'audio.
Kwaivgi
L'API Kwaivgi al 15% in meno rispetto al prezzo standard. Atlas Cloud offre accesso Day-0 alle nuove versioni di Kling con prezzi a consumo e senza limiti di postazioni. Un solo account, una sola chiave, tutti i modelli Kling dal livello standard a quello master.
Seedream 5.0 Pro
L'API Seedream 5.0 Pro offre agli sviluppatori il modello di editing delle immagini controllabile di ByteDance su Atlas Cloud. Posiziona le modifiche con precisione tramite ancore e coordinate, separa le immagini in livelli modificabili, fonde più riferimenti e abbina colori e materiali esatti, con testo multilingue a 2K e 3K. Su Atlas Cloud puoi accedervi tramite una sola chiave!


