Gemini Omni Flash API for Conversational Video Editing
La Gemini Omni API porta nel tuo stack il modello multimodale di generazione ed editing video di Google DeepMind, presentato a Google I/O 2026. Gemini Omni fonde il motore di ragionamento di Gemini con i media generativi, accettando qualsiasi combinazione di testo, immagini, video e audio per produrre output coerenti e fondati sulla conoscenza. Perfeziona i risultati con una conversazione naturale: sostituisci oggetti, riscrivi scene e cambia stile, mentre fisica, personaggi e continuità restano intatti. Atlas Cloud offre l'intera gamma Gemini Omni Flash — text-to-video, image-to-video con fino a 7 immagini di riferimento e reference-to-video — tramite un'unica API unificata, con prezzi trasparenti al secondo a partire da $0.112 e senza abbonamento. Inizia a sviluppare oggi stesso.
Esplora i Modelli di Punta
Atlas Cloud ti fornisce i più recenti modelli creativi leader del settore.







Quattro modi per generare con la Gemini Omni Flash API
Scegli l'endpoint dell'API Gemini Omni Flash più adatto alla tua attività, dalla generazione da testo a video e da immagine a video, fino alla generazione basata su riferimenti e all'editing conversazionale.
| Modalità | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | Hai solo un prompt testuale? L'API Gemini Omni Flash Text-to-Video lo trasforma in un clip a 720p con audio sincronizzato in un solo passaggio, seguendo una regia guidata dal ragionamento per scena, movimento e telecamera per clip fino a 10 secondi. |
| Gemini Omni Flash Image-to-Video API (I2V) | L'API Image-to-Video di Gemini Omni Flash anima un'immagine statica mettendola in movimento, fissando la fonte originale come fotogramma iniziale. Con movimenti naturali e audio sincronizzato, dà vita a foto di prodotti, ritratti e concetti a 720p. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Guida una generazione con un massimo di sette immagini di riferimento e tre brevi clip video utilizzando la Gemini Omni Flash Reference-to-Video API. Mantiene la coerenza di personaggi, stile e scena in tutta la clip, ideale per contenuti di marca e seriali. |
| Gemini Omni Flash Video Edit API | Quando una clip richiede delle modifiche, la Gemini Omni Flash Video Edit API applica istruzioni in linguaggio naturale tramite una Interactions API stateful. Sostituisce elementi, regola l'illuminazione e rielabora lo stile delle scene, mantenendo intatto il resto del filmato nei vari turni di interazione. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
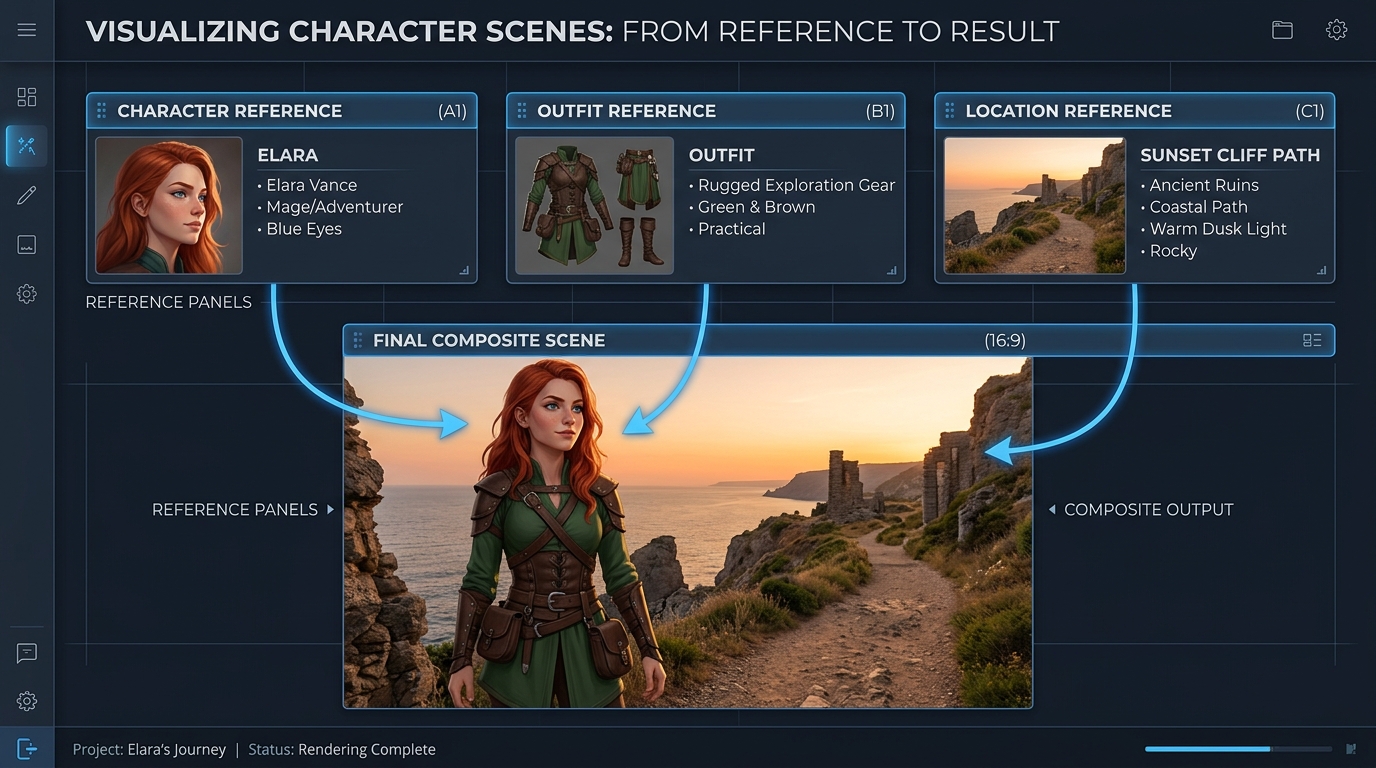
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Come si posiziona l'API Gemini Omni Flash
Scopri come si confrontano i modelli di diversi provider — confronta prestazioni, prezzi e punti di forza unici per una decisione informata.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | Modifica del video completato tramite conversazione | Yes | Sì, con stato | Testo, immagine, video, audio |
| Veo 3.1 | Clip cinematografiche con estensione della scena | Yes | No | Testo, immagine, riferimento |
| Seedance 2.0 | Video controllato da riferimento di altissima qualità | Yes | No | Testo, immagine, video, audio |
| Kling 3.0 | Storytelling multi-inquadratura con regia IA | Yes | No | Testo, immagine, riferimento |
Come Utilizzare Gemini Omni Flash su Atlas Cloud
Inizia in pochi minuti — segui questi semplici passaggi per integrare e distribuire i modelli tramite la piattaforma Atlas Cloud.
Crea un Account Atlas Cloud
Registrati su atlascloud.ai e completa la verifica. I nuovi utenti ricevono crediti gratuiti per esplorare la piattaforma e testare i modelli.
Perché Usare Gemini Omni Flash su Atlas Cloud
Combinando i modelli avanzati di Gemini Omni Flash con la piattaforma GPU-accelerata di Atlas Cloud, ottieni prestazioni, scalabilità ed esperienza di sviluppo senza pari.
Prestazioni e Flessibilità
Bassa Latenza:
Inferenza ottimizzata su GPU per elaborazione in tempo reale.
API Unificata:
Esegui Gemini Omni Flash, GPT, Gemini e DeepSeek con un'unica integrazione.
Prezzi Trasparenti:
Fatturazione prevedibile per token con opzioni Serverless.
Enterprise e Scalabilità
Esperienza Sviluppatore:
SDK, analytics, strumenti di fine-tuning e template.
Affidabilità:
99,99% di uptime, RBAC e logging conforme alle normative.
Sicurezza e Conformità:
SOC 2 Type II, allineamento HIPAA, sovranità dei dati negli USA.
Domande frequenti su Google Gemini Omni Flash API
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
Esplora Altre Famiglie
Seedance 2.0
L'API Seedance 2.0 ti offre l'accesso in produzione al modello video multimodale di ByteDance: input quadrimodali (testo, immagine, video, audio) e un sistema "Universal Reference" leader del settore che blocca la composizione, i movimenti di macchina e le azioni dei personaggi tra le diverse inquadrature. Integra un controllo di livello registico con una sola chiamata API, una tariffa fissa di $0,09/s, chiave istantanea e nessuna lista d'attesa, il tutto supportato da uptime e conformità di livello enterprise. Seedance 2.0 Native 4K è ora disponibile!
Grok Imagine
La Grok Imagine API offre agli sviluppatori la generazione di immagini, video e audio di xAI in un'unica suite. Produce immagini fino a 2K con rendering di testi multilingue, oltre a video fino a 15 secondi con audio nativo e sincronizzato ed editing basato su riferimenti. Su Atlas Cloud una singola chiave esegue ogni modalità di Grok Imagine, in modo da poter passare tra immagine, video e audio senza configurazioni separate, a partire da 0,02 $ per immagine e 0,05 $ al secondo.
Gemini Omni Flash
La Gemini Omni API porta nel tuo stack il modello multimodale di generazione ed editing video di Google DeepMind, presentato a Google I/O 2026. Gemini Omni fonde il motore di ragionamento di Gemini con i media generativi, accettando qualsiasi combinazione di testo, immagini, video e audio per produrre output coerenti e fondati sulla conoscenza. Perfeziona i risultati con una conversazione naturale: sostituisci oggetti, riscrivi scene e cambia stile, mentre fisica, personaggi e continuità restano intatti. Atlas Cloud offre l'intera gamma Gemini Omni Flash — text-to-video, image-to-video con fino a 7 immagini di riferimento e reference-to-video — tramite un'unica API unificata, con prezzi trasparenti al secondo a partire da $0.112 e senza abbonamento. Inizia a sviluppare oggi stesso.
GPT Image 2
L'API GPT Image 2 offre agli sviluppatori l'accesso all'ultimo modello di immagini di OpenAI, il successore di GPT Image 1.5. Genera e modifica immagini con un rendering accurato del testo nei caratteri latini e CJK, oltre a una solida composizione per poster, mockup e infografiche. Su Atlas Cloud puoi accedervi tramite un'unica API unificata insieme a oltre 300 modelli, con crediti gratuiti, un tempo di attività del 99,99% e nessuna verifica dell'organizzazione OpenAI richiesta.
I modelli creativi più potenti di Google sono tutti disponibili su Atlas Cloud. Veo 3.1 offre la generazione di video cinematografici, Nano Banana 2 alimenta la creazione di immagini ad alta fedeltà e Gemini porta l'intelligenza multimodale in ogni flusso di lavoro. Accedi alla suite completa di modelli Google tramite una singola API key con disponibilità Day-0 e prezzi a consumo (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini porta la generazione video multimodale di ByteDance nei flussi di lavoro in cui velocità e costi sono fondamentali. Offre le capacità principali di Seedance 2.0 con un impatto minore: generazione più rapida, costi inferiori per video e la stessa integrazione API che utilizzi già. Per i team che gestiscono pipeline ad alto volume o prototipazione su larga scala, Mini è l'opzione predefinita pratica.
ByteDance
Dalla generazione di video cinematografici alla creazione di immagini ad alta fedeltà, i modelli più potenti di ByteDance sono disponibili su Atlas Cloud. Esegui Seedance e Seedream su larga scala con i prezzi di inferenza più bassi e zero costi generali di infrastruttura.
Alibaba
Atlas Cloud riunisce l'intera linea di modelli di Alibaba in un'unica API: Qwen per attività linguistiche e di immagine, Wan per la generazione di video fino a 1080p. Accedi a ogni modello in modalità pay-as-you-go senza abbonamenti. L'API di Alibaba è disponibile tramite una singola base URL utilizzando il tuo attuale client compatibile con OpenAI.
OpenAI
Atlas Cloud ti offre l'accesso all'intera linea di API di OpenAI, da GPT Image 2 per la generazione di immagini a Sora 2 per i video. Ogni modello è disponibile in modalità pay-as-you-go senza alcun impegno mensile. Integralo con una semplice sostituzione dell'URL di base utilizzando l'API compatibile con OpenAI.
xAI
Costruisci pipeline complete di immagini e video utilizzando la xAI API su Atlas Cloud. Genera in 2K, modifica con immagini di riferimento e anima le immagini in clip sincronizzate con l'audio.
Kwaivgi
L'API Kwaivgi al 15% in meno rispetto al prezzo standard. Atlas Cloud offre accesso Day-0 alle nuove versioni di Kling con prezzi a consumo e senza limiti di postazioni. Un solo account, una sola chiave, tutti i modelli Kling dal livello standard a quello master.
Seedream 5.0 Pro
L'API Seedream 5.0 Pro offre agli sviluppatori il modello di editing delle immagini controllabile di ByteDance su Atlas Cloud. Posiziona le modifiche con precisione tramite ancore e coordinate, separa le immagini in livelli modificabili, fonde più riferimenti e abbina colori e materiali esatti, con testo multilingue a 2K e 3K. Su Atlas Cloud puoi accedervi tramite una sola chiave!


