MiniMax LLM Models
As a premier suite of Large Language Models (LLMs) developed by MiniMax AI, MiniMax is engineered to redefine real-world productivity through cutting-edge artificial intelligence. The ecosystem features MiniMax M2.5, which is purpose-built for high-efficiency professional environments, and MiniMax M2.1, a model that offers significantly enhanced multi-language programming capabilities to master complex, large-scale technical tasks. By achieving SOTA performance in coding, agentic tool use, intelligent search, and office workflow automation, MiniMax empowers users to streamline a wide range of economically valuable operations with unparalleled precision and reliability.
Explore the Leading MiniMax LLM Models
Atlas Cloud ti fornisce i più recenti modelli creativi leader del settore.
Cosa Rende Speciale MiniMax LLM Models
Atlas Cloud ti fornisce i più recenti modelli creativi leader del settore.
Ragionamento su scala di frontiera
Modelli linguistici all'avanguardia costruiti per il ragionamento profondo, la risoluzione di problemi complessi e la pianificazione a più fasi.
Comprensione del contesto ultra-lungo
L'attenzione in stile Lightning e un'architettura ottimizzata consentono ai modelli MiniMax di elaborare e conservare contesti lunghi,
Prestazioni MoE efficienti in termini di costi
Le architetture Mixture-of-Experts offrono un'elevata intelligenza, bassa latenza e un rapporto prezzo-prestazioni significativamente migliore.
Famiglia di modelli versatili
Da potenti modelli di uso generale a varianti ottimizzate per il coding e gli agenti.
Affidabilità di livello aziendale
Infrastruttura stabile e scalabile con monitoraggio e sicurezza per l'uso in produzione.
Aperto e a misura di sviluppatore
API ricche, SDK e rilasci open-weight offrono agli sviluppatori la flessibilità di integrare, perfezionare o gestire in self-hosting.
Velocità di picco
Costo più basso
| Modello | Descrizione |
|---|---|
| MiniMax M2.5 | MiniMax M2.5 è un LLM di punta ottimizzato per la produttività nel mondo reale, che integra architetture di inferenza avanzate con ampie capacità di elaborazione del contesto di 196,61K; vantando prestazioni SOTA nell'automazione d'ufficio e nella ricerca intelligente, funge da motore ad alta efficienza per la gestione di compiti economicamente preziosi e ragionamenti generali complessi in ambienti professionali. |
| MiniMax M2.1 | MiniMax M2.1 è un LLM ad alte prestazioni su misura per sfide tecniche complesse, che integra una programmazione multilingue significativamente migliorata con una robusta elaborazione del contesto di 196.61K; vantando un'eccezionale precisione nell'uso di strumenti agentici, funge da fondamento per la costruzione di Agents sofisticati per la pianificazione delle attività e per la risoluzione di intricati problemi ingegneristici su larga scala. |
| MiniMax M2 | MiniMax M2 è un LLM general-purpose SOTA, che integra moduli di ragionamento altamente efficienti con capacità di elaborazione del contesto espansive di 196.61K; vantando una versatilità competitiva in codifica, ricerca e flussi di lavoro professionali, funge da pietra angolare affidabile per le operazioni aziendali quotidiane che richiedono un'integrazione perfetta dell'esecuzione di attività in più passaggi. |
Nuove funzionalità di MiniMax LLM Models + Showcase
La combinazione di modelli avanzati con la piattaforma accelerata da GPU di Atlas Cloud offre velocità, scalabilità e controllo creativo senza pari per la generazione di immagini e video.
Programmazione avanzata e pianificazione degli agenti con MiniMax M2.5
MiniMax M2.5 supporta oltre 10 linguaggi di programmazione, tra cui Rust, Go e Python, per facilitare uno sviluppo full-stack completo su piattaforme Web, mobile e desktop. Integrando una profonda conoscenza del settore per la formattazione professionale dei documenti e la modellazione finanziaria, consente transizioni fluide dalla progettazione dell'architettura di sistema ai test finali dei deliverable. È la soluzione definitiva per l'ingegneria del software complessa e i flussi di lavoro di produttività d'ufficio ad alto rischio.
Risposta rapida ed efficienza decisionale delle attività con MiniMax M2.5
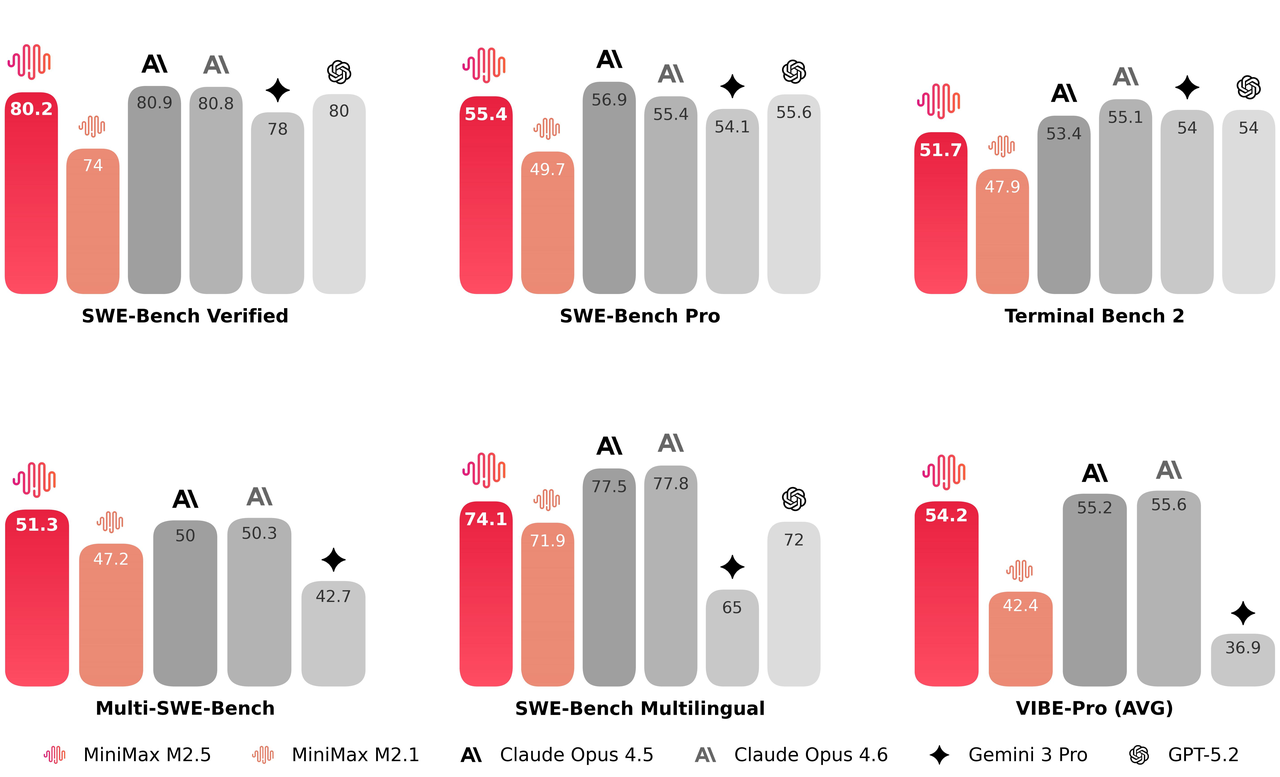
L'architettura M2.5 ottiene un aumento di velocità del 37% nell'esecuzione end-to-end, riducendo significativamente la durata di compiti complessi da 31,3 a 22,8 minuti su SWE-bench. Ottimizzando la logica di decomposizione dei task, il modello richiede il 20% in meno di token e round di ricerca per raggiungere gli obiettivi in benchmark come BrowseComp. Offre una soluzione snella per processi decisionali ad alta velocità, eliminando al contempo il sovraccarico computazionale ridondante.
Architettura evolutiva tramite apprendimento per rinforzo su larga scala con MiniMax M2.5
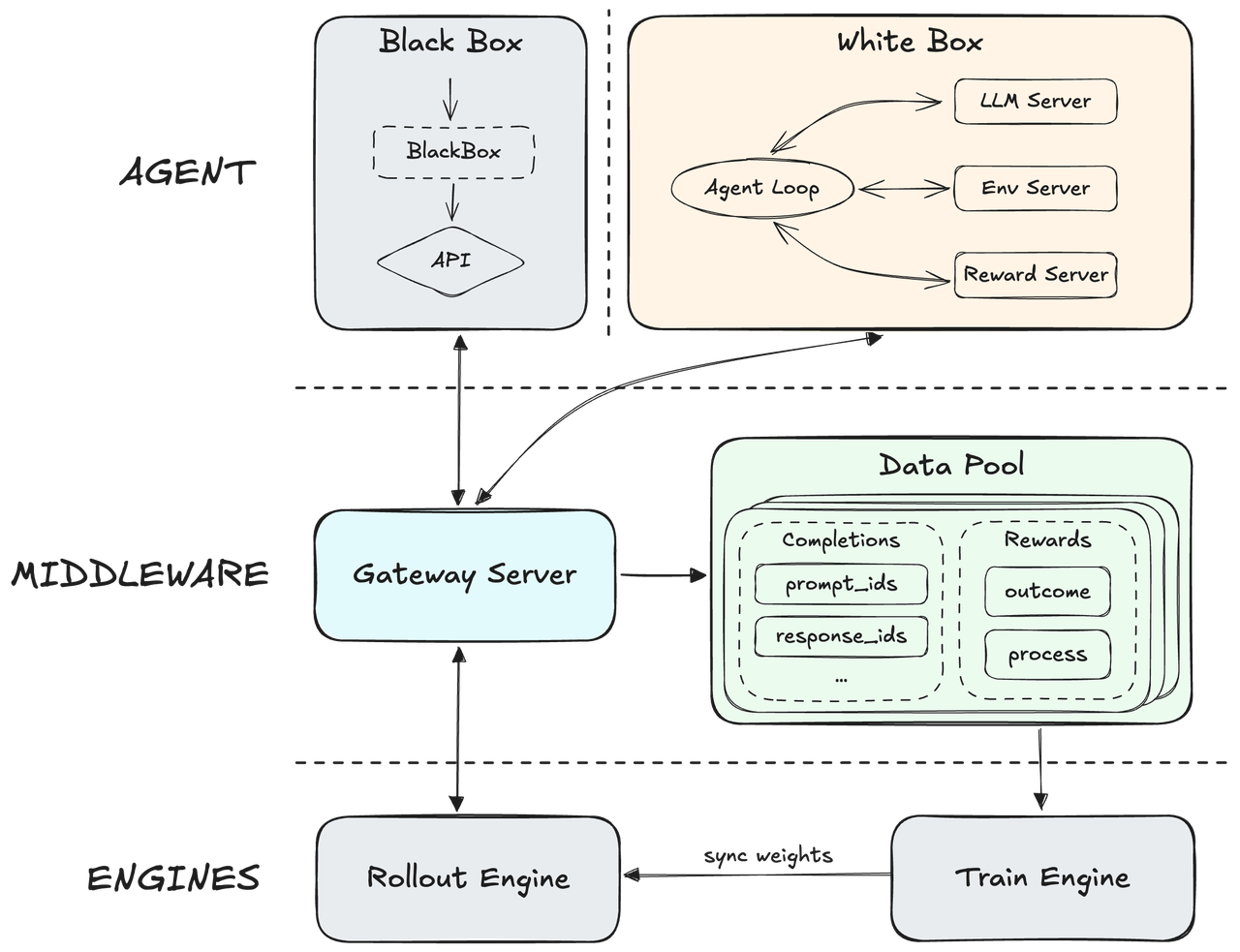
Costruito su un framework nativo Agent RL, MiniMax disaccoppia il suo motore centrale dall'impalcatura dell'agente per generalizzare attraverso centinaia di migliaia di diversi ambienti del mondo reale. Incorpora un sofisticato meccanismo di ricompensa del processo che utilizza il feedback di esecuzione in tempo reale per affinare i percorsi di ragionamento e garantire una qualità di output d'élite. Ciò crea un sistema altamente adattivo in grado di mantenere una precisione superiore massimizzando al contempo la velocità complessiva di risposta operativa.
Cosa Puoi Fare con MiniMax LLM Models
Scopri casi d'uso pratici e workflow che puoi costruire con questa famiglia di modelli — dalla creazione di contenuti e automazione alle applicazioni di livello produzione.
Debugging Full-Stack pronto per la produzione con MiniMax M2.5
MiniMax M2.5 agisce come un architetto tecnico senior, tracciando gli errori logici attraverso API backend, database e framework frontend come React o Swift. Invece di semplici snippet, rifattorizza interi moduli per garantire la compatibilità a livello di sistema. Ideale per la prototipazione rapida, l'API gestisce tutto, dalla configurazione dell'ambiente ai test dei casi limite e alla modernizzazione del codice legacy per i sistemi aziendali.
Modellazione finanziaria e reportistica professionale con MiniMax M2.5
Per gli analisti che richiedono una precisione assoluta, l'API automatizza la complessa modellazione finanziaria in Excel e genera rapporti di ricerca pronti per la pubblicazione seguendo quadri di investimento professionali. Interpreta i dati grezzi per costruire logiche di controllo del rischio e presentazioni professionali con formattazione standardizzata. Questo si adatta ad ambienti di consulenza e bancari ad alto rischio, dove l'accuratezza e il rispetto degli standard di reporting formale non sono negoziabili.
Ricerca web autonoma in più fasi con MiniMax M2.5
MiniMax M2.5 esegue compiti di ricerca complessi e multi-round per sintetizzare informazioni web disparate in brief esecutivi coesi. Decomponendo intelligentemente query ampie e navigando con una ridondanza di token minima, evita il ragionamento circolare per fornire fatti verificati. È uno strumento potente per i ricercatori di mercato e i team strategici che necessitano di intelligence approfondita senza filtrare manualmente centinaia di fonti.
Confronto Modelli
Scopri come si confrontano i modelli di diversi provider — confronta prestazioni, prezzi e punti di forza unici per una decisione informata.
| Modello | Contesto | Output massimo | Input | Posizionamento |
|---|---|---|---|---|
| MiniMax M2.5 | 196.61K | 196.61K | Testo | Programmazione agentica all'avanguardia |
| MiniMax M2 | 196.61K | 196.61K | Testo | Modello ad alte prestazioni |
| MiniMax M2 | 196.61K | 196.61K | Testo | Generale di punta |
| GLM-5 | 202.75K | 202.75K | Testo | Modello fondazionale di punta |
| DeepSeek V3.2 | 163.84K | 163.84K | Testo | Generale di Punta |
How to Use MiniMax LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Why Use MiniMax LLM Models on Atlas Cloud
Combining the advanced MiniMax LLM Models models with Atlas Cloud's GPU-accelerated platform provides unmatched performance, scalability, and developer experience.
Performance & flexibility
Low Latency:
GPU-optimized inference for real-time reasoning.
Unified API:
Run MiniMax LLM Models, GPT, Gemini, and DeepSeek with one integration.
Transparent Pricing:
Predictable per-token billing with serverless options.
Enterprise & Scale
Developer Experience:
SDKs, analytics, fine-tuning tools, and templates.
Reliability:
99.99% uptime, RBAC, and compliance-ready logging.
Security & Compliance:
SOC 2 Type II, HIPAA alignment, data sovereignty in US.
Domande Frequenti su MiniMax LLM Models
Offriamo tre versioni principali: MiniMax M2.5 (l'ammiraglia per la produttività d'ufficio e la ricerca), MiniMax M2.1 (potenziato per la programmazione e la logica complessa) e MiniMax M2 (il modello equilibrado per scopi generali).
La serie MiniMax M2 supporta uniformemente un contesto ultra-lungo di 196.61K, consentendo di elaborare centinaia di pagine di documentazione tecnica o enormi codebase ingegneristiche in una singola richiesta.
Nei test end-to-end di SWE-bench, M2.5 ha ridotto il tempo di elaborazione per compiti complessi da 31,3 a 22,8 minuti, segnando un aumento del 37% nella velocità complessiva di completamento delle attività.
Explore More Families
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
Grok-Imagine Models
Grok Imagine Image Quality is xAI's latest AI image generation model, delivering studio-grade visuals with up to 2K resolution and razor-sharp detail. It offers best-in-class text rendering across multiple languages, photorealistic outputs with natural lighting, rich textures, and believable physics, plus tighter prompt following and image editing with reference inputs for precise creative control. Ideal for hero images, ad creatives, product renders, and brand-grade visuals.
Gemini Omni
Gemini Omni (by Google DeepMind) is a video generation and editing model launched on May 20, 2026 at Google I/O that redefines the standard for "reasoning-driven creation," built specifically to solve the core challenge of AI video: making output that actually understands what you mean, not just what you type. It fuses Gemini's reasoning engine with generative capability, accepting any mix of images, text, video, and audio to produce consistent, knowledge-grounded output. Unlike models that start from scratch each time, Omni lets you edit through natural conversation — swapping objects, rewriting scenes, shifting styles — while keeping physics, characters, and continuity intact across every turn.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.


