
中国のAIラボは、現在利用可能な最も高性能なオープンソース・コーディングモデルのいくつかを静かに構築してきました。AnthropicやOpenAIの市場動向のみを追ってきた開発者にとって、DeepSeek、Moonshot、Zhipu、MiniMax、Alibabaが現在提供しているラインナップの広さは、間違いなく驚くべきものです。
2026年に問うべきは「これらのモデルが良いかどうか」ではありません。「どのモデルがどのワークロードに適しているか」「大規模運用におけるコストはいくらか」「既存のツールにどう組み込むか」という点です。本ガイドでは、ラボごとのプロフィール、スペックとコストの完全な比較表、実用的なユースケース別ルーティングガイド、そしてClaude Code、Codex、OpenClawの設定方法の3点をすべて網羅します。
![]()
なぜ最高のオープンソース・コーディングLLMが真剣に注目されているのか
転換点は、2024年12月にリリースされたDeepSeek V3でした。HumanEvalで89.1%、SWE-bench Verifiedで42.0%というスコアを記録し、当時のClaude 3.5 SonnetやGPT-4oに匹敵する性能を誇りました。しかも、オープンソースであり、6710億の全パラメータのうち推論ごとにわずか370億のパラメータのみをアクティブにする「Mixture of Experts(MoE)」アーキテクチャを採用していたのです(DeepSeek-V3 Technical Report、2024年12月)。このアーキテクチャが実現する効率性により、推論コストが劇的に低下した理由が説明されました。
この結果は、中国のより広範なオープンソース・エコシステムへ開発者の関心を引き寄せました。DeepSeekは特異な存在ではないことが判明しました。Moonshot AIのKimi K2シリーズは長文脈(ロングコンテキスト)ベンチマークで静かにリードし、AlibabaのQwen2.5-Coderシリーズはコーディング特化型のリーダーボードで上位を占め、ZhipuのGLM-5ラインはエージェントパイプラインに不可欠な精密な構造化出力を生成していました。
開発者にとっての実際的な結論は、現在5つの異なるラボが、プロプライエタリ(独自)な代替手段を大幅に下回る価格で、実運用可能なコーディングモデルをオープンウェイトまたは商用APIアクセスで提供しているということです。
最高のオープンソース・コーディングLLMを支えるラボ
DeepSeek: コーディング優先の設計とMoEの効率性
2023年設立でHigh-Flyer Capital(中国のクオンツヘッジファンド)の支援を受けるDeepSeek AIは、創業当初からコーディングに焦点を当ててモデルを構築してきました。DeepSeek-Coderは、オープンソースコミュニティから大きな注目を集めた最初のコーディング特化モデルの一つでした。V3およびV4シリーズでは、コーディングベンチマークの強力な性能を維持しつつ、一般的な推論能力へとその範囲を拡大しています。
MoEアーキテクチャは、その価格設定を理解する上で重要です。トークンごとにパラメータの一部のみをアクティブにすることで、同等の品質を持つ密な(dense)モデルよりもリクエストごとの計算コストが大幅に低くなります。その効率性がAPI価格に反映されているため、DeepSeek V4 Flashが単純なタスクで品質を犠牲にすることなく、1000トークンあたり0.23クレジットという入力レートを実現できています。
Moonshot AI (Kimi)、Zhipu AI (GLM)、MiniMax、Alibaba (Qwen)
Moonshot AI(2023年北京設立)は、長文脈推論でその名を馳せました。Kimi K2シリーズは262Kのコンテキストウィンドウを備え、大規模なコードベースを一度に処理する必要があるドキュメントやコード関連のタスク向けに設計されています。
Zhipu AI(2019年、清華大学KEG Labからスピンアウト)は、中国で最も歴史のあるAI企業の一つです。GLMシリーズは5世代にわたって進化し、反復ごとに構造化出力の信頼性と指示追従能力が向上しています。GLM-5.1は、正確なタスク実行に向けた長年の調整努力を反映したモデルです。
MiniMax(2021年設立)は、マルチモーダル領域から進出し、M2シリーズでコーディングモデルを強化しました。MiniMax M2.5およびM2.7は、ミッドティアのニーズを満たすコストと品質のバランスを提供しています。
AlibabaのQwenチームは、コーディング特化モデルの強力な系譜の上にQwen3.6-plusを構築しました。同シリーズは多言語コード生成において一貫して強力であり、256K以上のコンテキストウィンドウは利用可能な選択肢の中で最高水準に位置します(QwenLM GitHub、2025年)。
最高のオープンソース・コーディングLLM比較:コンテキスト、コスト、スペック
以下は、入力レート順に並べた現在のモデル一覧表です。コスト構造がひと目で分かるようになっています。
| モデル | ラボ | 文脈 | 入力レート | 出力レート | キャッシュ | 公式比 |
| DeepSeek V4 Flash | DeepSeek AI | 1M | 0.23 | 0.46 | 0.046 | -50% |
| DeepSeek V3.2 | DeepSeek AI | 160K | 0.42 | 0.62 | 0.193 | -55% |
| MiniMax M2.5 | MiniMax | 200K | 0.65 | 2.18 | 0.109 | -45% |
| Kimi K2.5 | Moonshot AI | 262K | 1.09 | 5.45 | 0.182 | -45% |
| Kimi K2.6 | Moonshot AI | 262K | 1.72 | 7.26 | 0.290 | -45% |
| GLM-5 | Zhipu AI | 200K | 1.82 | 5.81 | 0.363 | -45% |
| MiniMax M2.7 | MiniMax | 200K | 2.36 | 4.00 | 0.109 | -45% |
| GLM-5.1 | Zhipu AI | 200K | 2.54 | 7.99 | 0.472 | -45% |
| DeepSeek V4 Pro | DeepSeek AI | 1M | 2.87 | 5.75 | 0.231 | -50% |
| Qwen3.6-plus | Alibaba | 256K+ | 3.30 | 9.90 | 0.660 | -50% |
レートは1,000トークンあたりのクレジット数です。「公式比」は各モデルの直接API料金と比較した節約率です。
いくつかの点が際立っています。第一に、同じラボでありながらDeepSeek V4 Flash(入力0.23)とV4 Pro(入力2.87)の間には12.5倍の開きがあり、単一モデルファミリー内でもコストと性能の幅が広いことです。第二に、Kimi K2.5(入力1.09)は、ミッドティアの価格で262Kのコンテキストウィンドウを提供しており、V4 Proまで上げることなく長文脈作業を行いたい場合に魅力的です。第三に、Qwen3.6-plusの出力レート9.90はグループ内で最高であり、より長く徹底した補完作業を重視した設計であることがうかがえます。
各オープンソース・コーディングLLMの最適な活用シーン
ここでは実用面について解説します。上記のレートは、エージェント型のコーディングセッションを実行する際、どのようなルーティング判断を下すべきかを定義します。
軽量およびバックグラウンドタスク:DeepSeek V4 Flash ドキュメント作成、変数名の変更、単純なコード補完、フォーマット変換など、コーディングエージェントがバックグラウンドで自動的に行うユーティリティタスクに最適です。入力0.23、出力0.46というレートは、他を圧倒する安さです。Claude CodeなどでバックグラウンドタスクをHaikuモデルスロットに割り当てる際、ここをDeepSeek V4 Flashに向ければ、メインセッションに高性能モデルを使いつつ、不要なコストを抑えられます。
コスト効率重視のコーディング:DeepSeek V3.2 および MiniMax M2.5 DeepSeek V3.2は、V3アーキテクチャを公式レート比55%オフ、160Kのコンテキストウィンドウで利用できます。フルスペックのV4 Pro料金を払うことなく、堅実なコーディング性能を求める場合に実用的です。入力0.65のMiniMax M2.5も200Kウィンドウを備え、価格よりもコンテキストサイズが重要になるケースで重宝します。
長文脈ワークロード:Kimi K2.5 および K2.6 どちらも262Kのコンテキストウィンドウを提供します。コードベースの大部分を読み込ませる、長期間の会話履歴を分析する、あるいは複数ファイルにわたるリファクタリングなど、すべてを1つのコンテキスト内に収める必要がある場合に最適です。K2.5はコストを抑えつつウィンドウを確保でき、K2.6(入力1.72)は品質がより重要なケースに適しています。
構造化出力と指示の正確性:GLM-5 および GLM-5.1 Zhipu AIのGLMモデルは、指示に従う能力に秀でています。確実な構造化出力(特定のJSONスキーマ、コードアーティファクト、一貫したAPIレスポンス形式)が必要なパイプラインでは、GLM-5および5.1のテストを推奨します。出力レートが高めなのは、より徹底的で詳細な回答を生成する傾向があるためです。
最高峰の推論:DeepSeek V4 Pro および Qwen3.6-plus 複雑なアーキテクチャの決定、複数システム間の連携デバッグ、あるいは「初回生成の品質が重要(低品質な草案は再試行コストを生むため)」なタスクでは、V4 ProとQwen3.6-plusがトップティアです。V4 Proは1Mというコンテキストウィンドウが最大の特長であり、Qwen3.6-plusはDeepSeekファミリー以外で256K超えの選択肢として最有力です。
モデルルーティング:最も活用されていない最適化戦略
オープンソース・コーディングLLMを活用する開発者にとって、最も高いレバレッジを生む最適化は「最高の一つのモデルを選ぶこと」ではありません。一つのセッションの中で、タスクの種類に応じてモデルを切り替える(ルーティングする)ことです。
典型的なエージェントによるコーディングセッションを考えてみましょう。アプローチの計画(複雑、V4 Proが必要)、コアアルゴリズムの記述(複雑、V4 Pro)、テストケース生成(ミッドティア、MiniMax M2.5またはKimi K2.5)、新規関数のドキュメント記述(軽量、V4 Flash)、ファイル読み込み観察(軽量、V4 Flash)。すべてV4 Proで行った場合、軽量なステップごとに12.5倍ものコストを無駄にすることになります。
計算は簡単です。1セッション50回のAPIコールのうち60%(30回)が単純なタスクで、各2,000トークンの入力+500トークンの出力だった場合:
- V4 Flash利用:30回 × (2,000 × 0.23 + 500 × 0.46) = 30 × (460 + 230) = 20,700クレジット
- V4 Pro利用:30回 × (2,000 × 2.87 + 500 × 5.75) = 30 × (5,740 + 2,875) = 258,450クレジット
その差は12.5倍。ルーティングによるコスト削減は即座に効果を発揮します。
ワークフローに最適なオープンソース・コーディングLLMの選び方
状況別の決定木を以下に示します。
- リクエストごとに最大のコンテキストが必要: DeepSeek V4 Pro (1M) または Qwen3.6-plus (256K+)。チャンク分割なしで大規模なコードベースを扱えます。
- コストが最大の制約条件: 単純なタスクにはDeepSeek V4 Flash、中程度の複雑さにはDeepSeek V3.2またはMiniMax M2.5。
- 信頼性の高い構造化出力が必要: GLM-5.1から試して、特定のスキーマ要件に適合するか確認してください。
- 多段階のエージェントパイプラインを構築している: ステップの複雑さでルーティングします。ユーティリティにはFlash、中程度の推論にはKimi K2.5やGLM-5、計画やデバッグにはV4 Proを使用します。
- 最初に試す単一モデル: 開発者が初めて中国LLMを評価する場合、DeepSeek V4 Proが自然な標準です。ドキュメントが豊富で、コミュニティ(r/LocalLLaMA)でのカバー範囲も広く、最高峰のコーディング品質を実現します。
実用上の注意点として、効率的にルーティングするには、すべてのモデルを同一のAPIキーとベースURLの背後に置く必要があります。10個もの個別のAPIアカウントを管理するのは現実的ではありません。これこそが統合ゲートウェイの利点です。一つのエンドポイントとキーで、モデル選択はパラメータで指定するだけです。
コーディングツールでの実行方法
Atlas Cloud コーディングプランは、このガイドで取り上げた全10モデルを単一のAPIキーとベースURLで利用可能にし、直接契約比45-55%オフで提供します。各主要ツールでの設定は以下の通りです。
ベースURLに関する重要事項: Claude Codeは /v1 サフィックスなしの https://api.atlascloud.ai を使用します。それ以外のツール(Codex、OpenClaw、OpenCode、Cursorなど)は /v1 を付けた https://api.atlascloud.ai/v1 を使用します。これを間違えると、原因が分かりにくい認証エラーが発生します。
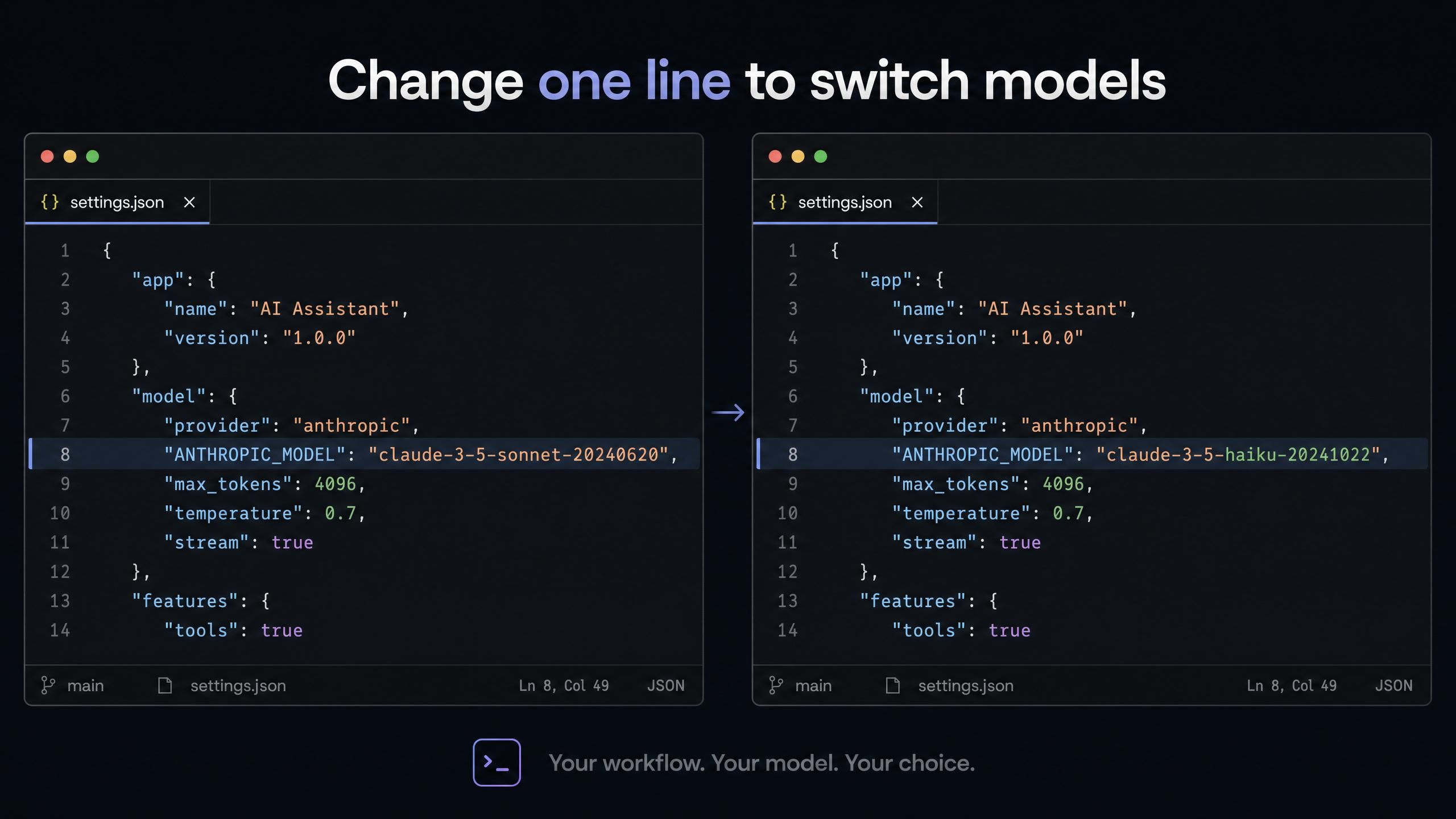
Claude Code (~/.claude/settings.json):
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "deepseek-ai/deepseek-v4-pro", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-ai/deepseek-v4-flash", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-ai/deepseek-v4-pro", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
ANTHROPIC_DEFAULT_HAIKU_MODEL はClaude Codeのバックグラウンドタスクスロットに対応します。ここにDeepSeek V4 Flashを指定すれば、自動的なユーティリティ呼び出しはすべて最安モデルで行われます。メインのプロンプトはV4 Proが担い、明示的なルーティングロジックなしで自動的に最適化されます。
Codex (~/.codex/config.toml + ~/.codex/auth.json):
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-pro" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
OpenClaw: OpenClawを起動し、QuickStartからCustom Providerを選択。ベースURLに https://api.atlascloud.ai/v1 を入力し、キーを貼り付け、モデルID(例: moonshotai/kimi-k2.5)を入力してOpenAI互換プロトコルを選択します。
設定の切り替えは1行の変更で済み、APIキーとベースURLはそのまま維持されます。
よくある質問
DeepSeekが最高のオープンソース・コーディングLLMですか? コミュニティでの扱い、ベンチマーク実績、1Mコンテキストと価格のバランスを考えると、DeepSeek V4 Proが最初の選択肢として最適です。しかし「最高」はタスクに依存します。長文脈ならKimi K2.5/K2.6、構造化出力ならGLM-5.1が優れています。「最高」は構築するものに応じて変化します。
Claude SonnetやGPT-4oと比べてどうですか? 標準的なベンチマークでは、トップクラスのオープンソースとプロプライエタリな米国モデルの差は2024年以降大幅に縮まっています。DeepSeek V3はリリース時点でいくつかのベンチマークでClaude 3.5 Sonnetに匹敵しました。米国モデルの強みは、微妙な指示の解釈や広範なRLHF(人間からのフィードバックによる強化学習)による微調整にありますが、日常的なコーディングやデバッグにおいて開発者が感じる実用上の差はわずかです。
同じパイプラインで複数のオープンソースLLMを使えますか? はい。ゲートウェイ経由で共有のベースURLとキーを使えば、リクエストごとにモデルIDを指定可能です。Flashでユーティリティ、Kimiで長文脈、Proで推論、といった使い分けを同一セッション内で実現できます。
初めてオープンソースLLMを使うならどれがいいですか? まずはDeepSeek V4 Proから始めてください。ドキュメントが最も多く、コミュニティでの議論も活発で、性能プロファイルも明確です。ベースラインができたら、Kimi K2.5やV4 Flashでのテストを検討してください。そのコスト差を見れば、ルーティングがあなたのワークフローにどれほど貢献するかがわかるはずです。
エンタープライズコードでの利用は安全ですか? サードパーティのゲートウェイ経由のAPIアクセスの場合、そのゲートウェイのデータ取扱方針に従います。自社ホスト可能なオープンウェイトモデルであれば、コードの場所を完全に管理できます。r/LocalLLaMAでの一般的な見解は、APIベースの利用については、他社のAPIと同様のデータセキュリティ精査を行えば問題ないというものです。
結論
現在、5つのラボが実運用に耐えうるコーディングモデルを提供しており、コストと能力の幅が広いため、一つのモデルに固執するのは賢明ではありません。
実用的な戦術は、一つのキーで全モデルにアクセスできるゲートウェイを選び、DeepSeek V4 Proでベースラインを確立し、上記のルーティングガイドを使って単純なタスクをより安価な層へシフトすることです。エージェント型のコーディングを行う開発者にとって、そのルーティングだけで、品質を犠牲にすることなくコストを大幅に削減できるはずです。
モデルスペックおよびレートは2026年5月時点のAtlas Cloud Coding Planドキュメントに基づきます。DeepSeek V3のベンチマーク数値はDeepSeek-V3テクニカルレポート(2024年12月)より。料金は変更される可能性があるため、契約前に各プロバイダーの最新数値を確認してください。






