
コーディング、推論、またはエージェント型パイプラインのためにオープンソースモデルを評価しているなら、Kimi K2.6とGLM 5.1の両方が候補に挙がるはずです。どちらも中国の主要なAIラボが開発したモデルであり、OpenAI互換APIで動作し、開発者が真に必要とする複雑なタスクをこなす能力を備えています。
問題は、両者が完全な代替品ではないという点です。コンテキストウィンドウ、コスト構造、そして特定のユースケースで発揮される強みがそれぞれ異なります。ワークロードに適さないモデルを選択すると、パフォーマンスを最大限に引き出せなかったり、不要な容量に対して過払いが発生したりすることになります。
本記事では、この2つのモデルの真の違いを解き明かします。スペックが実運用で何を意味するのか、それぞれのモデルが得意とする領域と不得意な領域、そして両者を大規模に運用した場合のコスト数値について詳しく解説します。

Kimi K2.6 vs GLM 5.1: クイックサマリー
Kimi K2.6は、Moonshot AIが現在フラッグシップラインとして展開しているK2シリーズの最新モデルです。MoonshotはAIアシスタント「Kimi」の開発元であり、K2.6は長文脈の推論と競争力のある価格設定を武器にしています。262Kトークンのコンテキストウィンドウが最大の特長です。
GLM 5.1は、中国でも特に実績のあるAI研究組織であるZhipu AIが提供しています。GLM(General Language Model)シリーズは世代を重ねて進化しており、5.1はZhipuの現在の最高峰モデルです。命令追従の正確さと構造化データの出力品質において、オープンソースコミュニティから高い評価を得ています。
どちらのモデルもOpenAI互換APIを提供しているため、Claude Code、Codex、OpenClawなどのツールへの接続は容易です。両者の選択は、リクエストごとの必要なコンテキスト量、想定ボリュームでのトークンコスト、そしてタスクが各モデルの得意分野に合致しているかという3つの要素で決まります。
モデルの背景
Kimi K2.6 vs GLM 5.1 コンテキストウィンドウの比較
コンテキストウィンドウは、最も明確かつ客観的な差別化要素です。Kimi K2.6は262Kトークン、GLM 5.1は200Kトークンをサポートしており、最大入力容量には31%の開きがあります。
典型的なコーディングタスクでは、日常的にこれらの制限に達することはまずありません。標準的なコードレビュー、デバッグセッション、ドキュメント生成のリクエストであれば、両方のウィンドウサイズに十分に収まります。この差が重要になるのは、以下のような特定のシナリオです。
- 大規模なコードベースの解析: リファクタリングやアーキテクチャレビューのために、数万行のコードを1つのリクエストで渡す場合
- 長時間稼働するエージェントセッション: 多数のターンとツール呼び出しを通じて大量のコンテキストが蓄積される会話
- ドキュメント集約型のパイプライン: 1回のコールで膨大なテキスト塊を読み込む必要があるリサーチ、要約、分析タスク
もし普段のワークロードが他のモデルでコンテキスト制限に近いのであれば、Kimi K2.6の262Kウィンドウは、チャンク分割や要約ロジックを実装する手間を軽減する余裕を与えてくれます。一方で、通常のリクエストが50Kトークン以下であれば、両モデルとも十分な容量を持っており、ウィンドウの差は検討材料になりません。

コーディングと推論の強み
両モデルともコーディングタスクをこなせますが、設計思想の違いにより実用面での挙動が異なります。
Kimi K2.6は「長文脈の理解」を重視して構築されています。そのため、複数ファイルにまたがるリファクタリングや、コードの一部変更が他にどのような影響を与えるかの把握、そして多くのステップを通じて状態を保持する必要がある高度な推論チェーンに適しています。Moonshot AIは、K2.6をまさにこうしたユースケース向けに位置付けています。
一方、GLM 5.1は、Zhipu AIが注力する「正確な命令追従」と「構造化出力」が強みです。詳細な仕様書に基づくコード生成、自然言語からの構造化フォーマット出力、複雑なツール呼び出しスキーマの管理などはGLM 5.1が得意とするところです。価格設定における出力レートがやや高い(7.99対7.26)ことからも、より緻密で詳細な補完を行う傾向が読み取れます。
これら2つのモデルを比較するほとんどの開発者にとって、一般的なコーディングタスクにおけるパフォーマンス差は、会社名のブランドイメージから受ける印象よりも実際には小さいものです。より明確な差別化要素は、スペックと具体的な数値として表れるコストにあります。
Kimi K2.6 vs GLM 5.1: トークンコストとクレジットレート
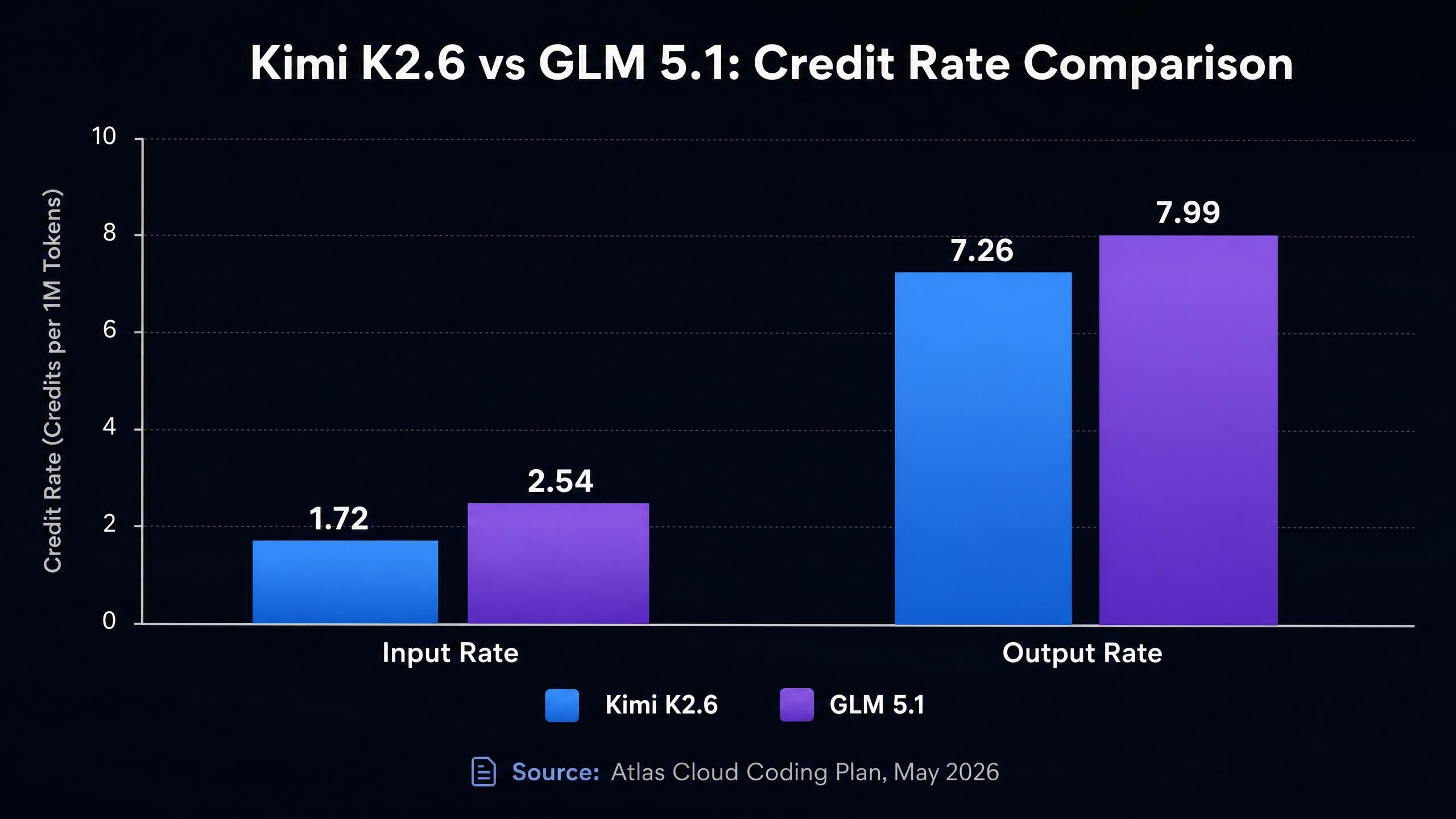
比較はここからが本番です。両モデルともAtlas Cloud Coding Planを通じて利用可能であり、クレジットレートは以下の通りです(Atlas Cloud Coding Plan、2026年5月時点)。
| モデル | コンテキスト | 入力レート | 出力レート | キャッシュ書き込み | 公式比 |
|---|---|---|---|---|---|
| Kimi K2.6 | 262K | 1.72 | 7.26 | 0.290 | 45%OFF |
| GLM 5.1 | 200K | 2.54 | 7.99 | 0.472 | 45%OFF |
いくつか注目すべき点があります。
GLM 5.1の入力レート(2.54)は、Kimi K2.6(1.72)より約48%高くなっています。ファイル内容や膨大なコード履歴、蓄積された会話など、入力トークンがコストの大部分を占めるコーディング作業においては、この差は大きいです。1日1,000リクエスト、各10Kトークンの入力があるパイプラインの場合、GLM 5.1はKimi K2.6に比べて入力コストだけで約48%余計にかかることになります。
出力レートの差は縮まりますが、それでもKimi K2.6の方が有利です(7.26対7.99、約10%の差)。キャッシュ書き込みレートでもKimi K2.6が有利(0.290対0.472)であり、プロンプトキャッシュを多用するワークフローではさらに差が開きます。
まとめると、入力トークン5,000、出力トークン1,000のリクエストの場合、コストは以下のようになります。
- Kimi K2.6: (5,000 × 1.72) + (1,000 × 7.26) = 8,600 + 7,260 = 15,860 クレジット
- GLM 5.1: (5,000 × 2.54) + (1,000 × 7.99) = 12,700 + 7,990 = 20,690 クレジット
この入力/出力比率では、Kimi K2.6がリクエストあたり約23%安価になります。高ボリュームで運用する場合、これが予算上の顕著な差となります。
なお、両モデルともAtlas経由では公式APIレートより45%安価に提供されています。
エージェント型コーディングワークフローにおける活用
エージェントツールを使用すると、モデル間のコストや能力の違いが増幅されます。
マルチステップのエージェントでは、各ツール呼び出しが独立したAPIリクエストとなります。全てのリクエストは蓄積されたコンテキストを含み、次ステップへの入力を生成し、合計コストに加算されます。セッション内で40回のAPI呼び出しを行うワークフローでは、単発リクエストの40倍の価格になるだけでなく、コンテキストが急速に蓄積されるため、セッションが進むにつれて入力トークン数も増大します。
エージェント用途でKimi K2.6が適している場面: 蓄積されたコンテキストが大きくなる長時間セッション、大規模なコードファイルの読み込みと修正、多数の呼び出しを通じてコストを抑えることが重要なパイプライン。コンテキストウィンドウが広いため、エージェントのワーキングメモリを損なうセッションリセットの回数を減らせます。
エージェント用途でGLM 5.1が適している場面: 各ステップで正確かつ構造化された出力が求められ、セッション全体のコンテキスト深度よりも個々の呼び出しにおける命令の正確さが重要なパイプライン。厳格な型スキーマに基づいたコード生成や、複雑な関数シグネチャの管理が必要な場合、GLM 5.1の命令追従能力がより直接的に貢献します。
どちらのモデルも、標準的なOpenAI互換設定を通じてClaude Code、Codex、OpenClaw、Cursorでスムーズに動作します。モデルIDを変更するだけでよく、統合の手間は同じです。
どちらを選ぶべきか
実践的な検証方法
どちらが良いか判断する最も確実な方法は、比較記事を読むことではなく、実際に自分のタスクで両方を試して品質を比較することです。幸いなことに、同じAPIキーとベースURLの下で両モデルが利用可能な環境であれば、これは非常に簡単です。
Atlas Cloud Coding Planは、Kimi K2.6とGLM 5.1を単一のAPIキーで利用できます。設定の書き換えは1行で済むため、統合をやり直すことなく、両モデルで実際のワークロードを交互に実行して比較できます。
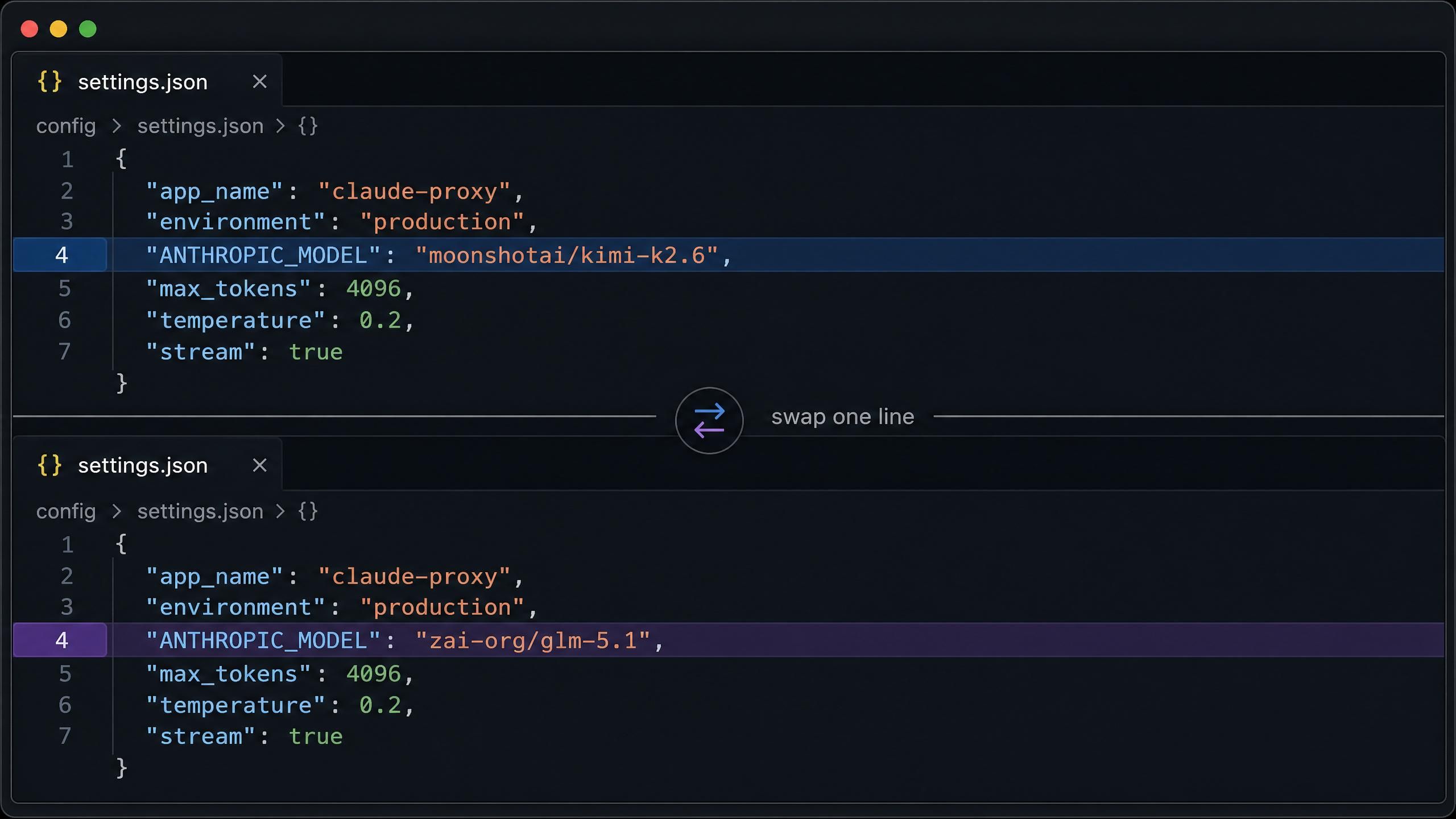
macOS/Linuxの Claude Code の場合、設定は ~/.claude/settings.json に記述します。まずはKimi K2.6を設定します:
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "moonshotai/kimi-k2.6", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "moonshotai/kimi-k2.6", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "moonshotai/kimi-k2.6", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
GLM 5.1に切り替えるには、3つのモデルフィールドを moonshotai/kimi-k2.6 から zai-org/glm-5.1 に変更するだけです。Claude CodeのベースURLは /v1 を含めない https://api.atlascloud.ai である点に注意してください。
Codex の場合は、以下の2ファイルに分けて設定します。~/.codex/config.toml:
plaintext1model_provider = "atlas_coding_plan" 2model = "moonshotai/kimi-k2.6" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
~/.codex/auth.json:
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
OpenClaw の場合は、openclaw onboard を実行し、「QuickStart」を選択後、「Custom Provider」を選びます。ベースURLに https://api.atlascloud.ai/v1 を入力し、Atlasキーを貼り付け、テストしたいモデルIDを選択してください。
Atlas Cloudプランには、月額サブスクリプション(安定した日次利用向け)と、90日有効のプリペイドパック(実験的・変動的なワークロード向け)の2種類があります。両モデルをテストする場合は、柔軟性の高いプリペイドパックをおすすめします。
よくある質問
Q: 大規模運用でコストが低いのはどちらですか? A: Kimi K2.6の方が入力・出力ともにトークン単価が安いです。特にコーディングワークフローで重要な入力コストの差が大きく(GLM 5.1はKimiより約48%高い)、リクエスト数が増えるほど予算への影響は大きくなります。
Q: 中国語のタスクにはどちらが向いていますか? A: 両モデルとも中国語能力は高いですが、Zhipu AIのGLM 5.1はシリーズを通じて長年中国語処理の実績を積み上げてきた歴史があります。Kimi K2.6も中国語ユーザー向けに最適化されているため、どちらも優れていますが、実績ベースではGLM 5.1に一日の長があります。
Q: 同じパイプラインで両方のモデルを混在させられますか? A: はい。APIゲートウェイを使用すれば、リクエストごとにモデルパラメータを変更して使い分けが可能です。例えば、コンテキスト解析にはコスト効率の良いKimi K2.6、構造化出力の生成には精度に優れたGLM 5.1を割り当てるといったことが、単一のAPIキーで可能です。
Q: 262Kと200Kというコンテキストウィンドウの差は無視できますか? A: 日常的なコーディングタスクのほとんどでは無視して構いません。差が意味を持つのは、セッションで頻繁に150K〜200Kトークンを消費する場合や、長時間エージェントをリセットせずに動かす場合です。通常のリクエストが50K以下であれば、判断材料にはなりません。
Q: Claude Codeでの動作に特別な設定は必要ですか?
A: 基本的には上述の設定のみで十分です。OpenAI互換フォーマットをサポートするゲートウェイであれば正常に接続されます。ただし、Claude Codeは /v1 を含まないベースURLを指定する必要がある点だけ注意してください。
結論
この2つのモデルのどちらを選ぶかは、「優劣」よりも「ワークロードへの適合性」の問題です。
Kimi K2.6は、よりコスト効率に優れたデフォルトの選択肢です。トークンあたりの単価が安く、コンテキスト容量も大きく、コーディングエージェントが生成する大量の入力や長文脈タスクに最適です。大規模なコードベースでコストを最適化したいなら、数字の面でKimi K2.6が勝ります。
GLM 5.1は、正確な指示追従と一貫性のある構造化出力が求められるタスクにおいて、わずかに高い価格に見合う価値を提供します。コンテキスト量よりも、ステップごとの出力精度を重視するなら、自身のタスクでテストする価値があります。
実践的な推奨アプローチは、コスト優位性とコンテキストウィンドウの大きさでまずはKimi K2.6から開始することです。実際のワークロードを流してみて、構造化出力の品質に疑問がある場合にGLM 5.1を試すのが効率的でしょう。Atlas Cloud Coding Planであれば、公式価格の45%OFFで両モデルを同じAPIキーで試せるため、検証コストを抑えながら納得のいく選択が可能です。
モデルスペックおよびクレジットレートは、2026年5月時点のAtlas Cloud Coding Planのドキュメントに基づいています。モデルの能力はMoonshot AIおよびZhipu AIによる公開情報に基づきます。料金は変更される可能性があるため、各提供元の最新情報を確認してください。






