AIビデオ生成APIは扱いにくいという評判がありますが、それにはもっともな理由があります。テキスト補完の場合、問題が発生すれば即座に400エラーが返されますが、ビデオレンダリングは異なり、予測不可能な要素が多く含まれます。ジョブが警告なしにGPUキューで永遠に待機し続けることもあれば、要求したクリップの半分しか戻ってこないこともあります。また、レンダリングが完璧に完了しても、最終的なビデオが物理的に不可能だったり、歪んでいたりすることさえあります。
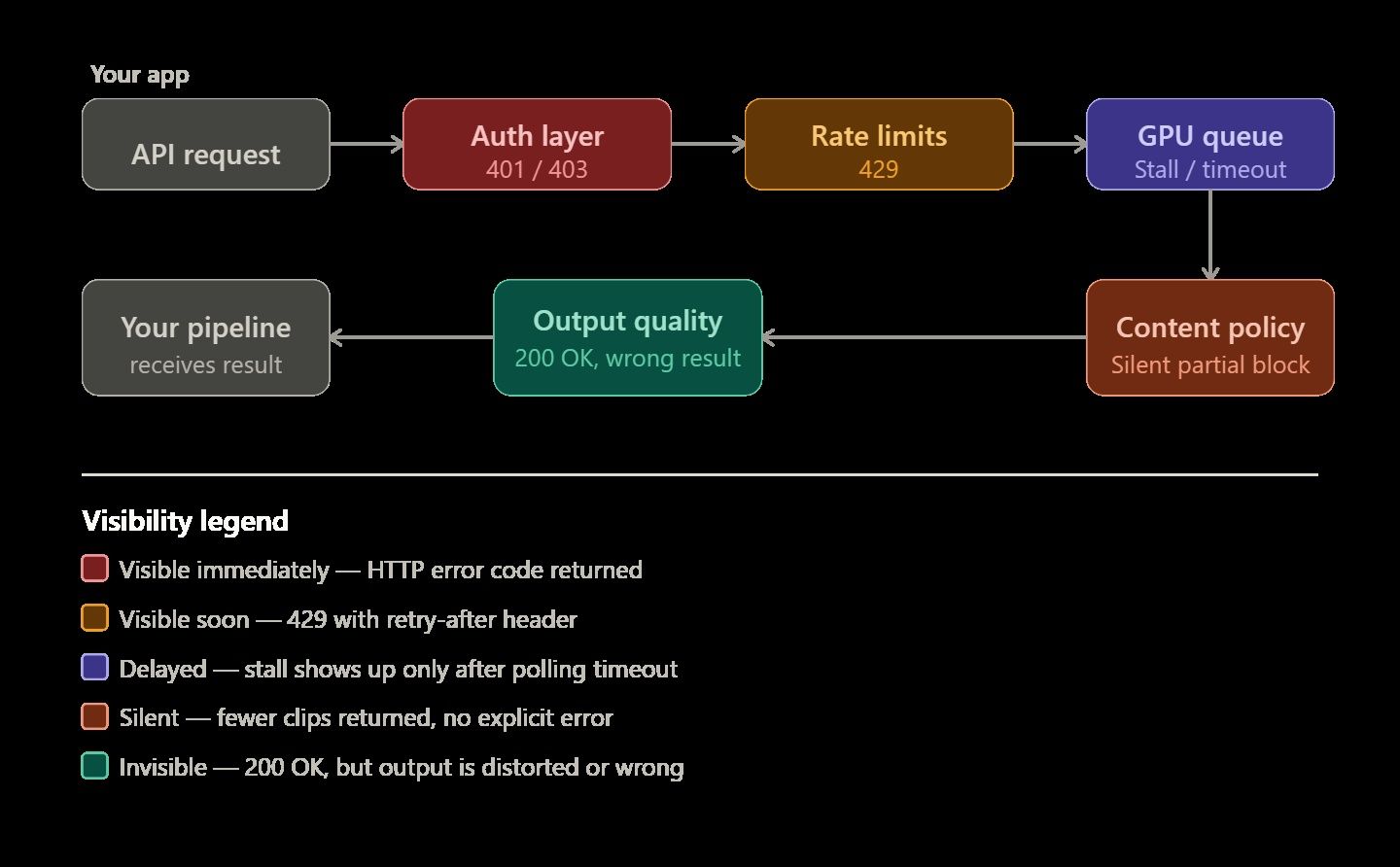
信頼性の高いシステムを構築するには、なぜこれらの特定のエラーが発生するのかを理解する必要があります。この知識こそが、単なるデモと、実際のユーザーにとって実用的なビデオパイプラインの決定的な違いとなります。
本ガイドでは、最も一般的な失敗モード、APIレスポンスの正確な読み方、そしてコストを抑えつつ故障率を低減するビデオレンダリングパイプラインの構築戦略を解説します。コード例では、300以上のビデオおよびマルチモーダルモデルを単一エンドポイントで利用できる統合推論プラットフォーム「Atlas Cloud API」を使用しており、マルチモデルパターンの参考として最適です。
AIビデオAPIエラーの5つのカテゴリ
AIビデオパイプラインのエラーは、通常5つのカテゴリに分類されます。適切なカテゴリを把握することで、コードの修正、プロンプトの書き換え、あるいは単に待機するといった対応を迅速に行うことができます。
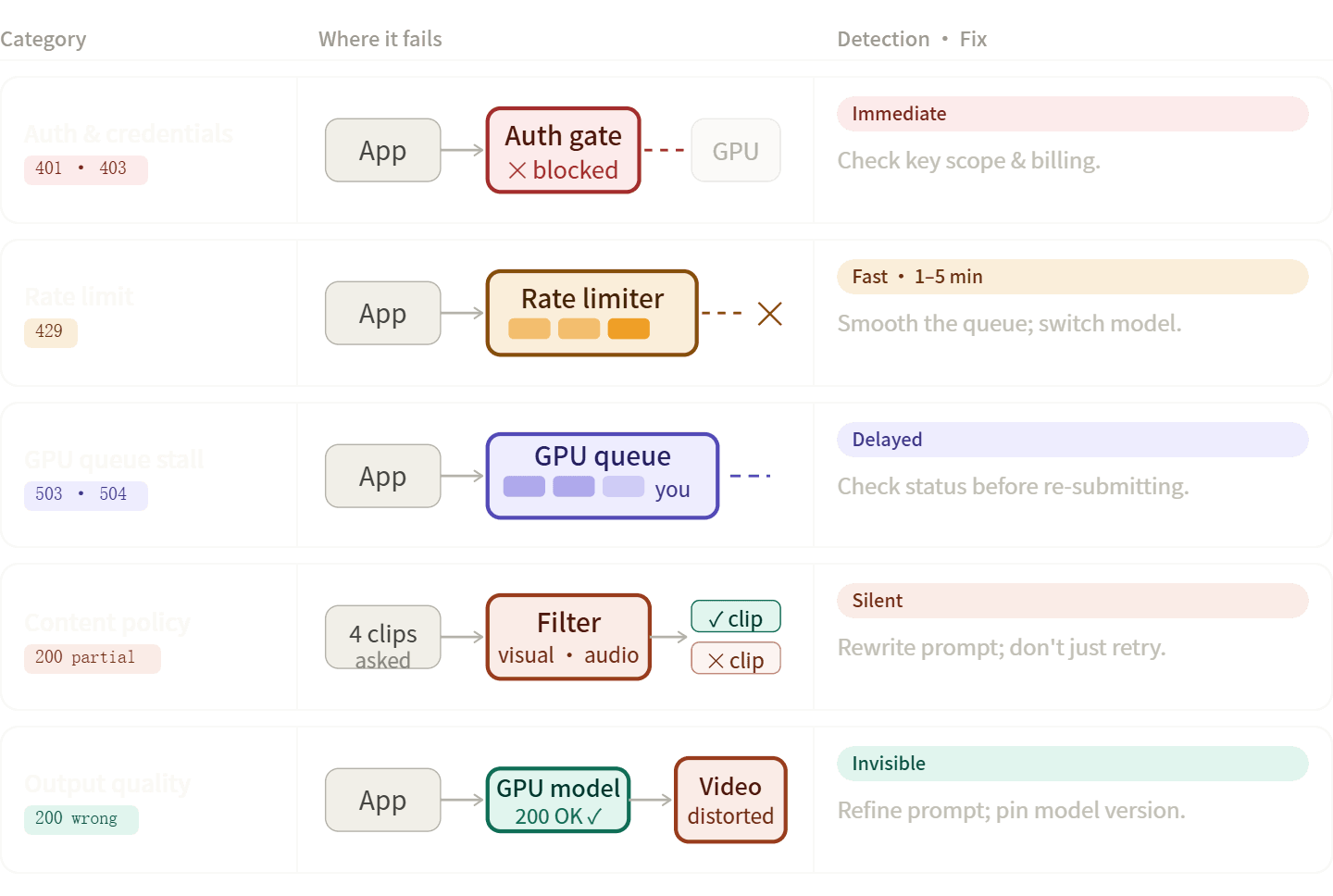
認証および資格情報エラー(401, 403)
| コード | 一般的な原因 | 修正方法 |
| 401 Unauthorized | Authorization: Bearer ヘッダーの欠落または形式ミス | ハードコーディングではなく環境変数からキーを読み込む |
| 403 Forbidden (クォータ) | APIクレジットの枯渇 | 請求設定の追加またはプランのアップグレード |
| 403 Forbidden (権限) | 要求したモデルに対するスコープ不足 | 正しい権限を持つキーの再生成 |
ここでは混同が起きやすいため注意が必要です。クォータ制限による403と、権限拒否による403は同じコードですが、修正方法は異なります。ステータスコードだけでなく、ボディ内の完全なエラーメッセージを必ず確認してください。
Atlas Cloudのようなプラットフォームでは、1つのAPIキーですべてのモデルをカバーできるため、「プロバイダーAのキーは動作するが、プロバイダーBのキーは期限切れ」といった認証ドリフトは発生しません。
レート制限エラー(429)
ビデオAPIにおけるレート制限は、テキストAPIよりも厳格です。各リクエストが30〜90秒間GPUスロットを占有するため、わずかな同時リクエストでも、一見余裕があるように見える制限を超えてしまうことがあります。
まず確認すべき重要な区別:
- RPM: GoogleのVeo 3.1 APIのプロダクションモデルでは50 RPM、プレビューモデルでは1プロジェクトあたり最大10 RPM(最大10同時リクエスト)に制限されています。
- 同時リクエスト制限: RPM予算内であっても、同時接続数上限に達すると429エラーが発生します。
- TPM (トークン/分): ビデオでは一般的ではありませんが、モダリティ間で請求が統合されているプラットフォームでは関連します。
有効な対策:
| 手法 | 有効なケース | 無効なケース |
|---|---|---|
| 指数バックオフ + リトライ | 一時的なバーストによる429 | 同時接続数が根本的な上限の場合 |
| バーストスムージング / キューイング | 大量バッチパイプライン | 低遅延が求められるインタラクティブUX |
| オフピークスケジューリング | 事前生成ワークフロー | リアルタイム生成 |
| 負荷の低いモデルへのルーティング | 複数の同等モデルを持つ統合プラットフォーム | 単一プロバイダー環境 |
コンテンツポリシーと安全フィルターによる拒否
APIレスポンスが明確なエラーではなく、「要求した数より少ないクリップが返される」という形で現れることが多いため、誤診しがちです。GoogleのVeoのドキュメントには、要求した数よりも少ないビデオが返された場合、リクエスト全体がトランスポート層で失敗したのではなく、一部の出力が安全フィルターによってブロックされた可能性があると明記されています。
2つの異なるトリガー:
- 視覚的プロンプト: 主題、シーンの背景、あるいは暴力・不適切なコンテンツの示唆。
- 音声/対話プロンプト: 音声コンテンツ、楽曲リクエスト、密度が高い音響環境は別のフィルター群をトリガーします。
プロンプトに音声が含まれる場合のみ失敗するなら、視覚シーンとは別にデバッグしてください。ポリシー違反でブロックされたプロンプトを再試行しても解決することは稀です。プロンプト自体の変更が必要です。
トランスポートおよびインフラエラー(500, 503, 504)
| コード | 一般的な解決時間 | 推奨アクション |
|---|---|---|
| 429 RESOURCE_EXHAUSTED | 1〜5分 | バックオフしてリトライ |
| 503 Service Unavailable | 30〜120分 | 待機し、ステータスダッシュボードを確認 |
| 504 Gateway Timeout | 不定 | 再送前にレンダリングが処理中か確認 |
| 500 Internal Server Error | 不定 | 予測IDを記録し、ステータス確認なしに自動リトライしない |
500/504エラーにおける鉄則は、再送前にレンダリングが進行中かどうかを確認することです。盲目的なリトライは、レンダリングの重複と二重課金を招きます。
出力品質の問題
これらはHTTPエラーではなく、APIは200を返しますが、出力結果が期待通りでない状態です。
- 視覚的アーティファクトや幾何学的な不正確さ: AIビデオは確率論的であり、物理計算ではなく入力の解釈を行っているためです。
- 音声対応モデルでの音声欠落: 通常はインフラの問題ではなく、プロンプトやパラメータの問題です。
- 期間や解像度の不一致: サポートされていない組み合わせによるものです。
- パイプラインの沈黙: 特定の形式でビデオが静かに破棄される場合があり、QA段階で初めて発覚します。
非同期レスポンスの読み方:予測IDとステータス調査
AIビデオ生成は設計上非同期です。リクエスト・レスポンスサイクルは2つのフェーズに分かれます。
- POST(生成エンドポイントへ)→
prediction_idを受け取る - GET(結果エンドポイントへ)→ 完了状態になるまでポーリングする
Atlas Cloudのレスポンススキーマが示す、完了した予測の例です。
plaintext1{ 2 "id": "pred_abc123", 3 "status": "completed", 4 "model": "bytedance/seedance-2.0/text-to-video", 5 "outputs": ["https://storage.atlascloud.ai/outputs/result.mp4"], 6 "metrics": { "predict_time": 45.2 }, 7 "created_at": "2025-01-01T00:00:00Z", 8 "completed_at": "2025-01-01T00:00:45Z" 9}
3つの最終状態:
| ステータス | 意味 | アクション |
|---|---|---|
| completed | レンダリング成功、出力利用可能 | 有効期限内にダウンロード |
| failed | レンダリング失敗、エラーフィールドを確認 | エラーメッセージを記録し、リトライを判断 |
| expired | 出力は利用不可 | 必要であれば再リクエスト |
よくあるポーリングのミス
開発者は「failed」ステータスを確認しますが、その後の「error」フィールドを読み飛ばしがちです。ここには実行可能な情報が含まれており、プロンプトを修正すべきか、クォータを確認すべきか、あるいはインフラの不調を待つべきかを判断する鍵となります。
プロダクション環境向けのポーリングパターン
plaintext1import time 2import requests 3 4def poll_prediction(prediction_id: str, api_key: str, max_wait: int = 600) -> dict: 5 url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 6 headers = {"Authorization": f"Bearer {api_key}"} 7 terminal_states = {"completed", "failed", "expired"} 8 wait = 5 9 10 for _ in range(max_wait // wait): 11 resp = requests.get(url, headers=headers).json() 12 status = resp.get("status") 13 14 if status in terminal_states: 15 if status == "failed": 16 print(f"Render failed: {resp.get('error')}") 17 return resp 18 19 time.sleep(wait) 20 wait = min(wait * 1.5, 60) # 最大60秒でキャップ 21 22 raise TimeoutError(f"Prediction {prediction_id} did not complete within {max_wait}s")
すべての完了レンダリングで metrics.predict_time をログ記録してください。この値の急増は、インフラの劣化を示す先行指標となり、致命的なエラーが発生する前に対応を可能にします。
堅牢なレンダリングパイプラインの構築
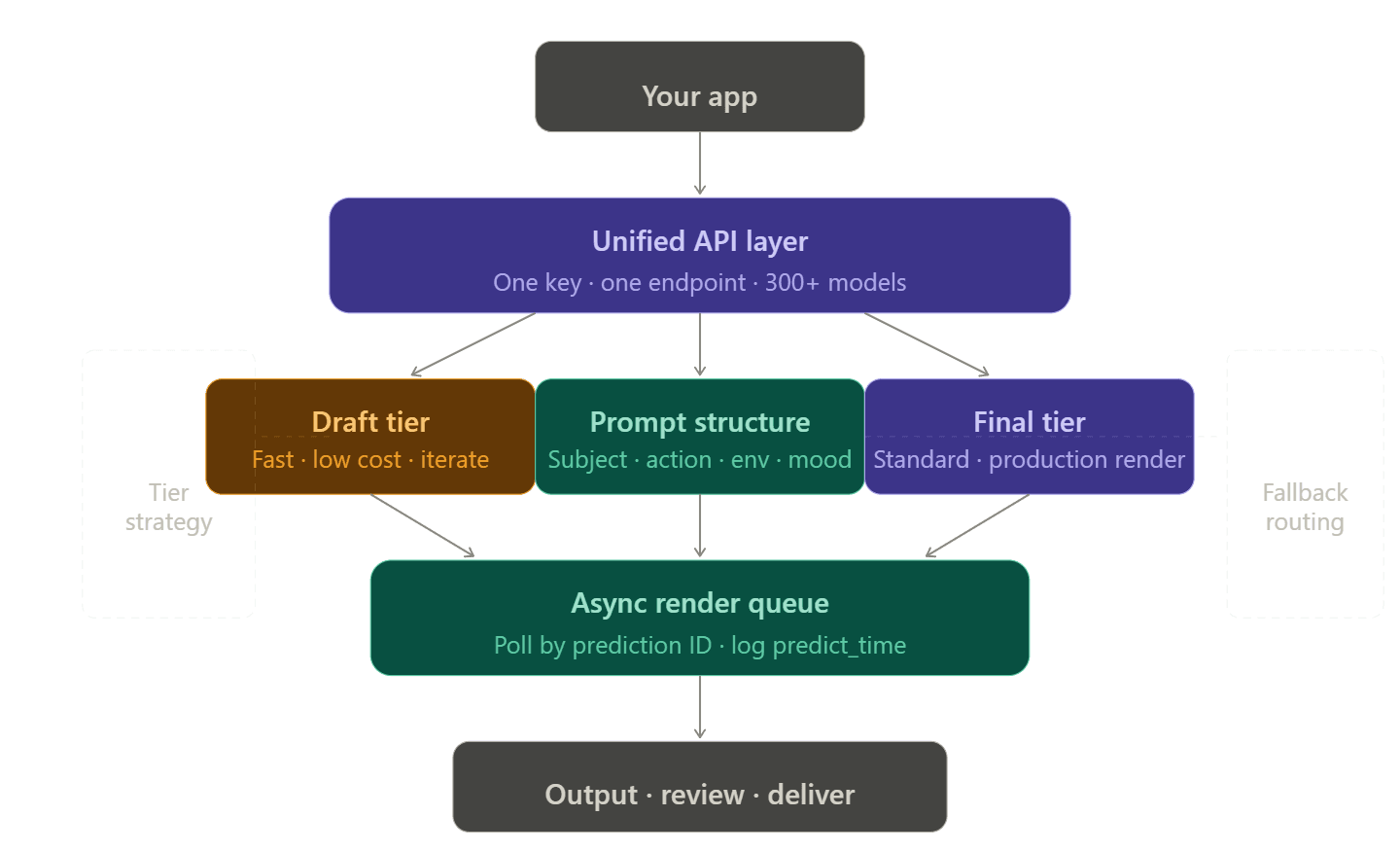
シングルベンダー vs 統合APIアーキテクチャ
すべてのビデオプロバイダーに対してアカウント、トークン、請求ページを管理するのは非常に煩雑であり、「統合コスト」と呼ばれます。モデルが制限に達した場合に備えてバックアップが必要になりますが、そのバックアップにも個別のAPIキーや設定が必要となります。
統合APIプラットフォームは、複数のプロバイダーを1つのエンドポイントにルーティングすることでこれを解消します。Atlas Cloudでは、openai/sora-2/text-to-video から bytedance/seedance-2.0/text-to-video への変更は文字列を1つ変えるだけで済み、認証や請求処理はそのまま維持されます。
ドラフトから最終出力への階層化
コストと信頼性の観点から最も効果が高いのは、ワークフローの段階に応じて適切なモデル層を選択することです。
| ステージ | 推奨層 | 理由 |
|---|---|---|
| プロンプト探索 / コンセプト検証 | Fast / Budget層 | Standard比で78%以上のコスト減、エラー検知が容易 |
| 内部レビュー用ドラフト | Fast層 | ステークホルダーレビューに十分な品質 |
| 最終プロダクションレンダリング | Standard / Pro層 | 品質差がコストを正当化 |
| バッチ生成(SNS、マーケティング) | Fast層 | ボリュームによりコスト差が顕著 |
Seedance 2.0のFast層は1秒あたり$0.081であり、Standardの$0.10よりも安価です。月間200個の10秒クリップを生成するチームの場合、$38の節約となります。
エラーを防ぐプロンプトエンジニアリング
曖昧なプロンプトはパイプライン失敗の主要な原因です。「人が歩いている」といったプロンプトは、AIに過度な解釈を強いるため、不安定な出力とリトライを招きます。
信頼性の高い4要素のプロンプト構造:
plaintext1[主題 + 詳細] + [アクション + 動きのスタイル] + [環境 + 照明] + [カメラ + 雰囲気] 2 3例: 4"A woman in a red coat walking briskly through a rain-slicked Tokyo street at night, 5neon reflections on wet pavement, medium tracking shot, cinematic and tense"
マルチモーダル入力(Seedance 2.0は画像、動画、音声など最大12の参照ファイルを受付)をサポートするモデルでは、視覚的参照を提供することで曖昧さを減らし、品質低下を防ぐことができます。
モデルの選択
すべてのAIビデオツールが同じ理由で失敗するわけではありません。特定のタスクに不適切なモデルを使うことは技術的なバグのように見えますが、単にそのモデルがその用途に向いていないだけというケースが多いです。
モデル能力リファレンス
| モデル | 強み | 注意点 | 価格 (Atlas Cloud) |
|---|---|---|---|
| Wan 2.7 | 物理シミュレーション、リアルな物体干渉 | 画像参照のみ、高コスト | $0.1/sec |
| Kling 3.0 | 高解像度、ネイティブ口パク、無料層 | 最大解像度での生成時間が長い | $0.071-0.143/sec |
| Veo 3.1 | シネマティック品質、厳格な安全基準 | プレビュー版はレート制限 (10 RPM) | $0.05–0.20/sec |
| Seedance 2.0 | マルチ参照入力制御、ネイティブ音声 | プロンプト構築の慎重さが必要 | $0.081–0.10/sec |
| Wan 2.6 | 低コスト、大量コンテンツ | 音声なし、最大1080p | $0.018-0.07/sec |
価格は2026年4月時点のAtlas Cloudのドキュメントに基づくものです。
モデルの切り替えとプロンプト修正の判断
以下の場合はモデルを切り替えてください:
- 音声や対話がプロンプトに含まれる場合のみ一貫して失敗する(モデルの音声対応不足)
- 物理演算や物体との干渉品質に問題がある場合
- プレビューモデルのレート制限に頻繁に達する場合
以下の場合はプロンプトを修正してください:
- スタイルが不適切だが構造は正しい場合
- 特定の言語で安全フィルターに抵触する場合
- 期間や解像度のパラメータが拒否される場合
また、kling-latestではなくkling-v3.0-stdのようにバージョンを固定してください。モデルのサイレントアップデートにより、品質回帰が発生する可能性があります。
デバッグツールキット
段階ごとのログ記録
ログはデバッグ時間を半分に短縮します。最小限必要な項目は以下の通りです。
リクエスト時:
- モデルIDとバージョン
- プロンプトハッシュ(フルプロンプトではなくハッシュでログをコンパクトに)
- 期間、解像度、モードパラメータ
- タイムスタンプ
レスポンス時:
- 予測ID
- 初期ステータス
- 即時エラーメッセージ
ポーリング完了時:
- 最終ステータス
- metricsからの predict_time
- エラーフィールドの内容(失敗時)
- 出力URL(完了時)
インフラエラーとアプリケーションエラーの区別
生成に失敗した際は、以下の順序で診断してください。
- API健全性ダッシュボードを確認 — プラットフォーム側の障害であればデバッグ不要。
- x-deny-reason ヘッダーを読み取る — プロキシによる拒否をモデルエラーと誤認しないため。
- CORSエラーを確認 — フロントエンドからの呼び出しの場合、ブラウザの開発ツールで認証失敗と同じ症状に見える。
- ファイル制限を確認 — 入力ファイルの最大サイズ(通常16MB)や対応形式を確認。
コスト最適化
3つのレバー
コストは3つの変数の積です。すべてを最適化することで節約効果が最大化されます。
| レバー | 低コストの選択 | 高コストの選択 | 典型的な乗数 |
|---|---|---|---|
| モデル層 | Fast | Standard/Pro | 3–5× |
| 期間 | 4–5秒 | 12–15秒 | 3× |
| 解像度 | 720p | 4K | 2–4× |
使用量ベース vs サブスクリプション
Google AI Proなどのコンシューマー向けプランはビデオ生成を含みますが、APIアクセスを含まないものがほとんどです。ここを誤解して予算を立てないようにしてください。
Atlas Cloudの使用量ベース課金は、実際に構築した分だけ支払うため、プロジェクトの変動が激しい場合に最適です。最終ビデオの秒単位コストを追跡し、モデル間で公平に比較してください。
参照アセットの再利用
キャラクターやシーンを頻繁に使用する場合は、アセットを事前に登録してください。
- 参照画像や動画を一度アップロードし、アセットIDを保存する
- 以降は
asset://<ark_asset_id>を使用する - ほとんどのプラットフォームで参照ファイルのアップロードは無料です
プロダクション準備チェックリスト
本番環境への投入前に以下を確認してください:
認証
- APIキーは環境変数から読み込まれている
- すべてのモデルに対する正しい権限がある
- キーのローテーション方針がある
レート制限と同時接続
- 各モデル層のRPMと同時実行数が確認されている
- バースト制御やキューが実装されている
- 制限時のフォールバック先がある
エラーハンドリング
- 最終状態(completed, failed, expired)がすべて処理されている
- 失敗時にエラーフィールドがキャプチャされている
- 長いレンダリング用にタイムアウトが10分以上に設定されている
コンテンツとプロンプト
- コンテンツガイドラインに準拠したプロンプト
- 音声・視覚のトリガーが切り分けられている
- 4要素プロンプト構造が採用されている
モデル設定
- バージョンが固定されている
- ワークフローに応じた層の選択(Fast/Standard)
- 必要なパラメータ(期間、解像度、音声)が全て確認されている
コスト管理
- 請求ダッシュボードのアラート設定
- 最終出力以外のデフォルトはFast層
- 参照アセットIDの活用
可観測性
- 予測ID、ステータス、時間をログ記録
- 健全性ダッシュボードのブックマーク
- predict_time急増時のアラート設定
よくある質問
プレミアムプランで「429 Resource Exhausted」が発生するのはなぜですか? それはレート制限に達したことを意味します。システムをスムーズに動かすため、プロバイダーはリクエストとトークンを制限します。
- 修正: コードに指数バックオフを加え、リトライを自動化してください。また、ダッシュボードで利用可能なティア(Usage Tier)を確認し、必要に応じてアップグレードしてください。
「コンテンツモデレーション」の誤検知を回避するには? 安全フィルターは技術的なプロンプトをポリシー違反と誤解することがあります。
- 修正: 曖昧な言葉を技術的な用語に置き換えてください。「混沌としたエネルギー」ではなく「高速カメラ動作」と表現します。LLMを使用してプロンプトを洗練させ、機械が理解しやすい記述に変換するのも有効です。
レンダリングパイプラインの遅延を減らすには? 遅延はポーリングの不備やモデルサイズの大きさに起因します。手動ポーリングの代わりにWebhookを使用して完了データを受け取るようにしてください。自己ホスティングの場合はFP8量子化の適用が有効です。APIユーザーは、シーケンシャルではなく非同期処理を導入して複数の生成を並列で行ってください。






