
Grok Imagine Video Generation は、xAIが提供する最先端のマルチモーダルAIビデオシステムであり、単一のAPIコールでクリエイターにこれまでにない体験をもたらします。xAI Auroraエンジンを基盤とするこのモデルは、自己回帰型 Mixture-of-Experts(MoE)ネットワークを採用しています。テキスト、画像、動画、音声を統合してトークン処理を行うこのアプローチは、SoraやVeoなどが採用する拡散トランスフォーマー方式を完全に置き換えるものです。
最大の利点は、生成プロセスにおいて自然な映像と音声の同期が同時に実現される点です。生成後の別個のダビング作業は不要です。
概要:主要スペック
| 項目 | 詳細 |
| 動画時間 | 1〜15秒 |
| フレームレート | 24 FPS |
| 解像度 | 480p / 720p |
| 音声 | ネイティブなリップシンク、SFX、台詞、環境音 |
| リーダーボード | Artificial Analysis Video Arenaで1位 (Elo 1404 ±6) |
2026年5月下旬にリリースされた Grok Imagine Video Generation は、Artificial Analysis Video ArenaのImage-to-Videoリーダーボードで初登場1位を記録し、ByteDanceのSeedance 2.0を上回りました。迅速かつ本番環境でそのまま使える、音響付き動画が求められる現代のデジタルワークフローにおいて、これこそが超えるべきベンチマークです。
xAI Grok Imagine Video Generationのアーキテクチャを理解する
Grokの機能を最大限に活用するには、その内部構造を理解する必要があります。従来の動画モデルが映像と音声を後付けで合成するのに対し、Grokはこれらを単一のエンティティとして扱います。この根本的な転換を理解することで、なぜプロンプトへの反応やレンダリング速度が市場の代替製品と大きく異なるのかが分かります。
Grok Imagineとは何か、そしてどのように機能するのか?
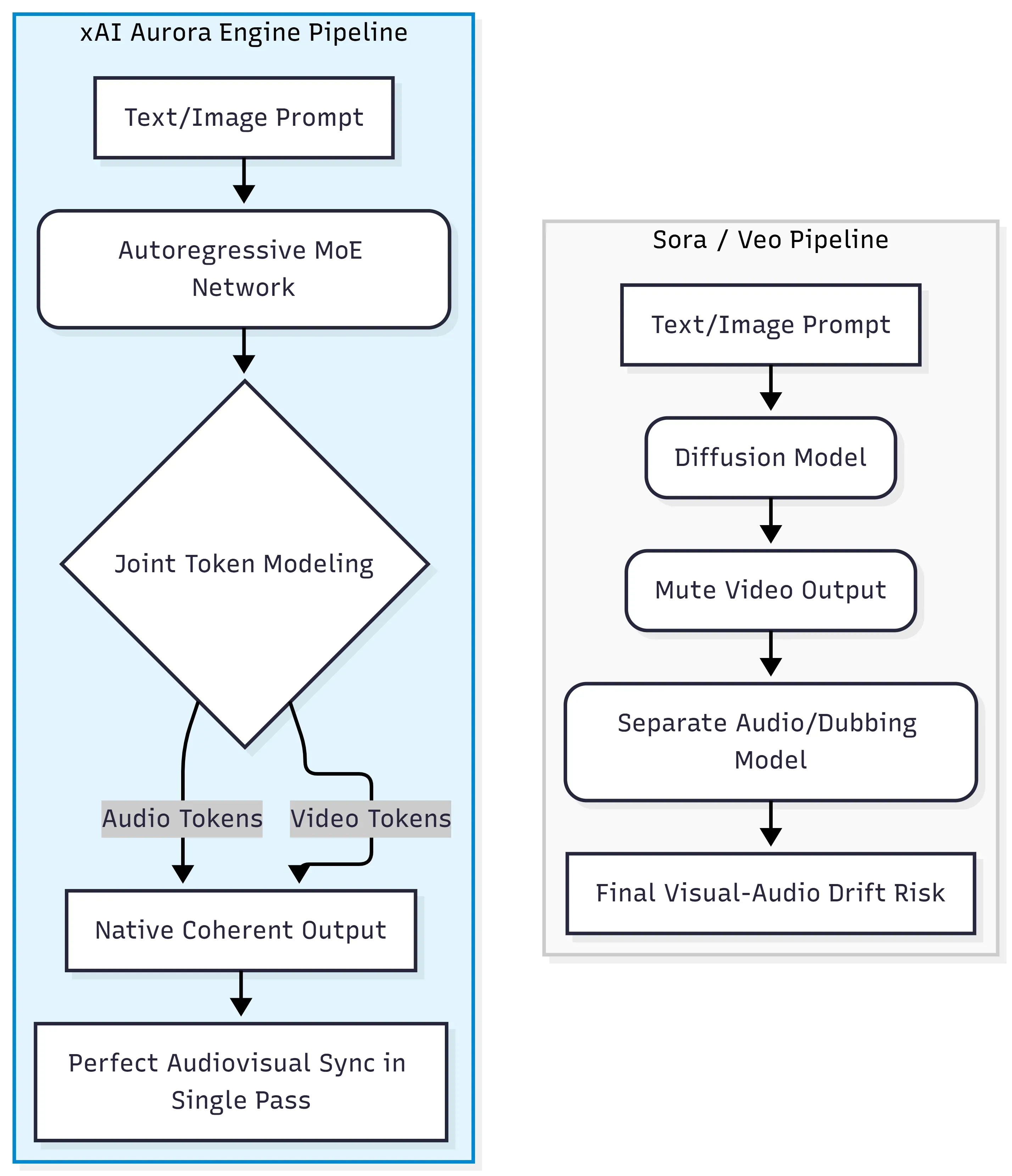
Grok Imagine Video Generationは、その核心部分で xAI Auroraエンジン を駆動しています。これは、テキスト、画像、動画、音声データの統一ストリーム全体で次のトークンを予測する、自己回帰型 Mixture-of-Experts(MoEネットワーク) です。これは、映像と音声を通常別々のステージで生成または同期させる、OpenAIのSoraやGoogleのVeoが採用する拡散トランスフォーマー・パラダイムとはアーキテクチャ的に一線を画しています。
拡散トランスフォーマーからの脱却
従来の拡散モデルは、ランダムなノイズを徐々にデノイズしてコヒーレントなフレームに変換します。視覚品質には優れていますが、音声は後付け扱いとなり、外部ツールやポストプロダクション・パイプラインで音声を加える必要があります。Auroraは全く異なるアプローチをとります。
| アプローチ | アーキテクチャ | 音声生成手法 |
| Sora / Veo | 拡散トランスフォーマー | ポストプロダクション / 別モデル |
| Grok Imagine Video | 自己回帰型 MoE | ネイティブ・シングルパス生成 |
インターリーブされたマルチモーダル・トークン処理
Auroraはモダリティを順次処理するのではなく、インターリーブされたマルチモーダルデータを処理します。つまり、視聴覚トークン(台詞、効果音、環境音楽)がビデオフレームと同時に同じフォワードパス内で生成されます。この共同トークンモデリングこそが、別個の調整システムではなく、モデル自体からリップシンクや音響効果を導き出すことを可能にしているのです。
Auroraのシングルパス実行を実証する製品サンプル。エンジンの轟音の音響周波数が、視覚的な加速およびタイヤの摩擦物理特性と完全に同期しています。
大規模なトレーニング:Colossus
このモデルは、xAIのスーパーコンピュータ「Colossus」でトレーニングされました。この巨大施設は約55万基のNVIDIA GPUを使用し、約2ギガワットの電力を消費します。これは、単一拠点のAIトレーニングクラスターとしては世界最大です。この膨大なセットアップこそが、品質を落とさずに4種類のメディアタイプを混合できるAuroraの秘密です。
主要機能:Image-to-Video、フォーマット設定、品質モード
Grokはテキストから動画への生成をサポートしていますが、真のエンタープライズユーティリティはImage-to-Video (I2V) ワークフローで発揮されます。静的な参照画像をモデルに読み込ませることで、キャラクターの造形を即座に固定し、詳細なテキスト説明の代わりに正確なメカニカル制御へ重点を移すことができます。スタイリングモードに入る前に、パイプラインの主要な制約を設定する必要があります。
Grok Imagineの動画制限、アスペクト比、解像度は?
画像を動画に変えることは、Grok Imagineで最も便利な機能の一つです。静止写真をアップロードし、動きを記述する簡単なプロンプトを入力するだけで、モデルが音声を同時に合成して画像をアニメーション化します。長さ、フレームレート、解像度、形状の4つの設定で最終フォーマットを完全に制御できます。
動画時間とフレームレート
詳細な時間制御により、1秒から15秒の間で任意の整数秒数を指定可能です。これは以前の10秒制限を50%拡張しつつ、長い時間軸全体で時間的整合性を維持します。すべての出力は24 FPSのベースラインで固定レンダリングされます。
解像度のオプション
| 解像度 | 品質 | 処理速度 |
| 480p | 標準画質 | 高速(デフォルト) |
| 720p | HD画質 | 低速 |
最終的な成果物やSNSでの配信には、720pが現実的な選択肢です。迅速な反復やプロンプトのテストには480pを使用してください。
アスペクト比のバリエーション
7つのアスペクト比がサポートされています。
| 比率 | 最適な用途 |
| 16:09 | ワイドスクリーン / YouTube(デフォルト) |
| 9:16 | TikTok / Instagramリール / ストーリーズ |
| 1:01 | SNSサムネイル |
| 4:3 / 3:4 | プレゼンテーション / ポートレート |
| 3:2 / 2:3 | 写真フォーマット |
Image-to-Video生成では、上書きされない限り、入力された画像のネイティブアスペクト比がデフォルトになります。
シネマティックな動きとゼロショット・アイデンティティのためのプロンプトエンジニアリング
xAI Auroraエンジンは共同トークンモデリングに依存しているため、プロンプト戦略を変える必要があります。キャラクターの外見を記述するトークンを費やす必要はもうありません。入力画像がゼロショットのアイデンティティ維持を担うためです。その代わり、プロンプトでは方向性のある動き、カメラ動作、そして極めて重要な点として、エンジンと同時に生成させたい音響環境に集中してください。
Grok Imagine Videoで最適な結果を得るためのプロンプトのコツ
最も重要な原則は、Grok Imagineがゼロショット・アイデンティティ保持をサポートしているため、モデルは入力画像から被写体の外見を直接引き継ぐという点です。髪の色、服装、顔の特徴を再記述する必要はありません。言葉のすべてを動作ダイナミクス、環境、カメラの方向性のために使ってください。
最適なプロンプト構文
これらの最適化されたトークンブロックを組み合わせて、高度に制御されたシネマティック環境を構築します。
| アクションと動き | カメラダイナミクス | 音響と環境 |
| ...自信を持って前進し、コートがなびく | ドリーズームでゆっくり引く | ...濡れた路面にネオンが反射する。SFX: アスファルトに叩きつける激しい雨 |
| ...混雑を駆け抜け、後ろを振り返る | ローアングル・トラッキングショット、高速 | ...ちらつく蛍光灯の下。SFX: くぐもった群衆のざわめきと息切れ |
| ...ゆっくり振り向き、目を見開く | マクロパン(左から右への追跡) | ...浅い被写界深度、浮遊する塵。SFX: 深く響くシネマティックな低音ドロップ |
シナリオA:サイバーパンクの追跡シーケンス(高ダイナミック、強力な音声同期)
プロンプト:
アクションと被写体: ネオンサインで照らされた濡れた路地を男が速く走る。
カメラダイナミクス: カメラは低い位置を保ち、彼に密着して追従する。背景がぼやけて過ぎ去り、明るい光が画面を横切る。
SFX: 速い電子音楽と水たまりを踏む音、遠くのサイレンが混ざり合う。ビートが点滅するネオンライトと完璧に一致。
テスト目的: このテストでは、高速移動中の形状をAuroraエンジンがどれだけうまく処理できるかを確認します。また、シンセのビートとネオンの点滅を合わせるなど、音声と視覚の同期精度を評価します。
成功点(Grokが優れていた点):
- ゼロショット・アイデンティティ保持: 静的シード画像からの遷移は完璧でした。トレンチコートのシワの質感や、キャラクターの乱れたダークヘアは、アイデンティティの崩れもなく完璧に安定しています。
- 物理的な整合性: Grokは、競合する拡散モデルでよくある失敗点である、手足の重複や衣類のクリッピングなしで高速スプリントを処理しました。
- ダイナミックな照明物理: 濡れた路面上のピンクと青のネオン反射が、カメラの前方トラッキング角度と正確に同期して変化しました。
課題点(ボトルネック):
- 音声トークンのバイアス: ネイティブなシングルパスの音声同期は印象的ですが、エンジンが「シンセウェーブ音楽」のトークンを強く優先し、「水たまりの跳ね」というSFXが完全に覆い隠されてしまいました。
- モーション圧縮: 720pにおいて、急激なカメラ移動が「MIDNIGHT DINER」のような遠くの背景文字周辺に軽微なエッジのぼけやデジタルアーティファクトを引き起こしました。
シナリオB:シネマティックな対話と感情の昂り
プロンプト:
アクションと被写体: 彼女が「It ends tonight」と、確信を持ってささやく、緊迫した映画のセリフを言う。
カメラダイナミクス: 突風が髪を乱すと同時に、カメラが彼女の顔にゆっくりと寄る。
SFX: 静かな声が唇の動きと完全に一致し、マイクに吹き込む突然の強い突風の音と、衣類が擦れる音が混ざる。
テスト目的: xAI Auroraエンジンのマルチトークン統合に対する決定的なストレステストです。ネイティブなリップシンクとダイナミックな表情の力学を完璧に実行しつつ、髪や衣類の動きという複雑な物理的相互作用を計算させ、さらに現実的な環境音とマッチさせることを単一の推論パスで行わせます。
成功点(Grokが優れていた点):
- 完璧なネイティブ・リップシンク: 「It ends tonight」という発声が、キャラクターの唇と顎の動きと完全に一致。追加編集なしで自然に実現されました。
- 微細な表情の保持: 顔のそばかす、小さな瞬き、鋭い眼差しが正確に維持されました。エンジンがクローズアップ撮影でもアイデンティティを安定させていることを示しています。
- 風の物理シミュレーション: 話し終えた瞬間に突風がダークヘアに吹き込み、髪の毛がリアルに動き、自然なボリュームを維持しました。
課題点(ボトルネック):
- 音声アーティファクト: 生成された声はタイミングは良好ですが、プロンプトで求めた生々しく息遣いのある質感に欠け、わずかに圧縮された人工的なロボット調の音色になりました。
- 時間的なマイクロ・モーフィング: 風で揺れるシーケンス中、耳と生え際付近でテクスチャがわずかに混ざり合い、動く髪と静止した肌背景を切り分けるのに苦労していました。
ピットフォールの回避:カウンター例マトリックス
現在のパブリックエンドポイントでは負のプロンプト(ネガティブプロンプト)パラメータをサポートしていないため、パイプラインエンジニアは従来の拡散ベースのプロンプトヒューリスティックから切り替える必要があります。
- ❌ 不適切なアプローチ(拡散モデルの思考):「A man running, highly detailed, 4k, no blur, no distortion, cinematic lighting.」
- 分析: これはコンテキストウィンドウを無駄なトークンで満たし、no blurのような否定的なフレーズを導入してしまいます。Auroraのような自己回帰型MoEネットワークは、これらの用語を意味的なアンカーと誤解し、避けたいはずの歪みを偶然生成してしまう可能性があります。
- ✅ 適切なアプローチ(Auroraネイティブの思考):「Strides forward dynamically. Sharp focus throughout, pristine cinematic textures, volumetric god rays piercing through dust.」
- 分析: これは除外条件を肯定的な決定論的空間・物理的記述に置き換え、エンジンのトークン予測パスを鮮明なレンダリングへと明快に導きます。
Pro tips:
同時のズームインと右パンといった、矛盾する空間指示をプロンプトに入れると、時間的一貫性が低下します。カメラの動きは単一で方向性の明確なものにしてください。8秒を超えるクリップの場合は、複数のシーンカットではなく、一つの継続的なモーションアークを中心にプロンプトを構成してください。
Grok Imagine Video Generation API統合:PythonとRESTのクイックスタート
創造的なコンセプトから本番環境のスケーリングへ移行するには、これらのパラメータを公式のxAI APIゲートウェイを通じて実行する必要があります。現在のインフラと、自動的なバックグラウンド処理を好むか、軽量なカスタムループを好むかに応じて、xAIは2つの異なる実装パスを提供しています。
Grok Imagine APIで動画を呼び出すには?
Grok Imagine APIを呼び出すためのサポートされているパスには、ネイティブの xai_sdk クライアント(ポーリングを自動処理)と、https://api.x.ai/v1 を介した OpenAI互換のbase_url RESTアプローチの2つがあります。どちらも環境変数として設定された APIキー認証 が必要です。
前提条件
コーディングの前に、以下の手順を完了してください。
- console.x.ai でAPIキーを生成。
- シェルでエクスポート: export XAI_API_KEY="your-key-here"
- SDKをインストール: pip install xai-sdk
パス1: ネイティブ xai_sdk (推奨)
xai_sdk クライアントは、内部で全非同期ポーリングループをラップしているため、video.generateエンドポイントへの単一の呼び出しで完了した動画オブジェクトを受け取れます。
plaintext1import os 2import xai_sdk 3 4client = xai_sdk.Client(api_key=os.getenv("XAI_API_KEY")) 5 6# Image-to-Videoワークフローでは参照画像を渡すこと 7response = client.video.generate( 8 model="grok-imagine-video", 9 image="your image", # 必須のURLまたはbase64 10 prompt="your prompt", 11 duration=5, 12 aspect_ratio="16:9", 13 resolution="720p", 14) 15 16# 修正済み: 標準的なxai_sdkレスポンススキーマに準拠 17print(f"Generation Successful. Video URL: {response.video.url}")
手動のポーリングは不要です。SDKがリクエストを送信し、完了を待機し、URLを返します。
パス2: 標準REST API (カスタム非同期ループ)
ネイティブSDKが使用できない環境では、HTTPエンドポイントを使用します。動画生成は非同期であるため、実行ステータスを追跡するためのポーリングシーケンスを実装する必要があります。
plaintext1import os 2import time 3import requests 4 5headers = { 6 "Authorization": f"Bearer {os.environ['XAI_API_KEY']}", 7 "Content-Type": "application/json", 8} 9 10payload = { 11 "model": "grok-imagine-video", 12 "image": "your image", 13 "prompt": "prompt", 14 "duration": 5, 15 "aspect_ratio": "16:9", 16 "resolution": "720p" 17} 18 19# 1. 動画生成リクエストの送信 20res = requests.post("https://api.x.ai/v1/videos/generations", headers=headers, json=payload) 21res.raise_for_status() 22request_id = res.json()["request_id"] 23 24# 2. 完了するまでステータスエンドポイントをポーリング 25while True: 26 poll = requests.get(f"https://api.x.ai/v1/videos/{request_id}", headers=headers) 27 data = poll.json() 28 29 if data["status"] == "done": 30 # 修正済み: 公式xAI JSONスキーマ戻り値に準拠 31 print(f"Success! Asset Available At: {data['video']['url']}") 32 break 33 elif data["status"] in ["expired", "failed"]: 34 print(f"Generation failed with status: {data['status']}") 35 break 36 37 time.sleep(5) # 安全なレート制限間隔
ポーリングステータスのリファレンス
生成中、APIは以下の4つのステータスのいずれかを返します。
| ステータス | 意味 |
| pending | 処理中 |
| done | 動画準備完了、URL利用可能 |
| expired | リクエスト期限切れ |
| failed | 生成エラー |
適切なレート制限内に収めるため、5秒ごとのポーリングを推奨します。SDKはデフォルトで100ms間隔ですが、本番ワークフローでは5秒間隔が実用的です。
本番用代替手段: Atlas Cloud APIゲートウェイによる効率化
高度な並行処理、統合請求、または高可用性ルーティングを必要とするエンタープライズ・パイプラインでは、Atlas Cloud のようなサードパーティのマネージドゲートウェイを統合することが有効な選択肢です。ローカルで複雑な非同期ポーリングループやステータスチェックを管理する代わりに、Atlas Cloudの統合ラッパーがサーバー側のキューイングと状態保持を自動的に処理します。
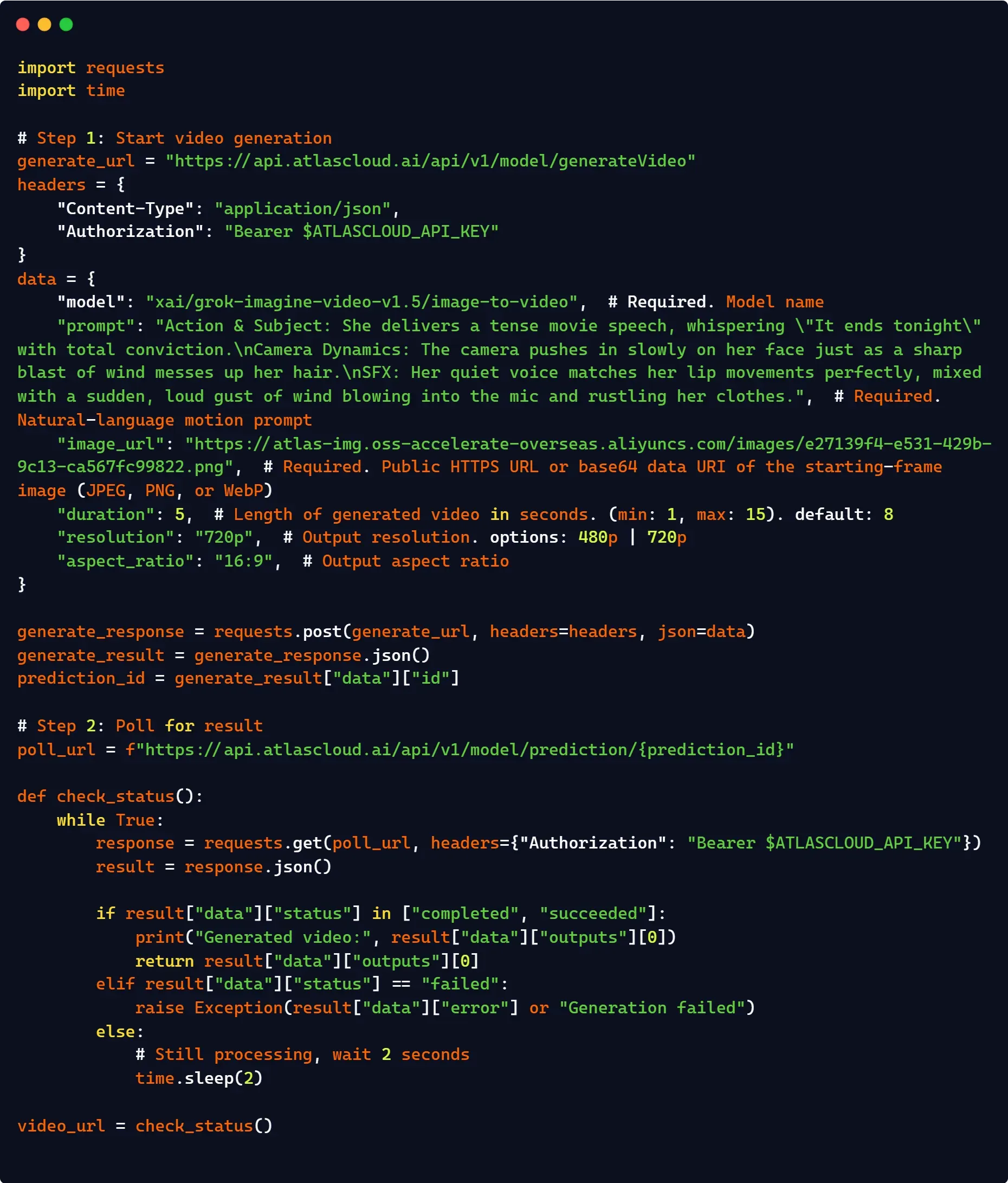
さらに、リクエストを統一されたベースURL経由でルーティングすることで、コードの変更を最小限に抑えつつ、標準のxAIパブリックティアの閾値を超えるようなエンタープライズグレードのレート制限を解除する、シームレスな代替手段となります。
ベンチマークパフォーマンス:コスト、レイテンシ、競合比較
高精細な視聴覚出力は、厳格なコンピューティング予算とレイテンシ要件に合致する場合にのみ、エンタープライズパイプラインとして成立します。Grokが市場でどの位置にあるかを確認するため、サードパーティのストレステストで生成速度と秒単価を既存の業界大手と比較します。
Grok Imagine Videoは他のAI動画ツールより高速で安価か?
独立したベンチマークでは、その答えは概ね「イエス」です。Grok Imagine Videoは、Artificial Analysis Video ArenaのImage-to-Videoリーダーボードにおいて、Eloレーティング 1404 ±6で初登場1位を記録し、ByteDanceのSeedance 2.0をトップの座から引きずり下ろしました。
主要競合他社との比較
| モデル | 開発元 | 最大長 | 最大解像度 | ネイティブ音声 |
| Grok Imagine V1.5 | xAI | 15s | 720p | あり |
| Seedance 2.0 | ByteDance | 4–12s | 720p | あり |
| Veo 3.1 | 8s | 1080p | あり | |
| Sora 2 | OpenAI | 20s | 1080p | あり |
| Runway Gen-4 | Runway | 10s | 1080p | 部分的 |
推論速度とレイテンシ
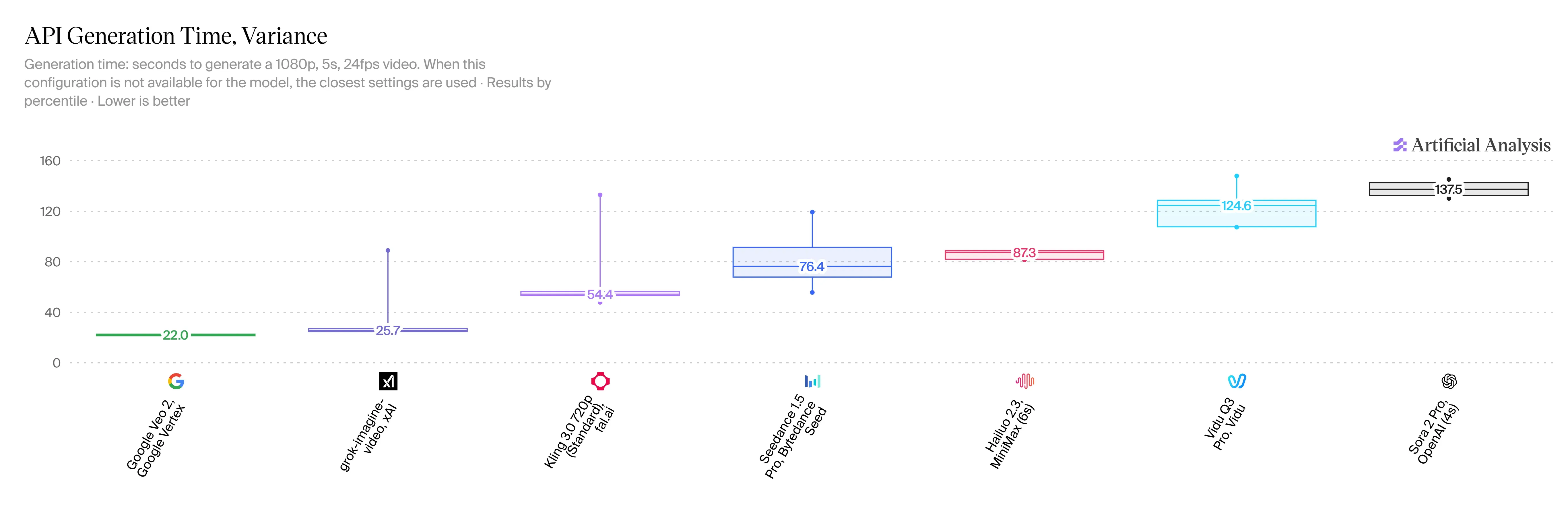
V1.5は信じられないほど高速であり、これはユーザーにとって大きな勝利です。5秒の720pクリップをわずか20〜30秒で作成できます。HappyHorse 2.3と比較して、待機時間を2〜3倍短縮しています。Veo 3.1の公式速度統計はまだありませんが、オンラインでは同様のクリップに1分以上かかると報告されています。
料金体系
Atlas CloudのようなサードパーティのAPIゲートウェイを経由した秒単位の料金体系は、生成された動画1秒あたり約USD0.096から始まります。そのレートであれば、10秒のクリップは概算でUSD0.96となり、独立したクリエイターや小規模チームが、最終的な本番実行を確定させる前に複数のプロンプトバリエーションを試すために、費用対効果の高い実験を真に利用可能にしています。
エンタープライズ・セキュリティ、データプライバシー、コンテンツ・コンプライアンス
独自のメディア資産やクライアント向けのコンテンツをクラウドベースのAIシステムに展開することは、必然的に法的な疑問をもたらします。商用制作会社にとって、生成用の入力データがどこに行き、どのように分離されているかを知ることは、最終的な出力品質と同じくらい重要です。
xAIは私のAPIデータや生成動画をモデルのトレーニングに使用するか?
これはエンタープライズ導入企業から最も多く寄せられる質問の一つであり、直接的な回答が必要です。xAIの開発者利用規約によると、プラットフォームを通じて処理されるAPIの入出力は安全フィルタリングのためのコンテンツポリシー審査の対象となりますが、推論データとパブリックなトレーニングパイプラインを分離するData Privacy by Design原則のもとで処理されます。
コンプライアンス・フレームワークの概要
Grok Imagineへのアクセスを提供するサードパーティAPIゲートウェイ(Atlas Cloudなど)は、独自の独立したコンプライアンス認証を公開しています。
| コンプライアンス基準 | ステータス |
| SOC 2 Type II コンプライアンス | 認証済み |
| GDPR データレジデンシー | 適合 |
| HIPAA | 対応可能 |
プロフェッショナルユーザーのための主要プライバシー境界
商用ワークフローでGrok Imagineを評価する専門家は、以下の点に注意してください。
- 生成された動画出力は、一時的にホストされたURLとして返され、デフォルトでは永続的に保存されません。
- コンテンツポリシー審査は、配信前に安全上の違反がないか出力をフィルタリングしますが、再利用のためにコンテンツを保持することはありません。
- モデルトレーニングの除外がAPIユーザーに適用されます。プロンプトや生成されたメディアは、パブリックなモデルトレーニングループにフィードバックされません。
- GDPRデータレジデンシーの適合により、データ処理の慣行が、管轄区域を越えて運営されるチームの欧州処理基準を満たしていることを意味します。
正式なデータ処理契約やカスタムの保持ポリシーを必要とするエンタープライズ導入については、x.ai を通じてxAIのエンタープライズチームに直接問い合わせるのが適切な次のステップです。






