
Kling 2.6は、これまでで最も有意義な Kling AIのアップデート ですが、使い始める前に知っておくべき重要な注意点が1つあります。
今回のリリースは、Klingが初めて真の ネイティブ音声同期 モデルを搭載したことを意味します。これまでの動画生成は基本的に無音映画のようなもので、クリエイターは動画を作成した後、手作業でナレーションや効果音、背景音を追加する必要がありました。しかし、新しいVIDEO 2.6モデルはすべてを変えます。ビジュアル、リアルなナレーション、マッチングする効果音、背景音を同時に生成できるのです。この機能により、このツールは完全に別のクラスへと進化しました。
優れている点
このモデルは、映像と音響をマッチさせる能力に長けています。声の抑揚、環境音、画面上のアクションが完全に同期するため、ビデオトラックと別個のオーディオトラックの間に生じる違和感が解消されます。映画のようなサウンドは非常にリアルで、焚き火のパチパチという音、街に降る雨、重なり合う群衆のざわめきといった細部まで鮮明に聞こえます。6つのオーディオタイプをサポートしています:
| オーディオタイプ | 用途 |
| 音声ナレーション | 製品動画、Vlog |
| マルチキャラクター対話 | インタビュー、コント |
| 歌唱 / ラップ | 音楽パフォーマンス |
| 環境音 | 自然、都市の風景 |
| オブジェクト/アクションSFX | 衝撃音、機械音 |
| ミックスサウンド | フル没入型作品 |
主な制限事項
3人以上の話し手が登場するマルチキャラクター対話シーンでは、声の割り当てが不整合になることがあります。最も信頼性の高い視聴覚同期を実現するには、2人のやり取りに留めるか、カメラワークを工夫することをお勧めします。
比較と評価
バージョン2.6は、従来の無音モデルから大きく進化しました。完璧なコントロールや膨大な高画質結果を求めるユーザーは、Kling 3.0を検討すべきでしょう。しかし、ほとんどのコンテンツクリエイターは、Kling 2.6のコストパフォーマンスと質の高さを高く評価しています。
Klingネイティブオーディオの解剖:対話、SFX、環境音の深掘り
Kling 2.6 は、単に動画に音声を重ねるだけではありません。視覚フレームと3つのオーディオレイヤーを同時に1パスで生成します。各レイヤーの実際の動作は以下の通りです。
対話とスピーチ
Kling AIの対話生成は、多くのクリエイターが期待する以上の範囲をカバーしています。このモデルは、ソロのスピーチ、キャラクター間の対話、ナレーション、歌、ラップを容易にこなします。各スタイルに合わせて感情のトーンを調整します。さらに、このツールはバイリンガルであり、英語と中国語の音声出力をネイティブにサポートしています。他の言語を入力した場合、モデルは動画出力を損なうことなく、自動的に英語へ翻訳して音声を生成します。
上記の8秒間の動画は、Atlas Cloudオーケストレーションプラットフォーム経由でKling 2.6を使用して直接出力したものです。話し手の高解像度ベース画像と、あらかじめ録音された8秒間の英語音声トラックをアップロードすることで、エンジンはリップシンクをネイティブに処理しました。
顔の筋肉の同期が、ロボットのような口の歪み(「不気味の谷」現象)なしに、複雑な音素に滑らかにマッピングされている点に注目してください。これは、AIによるブランドスポークスパーソンを迅速に生成するための完璧な青写真となります。
時間を節約するためのクイックルール:
- 大文字と小文字に注意してください。日常的な単語には小文字を使用し、名前や頭字語にのみ大文字を使用してください。
- 話し手にラベルを付けてください。各人物に [Character A] や [Character B] のようなタグを付けることで、AIが声を混ぜてしまうのを防げます。
- 気分を記述してください。ラベルのすぐ横にトーンの注釈を追加します。例えば、[Reporter, calm and steady voice] と記述します。
効果音 (SFX)
2.6のAIビデオ効果音は、手動で割り当てるのではなく、文脈に応じてトリガーされます。モデルはシーンの説明を読み取り、適切な音を推論します。AIはアクションワードに基づいて直接音を生成します。砂利の上を歩く足音、ガラスの割れる音、タイヤのきしむ音、機械の駆動音などを生成可能です。最良の結果を得るには、具体的な音源を明記してください。例えば、「ノイズがある」と言うよりも、[Wooden door slams shut, loud bang] と書く方がはるかに効果的です。
環境音
環境音合成は、カフェのざわめき、窓に打ち付ける雨、草原を渡る風、地下鉄の到着音など、環境レイヤーを担当します。これらのバックグラウンドトラックは、対話や効果音の下で再生され、動画に真の奥行きを加えます。プロンプト内で特定の環境を指定してください。例えば、`[small room acoustics]` や `[open hall reverb]` のような用語を使うことで、モデルに明確な目標が与えられ、オーディオ品質が向上します。
長さ:5秒 vs 10秒の出力
この選択はオーディオの安定性に直結します。Klingの5秒 vs 10秒の動画 の選択は、特に音声中心のコンテンツで重要です。
| コンテンツタイプ | 推奨される長さ | 理由 |
| 環境音のみ / SFX | 5秒 | クリーンで引き締まった出力 |
| モノローグ / ナレーション | どちらでも | スクリプトの長さに依存 |
| マルチキャラクター対話 | 10秒 | より安定した声の切り替え |
| 歌唱 / ラップ | 10秒 | 歌詞の途切れを防ぐ |
歌唱や対話シーンでは、より完全で安定した結果を得るために10秒パラメータの使用が推奨されます。短いクリップは雰囲気作りやアクションと音のペアリングに適していますが、セリフが含まれる場合は、最後の数秒での音声ドリフト(ズレ)を防ぐために長い時間枠が有利です。
完璧な視聴覚同期のためのKling 2.6プロンプト公式
Kling 2.6 で発生する同期問題のほとんどは、モデルではなくプロンプトに原因があります。プロンプトを「監督の指示書」と考えてください。各要素を正確に定義すればするほど、推論エンジンが推測する必要が減り、その推測のズレがリズム崩壊の原因となります。
コア公式
この Klingプロンプトテンプレート は、モデルがどのように生成を処理するかに直接対応しています:
シーン → 主題 → 動きとカメラ → オーディオの青写真
公式のプロンプト構造は:シーン(シーンの説明)+ 要素(主題の説明)+ 動き(動作の説明)+ オーディオ(対話 / 歌 / 効果音 / 音楽)+ その他(スタイル / 感情 / カメラ)です。
各ブロックが生成パイプラインの異なる部分に供給されます。いずれか一つを省略すると、モデルは隙間を埋めようと強制され、そこで 視聴覚リズム が崩れてしまいます。
ブロック別の詳細
| ブロック | 含めるべき内容 | よくある間違い |
| シーン | 場所、照明、時間帯 | 曖昧すぎる: "a room" |
| 主題 | 外見、役割、フレーム内の位置 | 名前や人称代名詞のみ |
| 動きとカメラ | アクションシーケンス、Klingのカメラ制御言語 (スローズーム、追跡ショット、クローズアップ) | カメラ指示がまったくない |
| オーディオの青写真 | 引用符付きの対話、感情タグ、SFXラベル、環境レイヤー | 対話が説明文の中に埋もれている |
すぐに使える例:完璧なレンダリングの解剖
地域的なAPIの制約やKlingネイティブプラットフォーム上のキューの混雑のため、Atlas Cloud上の統合されたkling-v2.6-std-avatarパイプラインを利用することが、大量の自動生成には最も信頼できるパスです。この特定のティアは、マルチエージェントの動的なシーンではなく静的なトーキングヘッド形式に限定されますが、正確な音声マッピングにおいて非常に優れています。
私たちのコア公式の権威を証明するため、上記で示した青写真をAtlas Cloudオーケストレーションプラットフォーム経由でKling 2.6(kwaivgi-kling-v2.6-std-avatarティア)で実行しました。上の2秒間のクリップは、未修正のシングルパス商用出力です。
なぜこのレンダリングが「不気味の谷」に陥らず、完璧な自然さを実現しているのかを分析します:
- フレーム0の構図ロック:女性ホストがすでにスマートウォッチを頬の横に添えている初期画像を使用することで、四肢が歪むリスクを排除しました。AIは複雑な骨格メカニズムを推測する必要がなく、微細な表情のアニメーションに集中できます。
- 音声リップシンクの精度:ホストの唇の動きと歯の追跡が、「Zero lag. All day battery.」という早口の音節変化に完全に一致していることに注目してください。
- 映画のような照明と奥行き:被写界深度の浅さ(背景のボケ味)が背景ノイズを大幅にフィルタリングし、AIパイプラインが計算能力の100%を、肌の毛穴や衣服のシャープな質感をレンダリングすることに集中できるようにしています。
長さとオーディオウィンドウ
Kling AIの最大クリップ長 を知ることはオーディオ計画に重要です。現在の出力は最大10秒です。上記のような製品デモの場合、10秒が適切な選択です。ナレーションが最後の言葉を切ることなく、きれいに収まる余地があります。5秒のクリップは、純粋な雰囲気や、セリフを伴わないアクションとSFXの組み合わせに適しています。
プロンプトを書く前に、クリップの長さに合わせてスクリプトの長さを計画してください。
画像から動画へのワークフロー:Klingモーションコントロールによるキャラクターの一貫性
プロのクリエイターにとって、テキストから動画へのパスは単なる入り口に過ぎません。Klingの画像から動画へのワークフロー こそが、本格的なキャラクター主導のコンテンツが構築される場所であり、Kling 2.6モーションコントロール と組み合わせることで、純粋なテキストプロンプトでは不可能なレベルの一貫性が得られます。
I2Vパイプラインがアイデンティティを固定する方法
画像から視聴覚生成モード(Image-to-Audio-Visual)で参照画像をアップロードすると、それがモデルとの視覚的な契約として機能します。入力画像は主題の外見、構図、スタイル、その他の視覚的特徴を指定し、生成された動画を元の画像に近づけます。これが AIキャラクターの一貫性 の基盤であり、モデルはアップロードされた顔、服装、フレーミングを提案ではなく固定された制約として扱います。
これは特に以下の場合に重要です:
- 複数のクリップで同じ顔が必要なブランドスポークスパーソンのコンテンツ
- シーン間で外見を維持する必要があるIPキャラクター
- ビジュアルアイデンティティが資産の一部となる製品デモのホスト
モートコントロール:物理データの投影
参照画像は外見を固定します。Kling 2.6モーションコントロール は、モーション参照からジェスチャー、姿勢、動きのデータを生成されたキャラクターに投影することで、物理的なレイヤーを追加します。モーション参照はパフォーマンスのテンプレートとして機能し、モデルが視覚的なアイデンティティを保持したまま、身体メカニズムを転送します。
このようにアイデンティティ(画像)と動き(参照クリップ)を分離することが、テキストだけで動きを説明するよりも 参照ビデオによるAIアニメーション アプローチをより信頼性の高いものにしています。
I2Vにおけるリップシンクとオーディオアライメント
Kling 2.6のリップシンクは、画像から動画へのモードでネイティブオーディオが有効になっている場合、ネイティブに処理されます。ボイスコントロール機能を使用すると、[Character@VoiceName] 形式を使用して特定の声をキャラクターにバインドでき、モデルが vocal の特徴を正確に再現して指定されたコンテンツを実行できるようにします。
| 入力レイヤー | 制御内容 |
| 参照画像 | 顔、服装、フレーミング、視覚スタイル |
| モーション参照 | ジェスチャー、姿勢の変化、体のリズム |
| ボイスコントロールのバインディング | 音色、話し方のスタイル、言語をまたぐ一貫性 |
| プロンプトのオーディオブロック | 対話内容、感情タグ、環境レイヤー |
すぐに使える例:画像から動画へのワークフローへのコア公式の適用
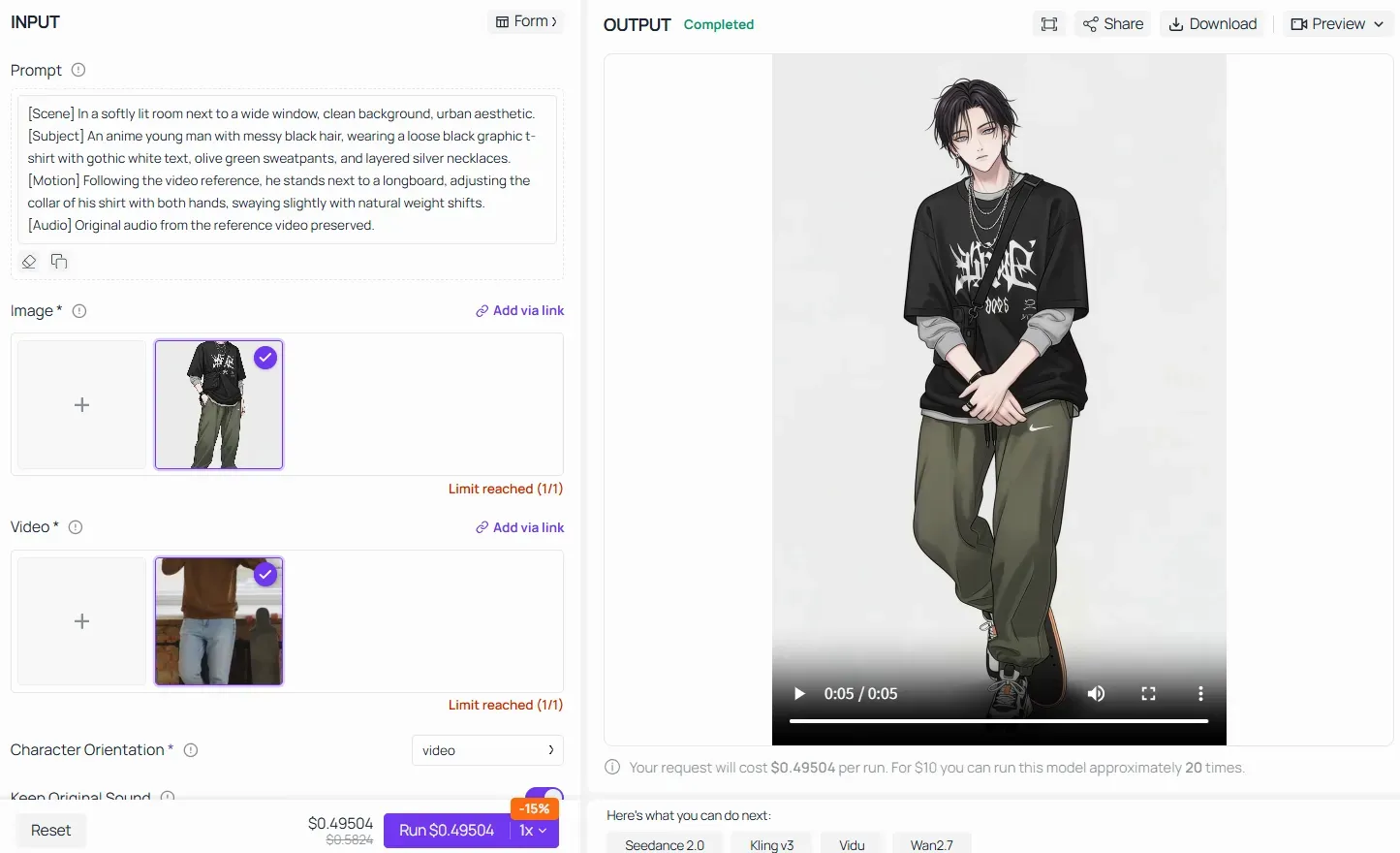
Atlas Cloudのようなプラットフォームで「ビデオ参照 / モーション転送」のような高度な機能を利用する場合でも、コア公式は絶対的な権威を持ちます。「アニメキャラに同じダンスをさせて」といった曖昧な指示をAIに与えるのではなく、シーンを分解し、アップロードされた主題の特徴を凍結し、モーションマッピングを固定することで、プロンプトを構造化する必要があります:
パイプラインのすべてのブロックを埋めることで、AIモデルが現実のビデオから物理的な骨格メカニズムを、元の視覚的アイデンティティを損なうことなくアニメキャラクターアセットにシームレスに転送することを保証します。
Kling 2.6におけるモーションコントロールのヒント: テキストプロンプトで細かな機械的詳細(「腕を45度上げる」など)を悩む必要はありません。キネマティクスについてはビデオ参照に任せてください。その代わりに、[Subject] および [Scene] ブロックを使用して、視覚スタイル、テクスチャ、カラーパレットを厳格に固定し、元の画像のアイデンティティを歪めることなくパフォーマンスを転送させることに集中してください。
画像品質と実用的な制限
一つの大きなルールを心に留めておいてください。最終的な動画の見た目は、アップロードした画像の品質に依存します。
常に高解像度の画像を使用してください。低解像度の画像では、ビデオがざらついたぼやけた結果になります。AIは後から汚いディテールを修正することはできません。この問題は、顔のクローズアップショットで特に顕著になります。
より高解像度のソース画像を実行すれば、5秒から10秒の出力ウィンドウ全体を通して、品質を低下させることなくキャラクターの一貫性を保つことができます。
技術的トラブルシューティング:生成のボトルネックとオーディオドリフトの解消
熟練したクリエイターであっても、Kling 2.6 で摩擦に遭遇することがあります。最も多く報告される問題は、処理途中で生成が停止すること、およびクリップの後半で対話が同期しなくなることです。どちらにも明確な原因と実用的な修正方法があります。
Klingが99%で止まる理由
動画が99%で止まる場合、通常2つの理由があります。第一に、サーバーが非常に混雑している可能性があること。第二に、プロンプトがシステムで処理するには複雑すぎることです。AIはすべての音と視覚を同時に構築しようとします。プロンプトに情報を詰め込みすぎると、指示が衝突します。この混乱がシステムを遅延させるか、完全にフリーズさせます。
試すべき修正方法(順不同):
- 時間を置いて再試行する。ページを更新し、空いている時間帯にプロンプトを送信する。早朝が最もスムーズです。
- シンプルにする。複雑なプロンプトを2つに分け、別々の動画生成として実行する。
- 重なった環境音の説明を削除し、クリップごとに1つの主要なサウンドレイヤーを保持する。
- 1回の生成で3人以上の話し手を使用している場合は、キャラクターの数を減らす。
対話ドリフト(ズレ)を修正する方法
対話ドリフトを修正するには、その根本原因に対処します。モデルのマルチスピーカー処理は、あまりに多くの音声指示が競合すると、5〜6秒を過ぎたあたりで低下します。3人以上のキャラクターがいるシーンではパフォーマンスが低下する可能性があります。
| シナリオ | 推奨される修正 |
| 10秒以上の2人対話 | 明確な話者の切り替え合図を入れて10秒の長さを使用する |
| 3人以上の話し手 | 話者ペアごとに別々のクリップに分割する |
| 長いモノローグのドリフト | セリフを10秒のウィンドウに収まるように短縮する |
| 歌唱の途切れ | 音楽コンテンツには常に10秒パラメータを使用する |
アーティファクトの削減とクレジットの最適化
生成アーティファクトを減らす には、画像から動画へのソースファイルを高解像度に保ち、不一致なシーン説明を避けてください。クレジット消費の最適化 については、ネイティブオーディオを有効にするとプロフェッショナルモードで1秒あたり10クレジットかかるのに対し、オーディオを無効にすると1秒あたり5クレジットであることに注意してください。まずはオーディオオフでドラフトを作成し、最終レンダリングでのみ有効にすることで、プラットフォームの制限 予算をさらに活用できます。
Kling 2.6 vs. Kling 3.0 vs. Wan 2.6 vs. Veo 3.1: 直接比較
1つのAIビデオツールがすべてを完璧にこなせるとは期待しないでください。組み込みオーディオが必要な場合、「最高」の選択肢は予算、ワークフロー、そしてビデオクリップに実際に必要なものによって決まります。
機能比較の概要
| 機能 | Kling 2.6 | Kling 3.0 | Wan 2.6 | Veo 3.1 |
| ネイティブオーディオ | フル (対話/SFX/環境) | フル (シングルパス同期) | フル (リップシンク含む) | フル (3D空間オーディオ) |
| 最大クリップ長 | 10秒 | 15秒 | 15秒 | 8秒 |
| 最大解像度 | 1080p | ネイティブ4K | 1080p | ネイティブ4K |
| モーションコントロール | 強力 (骨格/ビデオ参照) | 強力 (完全アイデンティティロック) | 中 (スタイル/モーション転送) | 中 (流体力学物理学) |
| マルチショット | なし | あり (1パスで最大6ショット) | あり (マルチシーン長文対応) | なし |
| ボイスコントロール | あり | あり | なし (プロンプト依存) | なし (プロンプト依存) |
| 価格 | $0.048 - $0.095/秒 | $0.071 - $0.357/秒 | $0.018 - $0.7/秒 | $0.05 - $0.2/秒 |
注:価格はAtlas Cloudを参照しています。
Kling 2.6の強み
Kling 2.6 vs Wan 2.6 は、オーディオ面では接戦ではありません。Wan 2.6は部分的なオーディオサポートしかありませんが、Kling 2.6は完全なネイティブ対話、SFX、環境音レイヤーを1パスで提供します。ポストプロダクションなしで、音響準備が整った完全なクリップを必要とするクリエイターにとって、Kling 2.6はよりクリーンなワークフローです。
Kling 2.6はVeo 3.1よりも50%以上低コストです。ハリウッドレベルのビデオ品質が不要であれば、Klingの方がはるかに賢い選択です。予算を圧迫することなく、膨大なコンテンツを作成できます。
Veo 3.1の強み
Veo 3.1 vs Klingビデオ の比較は、リアリズムとオーディオ空間化に集約されます。Veo 3.1は、音源がステレオフィールド内を移動する3次元音響環境を生成し、192kbpsのステレオAACエンコーディングで48kHzで出力します。2026年3月現在、他の主要なAIビデオモデルでこのレベルの空間オーディオを提供しているものはありません。放送品質の対話とテキストレンダリングにおいては、Veo 3.1がより強力な選択肢であり続けます。
AIビデオ物理学の比較
AIビデオ物理学 に関して、モデルは明確に分岐しています。Kling 2.6は優れたモーションの流動性と、人間の動きに対してよりリアルな物理シミュレーションを提供し、Veo 3.1は時折物理的な不整合が見られるものの、照明とテクスチャにおいて優れています。
決定フレームワーク
- 以下なら Kling 2.6 を選択:ボイスコントロールされたキャラクター、予算重視の制作、ソーシャルコンテンツ、1パスで完結する視聴覚出力
- 以下なら Kling 3.0 を選択:より長い映画的なショット、マルチシーンのストーリーボード、4K出力
- 以下なら Wan 2.6 を選択:オープンソース、ゼロコストの反復およびドラフトテスト
- 以下なら Veo 3.1 を選択:空間オーディオ、テキストレンダリング、フォトリアルな製品広告
結論:AI映像制作の新しいリズム
ビジュアルをエクスポートし、個別にナレーションを生成し、効果音を重ね、ポストプロダクションでミックスするという従来の映像制作チェーンは、Kling 2.6 を使用する場合には適用されません。その一連の流れは、今や単一のプロンプト送信に集約されます。
最も速く動くクリエイターは、プロンプト作成を検索クエリではなく「監督の技術」として扱う人々です。プロレベルの動画を作るための秘訣はシンプルです。シーン、主題、動き、サウンドの計画を1つの明確なプロンプトにまとめるだけです。
現在、Kling 2.6は最高のツールの1つです。大規模なコンテンツチーム、ソロのクリエイター、高品質な動画を求めるマーケティングスタジオにとって非常に有効です。技術的な天井はこれからも上がり続けます。今プロンプト構造を習得することで、それと共にスケールするための創造的な基盤が築かれます。






