
MiniMaxが1Mトークンで15.6倍のデコード高速化を予告しました。 この数値が事実であれば、100万トークンのコンテキストを実行するコストは1桁近く削減され、しかも生成速度は低下するどころか向上することになります。
これらのモデルで開発を行う人にとって、これは「何が手頃か」という基準を根底から覆すものです。今日では採算が合わないワークロードも可能になります。例えば、コーディングエージェントに断片的な情報ではなくコードベース全体を渡すこと、膨大な履歴が積み重なる数時間にわたるエージェントの実行、切り刻まれたスニペットではなく文書セット全体を対象とした検索などが挙げられます。「請求額や遅延によって製品が破綻する前に、コンテキストウィンドウにどれだけ詰め込めるか」という、すべてのチームが苦心してきた問題のハードルが大きく引き上げられます。
そのメカニズムは疎(スパース)アテンションであり、MiniMaxは唯一ではありません。DeepSeekは3つのモデル系列でこれを実装済みであり、Qwenも独自のバージョンを持っています。方向性は定まりました。変化しているのはその帰結です。すべてのフロンティアモデルが低コストでロングコンテキストを扱えるようになれば、モデル自体はもはや「堀(差別化要因)」にはなりません。そして、それこそが皆さんが注目すべき点であり、最後に改めて触れたいと思います。
その前に、実際にこれを導入しようとする人にとって重要な2つの注意点があります。
- これらはMiniMax自身が公開した、未発表モデルのティーザー図からの数値であり、同社のセットアップ環境下での結果です。方向性を示す強力なシグナルではありますが、第三者によるベンチマークではありません。「MiniMaxがそう主張している」ものとして扱い、ウェイト(重み)が公開されたら自身のワークロードで再検証してください。
- M3はまだ公開されていません。公開時には**Atlas Cloudでデイゼロアクセス(初日からの利用)**を提供予定です。詳細は後ほど。
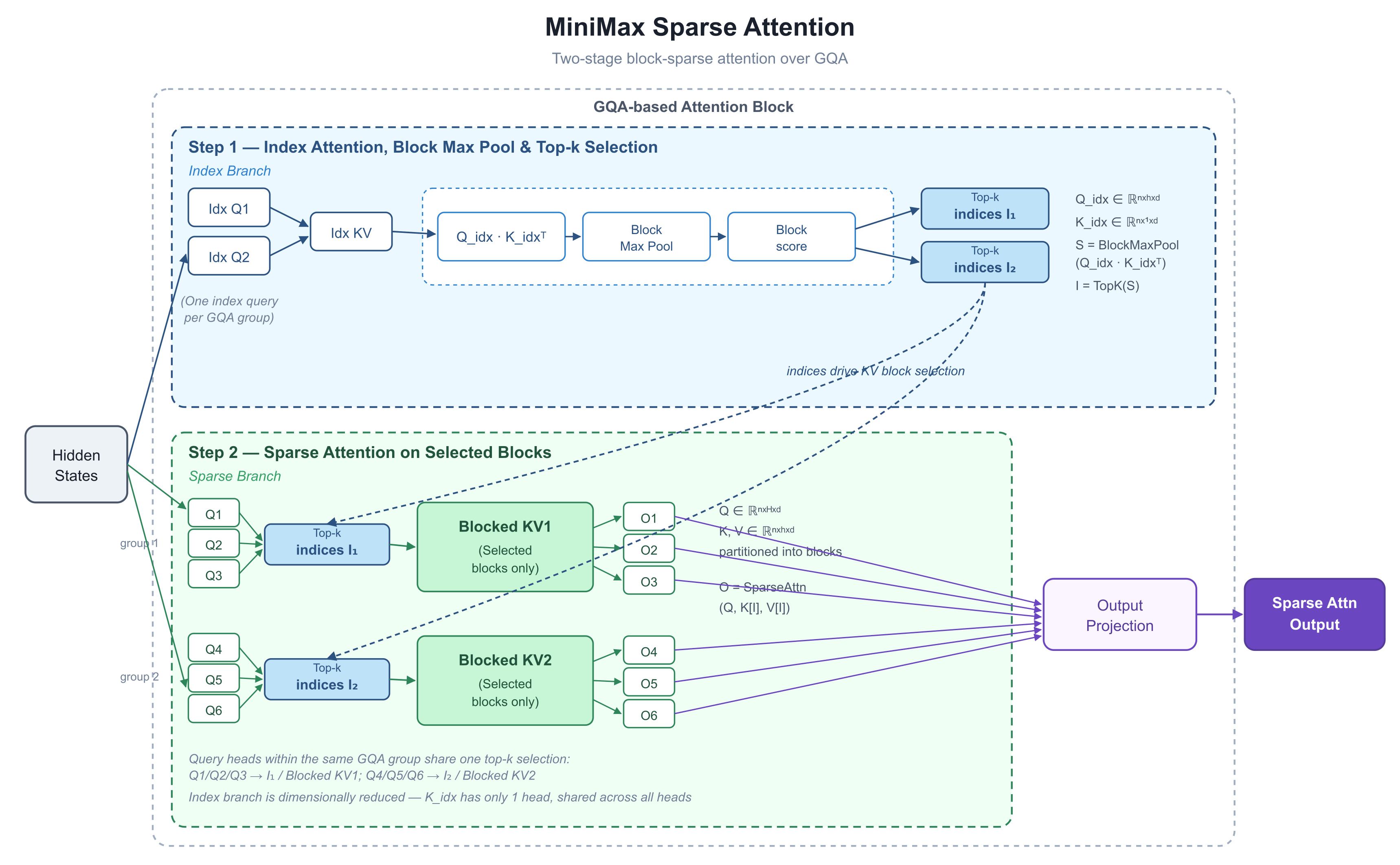
では、MiniMaxはどのようにこれを実現したのでしょうか?5月26日、MiniMaxのR&DリーダーであるSkyler Miao氏がXに1枚の図を投稿しました。控えめな色使いながら情報が凝縮されたその図には「MiniMax Sparse Attention」というタイトルがあり、誰もが注目した数値を持つ2つの曲線が描かれていました。1Mトークンでプリフィル(事前充填)が9.7倍、デコードが15.6倍高速化というものです。コミュニティはほぼ満場一致でこれをM3のティーザーと解釈しました。私たちはその数値の裏にあるアーキテクチャを解明するため、この図を分解しました。
解説の前に基本を押さえておきましょう。この話を理解するために必要な用語は3つです。
- プリフィル:モデルが入力内容を一気に読み込むパスのこと。
- デコード:トークンを1つずつ生成する、より低速なフェーズ。ロングコンテキストでは、新しいトークンが生成されるたびに過去のすべてを参照する必要があるため、このデコードがボトルネックとなります。
- 疎アテンション:この解決策です。すべてのトークンが他のすべてのトークンに注目する(デフォルトではコストがシーケンス長の2乗で増加する)のではなく、慎重に選択された「サブセット」にのみ注目させることで、計算量を抑えつつ精度を維持します。このサブセットをどう選ぶかが、各社の腕の見せ所です。
このティーザーが重みを持つ理由は、昨年10月にMiniMaxが公開した『なぜM2はフルアテンションモデルになったのか?』という記事にあります。M1の効率的な「Lightning Attention」を採用せず、効率的なアテンションが実用レベルに達していなかったことを説明した、極めて率直な内容でした。それから6ヶ月後、疎アテンションを前面に押し出したM3が登場したのです。そのサブテキストは、「今度は準備が整った」という一言に尽きます。
1. 図が示すもの:計算前に選択する2段階プロセス
この図は、単一のアテンションブロックの内部構造を展開したものです。その重要な動きは、「どのトークンを見るか」と「それらのトークンに対してどうアテンションを計算するか」を明確に分離した2つのステップにあります。
基盤技術について補足します。M3は**GQA(Grouped-Query Attention)**に基づいています。標準的なアテンション層では、すべてのクエリヘッドが独自のキーと値のセットを持ちますが、これは表現力が高い反面、KVキャッシュ(過去のすべてのトークンのキーと値を保持し、ステップごとに再計算しなくて済むようにするキャッシュ)を肥大化させます。GQAはクエリヘッドをグループ化し、各グループで1つのキーと値のセットを「共有」します。これは今日、ほとんどの商用モデルで採用されている標準的なメモリ節約レイアウトです。この設計が全体の基礎となっていることを覚えておいてください。
ステップ1:インデックス分岐 — 安価にスコアリングを行う
上半分はインデックス分岐です。メインパスの脇で実行され、「どのトークンブロックを見る価値があるか」を判断する役割を担います。
各GQAグループは1つのインデックスクエリを共有します(図では6つの実ヘッドが2つのインデックスクエリ「Idx Q」とペアになっており、グループごとに1つずつ割り当てられています)。この分岐のキー側は意図的に簡素化されています。

K_idxにはヘッドが1つしかなく、すべてのヘッドが同じインデックスキーを共有していることに注目してください。これにより、スコアリングステップ(Q_idx · K_idxᵀ)のコストがほぼゼロになります。
次に、Block Max Poolがトークンレベルのスコアをブロックレベルのスコアに圧縮します(シーケンスを固定サイズのブロックに分割し、各ブロックの最高スコアを保持します)。

最後にTopK(スコアの高い上位k個を保持する)が、この層とグループでどのKVブロックを残すかを決定します。出力はインデックスの短いリスト(I₁、I₂)です。
ステップ2:疎分岐 — 実際のアテンション計算
下半分は実際の計算です。クエリ、キー、値は標準的なGQA形式のままです。ステップ1で得られたI₁とI₂を使用して、ブロックはフルセットの中から選択されたサブセットのみを抽出し、それらに対してアテンションを実行します。

最も重要な設計上の決断: グループ内のすべてのクエリヘッドが、単一のTop-k選択を共有します。図では、Q1/Q2/Q3はすべてI₁を使用し、Q4/Q5/Q6はすべてI₂を使用しています。これはDeepSeekのNSA論文で強調されている「ハードウェア整合性の原則」であり、1つのクエリグループが1つのKVブロックセットを読み込み、それが(GPUの高速なオンチップメモリである)SRAMに収まるようにすることで、標準的なFlashAttentionスタイルのカーネルをそのまま再利用できるようにしています。
2. DeepSeekファミリーとの3つの意図的な差異
コミュニティはすぐに、これをDeepSeekの3つの疎アテンション設計と比較しました。
- NSA(Native Sparse Attention):事前学習の段階からスパース性が組み込まれたネイティブな実装。3つの並列分岐(圧縮+選択+スライディングウィンドウ)と学習済みゲートを備える。
- DSA(DeepSeek Sparse Attention):DeepSeek V3.2で実装。非常に軽量なインデクサーを用いたトークンレベルの選択。
- CSA:DeepSeek V4に関連するブロックレベルの手法を指すコミュニティ用語。
コミュニティの読み解きは、「M3はMLAではなくGQAを使用し、CSAの精神に基づいたブロックレベル選択を行うが、計算は「本物」のキーと値に対して実行する」というものです。
表にまとめると以下の通りです。
| 項目 | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (推測) |
|---|---|---|---|---|
| KV基盤 | MLA (latent) | GQA | MLA | GQA |
| 選択の粒度 | トークンレベル | ブロックレベル | ブロックレベル | ブロックレベル |
| 並列分岐 | 1 (indexer + select) | 3 (compress + select + window) | 1 | 1 (select only) |
| 計算対象 | 実際のK/V | 3者融合 | 圧縮済みKV | 実際のK/V |
| インデクサーのコスト | Lightning indexer | 圧縮分岐 | ブロック要約 | 単一ヘッドK + Block Max Pool |
| ゲーティング | なし | 学習済みゲート | なし | なし |
この表は、もう1つの重要な概念である**MLA(Multi-head Latent Attention)**を隠しています。これはDeepSeekの代名詞とも言える手法で、完全なキーと値をキャッシュする代わりに、小さな「潜在(latent)」ベクトルに圧縮してキャッシュし、オンザフライで復元します。KVキャッシュは劇的に縮小しますが、数学的な計算が標準的なアテンションとは異なるため、カスタムカーネルが必要です。この対比が、M3の3つのトレードオフのうち最初のもを導いています。
第1の差異:MLAではなくGQAを基盤とする。 M3は標準的なGQAに留まるため、vLLMやSGLangといった一般的なオープンソースの推論サーバーやFlashAttentionが、ほぼ修正なしでそのまま利用可能です。MLAのような特殊な処理を回避するためのエンジニアリングが必要ありません。「本番環境での即戦力」を目指すラボにとって、最もリスクの低い道です。これは設計全体の中で最もビジネス視点での合理性がある点です。「MiniMaxは、誰もがすでに持っているハードウェアとソフトウェアで即座に動くものを最適化しようとした」のです。
第2の差異:ブロックレベル選択だが、計算は実際のキーと値で行う。 圧縮済みKVに対して計算を行うCSAとは異なり、M3は標準的なソフトマックス・アテンションの表現力を保持します。コストとしてKVキャッシュはスパース化に比例して縮小しませんが、精度を保つためにメモリの一部を割くというのは合理的な妥協です。
第3の差異:NSAの他の2つの分岐がない。 NSAは3つの並列パスと学習済みゲートを実行しますが、M3は選択のみを残しました。一言で言えば「エンジニアリング・ファースト」の簡素化です。省略された2つの分岐のうち、スライディングウィンドウはおそらく**RoPE(回転位置埋め込み)**とアテンションシンク、あるいはGemma 3やQwen3-Nextのように層ごとのフォールバックとして密なアテンションを使用することで代用されています。圧縮分岐は、最小限の「単一ヘッドK + Block Max Pool」に吸収されました。
3. 数値の読み方
| フェーズ | 1Mトークンでの高速化 | 意味 |
|---|---|---|
| プリフィル | 9.7倍 | 100万トークンの入力を一括処理 |
| デコード | 15.6倍 | トークンを逐次生成 |
デコードがプリフィルを上回る高速化を見せているのは理にかなっています。プリフィル中、インデックス分岐は依然として全入力長をスキャンする必要があるため、恩恵はメインのアテンションに限定されます。一方デコードでは、新しいトークンが選択されたKVブロックのみとやり取りするため、KVキャッシュへのメモリ帯域圧力は1桁近く低下します。ここがデコード時のコストの主戦場だからです。
選択率を逆算してみましょう。ブロックサイズを64トークンと仮定すると、100万トークンは約16,000ブロックです。デコードが15.6倍高速化するということは、各クエリが実際にアクセスするのはブロックのわずか6〜7%、つまり実効受容野は約60k〜70kトークンであることを示唆しています。この比率は、NSA論文が報告するスパース率(6〜10%)とほぼ一致します。これは偶然ではなく、1Mスケールにおけるこの設計のスイートスポットなのです。
4. M3の残りの部分を推測する
このアテンションブロックからモデル全体を外挿すると(図は推論を示しているため):
- MoE(Mixture of Experts)バックボーンは維持される可能性が高い。 MoEはアテンションとは独立したモデルの骨格です。各トークンを巨大なネットワークに流す代わりに、ルーターが専門家サブネットワークへ振り分けることで、小さなアクティブ計算量で大きなモデルの精度を得ます。M2は総パラメータ230B / アクティブ約10BでTop-2ルーティングを採用し、M2.7では専門家数が256に増加しました。M3がこれを捨てる理由はなく、より深く、より広くなる変更が予想されます。
- フルアテンションスタックがブロック疎なGQAに置き換わる。 M1のLightning Attentionが復活する可能性は低いです。M3は線形アテンションへの再賭けではなく、「ソフトマックスの表現力+Top-kブロック選択」という、精度を保ちながらサブ2次コストを実現する道を選んでいます。
- ネイティブにスパース性を学習済み。 これがNSA論文の核心的な教訓です。スパースなパターンは事前学習時に勾配に組み込まれないと、検索性能が著しく低下します。MiniMaxは検索ヘッドに関する独自の研究ラインを持っているため、その罠にはまらないはずです。
- 主戦場は1M+のコンテキスト。 M1は学習時は1M、推論時には外挿で4Mに対応していました。M3は推論コストを大幅に削減しつつ、そのコンテキスト長を定着させる意図が見え、製品サイクルの自然な流れと言えます。
5. 2026年の設計空間におけるM3の位置づけ
2025年から2026年にかけて、疎アテンションの設計は急速に分岐しました。
- DeepSeek V3.2 DSA: MLA + トークンレベルTop-k。極めて軽量なインデクサー。品質は安定しているが、カーネル開発の難易度が高い。
- DeepSeek NSA: GQA、3分岐+ゲート。品質の天井は高いが、実装が最も複雑。
- Qwen3-Next: 密アテンションと線形アテンションを層ごとに混合。堅牢だが比較的保守的。
- MiniMax M3: GQA + 単一分岐ブロック選択。最小限の構成で、ハードウェアのトレンドを最大限に活用。
M3の設計が示唆するものは明らかです。理論的に最適なアテンションを追うのではなく、即座に動き、高速で、既存のカーネルを再利用できるものを追うのです。これは、M2でフルアテンションに立ち返ったという決断と一貫しています。まず主流の手法で品質を安定させ、技術が成熟した段階でクリーンに置き換えるという戦略です。
6. 次世代AIアプリを開発している意味とは
アーキテクチャの視点から一歩下がると、より大きなパターンが見えてきます。主要なAIラボはすべて、学習済みの疎アテンションをリリースしています。方向性は決まりました。すべてのフロンティアモデルが低コストでロングコンテキストを扱えるようになれば、モデル自体はもはや「堀」にはなりません。 推論コストはコモディティ化に向かっています。差別化の要素は、どのワークロードでどのモデルを走らせるか、それらをどうルーティングし、6週間ごとに次が登場した際にいかに速く適応できるかという点に移っています。
これは「最も安いエンドポイントを探す」ことよりも難しい問題です。本番アプリを運用するチームは、品質、遅延、コスト、そしてビジネス成果という4つのバランスを常に取る必要があり、正解はワークロードごとに異なり、リリースサイクルごとに変化します。開発者は、フロンティアが動くたびに統合し直すことなく、モデルの選択、ルーティング、交換ができる層の上に構築することが重要です。エンジニアリング予算を、リリースノートを追いかけることではなく、自社のプロダクトそのものに注ぐべきなのです。
Atlas Cloudはまさにその層で機能しています。LLM、動画、画像、音声を横断する300以上のモデルを1つのAPIで提供し、インテリジェントなルーティングと、新モデルへのデイゼロアクセスを実現しています。M3は未公開ですが、公開され次第、Atlasでデイゼロアクセスを提供予定です。 私たちを利用して開発を行うチームが、公開から数ヶ月後ではなく「公開されたその日」に自社のユーザーへ提供できるようにするためです。
結びに
たった1枚の図から断定できないことは多々あります。疎なパターンが層ごとに混合されているのか、密なフォールバックはあるのか、インデックス分岐がメインネットワークと埋め込みを共有しているのか、学習時のTop-kはハードかソフトかなど。これらはすべて公式論文やウェイトの公開を待つ必要があります。
しかし、1つだけ確かなことがあります。DeepSeekに続き、また1つの大手ラボが疎アテンション+ロングコンテキスト+オープンなウェイトという実用的なスタックを組み上げたということです。2026年後半には、オープンソースにおける1Mコンテキストは「売り」から「前提条件」へと変わるでしょう。それ自体が、個別のベンチマーク結果よりも遥かに重要です。






